
ベクトル検索とは?仕組み・LLMでの役割・実装方法・活用事例を徹底解説!
最終更新日:2026年06月25日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

生成AI(ジェネレーティブAI)、特にLLM(大規模言語モデル)の活用が進む中で、ベクトル検索が注目されています。従来の検索手法を超える精度と速度で、LLMのビジネス活用を強く後押ししています。
テキスト、画像、音声など、多様なデータを意味的に理解し、最適な情報を迅速に提供するベクトル検索技術は、Eコマース、製造業、金融など、様々な業界で既に具体的な成果を上げています。企業が保有する膨大なデータから、いかに実用的な価値を引き出すか。ベクトル検索が答えとなるかもしれません。
本記事では特にLLMで多用される
AIを活用した先進的な検索手法で、貴社のデータ活用戦略を一歩先へ進めましょう。
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
LLM・RAG開発が得意なAI開発会社について知りたい方はこちらで特集していますので、併せてご覧ください。
目次
ベクトル検索とは?

ベクトル検索は、テキストや画像などのデータをベクトル(数値の配列)に変換し、類似性を数学的に計算することで情報を効率的に検索する技術です。
従来のキーワードベースの検索とは異なり、データの意味や文脈を考慮した検索が可能となります。また、画像や音声などの非構造化データからも意味とコンテキストを取り込み、数値表現に変換して統一的に扱えるのが大きな特徴です。
データのベクトル化にはディープラーニングモデルが用いられます。ベクトル検索の登場により、企業は膨大な社内データを効率的に活用し、業務効率の向上や意思決定の迅速化を実現できるようになりました。
キーワードマッチングからセマンティック検索への進化
検索技術は、単純なキーワードマッチングからセマンティック検索へと進化してきました。この進化により、ユーザーの意図をより正確に理解し、関連性の高い検索結果を提供することが可能になりました。
従来のキーワード検索では、入力された単語と完全に一致する情報のみが検索結果として表示されていました。しかし、この方法では同義語や関連概念を含む重要な情報を見逃す可能性がありました。そこで登場したセマンティック検索は、検索クエリの意味や意図を理解し、関連性の高い情報を提供します。
これにより、ユーザーは求める情報により簡単にアクセスできるようになりました。
ベクトル検索技術を用いることで、テキストや画像などのデータを多次元のベクトル空間に変換し、意味的な類似性を数学的に計算することが可能になりました。これにより、より高度なセマンティック検索が実現されています。
また、ディープラーニングの発展により、自然言語処理技術が飛躍的に向上しました。これにより、検索エンジンはユーザーの検索意図をより正確に理解し、適切な検索結果を提供できるようになりました。
関連記事:「セマンティック検索とは?AI搭載検索エンジンの企業活用例・メリット・使える業界を徹底解説!」
LLMとRAGにおけるベクトル検索の重要性
LLM(大規模言語モデル)とRAG(検索拡張生成:Retrieval-Augmented Generation)の分野において、ベクトル検索は非常に重要な役割を果たしています。
ベクトル検索は、LLMの性能向上に以下のように大きく貢献します。
| ベクトル検索によるLLMへのメリット | メリットの内容 |
|---|---|
| 意味的理解の向上 | ベクトルデータベースは単語や文章の意味関係を捉えた埋め込みを保存します。これによりLLMはテキストの文脈や意味をより深く理解できます。 |
| 効率的な類似性検索 | ベクトル表現を用いることで、LLMは関連情報を高速に検索できます。これは情報検索やレコメンデーションシステムなどのタスクで特に有用です。 |
| 転移学習の促進 | 事前学習済みの単語埋め込みや文脈化された埋め込みを活用することで、LLMの言語理解能力を向上させることができます。 |
ベクトル検索はクエリの意味を理解し、文脈に応じた検索結果を提供します。これにより、LLMはユーザーの意図をより正確に把握し、適切な回答を生成することが可能になります。
関連記事:「LLMとは?ChatGPTとの違いは?ビジネス活用方法・種類・代表サービスを徹底解説!」
また、RAGを使用することで、外部のベクトルデータベースから最新の情報を取得し、より正確な回答を提供できます。
RAGは、LLMと外部のデータベースを組み合わせる技術です。外部情報を効率よく取り入れることで、より正確で多様な回答を生成できます。これはLLMの幻覚(hallucination)問題の軽減にも寄与します。
ベクトル検索はRAGの中核を担っており、以下のような重要な役割を果たします。
- クエリのベクトル化:ユーザーの質問をベクトル形式にエンコードします。
- 関連情報の抽出:エンコードされたクエリを基に、外部データベースから関連する必要な情報をベクトル検索で抽出します。
- コンテキストの提供:抽出された関連情報をLLMに提供し、より正確で文脈に即した回答生成を支援します。
ベクトル検索を活用したRAGは、LLMの能力を大幅に拡張し、より正確で文脈に即した回答を生成することを可能にします。これにより、質問応答システムや対話型AIなど、様々なアプリケーションの性能向上が期待できます。
RAGを支える技術やツールとして、ベクトル検索以外に以下が挙げられます。
| フレームワークとライブラリ | LangChain | RAGを含む様々なLLMアプリケーションの開発を支援するライブラリ |
| LlamaIndex | RAGパイプラインの構築を簡素化するフレームワーク | |
| 基盤技術 | Embedding | テキストを数値ベクトルに変換する技術 |
| データ前処理 | RAGチャンク | 文書を適切なサイズに分割する技術 |
| 検索最適化技術 | ハイブリッド検索 | ベクトル検索とキーワード検索を組み合わせた手法 |
| Rerankモデル | 検索結果を再評価し、より関連性の高い順に並べ替える技術 | |
| クラウドサービス | Azure AI Search | Microsoftが提供する高度な検索サービス |
関連記事:「RAG(検索拡張生成:Retrieval-Augmented Generation)とは?LLMでの活用方法・事例・メリット・導入の注意点まで徹底解説!」
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
ベクトル検索の特徴と仕組み

ベクトル検索は、従来の検索手法と比較して多くの優れた特徴を持ち、その仕組みは高度な技術に支えられています。ここでは、ベクトル検索の主要な特徴と仕組みについて詳しく解説します。
高速な検索性能
ベクトル検索の最大の特徴は、高速な検索性能と高い精度を両立している点です。従来のキーワードベースの検索では、大規模なデータセットを扱う際に検索速度が低下する傾向がありましたが、ベクトル検索ではこの問題を解決しています。
ベクトル検索では、データをあらかじめ多次元のベクトル空間に変換し、インデックスを作成します。このインデックスを利用することで、類似度の計算を効率的に行うことができ、大規模なデータセットでも高速な検索が可能となります。
例えば、1億件のデータに対する検索でも、数十ミリ秒程度で結果を返すことができるケースもあります。
曖昧な検索クエリでの検索精度
ベクトル検索は意味的な類似性を考慮するため、検索精度も大幅に向上します。単純なキーワードマッチングではなく、文脈や意味を理解した検索が可能となり、ユーザーの意図に沿った関連性の高い結果を提供できます。
これにより、検索結果の適合率(Precision)と再現率(Recall)が向上し、ユーザーエクスペリエンスの改善にもつながります。
ハイブリッド検索で高度な情報アクセスを実現
ベクトル検索は、単語や文書の意味・文脈を数値ベクトルとして捉え、その類似度に基づいて関連情報を探し出すAI技術です。この「意味を理解する」という大きな特徴が、ハイブリッド検索において極めて重要な役割を果たします。
従来のキーワード検索は、特定の単語との一致には強いものの、ユーザーの曖昧な検索意図や、言葉の言い換え(類義語)、文脈全体の理解には限界がありました。一方、ベクトル検索は、検索クエリと文書内容の意味的な近さを評価するため、キーワードが直接含まれていなくても、あるいは異なる表現が用いられていても、関連性の高い情報を見つけ出すことが可能です。
ハイブリッド検索では、このベクトル検索の高度な意味理解能力が、キーワード検索の網羅性や直接性と融合されます。単一の検索手法では達成困難だった、よりきめ細やかで精度の高い、ユーザーの期待に応える情報提供が実現します。
多様なデータ形式への対応
ベクトル検索の大きな利点は、テキストだけでなく、画像、音声、動画など、多様なデータ形式に対応できることです。これらのマルチモーダルデータを統一的に扱うことができるため、企業の持つ様々な種類のデータを効果的に検索・活用することが可能になります。
画像認識AIでは、畳み込みニューラルネットワーク(CNN)などのディープラーニングモデルを使用して、画像を高次元のベクトル(埋め込み)に変換されます。ベクトル表現は、画像の視覚的特徴や意味的内容を数値化したものです。
画像をベクトル化することで、ベクトル間の距離を計算し、類似度を測ることができます。大規模な画像データベースから、クエリ画像に最も類似した画像を高速に検索することが可能になります。
例えば、製造業では技術文書だけでなく、設計図面や製品画像なども含めた統合的な検索が可能になります。また、Eコマース分野では、商品の説明文と商品画像を組み合わせた検索を実現できます。
このような多様なデータ形式への対応は、ビジネスにおける情報活用の幅を大きく広げます。
大規模データ処理の効率
ベクトル検索は大規模データの処理にも優れています。ペタバイト級のデータセットでも効率的に検索を行うことができ、企業の持つビッグデータを最大限に活用することが可能です。例えば、数億件の顧客データや取引履歴を瞬時に検索し、リアルタイムでの意思決定支援に活用できます。
特に、近似近傍探索(ANN)技術を使用することで、総当たり検索よりも高速に類似データを検索できます。ただし、速度が速い分、完全一致しない場合もあるため、精度と速度のバランスが求められます。
ベクトル検索の課題

ベクトル検索には多くの利点がありますが、実装や運用にあたっては様々な課題があります。主な課題とその対策について説明します。
計算コスト
ベクトル検索の導入には、高い計算コストが伴います。まず、大量のデータをベクトル化し、インデックスを作成する際には、高性能なGPUやTPUなどの専用ハードウェアが必要となることがあります。これらの初期投資や運用コストは、中小企業にとっては大きな負担となる可能性があります。
尚、例えばAzure AI Searchのような最新のベクトル検索サービスでは、エンベディングモデルを直接デプロイできるため、高性能な専用ハードウェアや高額な初期投資なしでベクトル検索を導入できます。これにより、中小企業でも比較的容易にベクトル検索を活用できるようになってきています。
定期的な更新が必要
ベクトル検索の精度を維持するためには、定期的なモデルの更新や再学習が必要です。ベクトル検索では、インデックスを段階的に更新することが簡単ではありません。新しいベクトルを追加すると、検索速度が低下するため、定期的にインデックスを再構築する必要があります。
新しいデータが頻繁に追加される環境では、インデックスの更新頻度や方法が重要な課題となります。
ただし、最新のベクトル検索エンジンでは、インデックスの段階的な更新が可能であり、新しいベクトルの追加によって検索速度が大幅に低下することも少なくなってきています。
プライバシーとセキュリティ
プライバシーとセキュリティの観点からも課題があります。一般的に、ベクトル化されたデータから元情報を復元することは難しいとされていますが、常に技術は進歩しているため、ベクトル化されたデータから元の情報を復元できないようにする技術の更新や、検索クエリ自体からユーザーの意図を推測されないような保護メカニズムの実装が求められます。
出力結果の説明可能性
最後に、ベクトル検索の結果の解釈可能性も課題の一つです。なぜその検索結果が返されたのかを説明することが難しい場合があり、特に金融や医療など、意思決定の根拠が重要視される分野では、この点が導入の障壁となることがあります。
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
AIを活用したベクトル検索の実装方法

ベクトル検索をAIを活用して実装する方法は、企業のデータ活用戦略において重要な役割を果たします。
ここでは、ベクトル検索の実装における主要なステップについて詳しく解説します。導入を検討する際は、POC(概念実証)を行い、自社にとっての具体的な効果と必要投資を見極めることをおすすめします。
関連記事:「AI開発の基本からAIシステム構築の手順や流れを徹底解説!失敗しないための注意点も紹介」
エンベディング(Embedding)モデルの選択
ベクトル検索の実装において、最初に重要なのはエンベディングモデルの選択と学習です。エンベディングモデルは、テキストや画像などの入力データを固定長のベクトルに変換する役割を担います。
適切なモデルを選択し、効果的に学習させることで、検索精度を大きく向上させることができます。代表的なエンベディングモデルとしては、以下があります。
- BERT:Transformerアーキテクチャを基にした深層ニューラルネットワークモデルで双方向の文脈を考慮し、文全体の意味を捉えます
- GPT:Transformerのデコーダーを使用してテキスト生成タスクに強い
- Word2Vec:比較的シンプルな2層のニューラルネットワークモデルで少ない計算リソースでも扱えます
例えば、BERTは双方向のコンテキストを考慮できるため、多くの自然言語処理タスクで高い性能を発揮します。一方、特定のドメインや言語に特化したタスクでは、カスタムモデルの開発が効果的な場合もあります。
モデル選択の際には、タスクの特性(テキスト、画像、音声など)や必要な計算リソースも考慮する必要があります。
エンベディングについては、こちらの記事で詳しく解説しています。
転移学習やファインチューニングとモデル評価
モデルの選択後は、企業固有のデータセットを用いて転移学習やファインチューニングを行います。この過程では、大規模な訓練データと計算リソースが必要となりますが、クラウドサービスを活用することで、初期投資を抑えつつ高性能なモデルを構築することが可能です。
クラウドサービスを利用することで、初期投資を抑えつつ高度なベクトル検索機能を実装できます。例えば、Amazonの「Amazon Kendra」やGoogle Cloudの「Vertex AI Search」などのサービスを活用すれば、専門的な知識がなくてもベクトル検索を導入できます。
学習済みモデルの評価には、コサイン類似度やユークリッド距離などの指標を用います。また、人手による定性的な評価も併せて行うことで、実際のビジネスニーズに合致したモデルを選定することができます。
インデックス作成
インデックス作成では、データセット内の全てのアイテムをベクトル化し、それらを効率的に格納・検索できる構造に変換します。大規模なデータセットに対して高速な検索を実現するためには、効率的なインデックス構造が不可欠です。
代表的なインデックス構造には、KD-treeやBall-treeなどがありますが、高次元データに対しては必ずしも効率的ではありません。そこで、近年では、HNSW(Hierarchical Navigable Small World)やIVF(Inverted File)などの手法が注目されています。
インデックスの更新戦略も重要な検討事項です。新しいデータが追加される頻度や量に応じて、バッチ更新やインクリメンタル更新など、適切な方法を選択する必要があります。
ANN(近似最近傍探索)の実装
次は近似最近傍探索(ANN)の実装です。大規模なデータセットに対して高速な検索を実現するためには探索アルゴリズムが不可欠です。
ANNは、厳密な最近傍探索と比較して、若干の精度低下と引き換えに大幅な高速化を実現します。例えば、Facebook AI ResearchのFaissライブラリやSpotifyのAnnoyなど、オープンソースの実装が利用可能です。これらのライブラリを活用することで、数百万から数十億規模のベクトルに対しても、ミリ秒単位での高速な検索が可能になります。
クエリ処理とランキングアルゴリズムの最適化
ユーザーからのクエリを効果的に処理し、最適な検索結果を返すためのランキングアルゴリズムの実装が重要です。この段階では、単純な類似度計算だけでなく、ビジネスロジックや外部要因を考慮した複雑なランキング手法が求められます。
クエリ処理では、ユーザーの入力をベクトル化し、インデックスに対して効率的に検索を行います。この際、クエリの前処理(ストップワードの除去、ステミングなど)や、クエリ拡張(同義語の追加など)を行うことで、検索精度を向上させることができます。
ランキングアルゴリズムの最適化では、AIモデルを活用することが一般的です。例えば、Learning to Rank(LTR)と呼ばれる手法では、過去のユーザー行動データを用いて、最適なランキングモデルを学習します。これにより、単純な類似度だけでなく、ユーザーの嗜好やアイテムの人気度など、多様な要因を考慮したランキングが可能になります。
継続的な改善
A/Bテストを通じて継続的にアルゴリズムを改善することも重要です。ユーザーの行動データを分析し、クリック率や滞在時間などの指標を用いて、ランキングアルゴリズムの性能を評価・改善していくことで、長期的に検索品質を向上させることができます。
以上のステップを適切に実装することで、高性能かつビジネスニーズに合致したベクトル検索システムを構築することが可能になります。ただし、これらの実装には専門的な知識と経験が必要となるため、必要に応じて外部の専門家やコンサルタントの支援を受けることも検討してください。
ベクトル検索の多様なユースケース
ベクトル検索技術は、様々な業界で革新的なソリューションを提供しています。ここでは、Eコマース、製造業、金融サービスにおける具体的なユースケースを紹介し、ベクトル検索がどのようにビジネス価値を創出しているかを解説します。
Eコマース: 画像検索を活用した商品レコメンデーション
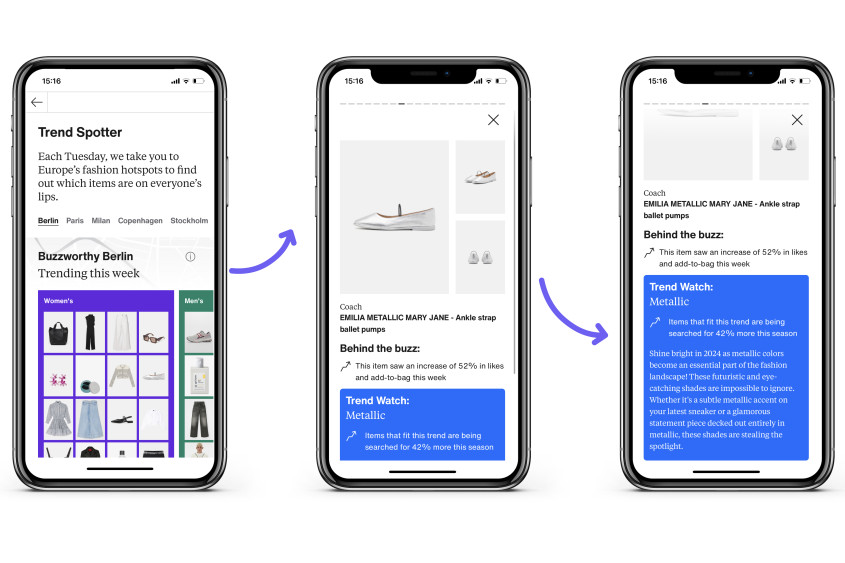
Eコマース業界では、ベクトル検索を活用した画像検索機能が、ユーザーエクスペリエンスの向上と売上増加に大きく貢献しています。例えば、ユーザーが気に入った商品の画像をアップロードすると、類似した商品を即座に表示するシステムが実現可能です。
この技術を導入した代表的な事例として、ヨーロッパのファッションEコマース大手のZALANDOが挙げられます。ZALANDOは、ディープラーニングを活用した画像認識技術と組み合わせたベクトル検索システムを導入し、ユーザーが撮影した写真や好みの商品画像から類似アイテムを瞬時に提案できるようになりました。この結果、ユーザーの購買行動が促進され、コンバージョン率が向上したと報告されています。
また、画像だけでなく、テキストと画像を組み合わせたマルチモーダル検索も可能です。ユーザーが「赤いドレス」と入力し、さらに好みのデザインの画像をアップロードすることで、より精緻な商品推薦が実現できます。このような高度なパーソナライゼーションは、顧客満足度の向上と売上増加に直結します。
製造業: 技術文書と図面の統合検索による知識管理
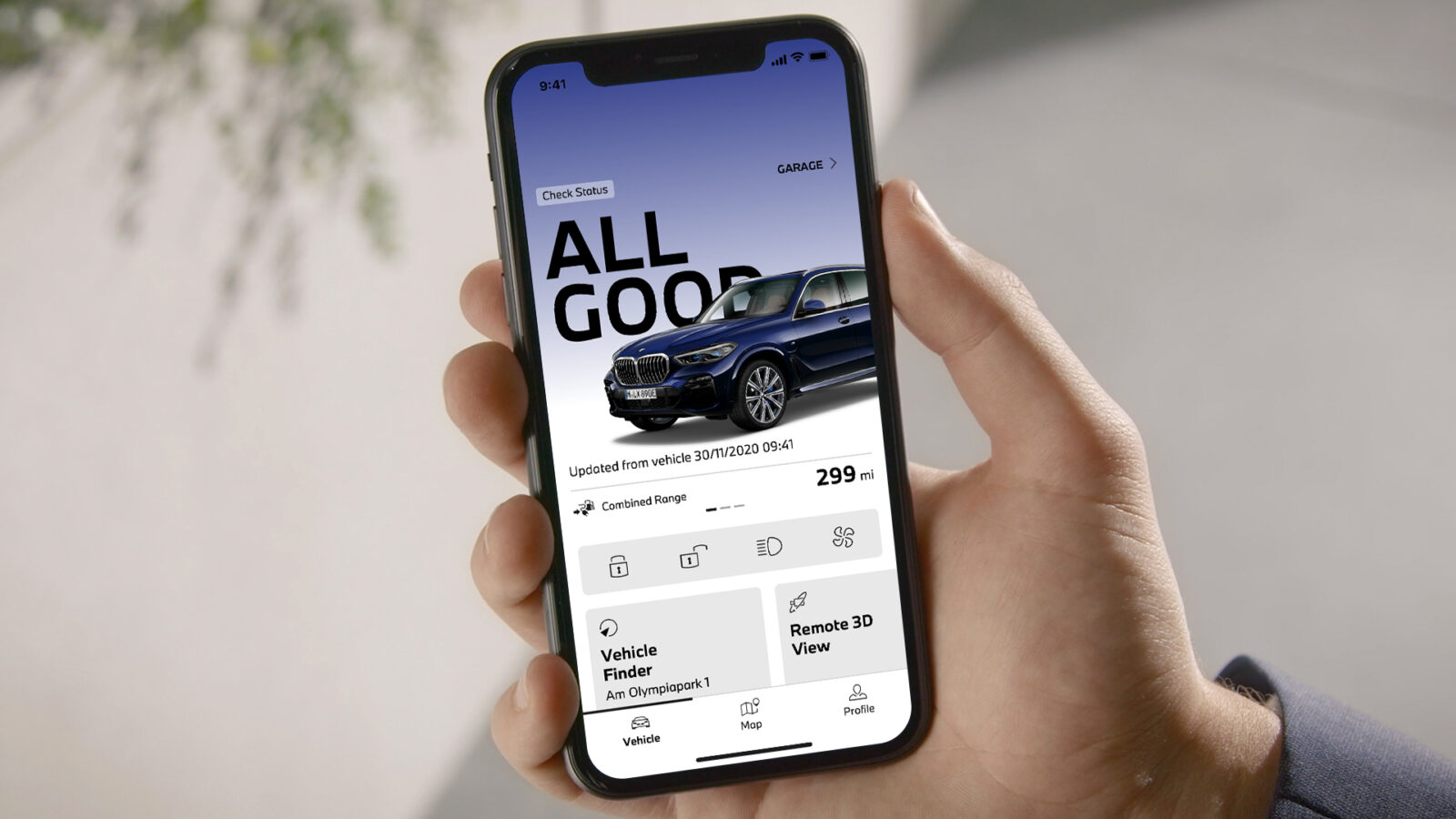
製造業では、膨大な技術文書や設計図面の効率的な管理と活用が課題となっています。ベクトル検索を用いることで、テキストデータと画像データを統合的に検索し、エンジニアの業務効率を大幅に向上させることが可能です。
例えば、自動車メーカーのBMWは、ベクトル検索技術を活用した知識管理システムを導入しています。このシステムでは、過去の設計文書、3D CADモデル、テスト結果などの多様なデータを統合的に検索できます。
エンジニアは、特定の部品に関する情報を検索する際、関連する技術文書だけでなく、その部品の3Dモデルや過去の不具合情報まで一括で取得できるようになりました。
このような統合検索システムにより、新製品開発のサイクルタイムが短縮され、品質管理の精度も向上しています。さらに、ベテラン社員の暗黙知を形式知化し、若手エンジニアへの技術伝承を効率化する効果も報告されています。
関連記事:「暗黙知とは?放置するリスク、形式知化の手法、AIで解決した企業事例を徹底解説」
金融サービス: 音声データを含むリスク分析と不正検知
金融サービス業界では、ベクトル検索技術を活用したリスク分析と不正検知が注目を集めています。特に、テキストデータだけでなく、音声データも含めた多角的な分析が可能になったことで、より高度なリスク管理が実現しています。
大手金融機関のJPMorgan Chaseは、ベクトル検索を活用した不正検知システムを導入しています。このシステムでは、取引データ、顧客とのメールのやり取り、さらには通話記録の音声データまでを統合的に分析し、不自然なパターンや潜在的なリスクを検出します。
例えば、特定のキーワードを含む会話や、通常とは異なる取引パターンを示す顧客を自動的にフラグ付けし、調査対象として抽出することが可能になりました。
また、投資銀行業務においても、ベクトル検索は重要な役割を果たしています。膨大な市場データ、企業情報、ニュース記事などを高速に検索・分析することで、投資判断の精度向上や新たな投資機会の発見につながっています。
これらのユースケースは、ベクトル検索技術が単なる検索機能の改善にとどまらず、ビジネスプロセス全体の変革と価値創造につながることを示しています。今後、AIとの統合がさらに進むことで、より高度で革新的なアプリケーションが登場することが期待されます。
エンタープライズサーチ:企業の情報資産を最大限に活用
ベクトル検索を活用したエンタープライズサーチは、企業の情報資産を最大限に活用し、意思決定の質を向上させる強力なツールとなります。
キーワードの完全一致ではなく、意味的な類似性に基づいて情報を検索できます。例えば、「顧客満足度向上策」という検索で、「カスタマーエクスペリエンス改善」に関する文書も検索結果に含まれます。
また、テキスト、画像、音声など、異なる種類のデータを統一的に扱えるので、製品画像をアップロードして、関連する技術文書や営業資料を検索することも可能です。
メリットとして、従業員が必要な情報を素早く見つけられるようになり、業務効率が向上します。また、埋もれていた情報や関連性のある情報を発見しやすくなり、社内知識の活用が促進されます。
関連記事:「エンタープライズサーチとは?AI搭載社内検索の機能・メリット・デメリット・導入手順・事例を徹底解説!」
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
まとめ
ベクトル検索は、AIを活用した革新的な検索技術で、多様なデータを高速かつ高精度に検索できます。LLMやRAGと組み合わせることで、より高度な情報検索が可能になります。実装には、適切なエンベディングモデルの選択、効率的なインデックス作成、最適化されたクエリ処理が重要です。
しかし、その恩恵を最大限に享受するには、適切な実装と運用が不可欠です。まずは、
ベクトル検索についてよくある質問まとめ
- ベクトル検索は従来の検索方法と比べてどのような利点がありますか?
大規模データセットでも迅速に結果を返すことができて、テキスト、画像、音声など、様々な形式のデータを統合的に扱えます。
- ベクトル検索は具体的にどのような業界で活用されていますか?
ベクトル検索は、Eコマース、製造業、金融など、様々な業界で活用されています。例えば、ヨーロッパのファッション系EコマースZALANDOが画像検索機能を導入し、ユーザーの購買行動促進とコンバージョン率向上を実現しました。
- ベクトル検索の導入にはどのくらいのコストと時間がかかりますか?
コストと時間は、プロジェクトの規模や複雑さによって大きく異なります。小規模なプロトタイプであれば、クラウドサービスを利用して数週間程度で構築可能です。コストは月額数万円から始められます。一方、大規模な企業全体のシステムとして導入する場合、数か月から1年程度の期間と、数千万円以上の投資が必要になることもあります。
主なコスト要因は、データの前処理、モデルのトレーニング、インフラ構築、そして運用・保守です。長期的には、業務効率の向上や新たな収益機会の創出によって、投資は十分に回収できると多くの企業が報告しています。導入を検討する際は、POC(概念実証)を行い、自社にとっての具体的な効果と必要投資を見極めることをおすすめします。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

