
AIの強化学習とは?世界モデルでかわること・機械学習・ディープラーニングとの違い・アルゴリズム・活用事例7選徹底解説!
最終更新日:2026年01月31日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

AI(人工知能)が自律的に学ぶことを目的とした、最も注目を集めている技術のひとつが強化学習です。この技術を使えば、コンピューターが複雑なタスクを自己学習でこなすことができるようになります。
囲碁やチェス、そして将棋でもAIが人間のチャンピオンに勝ったというニュースはご存知の方も多いのではないのでしょうか。その技術も強化学習があってこそです。
ゲームAIの最適化やロボットのタスク自動化など、さまざまなビジネス分野で活用されています。
この記事では、強化学習の基礎的な概念や原理、世界モデルを用いた改善手法、アルゴリズム、混同しやすい機械学習やディープラーニングとの違い、強化学習が実際に活用されている事例などを紹介します。初めて強化学習について学ぶ方や、この技術に興味を持つ方にもおすすめです。
AIとは?、基本的な仕組み、ビジネスへの活用事例を一気に学べる初心者向け完全マスター記事はこちらです。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
目次
強化学習とは?

強化学習とは、AIが自律的に学ぶことを目的とした技術です。正解を与えなくても試行錯誤を繰り返しながら、最適な行動をするようコンピューターが学習します。この技術を使えば、コンピューターが複雑なタスクを自己学習でこなすことができるようになります。
強化学習は、教師あり学習や教師なし学習といった機械学習の種類全般の中でも特徴的なポジションを占めています。以下のような学習手法と組み合わせることでさらなる発展が期待されています。
- 転移学習
- メタ学習
- Few Shot Learning(フューショット学習)
- Zero Shot Learning(ゼロショット学習)
- アンサンブル学習
- モデルマージ
- 知識蒸留(knowledge distillation)によりモデルを軽量化
強化学習では、人間や一部の動物が学習するように、コンピューターが報酬を得ることを目的として行動を学習します。コンピューターは、自身の行動によって得られる報酬を最大化するように学習します。
強化学習は、ゲームAIの最適化やロボットのタスク自動化など、さまざまな分野で活用されています。また、近年では、医療や金融などの業界でも採用されるようになっています。
複雑な環境における最適行動選択にはフレーム問題への対処が重要な課題となっています。
強化学習のモデル
強化学習がどのようなモデルから成り立っているのか、いくつかの言葉の定義を含め説明します。強化学習は主に以下2つの要素から成り立ちます。
- エージェント・・・学習主体(AI)
- 環境・・・制御対象
エージェントと環境の相互作用は「エピソード」と呼ばれる期間で何度も繰り返されます。
強化学習でAIが各州する基本モデルは以下です。
- エージェントが何らかの行動をする
- 置かれた環境下でエージェントを取り巻く状態が変化
- 環境変化の結果が報酬としてエージェントにフィードバックされる
強化学習の目標は、エージェントが将来にわたって受け取れる報酬が最大化する行動を選択できるモデルを獲得することです。行動を決定するモデルを「方策(ポリシー)」、報酬の合計値を「収益」と呼びます。つまり、強化学習の目的は「収益を最大化する方策(ポリシー)を獲得すること」です。
仮想世界で学習を加速させる世界モデル
強化学習では、エージェントが実環境で膨大な試行錯誤を繰り返す必要があり、学習に多大なコストや時間がかかるという課題がありました。この課題を解決するアプローチとして注目されているのが「世界モデル(World Model)」です。
世界モデルとは、一言で言えば「環境そのものを模倣したシミュレーター」です。エージェントはまず、実環境との相互作用から「次に行動したら、世界(環境)はどのように変化するか」を予測するモデルを頭の中に構築します。
そして、その仮想的な世界モデルの中で行動のシミュレーションを高速に繰り返すことで効率的に最適な方策を学習します。
このように環境のモデルを活用する手法は「モデルベース強化学習」と呼ばれます。実世界での試行錯誤が難しいロボット制御や自動運転といった領域で特に重要視されており、より少ないデータで、より長期的な予測に基づいた賢い意思決定を実現する技術として期待されています。
関連記事:「世界モデルとLLMの違いは?定義・ベース技術・活用シーンの比較や相互補完する関係性を徹底解説!」
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
強化学習と機械学習の違いは?

AIがパターンやルールを学習する方法の一つに「機械学習」があります。機械学習は主に強化学習を含む以下3領域に分けられます。
1. 教師あり学習
2. 教師なし学習
3. 強化学習
AIモデルにどんな種類があるかこちらの記事で詳しく説明していますので併せてご覧ください。
強化学習と教師あり学習、自己教師あり学習の違い
教師あり学習は、人間がAIに正解を示しパターンを学習させる方法です。明示的な正解があって、AIはそれを真似ることを目指します。
自己教師あり学習は、人間が正解を示すわけではなく、データそのものから学習用の正解を自動生成して学習する手法です。
一方、強化学習と教師なし学習は正解がない状態から自ら正解を探索して学習する方法です。
教師あり学習の詳しい仕組み、用いられるアルゴリズムについてはこちらの記事で特集していますので併せてごらんください。
強化学習と教師なし学習の違い
機械学習の1つである教師なし学習は、データセット内に含まれる潜在的な関係や構造を自動的に抽出する手法です。データを分析することで、データの特徴を自動的に学習し、正解を知らない未知のデータに対して予測や分類を行うことができるようになります。
強化学習にも正解はありません。その代わりに、強化学習は行動がどれだけよかったかを報酬として与えて、その報酬が高くなるように行動を仕向けます。データそのものの関係性や構造には踏み込む必要がありません。
教師なし学習はデータそのものの特徴を学習する一方で、強化学習は長期で最適な行動を学習するという点で異なります。
強化学習とディープラーニング(深層学習)の違い
ディープラーニング(深層学習)は、多層のニューラルネットワークを使った機械学習手法です。機械学習に飛躍的な進展をもたらし、現在のAIブームの火付け役にもなりました。ディープラーニングでは、大量のデータを入力し、データから自動的に特徴量を抽出して、予測や分類を行うことができます。ディープラーニングは、自ら学習すべき要素を見つけ出して試行錯誤を繰り返すのが特徴です。
強化学習では、何を学習するのかは人間が決めます。そして、報酬の最大化を目的としてAIが自己学習する手法です。
関連記事:「DNN(ディープニューラルネットワーク)とは?仕組み・活用メリット・活用分野・注意点を徹底紹介!」
強化学習と深層強化学習の違い
「深層強化学習」は強化学習に、ディープラーニングを組み合わせた新しい学習方法です。深層強化学習によって、それまで実現が不可能だったより複雑なタスクの処理も人間を上回るようになりました。
強化学習と深層強化学習は、ある状態で最適な行動を学ぶという点は同じです。深層強化学習は学習段階での行動を決定する手がかりとしてニューラルネットワークが用いられる点で異なります。
強化学習と逆強化学習の違い
逆強化学習(inverse reinforcement learning)は、エージェント(AI)が行った行動から、そのエージェントが望んでいる報酬を推定する方法を学習します。逆強化学習は、人間のように行動を学習するエージェントを作成するために使用されることがよくあります。
例えば、人間が何を望んでいるかを知ることで、AIが人間とより良いコミュニケーションを取ることができるようになるでしょう。また、人間のように行動を学習するAIを作成することで、人間が行うタスクを代替することができるようになります。
敵対的逆強化学習とは?
敵対的逆強化学習(Adversarial Reinforcement Learning)とは、2つのエージェントが相互に対抗し合いながら報酬を最大化するように行動するように学習する方法です。通常の強化学習では、エージェントが環境を観察して、報酬を最大化するように行動するように学習します。しかし、敵対的逆強化学習では、2つのエージェントが自分の報酬を最大化するように対抗して行動するように学習することで、より複雑な環境での行動を学習できます。
敵対的逆強化学習は、ゲームや競争的な環境で使用されることがよくあります。例えば、将棋や囲碁のように2人で対戦するゲームでは、お互いがどのような行動をするかを考慮して報酬を最大化する行動を学習できます。
GANとは?
GAN(Generative Adversarial Network)は、2つのニューラルネットワークを用いて、データセットから新しいデータを生成できるように学習することができます。GANは、以下のような2つのニューラルネットワークからなります。
- 生成モデル・・・入力されたデータから新しいデータを生成するように学習
- 識別モデル・・・入力されたデータが生成モデルで生成されたデータか、もともと存在するデータかを判別するように学習
上記のモデルは、相互に対抗し合いながら、お互いを強化するように学習します。
GANは、画像や音声などのデータを扱うことができます。例えば、GANを使用すると、入力された画像から新しい画像を生成することができるようになります。例えば、本物そっくりの画像や動画を生成するディープフェイクの技術として使われています。
また、GANを使用することで、音声データを入力して新しい音声データを生成することもできます。 GANを使用することで、新しいデータを生成することができるため、データの拡張やデータの不足を補うことができます。
GANの仕組み、ビジネスでの活用事例についてこちらの記事で解説していますので併せてご覧ください。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
強化学習のアルゴリズム3選

強化学習にはさまざまなアルゴリズムがあります。ここでは代表的な以下のアルゴリズムを紹介します。
1. DP法(動的計画法)
2. MC法(モンテカルロ法)
3. TD法(時間差分学習法)
それぞれのアルゴリズムについて説明します。
1.DP法(動的計画法)
DP法(動的計画法)は、最適化問題を解くためのアルゴリズムの一つです。「DP」はDynamin Programinng:動的計画の頭文字です。対象の問題を細かく分割し、計算や処理をしていくことで学ぶアルゴリズムです。分割した部分問題を順に解いていき、すでに得られた部分問題の解を再利用することで全体の解を効率的に求めます。
数学的な計算や探索を行うので計算量が多くなることがあります。だからこそAIに向いていると言えるでしょう。完全で正確な環境のモデルが与えられている場合、DP法は最適な方策を計算可能です。それで、多くの最適化問題で採用されています。
例えば、ゲームAIの最適化や、ロボットのタスク自動化などで使われることがあります。また、経済学や工学など用いられます。
2.MC法(モンテカルロ法)
MC法(モンテカルロ法)は、乱数を用いて期待値を求める手法です。期待値とは、特定の確率分布に従って、ある出力が得られる確率と、その出力に対する報酬を掛け合わせた値の平均です。
MC法では、期待値を求めるために大量のサンプルを生成して、それらを用いて計算を行います。または、エージェントにとにかく何らかの行動を実行させて得られる報酬をエピソードで記録する方法も用いられます。各エピソードの結果で得られた報酬の平均を算出して期待値を求め、報酬の値として学習します。
一般的に、MC法は、サンプル数が大きいほど期待値を正確に求めることができます。ただし、サンプル数が多いほど、計算時間がかかることになります。また、確率分布が不明な場合には、MC法を使用することができません。
3.TD法(時間差分学習法)
「TD(Temporal Diggerence:時間差分学習)法」は、DP法とMC法を組み合わせたアルゴリズムです。行動したことによる環境への影響が不確定な場合でも、影響を推定することにより行動を可能にすることを目的としています。TD法は「SARSA(State-Action-Reward-State-Action)」と「Q-learning」の2種類に分けられます。
SARSAはAIが行動した結果で得られた数値をもとに学習するアルゴリズムです。現在の状態「S」から、エージェントがある行動「A」を取ったとき、エージェントには行動に対する報酬「R」が与えられます。結果として、「S’」という行動後の状態が確定します。SARSAでは、AIは「S’」という状態を前提に、「A’」という次の最適な行動を予測して行動に移ります。この流れを繰り返しAIが最適な行動パターンを学ぶのがSARSAです。Q-learning(Q学習)よりも安定した学習を行える傾向があります。
Q-learning(Q学習)は、「max関数」という関数によって行動を学習しエージェントを制御するアルゴリズムです。ある行動を取るたび、行動の価値である「Q値」を「Qテーブル」に入力し、新しく行動するたびにQ値を更新する学習方法です。その時点での価値の最大化できる行動を学習させます。
強化学習の活用事例7選

強化学習を活用した事例をいくつか見ていきましょう。
- 最強の囲碁プログラム「AlphaGo」(DeepMind社)
- 広告の最適化でマーケティング支援(ナビプラス)
- 自動運転をより安全に(Preferred Networks)
- 文脈バンディットを使ってコンテンツをレコメンド(ネットフリックス)
- ゲーム開発工程でのテスト作業の効率化・自動化(セガ/ブレインパッド)
- 通信ネットワーク経路の最適化
- エレベーターの稼働効率アップ
それぞれの事例について説明します。
最強の囲碁プログラム「AlphaGo」(DeepMind社)
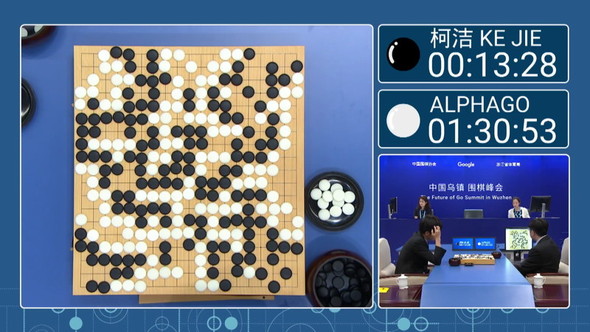
強化学習に一躍注目が集まるようになったのは、Googleの系列企業DeepMind社が開発した囲碁プログラム「AlphaGo」でした。囲碁に留まらず、チェス、将棋などでもAIが人間を上回る能力を獲得したことが大々的に報道されました。最近のAIの進化は強化学習によってもたらされています。
AlphaGoは、ニューラルネットワークでモデル化し、教師あり学習と強化学習を組み合わせ学習しています。「モンテカルロ木探索」という手法で、統計的に勝つ確率が高い一手を実際の手として選んでいます。
広告の最適化でマーケティング支援(ナビプラス)
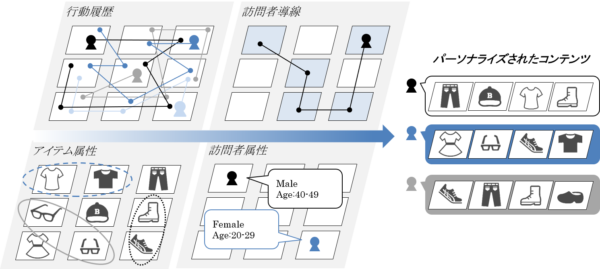
マーケティングツールを手掛けるナビプラス株式会社が提供している「NaviPlusレコメンド」は、ECサイトにおすすめやランキングなどのコンテンツを簡単に表示可能なレコメンドサービスです。
サイトにアクセスしたユーザーにレコメンドされるコンテンツはそれぞれ異なります。ユーザーに最適なコンテンツをレコメンドできれば、満足度も上げられるでしょう。
AIがサイト訪問者の行動情報から強化学習を繰り返し、複数のレコメンドのロジックから最も成果が高いものを自動表示します。最適レコメンドロジックの表示のためのコスト削減や、マーケティング経験者に依存しない運用が可能です。
AIによるレコメンドの仕組み、アルゴリズムについてはこちらの記事で特集していますのでご覧ください。
自動運転をより安全に(Preferred Networks)

完全自動運転で自律走行が可能な自動車にも強化学習が用いられています。株式会社Preferred Networksでは、深層強化学習を活用した「ぶつからない車の自動運転」に取り組んでいます。
道幅が自動車の幅に対して狭く、車が密集しているような交差点など難しい状況において、自動運転の精度を高める取り組みです。トヨタ自動車もPreferred Networksに出資したことで話題となりました。
自動運転で活用されているAI技術の種類と、これからの課題についてこちらの記事で特集しています。
文脈バンディットを使ってコンテンツをレコメンド(NETFLIX)

米国の動画配信サービスのネットフリックス(NETFLIX)では、強化学習のアルゴリズムの一つである「文脈バンディット」を使い、レコメンドする映像作品のサムネイルをカスタマイズしています。同じ映画やコンテンツに至った場合でも、視聴者によって反応が変わるので、視聴履歴に応じて強調するテーマや俳優を変えています。視聴されたコンテンツのおよそ75%がレコメンドシステムをきっかけとして選ばれていると明らかにしました。
文脈バンディットは、強化学習の一種であるバンディット問題を解決するために使用されます。バンディット問題は、複数のアクションを選択できる環境で、過去のデータを使用して報酬を最大化するように行動することを目的とする問題です。文脈バンディットは、その環境の文脈(コンテキスト)を考慮して行動を選択できます。
ゲーム開発工程でのテスト作業の効率化・自動化(セガ/ブレインパッド)
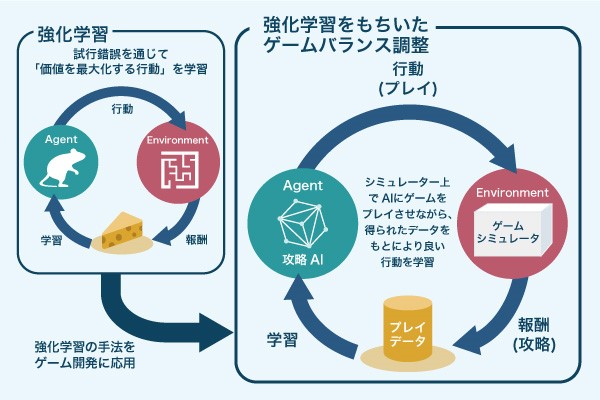
株式会社セガゲームスと株式会社ブレインパッドは、ゲーム開発工程におけるテスト作業の負荷を軽減させるため、強化学習AIによるテスト作業の効率化や自動化を実現しました。ゲーム開発に欠かせないテスト作業は時間やコストが非常に多くかかります。スマートデバイス向けの多くは、リリース後にもアップデートが頻繁に行われるため、さらにテスト作業の負荷が大きくなります。
そこで、強化学習を用いたテスト作業を導入しました。開発段階では、まだ一般ユーザーがプレイしていないために学習に使えるデータがありません。しかし、強化学習であればAIが実際にゲームをプレイしながら、最適戦略を見つけられます。強化学習により、ゲームバランスの調整作業をより短時間で行えるようになり、開発効率が飛躍的に向上したということです。
ゲーム開発に用いられるAI技術については、こちらの記事で特集していますので併せてごらんください。
通信ネットワーク経路の最適化
通信ネットワークの経路の最適化に強化学習が用いられています。音声や映像などさまざまなデータを特性に応じてトラフィックを最適化するために強化学習によって改善が可能です。
TD法(時間差分学習法)の1つであるQ-learning(Q学習)を手法として、データ移動の遅延を極力少なくできるような経路探索ができるようになっています。
エレベーターの稼働効率アップ
エレベーターでいかに多くの人を短い時間で効率的に運ぶことができるかという最適化問題は長年研究されている課題の一つです。高層のオフィスビルやタワーマンションなど、多くの人が使用するエレベーターは、ルールベースのアルゴリズムだけでは効率を上げることが難しいとされています。
そこでエレベーターの稼働効率を上げる取り組みに強化学習が用いられています。エレベーターを使用する人々が最短の時間で目的のフロアに到達することを報酬として、フロアのパターンやエレベーターを使用する人々の数などを入力として強化学習を用いることで、エレベーターの稼働を最適化できるのです。強化学習によって過去のデータをもとに最適な運行ルートが選択できるので、乗降客の待ち時間を短縮することにも成功し、柔軟なエレベーターの稼働が可能です。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
AIの強化学習についてよくある質問まとめ
- 強化学習と他の機械学習手法(教師あり学習、教師なし学習、ディープラーニング)との主な違いは何ですか?
強化学習と他の機械学習手法の主な違いは以下の通りです。
- 教師あり学習: 正解データが必要。強化学習は試行錯誤で学習
- 教師なし学習: データの構造を学習。強化学習は長期的に最適な行動を学習
- ディープラーニング: 特徴量を自動抽出。強化学習は報酬最大化が目的
- 強化学習: エージェントが環境と相互作用しながら報酬を最大化する行動を学習
- 強化学習の代表的なアルゴリズムには何がありますか?それぞれの特徴を教えてください。
強化学習の代表的なアルゴリズムは以下の通りです。
- DP法(動的計画法): 問題を分割して解く。環境モデルが既知の場合に有効
- MC法(モンテカルロ法): 大量のサンプルで期待値を求める。確率分布が不明な場合は使用不可
- TD法(時間差分学習法): DP法とMC法を組み合わせた方法。SARSAとQ-learningがある
- 強化学習の実際の活用事例にはどのようなものがありますか?
強化学習の主な活用事例は以下の通りです。
- AlphaGo: 囲碁プログラム
- 自動運転: 安全性向上
- レコメンドシステム: Netflix, ECサイトでの商品推薦
- 広告最適化: マーケティング支援
- ゲーム開発: テスト作業の効率化
- 通信ネットワーク: 経路最適化
- エレベーター制御: 稼働効率向上
まとめ
さまざまな分野で強化学習のAIが採用されています。これからニーズはますます高まるでしょう。自社でも強化学習を活用したAIをビジネスの最適化に使いたいとお考えかもしれません。今はベテランの勘や経験によってでしか答えを出せていない業務も、実はAIによって誰もが最適解を出せるかもしれません。
しかし、AIを導入するためにはどのような業者やパートナーと組むのがいいのかわからないという方も多いのではないでしょうか。AIの専門用語、システム要件はわからないし、見積もりの内容チェック方法もわからない方がほとんどではないかと思います。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

