
RAG(検索拡張生成)とは?【2026年最新版】AI Marketでの導入相談事例・LLMとの連携シーン・メリット・システム構築の注意点を徹底解説!
最終更新日:2026年06月05日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

ChatGPTをはじめとするLLM(大規模言語モデル)だけでは、最新の情報、及び企業内部データを反映した正確な文章生成が困難、かつ情報セキュリティの不安がありました。
LLMとは?どんな種類がある?こちらの記事で詳しく説明していますので併せてご覧ください。
こうした中、注目を集めているのが「RAG(検索拡張生成:Retrieval-Augmented Generation)」と呼ばれる最新技術です。RAGは、LLM単体では保有していない情報も含めた、より正確で自然な文章生成を可能にすることから、LLMとRAGを組み合わせたシステム活用が進んでいます。
本記事では、RAGとはなにか、RAGの仕組みやメリット・デメリットを解説するとともに、ビジネスシーンでの具体的な活用事例、構築方法、さらには、AI Marketで実際にRAG相談をいただいた事例について紹介します。
DXを推進する企業の意思決定者の皆様にとって、RAGがもたらす価値とインパクトをご理解いただく一助となれば幸いです。
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
LLM・RAG開発が得意なAI開発会社について知りたい方はこちらで特集していますので、併せてご覧ください。
目次
RAG(検索拡張生成:Retrieval-Augmented Generation)とは?

RAG(検索拡張生成:Retrieval-Augmented Generation)は自然言語処理(NLP)技術の一つで、LLMの生成能力を外部情報源からの検索結果によって拡張する技術です。
簡単に言えば、AIが「本を調べてから答える」ように動作するシステムと考えることができます。現在、ChatGPT等のLLMと組み合わせた活用が進んでいます。
この先、エージェンティックRAG(Agentic RAG)による業務自動化、そして、テキストだけでなく、CAD図面、回路図、フローチャートなどの画像情報を直接検索対象に含めるマルチモーダルRAGは企業必須のツールとなっていくでしょう。
さらに、クラウドに出さず社内サーバーやローカル環境で完結させるエッジ/ローカルRAGのニーズも高まっています。
なぜLLMの事前学習データだけでは不十分?
LLM(大規模言語モデル)は事前学習済みのデータセットに依存するため、最新情報の反映や速やかなアップデートが困難です。また、学習データやユーザーの入力データに社内データ(特に機密情報を含むもの)を使うことは機密情報の漏洩につながるリスクがあります。
そこで、RAGの技術を活用し、事前学習されていない自社オリジナルのデータが格納されたデータベースからリアルタイムに情報を検索・取得し、そのデータをLLMの回答生成に活用することで、オリジナルデータを踏まえた回答を行うことが可能になります。
RAGとLLMを組み合わせて、オリジナルな回答を行うシステムのイメージは以下のような形です。
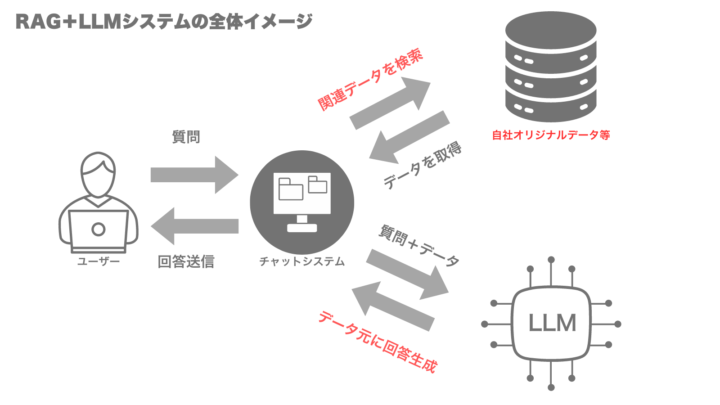
関連記事:「LLMとRAGで社内情報検索を効率化!検索・活用における役割やメリット、課題の解決方法」
ファインチューニングとの違い
ファインチューニングは、特定領域に対応した大量の学習データによる追加トレーニングを行う手法で、膨大なコストと時間がかかります。
一方、RAGは事前学習済みのLLMの知識を活用しつつ、LLMの回答結果に別の知識データ(外部で構築したデータベースなど)を読み込ませる手法となるため、ファインチューニングを行うよりもカスタマイズ工数を削減しつつ、高精度な回答生成を可能とします。これにより、より低コスト且つスピーディーに独自の回答を行うオリジナルLLMの構築を可能とします。
ファインチューニングとRAGの違い、使い分け方をこちらの記事で詳しく説明していますので併せてご覧ください。
下記は、RAGを理解する上で、非常に重要な論文です。RAGについては、現在進行中で、新しい技術や手法が研究・報告されています。
arXiv|Retrieval-Augmented Generation for Large Language Models: A Survey
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
AI MarketでのRAGに関連する相談事例
生成AI(RAG)に関連する、実際にAI Marketに相談のあった企業様の事例をご紹介します。(会社名が特定できる情報は伏せています)
製造現場の技術継承を支援するチャット型LLM活用
幅広い化学製品を製造・販売するメーカー様では、熟練オペレーターが長年にわたり培ってきた設備トラブル対応ノウハウを若手に継承することが急務となっていました。
現場では「●●プラントの温度が安定しない」「異常音が出た」など突発的な課題が日常的に起こります。しかし、マニュアル検索やベテランへの電話連絡では解決に時間がかかり、稼働ロスが発生していました。
そこで同社は、自社過去データや操作手順書を学習させたLLMをチャットツール上で利用する仕組みについてAI Marketへご相談をいただきました。
AI Marketのパートナー紹介
担当者が質問すると即座に原因切り分けや対処手順を提示してくれる仕組みを構想し、AI Marketは、お客様の課題をヒアリングした上で、以下のような技術を提供できるAI会社・サービスを紹介致しました。
- 自社文書を検索・参照できるRAG技術
- チャットUIを安全に社内展開する エンタープライズ向けLLMチャットボット開発
医薬品講演資料の法規制チェックをAIで自動化したい
国内で医療機関向け講演会を開催する医薬品メーカー様では、講演で使用されるスライド(1回最大150枚程度)の内容が各種法規制や業界ガイドラインに適合しているかを審査する業務に追われていました。
以下について確認する必要があり、担当部門の負荷は限界に近づいていました。
- 公正取引委員会の指針
- 薬機法や景表法
- 製薬業界団体のルール
- 引用論文との整合性
同社からはAIを用いてスライドのテキストと画像を解析し、規制違反や誇張表現を自動で検知したいというご相談を受けました。具体的には、LLMに社内外のレギュレーション文書を取り込むRAG(検索拡張生成)の仕組みを用い、スライドの記述を自動照合するイメージです。
AI Marketのパートナー紹介
お客様としては、将来的には、引用文献の自動突合や、審査レポートの生成まで一気通貫で行えるワークフローを構築したいと考えられていました。AI Marketは、お客様の課題をヒアリングした上で、相談内容に合わせ、以下のような技術を提供できるAI会社・サービスを紹介致しました。
- LLMを活用した法規制要件の自動抽出
- RAGを活用した引用文献・エビデンス照合
- スライド画像解析・OCRによる内容デジタル化

LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
なぜ今企業でRAG導入が進んでいるのか?
現代のビジネス環境において、企業競争力の源泉は「どれだけデータを活用し、テクノロジーを業務に組み込めるか」に大きく依存しています。
特に近年では、生成AIを活用した業務効率化やナレッジの利活用が注目されており、生産性向上や働き方改革、さらにはDXの加速といった企業課題の解決に直結する手段として脚光を浴びています。
その中でもRAGは、既存の社内データや外部情報を柔軟に組み合わせながら、LLMの弱点を補完し、より信頼性の高い回答生成と実務活用を実現できる点で、多くの企業から注目されています。
RAGは単なるデータ活用ツールにとどまらず、組織全体の知識を引き出し、活かし、つなげるための「次世代の業務基盤」としての役割を担っており、今やRAGの導入は、単なる技術投資ではなく、企業成長と変革に向けた戦略的な選択肢となりつつあります。
社内データが活用されていない
企業内には日々、以下のような情報が蓄積されています。
- 議事録
- 報告書
- 製品マニュアル
- FAQ
- トラブル対応履歴
- ベテラン社員の経験に基づくノウハウや業務のコツ:暗黙知
とりわけ製造業や建設業などでは、熟練工による技術伝承が課題となることも少なくありません。
しかし、こうした情報の多くは検索しづらい形式(非構造化データ)で保管されており、必要なときに必要な情報を活用できない「死蔵データ」となっているのが実態です。
RAGは、自然言語による柔軟な検索と生成を組み合わせることで、こうした埋もれた情報やノウハウを表出化・再活用可能にします。
これにより、社内ナレッジの属人化を防ぎ、技術伝承の効率化や業務標準化の推進といった、経営の基盤強化にもつながります。
関連記事:「RAGのデータ収集を成功させる方法は?目的別の考え方・コツ・ツール・外部データ収集手段を徹底解説!」
従来の生成AI活用の限界
ChatGPTをはじめとするLLMの活用は多くの企業で進んでいますが、実運用ではハルシネーションや最新情報が反映されないことによる信頼性の低下が課題として浮上しています。
特に、法務・医療・製造など正確性が求められる領域では、「間違いを含む自動回答」が重大なリスクにつながりかねません。
RAGは、LLMの出力根拠を社内データや信頼できる情報ソースに紐づけることで、回答の正確性と説明可能性を担保します。これにより、LLMの弱点を補完し、より安全かつ実用的な形での業務活用が可能になります。
関連記事:「ChatGPTの回答精度を上げる方法は?RAGの活用方法・プロンプト設計のコツも徹底解説!」
データドリブン経営の加速
DXやAX(顧客体験の変革)において、「データに基づいた意思決定」は極めて重要なファクターです。しかし、実際には「どのデータを、どう使えば良いか分からない」「導入ツールを使いこなせていない」といった現場の声が少なくありません。
RAGは、自然言語によって直感的に情報を検索・抽出し、その場で活用可能な形で提示できる点で、DXやAX推進の「最初の一歩」として極めて有効です。
- 業務マニュアルやナレッジを会話形式で引き出し、現場教育を効率化
- 顧客対応履歴から応対内容を自動提案し、CX向上を図る
- 市場データや社内資料から意思決定に必要な要素を抽出し、判断の質を高める
上記のような活用が、RAGを導入することでスムーズに実現できます。「データはあるが活かしきれない」という課題に対し、RAGはそのボトルネックを解消するテクノロジーとなっています。
関連記事:「データドリブンについて解説し、導入方法、メリットやビジネスへの活用例」
AIエージェントでの活用
RAG(検索拡張生成)は、AIエージェントがより信頼性の高い情報に基づいて判断し、企業の特定の業務ニーズに合致した行動をとるために不可欠な技術です。AIエージェントが自律的にタスクを処理する際、その根拠となる情報が最新かつ正確でなければ、その有効性は大きく損なわれます。
AIエージェントにRAGを組み込むことで、エージェントはまずユーザーの質問やタスク指示に関連する情報を、社内の文書データベースやナレッジベースといった信頼できる情報源から検索・取得します。そして、この取得した具体的かつ最新の情報をプロンプトに含めてLLM(大規模言語モデル)に渡すことで、LLMが持つ汎用的な知識を補強し、より文脈に即した、誤情報の少ない応答や計画を生成させることが可能になります。
これにより、AIエージェントは、例えば「社内規定に関する問い合わせ」に対しては関連規程を正確に参照し、「特定の顧客に関する過去の対応履歴を踏まえた提案」といった業務特有のタスクも、より的確にこなせるようになります。
一歩進んだ活用フェーズとして「Agentic RAG(エージェント型RAG)」が注目されています。Agentic RAGは、AIエージェント自身が「RAG(社内DB検索)を使う」という行動を含む、より複雑なタスクを自律的に計画・実行・評価するアーキテクチャを指します。
関連記事:「AIエージェントの開発手順を解説!必要な技術やフレームワーク、注意点徹底ナビ」
RAG(検索拡張生成)の主要活用シーン比較
単なる社内FAQの高度化に留まらず、企業の意思決定スピードを左右する外部脳へと進化しています。現在のビジネスシーンにおける主要な活用方法を整理しました。
| 活用カテゴリー | 活用内容(ユースケース) | ビジネスメリット |
| CX(顧客体験)の変革 | 過去の応対履歴、購買データ、製品マニュアルと連携したパーソナライズ回答やクレームの一次対応 |
|
| 組織知の資産化 |
|
|
| セールス・マーケ支援 |
|
|
| コンテンツ・知財創出 |
|
|
| 法務・コンプライアンス |
|
|
関連記事:「RAG(検索拡張生成)の活用事例は?企業の事例を徹底解説!」
RAG(検索拡張生成:Retrieval-Augmented Generation)の仕組み

RAG(検索拡張生成:Retrieval-Augmented Generation)は、情報検索と言語生成を組み合わせることで、高度な文章生成を可能にする技術です。RAGの仕組みを理解するために、以下の観点から解説します。
入力されたクエリのエンコーディング
ユーザーからの質問や要求(クエリ)がRAGに入力されると、まず自然言語処理(NLP)技術を用いてクエリを解析します。この解析では、クエリを構成する単語や文章の構造を分析し、その意味や文脈を捉えます。
RAGの処理の第一段階は、ユーザーからの入力(クエリ)をベクトル表現にエンコーディングすることです。ベクトル表現に変換する際には、大規模なテキストデータから単語の意味や関係性を学習し、各単語を数値のベクトルで表現します。このベクトル表現は、クエリの意味や文脈を数値的に表現したものです。
この変換されたベクトルは、後段のベクトルデータベースに対して「意味検索」を行うための、いわば「検索キー」としての役割を果たします。
関連情報の検索
次に、エンコーディングされたクエリベクトルを用いて、ベクトルデータベースから関連する情報を検索します。
ベクトルデータベースには、あらかじめ社内ドキュメントや最新情報がベクトル化され、高速に検索できるようインデックス化されて格納されています。このプロセスにより、LLMがまだ学習していない最新情報や社外秘の内部データにアクセスすることが可能になり、生成される回答の質が向上します。
この検索段階では、ベクトルデータベースのエンジンが、クエリベクトルと格納されている膨大なデータのベクトルとの距離(類似度)を高速に計算し、最も意味的に関連性の高い情報を抽出して提示します。
ハイブリッド検索
ハイブリッド検索は、従来のキーワード検索の強み(特定の単語やフレーズとの完全一致・部分一致による網羅性や直接性)と、AIを活用したベクトル検索の強み(単語や文章の意味・文脈を理解し、類義語や関連情報を見つけ出す能力)を組み合わせた高度な検索手法です。
RAGの仕組みにおいて、まずユーザーの質問に対し、キーワード検索で関連性の高い候補を広範囲に絞り込み、同時にベクトル検索で質問の意図や文脈に合致する情報を意味的に探索します。
そして、これらの検索結果を統合アルゴリズム(スコアの重み付けやリランキングなど)によって最適化し、最も適切で質の高い情報をLLMに提供します。
抽出した情報の統合と文脈理解
検索で抽出された情報は、次にLLM(大規模言語モデル)に入力されます。LLMは、抽出された情報とクエリを組み合わせて、文脈を理解します。
この過程で、LLMは事前学習で得た知識と検索で抽出された情報を、セマンティック検索機能を活用してクエリに対する最適な応答を生成するために必要な情報を選択・統合します。
自然な応答の生成
文脈理解の結果を基に、LLMは自然言語での応答を生成します。この応答生成では、LLMの言語生成能力が活かされ、文法的に正しく、かつ文脈に即した自然な文章が生成されます。
生成された応答は、ユーザーに提示される前に、さらなる後処理が行われる場合があります。例えば、応答の文体を調整したり、不適切な内容をフィルタリングしたりすることで、より質の高い応答を提供できます。
検索と生成の反復によるインタラクティブな対話
RAGは、検索と生成のプロセスを反復的に行うことで、インタラクティブな対話を実現します。ユーザーからの追加の質問や要求に対して、RAGは再度関連情報を検索し、それを基に新たな応答を生成します。
この反復プロセスにより、RAGはユーザーとの対話を通じて、徐々に文脈を深く理解していきます。その結果、より的確で詳細な応答を提供できるようになります。
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
企業がRAGを導入する7つのメリット

RAGのメリットには、精度の高い回答を得られることや、最新の情報、オリジナルの情報を得られることなどが挙げられます。
リアルタイム、オリジナルな情報の反映
RAGは質問に応じてその都度外部データベースを検索するため、常に最新の情報を反映した回答を生成できます。また、自社独自の製品情報(製品に関するお問い合わせへの回答や操作サポートなど)に関する回答なども生成できます。
そのため、社内ヘルプデスク業務の大幅な効率化、自動化を期待できます。
関連記事:「RAGでヘルプデスクを効率化?対話型AIでは不十分な理由・導入メリット・活用事例を徹底解説!」
データ漏洩リスクの低減
LLMの学習データ、そしてユーザーの入力データに機密情報が含まれるとデータ漏洩のリスクが懸念されます。RAGは任意のデータベースから動的に情報を取得するため、学習データに依存せずに高精度な文章生成ができ、漏洩リスクを最小限に抑えられます。
関連記事:「生成AIの機密情報漏洩リスクはRAGで解決できる?メリットや強化策を徹底紹介!」
回答の精度の向上
RAGは、検索ベースと生成ベースのAIモデルの長所を組み合わせることで、より正確で関連性の高い回答を提供します。この技術は、外部データベースからの情報を取得し、その情報を基に質問やプロンプトに対する回答を生成するため、正確な情報を反映した精度の高い回答を生み出すことが可能です。
特に、変化が激しい分野の情報を得る際に役立ち、ユーザーのニーズに合わせたカスタマイズされた回答を生成できる点が大きなメリットです。
RAGをさらに発展させたGraphRAGでは、ナレッジグラフを活用して情報検索と生成を統合します。これにより情報間の関連性を明確にし、高度な推論と精度の高い回答生成が可能になります。
関連記事:「RAGの精度を向上させるには?チャンキングなど手法やメリット、低精度で運用するリスクを徹底解説!」
コスト削減
RAGは少ない学習データでも高精度なタスク実行が可能なため、ファインチューニングや追加学習に必要なデータ収集・アノテーションのコストを大幅に削減できます。
柔軟なカスタマイズと拡張性
従来のLLM(大規模言語モデル)の訓練には膨大なデータセットが必要でしたが、RAGを使用することで、既存の知識ソースを活用し、訓練データの収集と取り込みの必要性が減ります。RAGは検索対象とするデータベースを柔軟に選択・拡張できるため、企業ごとに最適なシステムを構築可能です。
また、新たなデータソースを追加することで、システムの能力を継続的に向上できます。
応答速度の向上
RAGモデルは、検索フェーズで文脈を絞り込むことにより、生成フェーズで処理が必要なデータ量を減らすことができます。これにより、応答速度が向上し、ユーザー体験が改善されます。
特に、顧客サポートやバーチャルアシスタントなどのアプリケーションでは、迅速な回答提供が求められるため応答速度の向上は大きな利点となります。
また、最新の情報やデータソースへのアクセスが実現することで、回答が正確かどうかをチェックしやすくなり、結果的に信頼性の保証にもつながります。
文脈に合わせた回答生成
抽出された情報は、生成モデルによって統合され、ユーザーの質問やプロンプトの文脈に沿った回答が生成されます。この過程では、人間のような自然な言葉遣いや文脈を反映した説明が可能になり、より理解しやすい回答の提供が可能です。
RAGによる回答は、ただの情報の要約ではなく、質問の意図を把握し、適切な情報を組み合わせることで形成されます。
RAGを活用した独自チャット(LLM)の構築方法
既存のLLM(大規模言語モデル)、例えばChatGPTにも使われているGPTなどを基に社内用のRAGシステムを構築する方法は以下の通りです。
この過程では、LlamaIndexのようなRAG特化型のフレームワークを活用することで、効率的に開発を進めることができます。
関連記事:「RAGを導入するまでの8ステップ!プロジェクトの進め方や技術選定のポイントも徹底解説!」
1. LLMの選定
GPTやClaudeなど、RAGシステムのベースとなるLLMを選定します。モデルの言語生成能力や対応言語、ライセンス条件などを考慮し、自社のニーズに最も適したものを選びます。
2. 検索エンジンの開発
社内データを検索するための検索エンジンを開発します。この際、LLMとの連携を念頭に置き、検索結果をLLMに入力しやすい形式で出力できるようにします。また、Rerankモデルを導入することで、検索結果の関連性と精度を向上させることができます。
LlamaIndexは高度なインデックス作成機能を提供し、効率的なデータ検索を可能にします。さらに、Rerankモデルとの統合も容易です。
3. 参照データの準備
RAG構築における参照データの準備は、AIが情報を正確に理解し、検索精度を高めるための重要な土台となります。
まず、社内文書やウェブページなど元となるデータを収集します。次に、不要なHTMLタグや定型文を除去するデータクリーニングを行い、情報を整理します。
続いて、長い文書をAIが扱いやすいサイズに分割するチャンキングを実行します。
最後に、分割したデータ(チャンク)を数値のベクトルに変換するベクトル化(Embedding)を行い、AIが意味的に近い情報を検索できるようにします。LlamaIndexのようなフレームワークは、これら一連の準備プロセスを自動化し、効率的なRAG構築を支援します。
4. 検索エンジンとLLMの連携
検索エンジンとLLMを連携させる仕組みを開発します。ユーザーからの質問をLLMで解析し、関連するキーワードを抽出して検索エンジンに渡します。検索結果をLLMに入力し、文脈に即した自然な応答を生成します。
LlamaIndexを使用すると、検索エンジンとLLMの連携が非常にスムーズになります。LlamaIndexは、ユーザーからの質問をLLMで解析し、関連するキーワードを抽出して検索を行い、その結果をLLMに入力して文脈に即した自然な応答を生成するプロセスを一貫して管理します。
5. LLMのファインチューニング(オプション)
必要に応じて、社内データを用いてLLMのファインチューニングを行います。これにより、社内特有の用語や文脈をより高度にLLMに学習させ、さらに適切な応答の生成が期待できます。
ただし、ファインチューニングには大量の計算リソースと時間が必要となります。
6. ユーザーインターフェースの開発
ユーザーとのやり取りを行うためのインターフェース(チャットボット、Web UIなど)を開発します。ユーザーの入力をLLMに渡し、生成された応答を適切に表示できるようにします。
7. テストと評価
システム全体の動作をテストし、応答の質や応答時間などを評価します。ユーザーによる実際の利用を想定したテストを行い、システムの改善点を洗い出します。
8. 運用とメンテナンス
システムの本番運用を開始したら、継続的なモニタリングとメンテナンスが必要です。ユーザーからのフィードバックを収集し、システムの改善につなげます。
また、LLMの更新や検索エンジンのインデックス更新など、定期的なメンテナンスも欠かせません。
既存のLLMを活用することで、自前でLLMを学習するよりも短期間かつ低コストでRAGシステムの構築が可能になります。ただし、LLMの利用条件や、検索エンジンとの連携における技術的な課題にも注意が必要です。
また、既存のLLMはあくまで一般的な言語生成モデルであるため、社内の特定ドメインに特化した応答を生成するには限界があります。高度なカスタマイズが必要な場合は、独自のLLMを学習することも検討に値します。
RAGシステムの構築は、自然言語処理や機械学習の知見を持つエンジニアとの協力が不可欠です。自社の技術力を見極め、必要に応じて外部の専門家やベンダーとの連携を図ることが重要でしょう。
関連記事:「LLMOpsとは?導入メリット・最適ツール、活用のコツを徹底解説」
企業でのRAG導入時の課題と解決策
RAGは強力な技術である一方で、導入・活用にはいくつかの課題が存在します。以下に代表的な課題とその解決策を表形式で整理しました。
| 課題カテゴリ | 具体的な課題 | 解決策 |
|---|---|---|
| データの品質と更新 |
|
|
| 精度と信頼性 |
|
|
| セキュリティとプライバシー |
|
|
| 組織的な変化への受容 |
|
|
| ベンダー選定と依存度の管理 |
|
|
このように、各課題に対して具体的な解決策を講じることで、RAG導入の成功率を高め、業務への定着をスムーズに進めることが可能です。
RAGについてよくある質問まとめ
- RAGはどんな仕組みですか?
RAGは、以下の3つのステップで動作する情報検索と言語生成を組み合わせたAI技術です。
- ユーザーの質問を解析し、ベクトル表現に変換
- ベクトル表現を使って外部データベースから関連情報を検索・抽出
- 抽出した情報を言語モデルに入力し、文脈に即した自然な応答を生成
この一連のプロセスを反復することで、RAGはユーザーとのインタラクティブな対話を実現します。
- RAGを活用するメリットは?
RAGを活用するメリットは以下の通りです。
- 常に最新の情報を反映した正確な応答が可能
- 少ない学習データでも高精度な文章生成を実現
- 学習データに依存しないため、データ漏洩リスクを低減
- 企業ごとに最適なシステムを柔軟に構築・拡張可能
- カスタマーサポートの自動化、社内ナレッジの活用、マーケティングの高度化など、様々な業務シーンで活用可能
RAGの導入により、企業はデータドリブンな意思決定を加速し、業務効率の向上と競争力の強化を実現できます。
- AI Marketでは、生成AI(RAG)を活用した業務効率化の相談は可能ですか?
はい、可能です。例えば製造業様からは、熟練者のノウハウを学習させたチャットボットで技術継承を支援したいというご相談を、製薬企業様からは、RAG(検索拡張生成)を用いて講演資料の法規制チェックを自動化したいとのご相談をいただいています。
AI Marketでは、お客様の独自データを活用できるRAG技術に強いパートナーをご紹介し、属人化した業務の効率化をご支援します。
まとめ
RAGは、LLMの課題を克服し、より実用的で拡張性の高いAIシステムを実現するための重要な技術です。情報検索とLLMを組み合わせることで、企業内外の膨大なデータを有効活用し、業務効率化と意思決定の高度化を推進することができるでしょう。
RAGの導入を検討することは、競争力強化につながる戦略的な選択肢の一つといえます。一方で、データガバナンスの強化やセキュリティ対策など、導入に向けた体制整備も欠かせません。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

