

【フィジカルAI向けデータもリリース】100万時間音声認識コーパス・800TB画像・動画データセットを自社版権で保有・販売し、カスタマイズしたデータ収集・アノテーションも一気通貫して提供しています。









サービス詳細
NexdataはAI学習用データサービスプロバイダーとして1万社以上の取引実績を積み上げてきました。
AIモデル開発に学習用データサービス(画像・動画、音声、テキストまたアノテーションサービス)をご提供することでAI開発に貢献するものです。
■サービス概要
1.お客様のニーズに応じて、顔識別・物体検出、スマートドライブ、自動翻訳・OCR、音声、LLM、自動運転、フィジカルAIなどあらゆる種類のデータセットを迅速に納品可能です。
2.専門的なデータ収集設備とツールを持つとともに、3つの大型データアノテーション基地を設置。顧客要望に合わせて柔軟にデータ収集・アノテーションを提供します。
3.独自開発した半自動アノテーションプラットフォームは、30セットの成熟したアノテーションツールを統合。ローカル搭載も可能でデータ資産の安全を守ります。
※AI学習用データの提供、カスタマイズによるデータ収集、独自のアノテーションツールといったニーズを一気通貫に対応可能。
お問い合わせ:contact@nexdata.ai
特長
1大規模なデータセットを迅速に納品可能
Nexdata(Datatang)は、お客様のニーズに応じて、最短一日でデータセット納品可能です。高精度・短納期によって、世界をリードするAI企業によって信頼されています。
人気データセット:
23,110 People Multi-race and Multi-pose Face Images Data
2,769 People - CCTV Re-ID Data in Europe
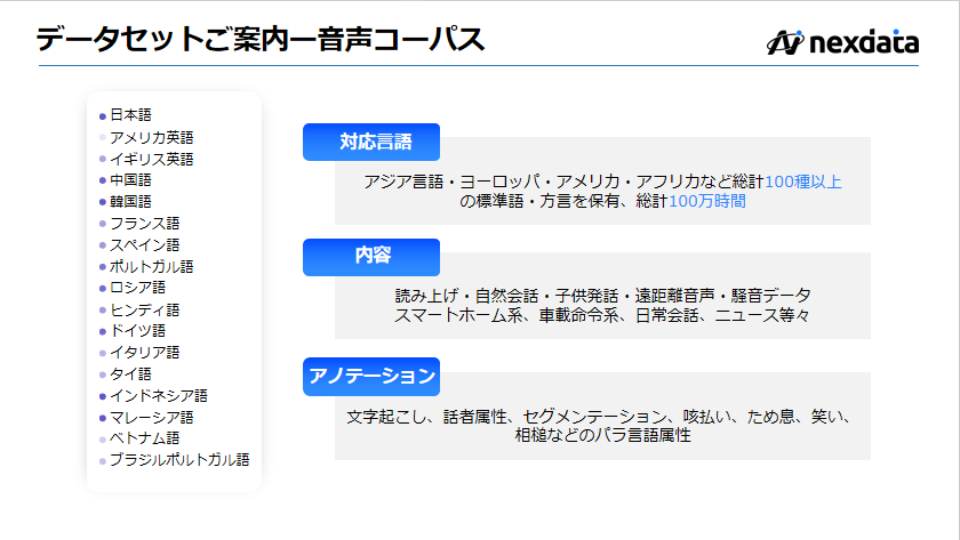
100時間日本語エンティティ音声読み上げデータセット
500時間日本語話者分離・LR分離音声対話データセット
200時間日本人英語音声対話データセット2AIアノテーション
様々なAI応用シーンに利用される多種多様なデータセット・データ収集・アノテーションニーズに対応し、短納期、高品質なサービスを1万社以上のAI大手会社に提供した実績があります。
データセット提供・カスタマイズ事例の一部:
百万枚顔認証・人体検出向け画像データセット提供
100万時間教師なし学習向け多言語音声コーパス提供
500時間ストリュートビュー動画データ収集
自動運転向け点群セグメン、物体追跡、BEV、4D点群、E2Eアノテーション
日本語/英語OCR画像データセット収集(帳票、手形、手書き文字)
LLM向け多言語試験問題解析データセット提供
100万LLM向け質問応答データ作成
3フィジカルAI・エンボディドAI向けデータ作成も可能
エンボディドAI専用の「データ収集センター」を複数設置しています。グローバル拠点としては、アメリカ、ドイツ、中国の3カ国で20箇所を展開しています。人型ロボット、マニピュレータ(アーム)、四足歩行ロボット(機械犬)など、70台以上もの多様なメーカー製ロボットを保有しており、家庭・工場・商業施設などさまざまな環境下で、物体把持、ナビゲーションと障害物回避、ヒューマン・ロボットインタラクションなどの複雑なタスクを実行可能です。
解決する課題
適切なデータが見つからないので、カスタマイズしたい
AIモデルを訓練するための学習用データがない・少ない
持っている学習用データの精度や品質が低い
持っているデータのアノテーションを外部に委託したい
どの学習用データが必要かわからない
短期間、大量で高品質なアノテーションをしたい
自社でアノテーションしたいが、管理機能の付いている適切なシステム、環境がない
その他提供会社コメント
データ収集・アノテーション作業が不要な既製データセットを直接納品可能です。データの高精度、短い納期に非常に感心です。そして、データセットからID抽出によりカスタマイズ納品も丁寧に対応して頂き、助かりました。
導入実績
・日本語・英語・フランス語など30万時間多言語音声認識・音声コーパス提供
・百万枚顔認証・人体検出向け画像データセット提供
・建築現場における人体識別用の画像収集及びアノテーション作業対応
・室内において人の動きや移動等識別データ収集対応
・100万フレーム自動運転向け点群セグメン、BEV、4D点群、E2Eデータ収集・アノテーション
費用
| 初期費用 | なし |
| 月額費用 | お問い合わせください |
| その他 | お問い合わせください |




