
【AI論文解説】LLM2CLIP: Powerful Language Model Unlock Richer Visual Representation:LLMの力でCLIPの限界を超えるLLM2CLIP
最終更新日:2024年11月14日

本論文は、画像とテキストのマルチモーダル表現学習を向上させる新しいアプローチ「LLM2CLIP」を提案しています。
従来のCLIPモデルは、画像とテキストを共有の特徴空間に整列させるために大規模な画像テキストペアで学習されましたが、長文や複雑なキャプションの処理に限界がありました。
本研究では、LLM(大規模言語モデル)の知識を取り入れることでこれらの制限を克服し、特に長文や複雑なキャプションの処理能力を大幅に向上させるとともに、ゼロショット分類やクロスモーダル検索などのタスクで顕著なパフォーマンス向上を実現しています。
- 論文名:LLM2CLIP: Powerful Language Model Unlock Richer Visual Representation
- 論文著者:Weiquan Huang, Aoqi Wu, Yifan Yang, Xufang Luo, Yuqing Yang, Liang Hu, Qi Dai, Xiyang Dai, Dongdong Chen, Chong Luo, Lili Qiu|Tongji University, Microsoft Corporation
- 論文提出日:2024年11月7日
- 論文URL:https://arxiv.org/abs/2411.04997
論文の要約
この研究は、画像とテキストを結びつけるモデルであるCLIPをさらに強化するために、LLMの能力を活用しています。
従来のCLIPは、長いテキストや複雑なキャプションを扱うのが苦手だったため、研究者たちはLLMを微調整してテキストの理解力を高め、それを用いてCLIPの視覚部分を再訓練しました。
その結果、画像と言語をより深く結びつけることができ、多くのタスクで性能が向上しました。
ポイント
- LLMをCLIPに統合することで、長文キャプション処理の限界を克服
- キャプションコントラスト学習によるLLMの出力特徴の識別力向上
- CLIPのビジュアルエンコーダとLLMを効率的に組み合わせ、クロスモーダルタスクのパフォーマンスを向上
論文研究内容詳細
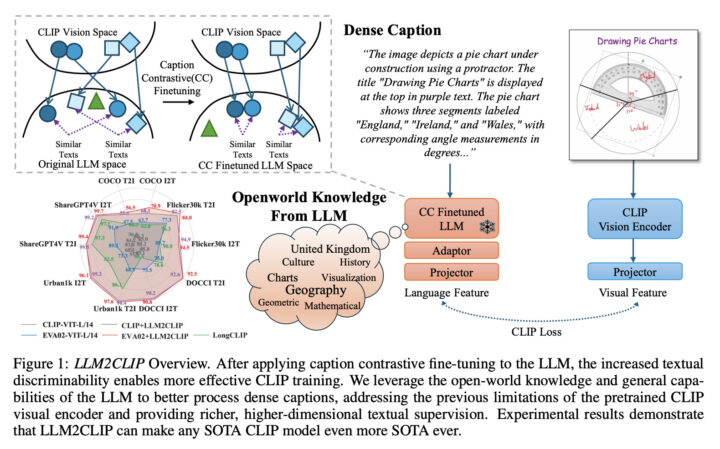
本研究は、画像と言語の関係性を学習するマルチモーダルモデルであるCLIPに対して、LLMの強力な言語理解能力とオープンワールドの知識を統合することで、視覚表現の質を大幅に向上させる試みです。
従来のCLIPは、画像と言語のペアを用いてコントラスト学習を行い、視覚と言語の表現を共有の特徴空間にマッピングしますが、そのテキストエンコーダはモデルサイズやコンテキスト長に制約があり、長いキャプションや複雑なテキストを十分に扱えませんでした。
本研究では、まずLLMがそのままではCLIPのテキストエンコーダとして適切に機能しない原因を分析しました。その結果、LLMの出力特徴がテキスト間の識別性に欠けており、これはLLMが主に次の単語を予測するために最適化されているためであると判明しました。
そこで、キャプションコントラスト学習(Caption Contrastive Fine-tuning)という新しい微調整手法を開発し、LLMの出力特徴の識別性を高めました。具体的には、同じ画像に対する異なるキャプションを正例として扱い、それ以外のキャプションを負例としてコントラスト学習を行います。
この微調整されたLLMを用いて、CLIPのビジュアルエンコーダを再訓練します。LLMの強力な言語理解能力とオープンワールドの知識が、ビジュアルエンコーダに豊富な情報を提供し、長く複雑なキャプションを扱えるようになります。
実験では、さまざまなクロスモーダルタスクで性能を評価し、既存の最先端モデルを大幅に上回る成果を達成しました。
先行研究との比較
従来の研究では、CLIPのテキストエンコーダの限界を克服するために、さまざまな手法が提案されてきました。しかし、これらの手法はモデルサイズの制約やテキストのコンテキスト長の制限を完全には解決できていませんでした。
また、LLMを直接CLIPに組み込もうとする試みもありましたが、LLMの出力特徴が識別性に欠けるため、性能が低下するという問題がありました。
本研究の革新性は、LLMの出力特徴の識別性の欠如という根本的な問題をキャプションコントラスト学習によって解決した点にあります。これにより、LLMの強力な言語理解能力とオープンワールドの知識を効果的にCLIPに統合することが可能となりました。
その結果、長いテキストや複雑なキャプションを扱う能力が飛躍的に向上し、クロスモーダルなタスクで既存の最先端モデルを大幅に上回る性能を達成しています。
さらに、提案手法は効率的であり、CLIPの再訓練において追加の計算資源を大幅に必要としません。これは、LLMの微調整をLoRA(Low-Rank Adaptation)という効率的な手法で行い、CLIPのビジュアルエンコーダの再訓練時にはLLMの勾配を固定することで実現しています。
本論文のキモ
本研究の技術的な核心は、以下の2つのステップにあります。まず、LLMの出力特徴の識別性を高めるために、キャプションコントラスト学習を適用します。
具体的には、MS COCOなどのデータセットから同じ画像に対する複数のキャプションを正例ペアとして選び、それ以外のキャプションを負例とします。そして、LLMを微調整し、同じ画像のキャプションが近くなるように、異なる画像のキャプションが遠ざかるように学習させます。
次に、微調整されたLLMを教師モデルとして、CLIPのビジュアルエンコーダを再訓練します。この際、LLMの勾配を固定することで、計算資源を節約しつつ、LLMのオープンワールド知識をビジュアルエンコーダに効果的に伝達します。
また、LLMとビジュアルエンコーダの出力次元を合わせるためのプロジェクション層を設け、コントラスト学習を効率的に行えるように設計しています。
このプロセス全体で重要なのは、LLMの強力な言語理解能力をビジュアルエンコーダに反映させる点と、長いキャプションや複雑なテキストをそのまま扱えるようにする点です。従来の手法では、長いテキストを扱うためにモデルのアーキテクチャを変更する必要がありましたが、LLM2CLIPではその必要がありません。
検証方法・結果
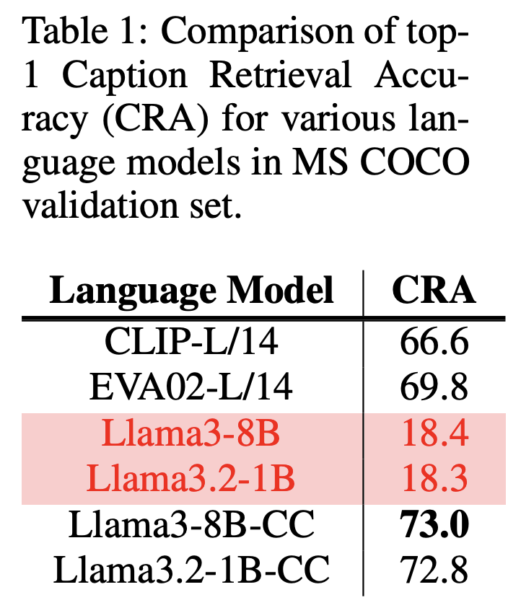
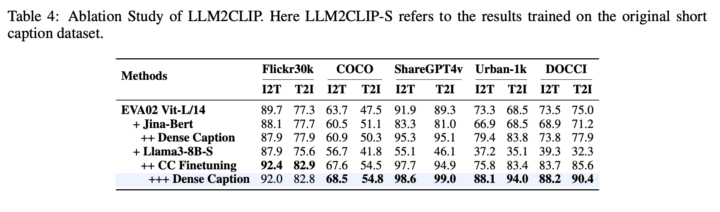
提案手法の有効性は、多角的な実験によって検証されました。まず、キャプションコントラスト学習の効果を確認するために、MS COCOデータセットを用いてキャプションからキャプションへの検索実験を行いました。
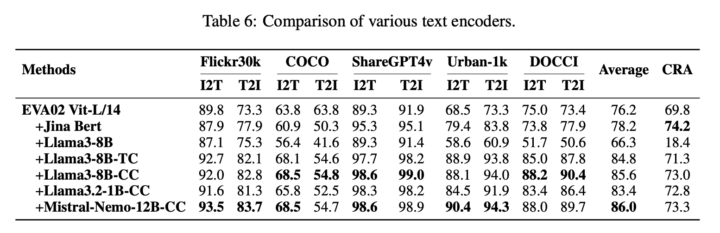
結果として、微調整前のLLMのキャプション検索精度(CRA)は18.4%と低かったのに対し、微調整後は73.0%に大幅に向上しました。
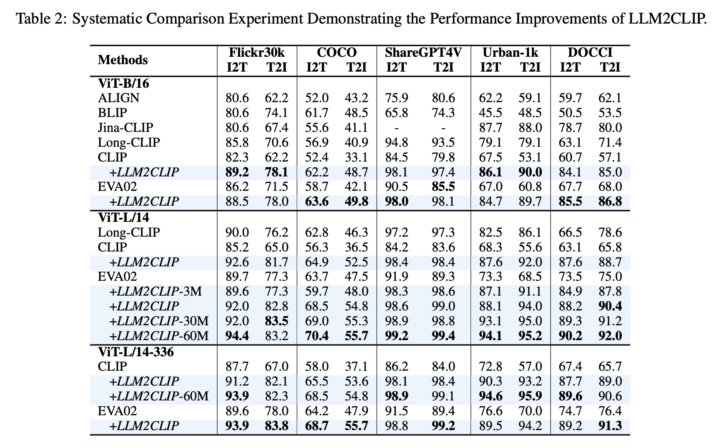
次に、微調整されたLLMを用いてCLIPのビジュアルエンコーダを再訓練し、さまざまなクロスモーダルなタスクで性能を評価しました。
Flickr30kやCOCOといった一般的なデータセットでの画像と言語の相互検索、長いテキストを含むShareGPT4VやDOCCIデータセットでの性能評価、さらに中国語のデータセットであるFlickrCNやCNCOCOでの評価も行われました。
提案手法は、既存の最先端モデルであるEVA02やCLIPを大幅に上回る性能を示しました。
さらに、LLM2CLIPを用いてマルチモーダル大規模言語モデル(MLLM)であるLLaVA 1.5の訓練も行われ、複雑な画像理解タスクで性能向上が確認されました。
これらの結果は、提案手法が幅広いタスクで有効であることを示しています。

LLM2CLIPについてよくある質問まとめ
- LLM2CLIPとはなんですか?
LLMの強力な言語理解能力を活用して、CLIPの視覚表現学習を向上させる新しい手法です。
具体的には、LLMをキャプションコントラスト学習で微調整し、その微調整されたLLMを教師モデルとしてCLIPの視覚エンコーダを再訓練します。
これにより、長く複雑なキャプションを効果的に処理でき、クロスモーダルなタスクでの性能が大幅に向上します。
- LLM2CLIPはどのようにしてCLIPの性能を向上させるのですか?
まず、LLMにキャプションコントラスト学習を施し、テキストの識別能力を高めます。
これにより、LLMの出力特徴空間で異なるキャプションが明確に区別できるようになります。
その微調整されたLLMを教師モデルとして、CLIPの視覚エンコーダを再訓練します。LLMのオープンワールド知識と長いテキストの理解力が、視覚エンコーダに豊富な情報を提供し、結果としてCLIPの性能が大幅に向上します。
継続的な課題・議論
本研究は、LLMの強力な言語理解能力を視覚領域に拡張する新たな方向性を示していますが、いくつかの課題や議論も残されています。
まず、LLMとCLIPの最適な統合方法については、さらなる研究が必要です。特に、LLMの勾配を固定せずにCLIPと共同で学習させる方法や、計算資源とのバランスをどう取るかといった点が挙げられます。
さらに、LLM2CLIPをゼロから再訓練する場合の効率性や、他のマルチモーダルモデルへの応用可能性についても議論の余地があります。
他のタスクやドメインで同様の効果が得られるか、またLLMの持つオープンワールドの知識をどのように最適に活用できるかといった点も、今後の研究課題となります。
AI Marketでは、
下記の記事も一緒によく読まれています
 【AI論文解説】CLEAR: Character Unlearning in Textual and Visual Modalities:マルチモーダルAIにおける『忘れる技術』を評価する新たなベンチマークデータセット
【AI論文解説】CLEAR: Character Unlearning in Textual and Visual Modalities:マルチモーダルAIにおける『忘れる技術』を評価する新たなベンチマークデータセット  【AI論文解説】OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models:全てを公開したトップクラスのコード生成モデル
【AI論文解説】OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models:全てを公開したトップクラスのコード生成モデル  【AI論文解説】HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems:HTMLそのものを活用し、LLMの知識強化を革新する新手法『HtmlRAG』の提案
【AI論文解説】HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems:HTMLそのものを活用し、LLMの知識強化を革新する新手法『HtmlRAG』の提案  【AI論文解説】Differential Transformer:重要な情報だけを引き出す新型Transformer「Diff Transformer」
【AI論文解説】Differential Transformer:重要な情報だけを引き出す新型Transformer「Diff Transformer」  Diffusion model(拡散モデル)とは?仕組み、GANやVAEとの違い、企業導入メリット、活用シーンを徹底解説!
Diffusion model(拡散モデル)とは?仕組み、GANやVAEとの違い、企業導入メリット、活用シーンを徹底解説!
AI Marketの編集部です。AI Market編集部は、AI Marketへ寄せられた累計1,000件を超えるAI導入相談実績を活かし、AI(人工知能)、生成AIに関する技術や、製品・サービス、業界事例などの紹介記事を提供しています。AI開発、生成AI導入における会社選定にお困りの方は、ぜひご相談ください。ご相談はこちら
𝕏:@AIMarket_jp
Youtube:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

