
Google Imagenとは?DALL・E 3・Stable Diffusionとの違いは?活用事例・商用利用・安全性を徹底解説!
最終更新日:2025年08月27日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

Google Imagenとは、Googleが2022年に発表した画像生成AIです。ChatGPT以降さまざまな生成AIが大手IT企業からリリースされ、その中でも対話型と画像生成の分野は非常に注目を集めています。
画像生成とはなにか、活用事例等をこちらの記事で詳しく説明していますので併せてご覧ください。
しかし、DALL·E 3、Stable Diffusion、Midjourneyとたくさんの画像生成AIが発表されている中でそれぞれどのような特徴があるのか、どれを使うのが自社にとって良いのかわからないという方も多いでしょう。
今回はGoogle Imagenについて、どのようなものか、他の画像生成AIとはどこが違うのか、安全性や将来性はあるのかなど徹底解説します。この記事を読んで、自社のAI導入の参考にしていきましょう。
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
画像生成システムに強いAI開発会社を自力で選びたい方はこちらで特集していますので併せてご覧ください。
目次
Google Imagenとは?
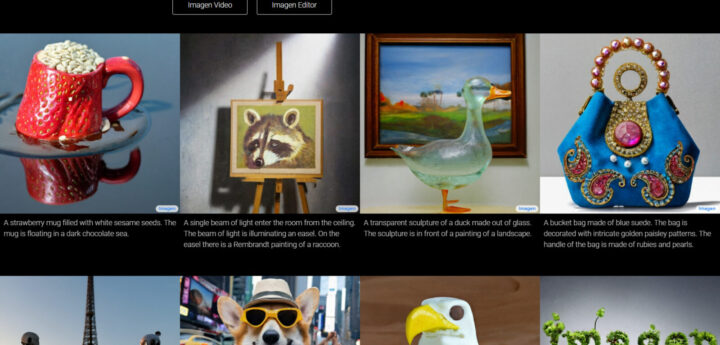
Google ImagenはGoogleが開発している画像生成AIです。Vertex AI上で利用することができ、現在は主にデベロッパー向けに公開しており、一部の機能を制限した状態です。
ディープラーニングに基づいており、膨大なデータベースから学習しています。テキストを入力するだけでその意味を汲み取った新しい画像を生成したり、自身でアップロードした画像をどう編集して欲しいか入力して修正できます。
Google Imagenの言語理解が優れている理由は、画像生成する過程でテキストをエンコーディングする(テキストなどをコンピュータが読み取れるように変換する)工程に注目したことにあります。この工程で、学習済みのLLMのサイズを活用したことでより複雑な文章でも文脈を読み取ることが可能になりました。
より高精度でテキストから内容を反映した画像生成を可能にしています。
LLM(大規模言語モデル)とは何か、どう活用されているか、こちらの記事で詳しく説明していますので併せてご覧ください。
Google Imagenは、数多い画像生成AIサービスの中でも高精度な画像生成と言語理解のレベルが非常に高いことで注目されています。広告、メディア、デザインなどの分野での応用が期待され、これらの産業に新たな革命をもたらす可能性があります。
Google Imagenのモデルヒストリー
Google Imagenの各バージョンの歴史を簡潔にまとめると以下のようになります:
- Imagen (初期バージョン):2022年に発表された基本的な画像生成機能
- Imagen 2:2023年12月にリリース。より写実的な画像生成
- Imagen 3:2024年12月にリリース。自然言語プロンプトの理解力向上
各バージョンで、画像生成の品質と機能が段階的に向上しています。また、安全性と責任あるAI開発の観点から、デジタル透かしや安全性フィルターなどの機能も強化されています。
Vertex AIとは?
Vertex AIとは、Googleが提供する機械学習プラットフォームです。Vertex AI上でLLMのカスタマイズからアプリケーションの作成まで幅広い機能が備わっています。
特に、Imagen 2のような高度な画像生成AIの利用において、Vertex AIは重要な役割を果たします。Imagen 2をVertex AI上で活用することにより、ユーザーは独自のカスタマイズや最適化を行いながら、高品質な画像生成を実現できます。
Vertex AIは一例として以下のことができます。
AutoML
AutoML機能で、コード作成やデータを分割する必要なく画像や動画データをトレーニングすることが可能です。これにより、AIと機械学習に関する専門知識がないユーザーでも、高度なモデルのトレーニングが可能になります。
関連記事:「AutoMLとは?機能・メリット・デメリット・活用事例を徹底紹介!」
カスタムトレーニング
カスタムトレーニングの機能を利用すると、コードの生成や機械学習に必要なパラメータの調整など、自身でトレーニングプロセスをカスタマイズできます。より複雑な要件や特定のビジネスニーズに合わせたモデルの開発が可能になります。
Model Garden
Model Garden機能を利用すると、テストやデプロイが行えるようになります。開発したモデルを実際のビジネス環境に容易に統合し、効果的に利用することが可能になります。
Vertex AIの活用方法をこちらの記事で詳しく説明していますので併せてご覧ください。
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
DALL・E 3、Stable Diffusion、Midjourneyとの共通点

Google Imagenと他の画像生成AIの違いは画像生成におけるテキストエンコーディングの処理で大規模言語モデルを利用したことが挙げられます。他にもさまざまな点でGoogle Imagenは他の画像生成AIと違う部分が存在します。
DALL・E 3とGoogle Imagenの共通点は、入力されたテキストをエンコーディングして数値情報に変換し、その数値から拡散モデル(Diffusionモデル)を利用して画像生成することにあります。画像生成AIの処理における拡散モデルとは、元になる画像にノイズをかけて、次にノイズを除去して生成される画像と元画像の差分を小さくするようにする学習モデルを指します。
DALL・Eより前の画像生成AIでは、敵対的生成ネットワーク(GAN)を用いるのが主流でしたが、Google Imagenを含めて、DALL・E 3、Stable Diffusion、Midjourneyなど主要画像生成AIが拡散モデルを使用しています。Midjourneyについて技術詳細は公表されていませんが拡散モデルの一種を活用していると推測されています。
拡散モデルを使うことで、入力テキストの情報から画像の特徴を抽出して、より高精度な出力を実現できます。Google Imagenでもこの拡散モデルを利用する工程は共通しています。
Diffusion model(拡散モデル)とは?実際の利用シーンは?こちらの記事で詳しく説明していますので併せてご覧ください。
DALL・E 3、Stable Diffusion、Midjourneyとの相違点
Google ImagenとDALL・E 3、Stable Diffusion、Midjourneyなど主要画像生成AIとの主な相違点は以下です。
LLM(大規模言語モデル)を使って学習して拡散モデルに移行
DALL・E 3、Stable Diffusion、Midjourneyは、画像とテキストのペアを学習するCLIPという手法から拡散モデルに移行するのに対し、Google ImagenはLLM(大規模言語モデル)を使って学習して拡散モデルに移行している相違点があります。
CLIP(Contrastive Language–Image Pretraining)は、画像とテキストのペアを学習します。そして、入力されたテキストに基づいて関連する画像を生成する技術です。このモデルはもともと画像に適したテキストを選択するために開発されました。
画像生成ではその逆、つまりテキストから関連する画像を選択するために応用されています。技術詳細を公開していないMidjourneyも、CLIPを応用していると推測されています。
関連記事:「Clipとは?OpenAIのマルチモーダル基盤モデルの仕組み・活用事例・課題を徹底解説!」
一方、Google ImagenはLLMでテキストのみを使用して豊富な学習を行うことが可能です。このアプローチのおかげで、より複雑なコンテキストを含むテキストを処理し、高度に関連性のある画像を生成することができます。
特に、テキストを画像に埋め込む場合、Imagenはテキストを効果的に画像に統合することが可能です。また、より複雑なコンテキストを含むテキストを入力したい場合に向いています。一方で、DALL・E 3、Stable Diffusion、Midjourneyは文字列を含む画像の生成には若干の制限があると報告されています。
高度なリアリズムと細部のディテール
Imagenが生成した画像データは、高度なリアリズムと細部のディテールに優れています。それは膨大なLLMで学習できることのメリットです。
Google Imagenと他の画像生成AIとの精度比較では、AlignmentとFidelityという指標でより良い精度を出していることが検証されています。
Alignmentは生成画像が本物の画像とどのくらい整合性が取れているかを測ります。例えば、犬の画像が生成された時どの程度本物の犬の画像に近いかを比較します。Fidelityではテキストで指示した内容と生成された画像がどのくらい近いかを測る指標です。例えば、犬というテキストに対して犬の画像が生成されているかを比較します。
これらの指標が他の画像生成AIのスコアより高いため、Google Imagenはテキストから生成される画像の忠実さやテキスト内容が反映される能力が高いことがわかります。
ただし、あまりにリアルなため、フェイクニュースやリベンジポルノに悪用されることが懸念されています。また、学習に使用するLLMに差別的な主張や暴力的な表現などの倫理的に問題のあるデータが含まれる可能性が払拭できないとされています。
アクセスの限定性
Stable Diffusionはオープンソースのプロジェクトであり、より広範囲の開発者や研究者にアクセス可能です。Midjourney、DALL・E 3もより広いユーザーベースに向けて提供されており、異なる業界や分野での利用が進んでいます。
一方、Imagenは開発者向けのVertex AI上での公開に限定されています。と言っても、かなりハードルは下がっており、生成した画像を簡単に編集する「Imagen Editor」や、テキストから動画を生成する「Imagen Video」という公式サービスが開発されています。
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
Imagenは商用利用できる?

現在Google Imagenは商用利用可能です。Google Imagenで生成されてアウトプットされる前に、他の生成AIのプロダクトに関する制限違反のチェックがされています。Google Imagenは既存のコンテンツ複製をするものではなく、著作権侵害が発生する可能性を抑制する設計もされています。
ただし、Google Imagenの一部の機能は承認されたユーザーのみ利用可能なケースや試験運用中のものもあるため、自身が使いたい機能があるか事前確認する必要があります。また、企業側が画像生成AIの商用利用を禁止しているケースもあるため、実際に利用する場合は注意が必要です。
Imagenの安全性
Google Imagenは、生成されたAIがGoogleが規定している責任ある信頼されたAIの原則を満たしているか確認する対策がされています。Google Imagen 2では電子透かしサービスが試験運用版で搭載されています。
電子透かしサービスでは、人間の目では判別できない電子透かしを画像に組み込むことでその画像が画像生成AIから作成されたかどうか検知したり、不正コピーがされていないか確認したりできます。
また、生成される画像には有害コンテンツが含まれているかの確認もされているため、ユーザーは安全にGoogle Imagenを利用することができます。Imagenが学習に使用するLLMには差別的な主張や暴力的な表現などの倫理的に問題のあるデータが含まれる可能性があり、生成される画像でも有害コンテンツが含まれる可能性はあります。
Imagenの将来性は?
![]()
Google Imagenは複雑なテキストでも精度高く画像を生成できるため、AIが人間の言語をうまく捉え、視覚情報の深い理解ができることが期待されています。すでに大手画像提供サービスShutterstockや画像編集プラットフォームCanvaなどにも導入されており、クリエイティブ産業から注目を集めています。
今後は画像生成AIの枠組みを超えてさまざまな分野に発展していくことが予想されます。
また、Google Imagenの精密なイメージ生成は、エンターテイメントやデザインの分野で仮想現実のアバターや動きあるキャラクターにまで昇華させる可能性も示唆されており、十分な将来性があると言えます。
Google ImagenとBard、Geminiの関連性
Googleは、テキストから高品質な画像を生成するImagenに加え、自然言語処理(NLP)に特化したAIであるBard、そして複数のAI技術を組み合わせた総合プラットフォームGeminiで生成AI系の覇権を握ろうとしています。
Bardは、Googleによって開発された自然言語処理(NLP)に特化した対話型AIです。このAIは、テキストデータの解析、意味理解、そしてそれに基づく質の高いテキスト生成に優れています。
Bardとは?活用事例は?こちらの記事で詳しく説明していますので併せてご覧ください。
Geminiは、複数のAI技術を組み合わせた総合的なソリューションを提供するマルチモーダルAIプラットフォームです。このプラットフォームは、画像生成、自然言語処理、データ分析など、さまざまなAI技術を統合し、企業のビジネスプロセス全体をサポートします。
Google Imagenは画像生成に特化して提供されており、Bardはテキスト生成と解析に活用できる対話型AIとして提供されています。そしてGeminiはマルチモーダルAIプラットフォームです。
これらの技術を組み合わせることで、企業はマーケティング、プロダクトデザイン、顧客対応など多岐にわたる分野での革新的な取り組みを実現できます。例えば、Bardで生成した高品質なテキストをGoogle Imagenで視覚化することで、よりインパクトのあるマーケティングコンテンツを作成することが可能です。また、Geminiを利用することで、これらの技術を統合し、ビジネスの様々な側面に応用することができます。
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
Google Imagenについてよくある質問まとめ
- Google Imagenとは?
Google ImagenはGoogleが開発している画像生成AIです。Vertex AI上で利用することができ、現在は主にデベロッパー向けに公開しており、一部の機能を制限した状態です。Google Imagenの言語理解が優れている理由は、画像生成する過程でテキストをエンコーディングする(テキストなどをコンピュータが読み取れるように変換する)工程に注目したことにあります。この工程で、学習済みのLLMのサイズを活用したことでより複雑な文章でも文脈を読み取ることが可能になりました。より高精度でテキストから内容を反映した画像生成を可能にしています。
- ImagenとDALL-E3、Stable Diffusion、Midjourneyはどう違う?
Google Imagenと他の画像生成AIの違いは画像生成におけるテキストエンコーディングの処理で大規模言語モデルを利用したことが挙げられます。Imagenが生成した画像データは、高度なリアリズムと細部のディテールに優れています。それは膨大なLLMで学習できることのメリットです。
まとめ
今回はGoogle Imagenについてどういうものか、他の画像生成AIとはどう違うのか、安全性や将来性はあるのかについて徹底解説してきました。Google Imagenの特徴は
自社でどのAIツールを利用するか検討している際は、ぜひ今回の内容を参考にしてより有効活用できるサービスを選んでいきましょう。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

