
ChatGPTでRAGを活用する方法は?課題や実装方法、活用事例、注意点を徹底解説!
最終更新日:2026年06月04日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

多くの企業がChatGPTの活用を進める中で、機密情報の取り扱いやハルシネーションといった課題に直面しています。特に、顧客情報や社内の機密データを扱う部門では、情報漏洩のリスクから活用を見送らざるを得ないケースも少なくありません。
しかし、RAG(検索拡張生成:Retrieval-Augmented Generation)という手法を活用することで、これらの課題を解決できる可能性が広がっています。すでに多くの企業がRAGを活用し、業務効率の向上を実現しています。
本記事では、
ChatGPTの活用を検討している企業担当者はぜひ最後までご覧ください。
ChatGPTとはなにか、機能や使い方事例をこちらの記事で、LLM(大規模言語モデル)についてはこちらで詳しく説明していますので併せてご覧ください。
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
ChatGPT/LLM導入・カスタマイズに強いAI開発会社を自力で選びたい方はこちらで特集していますので併せてご覧ください。
目次
ChatGPTの企業導入を阻む課題をRAGが解決できる?
RAGは、ChatGPTが直面する主要な課題を解決するのに役立ちます。以下では、ChatGPTが持つどのような課題をRAGで解決できるかについて解説します。ファインチューニングやプロンプトエンジニアリングなど、他のLLM拡張手法との比較も説明します。
情報漏えいのリスク
RAGを使用することで、機密情報や重要なデータを外部に送信せずに、社内のデータベースから情報を取得し、それを基に回答を生成することは可能です。そのため、社内情報の漏えいリスクを抑えられます。
多くの企業ではChatGPTをAPI連携で利用していまる。APIセキュリティ対策を施していない場合には、API経由で企業や顧客の機密情報が外部へ流出するリスクもあります。
そのため、ChatGPTを利用する場合には、情報漏えいリスクを避けるため、適用できる範囲が限定されます。
そのため、RAGの導入により、情報の取り扱いにおいて柔軟性が向上し、社内の幅広い業務へ活用が可能となります。
関連記事:「ChatGPTは安全なのか?情報漏洩が起きる原因や情報漏洩を防ぐためのポイントを説明」
最新情報の欠如
ChatGPT(に限らずすべてのAI)は学習データに依存しており、古い情報に基づいた誤った回答を出力する可能性があります。定期的に学習されるとはいえ、金融業界など最新の情報提供が求められる業界では課題となります。
一方、RAGでは、社内にある最新の業界レポートやプレリリース情報などの新しい情報を直接参照し、常にリアルタイムで、オリジナルな情報をもとにした回答が可能です。そのため、RAGの導入により、最新の業界動向や製品情報に対しても、正確な情報提供を行えるようになります。
ファインチューニングでは、モデル全体を再学習させるため、大量のデータと計算リソースが必要です。また、新しい情報を追加するたびにモデルを再学習させる必要があり、時間とコストがかかります。
プロンプトエンジニアリングを駆使しても、モデルの既存知識に依存するため、最新情報や専門的な知識を反映させるのは困難です。
RAGはモデル自体を再学習させる必要がなく、最新且つオリジナルな情報を迅速に反映できます。
尚、2024年11月にOpenAIが新たに提供を開始した「ChatGPT Search」では、最新情報を参照した回答が可能になっていますが、あくまで一般公開されているWebニュースを情報源としているため、企業独自の最新情報を反映することはできません。
関連記事:「ChatGPTの回答精度を上げる方法は?RAGの活用方法・プロンプト設計のコツも徹底解説!」
ハルシネーション
ChatGPTは、「ハルシネーション」と呼ばれる正しくない情報をあたかも正しいように回答することがあります。
ハルシネーションは、学習範囲外などが原因で情報が見つからない場合に見られる現象です。情報の信頼性が低下することから、医療分野など正確な回答が求められるシーンにおいて適用が限定されます。
プロンプトエンジニアリングだけでは、モデルの回答の一貫性や事実的正確性を完全に制御するのは困難です。
一方、RAGでは、連携された社内のデータベース内からの情報を参照するため、ハルシネーションの発生を防ぎ、信頼性の高い回答を提供することが可能です。この情報の透明性により、従業員が提供された情報を信頼しやすくなり、ChatGPT活用の頻度と幅をより広げられます。
関連記事:「ChatGPTでハルシネーションを抑制する対策は?すぐ使えるプロンプト例・最新機能を活用した対策方法を徹底解説!」
専門性の低さ
ChatGPTは「パソコンの電源をつける方法」など普遍的な質問に対しては対応できる一方で、医療や金融など専門的な質問には十分に回答できない場合があります。
その点、RAGでは、社内に蓄積された特定業務のマニュアルや問い合わせ例を参照し、「製品の具体的な操作方法」など業務や専門分野に特化した質問にも的確に回答することが可能です。
ファインチューニングは、特定のドメインに特化しすぎて汎用性を失わせる可能性があります。RAGは基本的なLLMの能力を維持しながら、必要に応じて外部知識を活用しますので、特定ドメインの専門性と一般的な言語理解のバランスを取ることができます。
RAGにより、特化型AIソリューションとしてのChatGPTの利用価値がさらに向上します。
ファインチューニング・プロンプトエンジニアリング・RAGの比較一覧
以下の表は、ファインチューニング・プロンプトエンジニアリング・RAG、各手法の主な特徴、課題、メリットを比較しています。
RAGは多くの面で他の手法よりも優れていますが、外部データの信頼性に依存するという課題もあります。実際の適用では、これらの手法を組み合わせて使用することも多く、特定の用途や要件に応じて最適な方法を選択することが重要です。
関連記事:「RAGとファインチューニングの違いは?システム開発の工数・コスト・効果を徹底比較!」
| 特性 | ファインチューニング | プロンプトエンジニアリング | RAG |
|---|---|---|---|
| 柔軟性 | 低(再学習が必要) | 高(プロンプト変更のみ) | 高(新情報を容易に統合) |
| コスト効率 | 低(大量のデータと計算リソースが必要) | 高 | 高(再学習不要) |
| 最新情報の反映 | 困難(再学習が必要) | 困難(既存知識に依存) | 容易(外部データベースを更新) |
| 専門性 | 高(特定ドメインに特化) | 中 | 高(外部知識を活用) |
| 汎用性 | 低(過適合のリスク) | 中 | 高(基本的なLLM能力を維持) |
| 透明性 | 低 | 中 | 高(情報源の追跡が容易) |
| 実装の複雑さ | 高 | 中 | 中~高 |
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
ChatGPTにRAGを導入する方法

ChatGPTにRAGを直接組み込む方法はOpenAIから提供されていませんが、以下のような方法でRAGを実装することが可能です。
- OpenAIが提供するGPTのAPIを利用してチャットボットを構築し、ChatGPTライクな環境を作成する
- OpenAIが提供する「EmbeddingモデルAPI」を活用して社内文書や関連情報をベクトル変換する
- 外部データベース検索(RAG)を行う
- 検索した情報を元に回答を行う
Python言語とLangChainなどのライブラリを使用すると効率的に実装できますが、実際のところは回答精度を上げる手法などが比較的複雑で、専門的な知識が必要です。
尚、社内情報を扱う際は、適切なアクセス制御と暗号化を実施することが重要です。
ユーザーとの応答の仕組み
ユーザー側から見た場合は以下の仕組みでRAGを活用した応答が出力されます。
- ユーザーの質問をベクトル化
- ベクトルデータベースから関連情報を検索
- 検索結果とオリジナルの質問をAPIに送信
- APIからの回答を生成・表示
関連記事:「ベクトル検索の仕組みから実装方法、さらに具体的な活用事例まで徹底解説」
社内知識機能(Company knowledge)を使う方法も
ChatGPTの法人向けプラン(Enterpriseなど)で提供される「Company Knowledge」機能は、まさにこのRAGをノーコードで導入する最もシンプルな方法です。ユーザーはSlack、Google Drive、GitHub、SharePointなどの業務アプリを接続するだけで、セキュリティとアクセス権限を保持したまま、ChatGPTに社内の知識を与えられます。
Company knowledgeにより、LLMが最新かつ正確な社内情報に基づいて回答するようになり、情報の信頼性が飛躍的に向上し、意思決定の質と速度を高めることが可能です。
関連記事:「ナレッジマネジメントとは?AI Marketに実際に寄せられた相談事例、重要手法・生成AI(RAG)を活用するメリットを徹底解説!」
ChatGPT×RAGの活用事例
ChatGPTの企業活用ニーズが高まる中で、ChatGPTを搭載したRAGサービスの提供が増えつつあります。以下では、ChatGPTとRAGを組み合わせて活用している企業事例について紹介します。
ChatGPT以外でも多くあるRAG活用事例をこちらの記事で詳しく説明していますので併せてご覧ください。
【味の素/ナレッジセンス】新レシピ開発など食品業界ならではの業務に活用
味の素冷凍食品では、本格的に社内のDXを推進する中で、セキュアな環境でChatGPTを利用できるナレッジセンス社の「ChatSense」を導入しました。社内データをChatGPTに学習させる「追加学習(RAG)」機能を利用して、業務のノウハウや注意点を学習させ、従業員をサポートするAIを作成しました。
RAGを通じて社内に蓄積された知見やノウハウを活用することで、生産性向上につなげています。
2024年8月時点で、社内の半数以上が業務へ生成AIを活用しており、今後さらに拡大予定です。特に研究開発部門では、生成AIを活用して新レシピの開発や評価結果の分析など、食品業界特有の業務を効率化しています。
【くすりの窓口/クラスメソッド】RAG技術を活用した生成AI チャットボットを導入
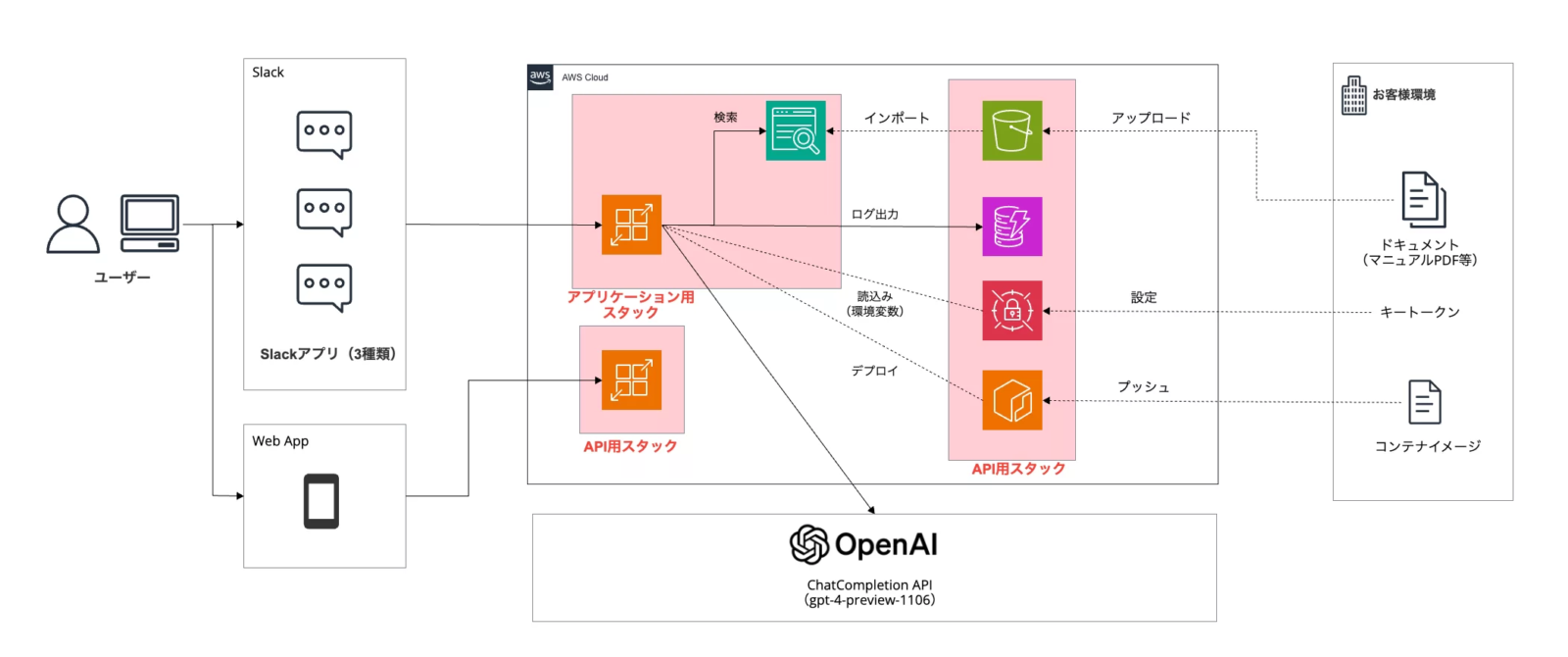
株式会社くすりの窓口では、専門用語やオペレーションが異なる複数のサービスに対応する中で、従業員の理解度により顧客からの問い合わせに対する回答の質の差に課題がありました。
そこで、RAG技術搭載の生成AI チャットボットをPoC検証用として社内へ導入しました。クラスメソッド株式会社が開発したチャットボットにはサービスの操作マニュアルなどを集約しています。
複数ある基盤モデルからOpenAIのGPTモデルを採用し、AWS(Amazon Web Services)上でセキュアな環境を構築しています。
従業員はまずAI チャットボットから精度の高い回答を得て、それをもとに顧客に回答することで、正確さを向上させています。
今後は製品の操作マニュアル不足やAIが最適解を出せていない点を改善し、2024年には新人教育用の生成AI チャットボットとして社内ローンチする予定で検討しています。
【京都トヨペット/SELF】社内問い合わせ対応を削減
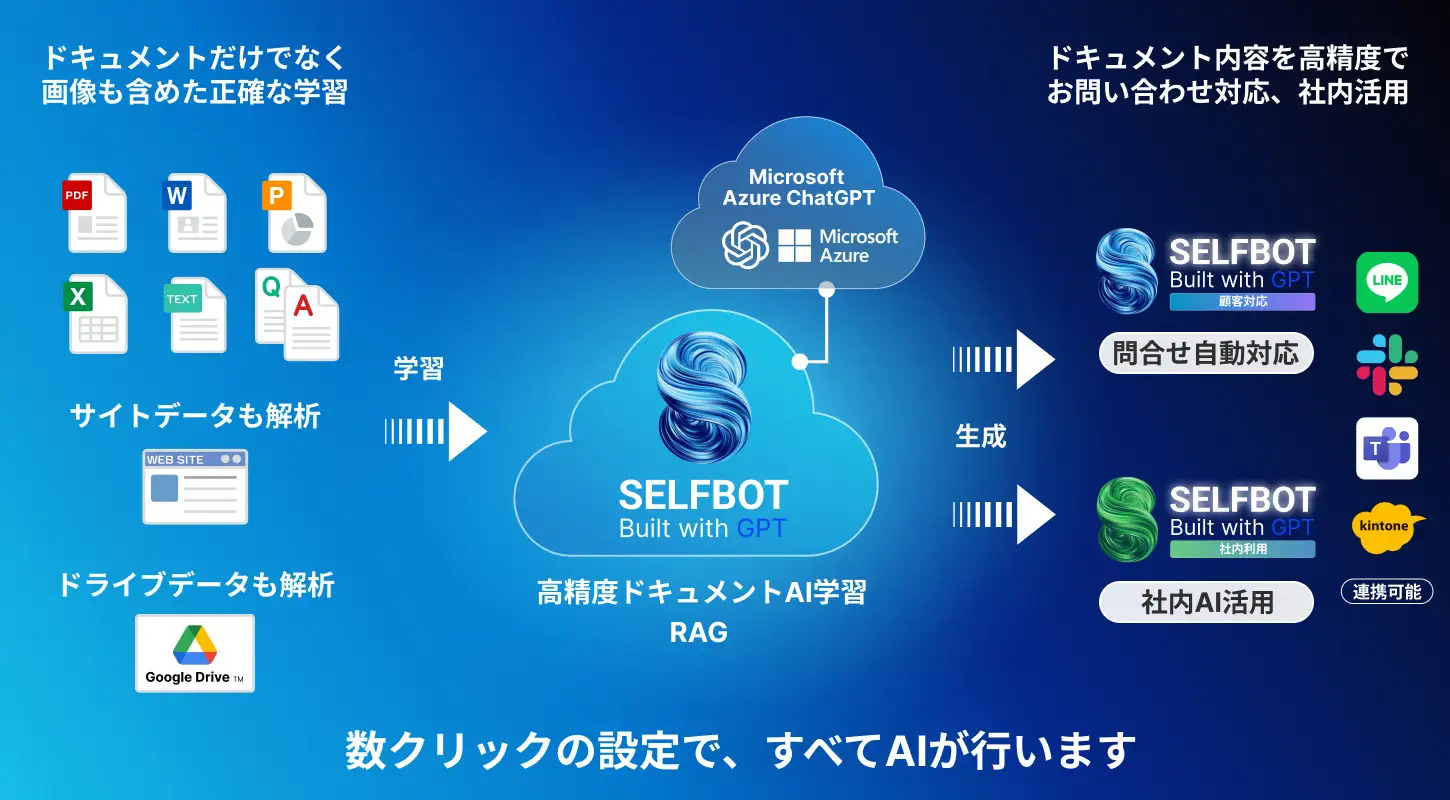
京都トヨペットは、DXツールの導入や制度改革を積極的に進める中で、本部への問い合わせの増加や従業員における理解の浸透が課題となっていました。そこで、社内問い合わせや資料検索にかかる工数削減を目指し、RAG技術を活用したChatGPTライクのチャットボット「SELFBOT」を導入しました。
SELF株式会社が開発したSELFBOTは、学習した各部署が扱うURLや社内文書、QAなどの膨大なリソースをもとに、効率的に情報を検索・高精度で回答できるチャットボットです。
これにより、従業員と本部双方の問い合わせ対応が大幅に軽減され、従業員満足度と生産性向上に大きく寄与しています。
【WOWOW/Exa Enterprise AI】社内規定など自社データの活用にも取り組む
株式会社WOWOWでは、アイデア出し・プログラミング相談・英語の翻訳・ミーティングの議事録作成など幅広い業務で、株式会社Exa Enterprise AIが開発した「exaBase 生成AI」を活用し、生産性の向上を実現しています。RAG技術を活用した自社データの利用にも取り組み始め、「作業支援」と「社内の規定集」において積極的に活用しています。
例えば、作業支援への活用を目的としたテストでは、公開資料を生成AIに読み込ませ、プロンプトを経て人と同等の作業結果を出すことに成功しています。複雑な資料作業に取り掛かる際の心理的負担を軽減し、効率的に作業を進められることが期待されています。
また、社内の規定集への活用においては、膨大な社内規定を取り込んだ生成AIがガバナンス関連の電子研修で最適解を出力するなど、実用レベルの正確性が確認されました。
今後は全従業員向けにAIの検索窓口をリリースし、さらなる業務効率化を目指します。
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
ChatGPTにRAGを実装する際の課題

RAGによりChatGPTの活用領域を拡大できる一方で、RAGにも活用するうえで課題が存在します。
以下では、RAGの課題を紹介します。また、それぞれの課題に対する有効な解決法についても簡単に解説します。
参照するデータベースへの依存
RAGは外部データベースから情報を取得するため、そのデータの質が応答の質に直結します。社内の信頼性の低いデータを使用すると、逆に誤った情報が生成されるリスクが高まります。
また、データベースの更新頻度が低く、古い情報しかない場合には最新情報を反映した回答ができなくなる点も課題の一つです。
そのため、RAGを効果的に活用するうえでは、データを精査したうえで定期的にデータを更新することで、連携するデータベースの信頼性を確保することが重要です。
そのためには、データの整合性や品質を維持するための監査プロセスを導入する必要があります。
関連記事:「RAGの精度を向上させるには?チャンキングなど手法やメリット、低精度で運用するリスクを徹底解説!」
実装の複雑さ
RAGの実装には、企業が保持するデータベースや情報ソースの統合の調整や、データの整合性を保つためのデータクレンジングやデータ構造の最適化が必要です。また、2024年10月現時点ではChatGPTへRAGを直接組み込む方法が確立されていないため、実装が複雑化している点も課題です。
そのため、RAGを組み込むには時間やリソースがかかるうえに、AI開発やデータを扱うための専門的な知識が求められます。RAG開発に必要な専門性を持つAIエンジニア・データベースエンジニアを確保できない場合には、RAGのスムーズな導入が難しくなります。
専門外の企業がRAGを実装するうえでは、データベース管理やベクトル検索技術に関するスキルを持つ外部の専門家や技術パートナーとの協力が推奨されます。
応答時間の長さ
RAGシステムでは、ベクトルデータベースを経由して検索した情報をもとに回答を生成するため、応答時間が生成AIよりも長くなる傾向にあります。そのため、社内の基幹システムのトラブル解決など回答のスピードが重視される場合には、活用が難しくなります。
応答時間を短縮するためには、効率的なインデックス作成やクエリ最適化の技術が必要です。また、応答の高速化には、ハードウェアの性能やデータベースの構造も重要な要素となります。
例えば、キャッシュメカニズムを活用して頻繁に使用されるデータへ迅速にアクセスできるようにすることや、並列処理を活用してクエリの処理速度を向上させることも効果的です。
セキュリティ対策の必要性
ChatGPTにRAG(Retrieval Augmented Generation)を実装することで新たなセキュリティ課題も生じさせます。
主な課題は、RAGがアクセスする「知識ベース」の管理です。まず、この知識ベースへのアクセス制御が不適切だと、機密情報や個人情報が権限のないユーザーに意図せず開示されてしまう情報漏洩リスクがあります。
次に、知識ベースに悪意のある情報や誤情報が混入(データポイズニング)した場合、ChatGPTがそれを基に不正確または有害な回答を生成する可能性があります。さらに、巧妙なプロンプト(指示)により、本来アクセスが許可されていない知識ベース内の情報を不正に引き出そうとするプロンプトインジェクション攻撃のリスクも無視できません。
これらのリスクに対応するため、RAGを実装する際には、知識ベースへの厳格なアクセス権限管理、入力されるプロンプトの検証、参照データの信頼性確保、そしてLLMからの出力内容のフィルタリングといった、RAG特有のセキュリティ対策を講じることが不可欠です。
ChatGPTとRAGについてよくある質問まとめ
- ChatGPTとRAGを組み合わせることでどのような課題が解決されますか?
ChatGPTの知識更新の遅さやハルシネーションの問題をRAGによって解決できます。社内のデータベースから最新情報を取得することで、正確な応答が可能になります。
- どのような業界でChatGPTとRAGの組み合わせが有効ですか?
顧客対応やサポート業務が多い業界、たとえば小売業・金融業・ヘルスケアなどで有効です。顧客からの質問に対して最新の情報を提供できるため、顧客満足度の向上に寄与します。
- RAGを導入して情報漏洩のリスクは完全になくなりますか?
RAGにより社内データを外部に送信せずに利用できますが、システムの設計や運用方法によってはリスクが残る可能性があります。適切なアクセス制御や監査の仕組みを併せて検討することが重要です。
まとめ
RAGは、企業におけるChatGPT活用の可能性を大きく広げる手法です。社内のデータベースから情報を網羅的に取得し、生成プロセスに活用することで、ChatGPTの課題を解決します。
この機会にRAGを導入し、ChatGPTのパフォーマンスを最大限に引き出して、ビジネスの競争力をさらに高めてみてはいかがでしょうか。
しかし、効果的な導入のためには、データベースの整備や技術的な実装など、複数の課題をクリアする必要があります。特に、ベクトル検索技術を活用したシステム構築、応答速度の最適化については専門家との連携が推奨されます。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

