
CLIPとは?OpenAIのマルチモーダル基盤モデルの仕組み・活用事例5選・課題を徹底解説!
最終更新日:2026年07月24日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

画像と自然言語を同時に理解するマルチモーダル基盤モデル「CLIP」は、生成AI(ジェネレーティブAI)の進化とともに大きな注目を集めています。OpenAIが2021年に発表したCLIPは、従来の画像解析モデルとは異なり、自然言語と組み合わせた非常に汎化性能の高いモデルとして、現在多くのAI開発に用いられています。
関連記事:「画像解析とは?種類・活用方法・企業での導入ステップ・注意点を徹底解説!」
この記事では、CLIPの基本技術や仕組み、活用事例、課題について解説します。CLIPがどういう技術なのか知らない方でも、本記事を読めば概要を把握できるようになっています。
AIが人間の認知能力にさらに一歩近づいた今、CLIPがもたらす未来とは何か。技術の進化が私たちの生活をどう変えていくのか、一緒に探っていきましょう。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
目次
CLIPとは?

CLIP(Contrastive Language–Image Pretraining)は、2021年にOpenAIが発表したマルチモーダルの基盤モデルです。画像と言語のマルチモーダルな情報を同時に処理し、画像とテキストを関連付けることができます。
ゼロショット学習(Zero Shot Learning)を可能にする画像分類モデルとしても注目されています。ゼロショット学習とは、特定のカテゴリやタスクに対する事前のファインチューニングを必要とせずに推論を行う技術です。
CLIPでゼロショット学習が可能になった一つの要因は、従来の画像認識モデルのようにアノテーションによって作成されるラベル付きデータに依存しない点です。
主にテキストデータを用いて学習するLLMと異なり、CLIPはインターネット上で収集された画像とテキストのペアで構成される大規模なデータセットで学習しています。画像とテキストの両方をエンコードし、これらの間の類似性を学習することで、ゼロショット分類を実現しています。
そのため、特定の訓練を必要とせずに新しいカテゴリやタスクに対して高いパフォーマンスを発揮します。これにより、文章からの画像生成や、画像からの物体検出が容易に行えるようになりました。
マルチモーダルな画像分類が可能
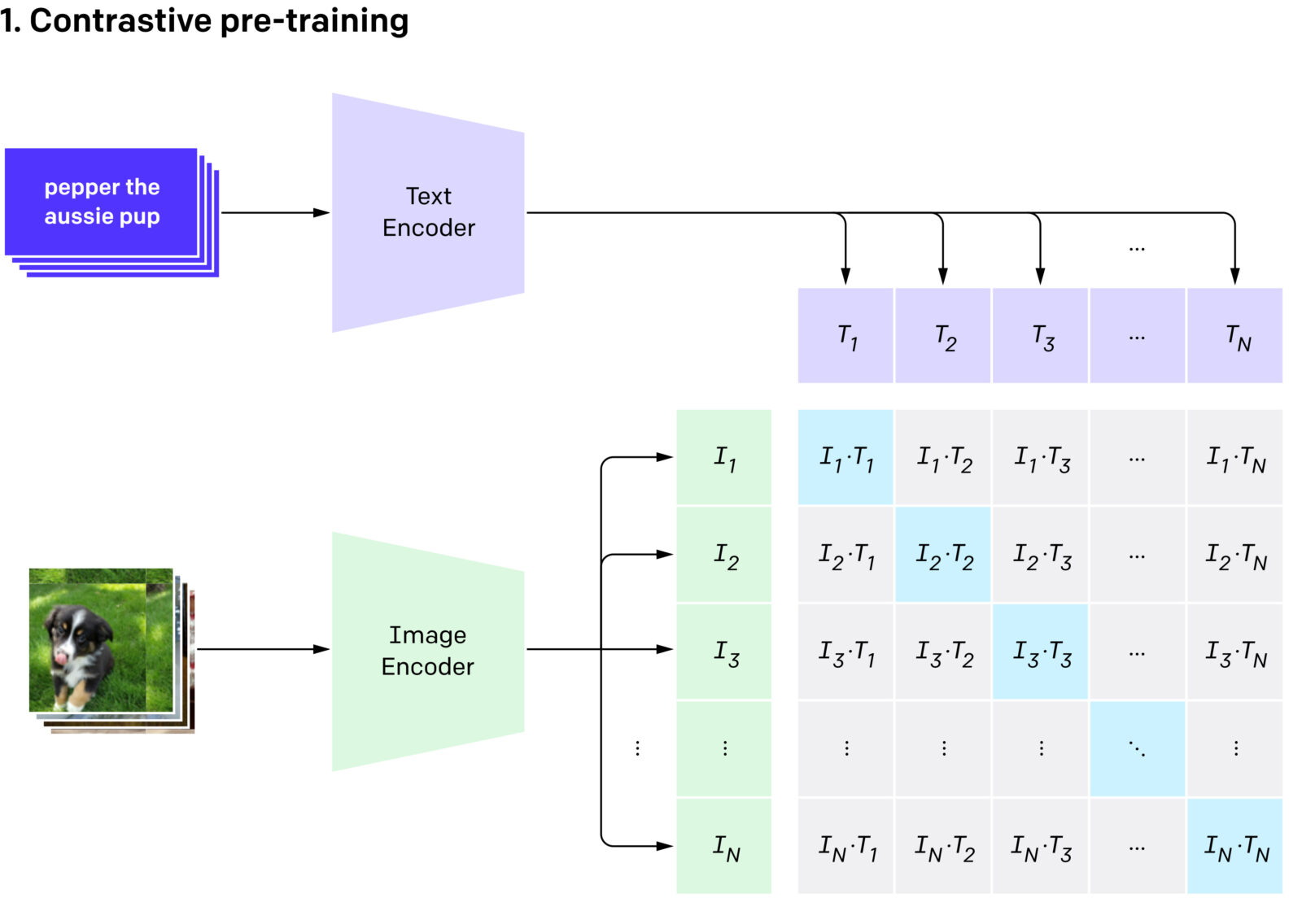
CLIPの特徴であるマルチモーダルとは複数の異なるデータ形式を同時に処理することを指し、CLIPの場合は画像とテキストを対象としており、文章から画像を生成したり、多様な物体を検出することが可能です。
通常の画像分類モデルは、訓練データセットに含まれる画像とそのラベルを使って学習し、未知の画像に対してそのラベルを予測します。一方、CLIPは画像と言語の両方の情報を同時に処理します。
画像とテキストの両方を固定長のベクトルに変換して同じプロセス内で処理できます。そのため、画像とテキストを相互に関連付けながら類似画像や類義テキストを探したり画像の分類を行えます。
学習時はコサイン類似度という指標に基づき、画像とテキストのペアが正しいかどうかを計算します。画像エンコーダにはResNet(EfficientNetと並んで画像分類の定番アーキテクチャ)やVision Transformerが使用され、テキストエンコーダにはトランスフォーマーモデルが使用されます。これにより、CLIPは新しい画像に対しても高精度で分類や関連付けを行うことが可能です。
関連記事:「VLMとは?画像とテキストを統合処理する仕組み・メリット・デメリット・活用分野を徹底紹介!」
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
CLIPの仕組み

CLIPのマルチモーダルモデルを支えるのは、以下のような技術です。
- データセット
- Contrastive Pre-Training
- Vision Transformer (ViT)
それぞれの技術や仕組みについて解説します。
データセット
CLIPを構成する技術の1つに、豊富なデータセットがあります。CLIPのデータセットはインターネット上から収集された大量の画像とテキストのペアが使用され、数億単位の画像とその説明文が含まれています。
CLIPは多岐にわたる画像とテキストを学習するため、新しいタスクにも柔軟に対応することが可能です。日常生活におけるシーンやオブジェクト、文化的コンテキストが含まれているため、幅広い文脈での理解ができます。これにより、CLIPは新しいタスクにも柔軟に対応できるようになっています。
また、単なる画像と言語の組み合わせにとどまらず、画像の内容やテキストの意味・ニュアンスなど、複雑な関係性も学習します。
Contrastive Pre-Training
Contrastive Pre-Trainingは、CLIPの学習手法です。大量の画像とそれに対応するテキストが用意され、モデルはこれらのペアを通じて、関連する画像とテキストが近い位置に配置されるように調整されます。
これにより、モデルは視覚的および言語的な情報を統合し、相互の関係性を理解することが可能になります。画像やテキストのラベルが何かを予測するのではなく、ラベルがどれに該当するか、複数の候補の中から最も適切なラベルを選択する仕組みです。
また、Contrastive Pre-Trainingにおけるもう一つの重要な要素は、バッチ単位での訓練です。大量のデータを処理するために、一度に複数のペアをモデルに入力し、同時に学習を行います。そして、各ペアについて、正しいペア(正例)と、その他のペア(負例)を設定し、正例の類似度を高く、負例の類似度を低くするように学習します。これにより、訓練速度の向上とパフォーマンスの最適化に貢献します。
Vision Transformer(ViT)
Vision Transformer(ViT)は、CLIPの画像処理部分を担うアーキテクチャです。ViTは画像認識AIで多く用いられてきた畳み込みニューラルネットワーク(CNN)とは異なり、Transformerをベースにした構造を持っています。これによって、より正確な分類や認識を可能にします。
ViTは、大規模なデータセットの処理に効果的です。画像を「パッチ」として分割し、これらをシーケンスデータとして扱うことで、画像全体を広範囲に捉えることが可能です。従来のCNNは画像の局所的な特徴に依存しがちですが、ViTは広範囲の視点で画像全体を捉えることができるため、より正確な分類や認識が可能です。
また、ViTは事前学習済みモデルとして使用されることが多く、他のタスクへの適応も容易です。ViTは画像の視覚情報を抽出し、テキストとの関連付けを行うための重要な役割を果たしています。画像を細かく分割して精密に解析することで、テキストとの相関性を高めることが可能です。
このように、ViTはCLIPの高度な画像処理を支える技術として、重要な役割を果たしています。
関連記事:「Vision Transformer(ViT)とは?仕組み・CNNとの違い・メリット・限界を徹底解説!」
画像認識技術は急速に進化しており、様々なモデルやサービスが登場しています。以下に、代表的な画像認識モデルとサービスを紹介します。
- U-Net:医用画像のセグメンテーションに特化したCNNアーキテクチャで、エンコーダ-デコーダ構造とスキップ接続が特徴的です。
- ResNet:深層ネットワークの学習を可能にしたモデルで、残差接続により勾配消失問題を解決しました。
- EfficientNet:モデルのスケーリングを最適化することで、少ないパラメータ数で高い精度を実現したCNNアーキテクチャです。
- Segment Anything Model (SAM):Meta AIが開発した汎用的なセグメンテーションモデル。画像エンコーダはVision Transformer (ViT) をベースとしたアーキテクチャを採用。
CLIPの活用事例5選

ゼロショット学習を用いたCLIPは、さまざまなシーンでの活用が期待されています。CLIPの導入が効果的な活用事例を3つ解説します。
画像検索
従来の画像検索システムは、主に画像のメタデータやタグに依存していました。CLIPは画像そのものとテキストの関係を直接利用するため、より精度の高い検索結果を提供します。
CLIPを用いた画像検索では、ユーザーが入力したテキストクエリに基づいて、最も関連性の高い画像を見つけ出すことが可能です。例えば、「山の頂上からの夕日」というクエリを入力すると、CLIPは大量の画像データから最も合致する画像を特定します。
また、新しい商品やトレンドに関する画像検索でも、CLIPは柔軟に対応し、正確な結果を提供することが可能です。CLIPのマルチモーダルなアプローチは、ユーザーの直感的な検索を可能にし、満足度を向上させます。
画像生成
ユーザーが入力したテキストの説明に基づき画像を生成する技術は、現在リリースされているさまざまなAIが提供していますが、CLIPを活用することで、より精度の高い画像生成が期待されています。この技術は、広告・デザイン・エンターテインメントなど多様な分野での応用が可能です。OpenAIでは、同社の画像生成モデルであるDALL・Eと組み合わせて使用され、生成された画像のリランキングに利用されています。
例えば、デザイナーが新しいコンセプトをデザインする際に、簡単なテキストを入力するだけで、そのコンセプトに基づいた画像を生成できます。これにより、デザイン作成の時間とコストを削減することが可能です。
物体検出
CLIPは、物体検出とセグメンテーションの分野での応用が進んでいます。特に、ゼロショットでのオープンボキャブラリーセグメンテーション(事前に定義されていないクラスの検出)において、その能力が活用されています。
従来の物体検出モデルは、限られたクラスに対して訓練されるため、新しいクラスに対応するには追加の訓練が必要でした。しかし、CLIPは言語モデルを活用することで、新たなクラスに対しても柔軟に対応できます。
ロボティクス
CLIPは、ロボティクス分野においてもその特性を活かして活用されています。特に、視覚情報とテキスト情報を統合する能力が、ロボットの認識能力を向上させるために役立っています。
CLIPは、画像とテキストの両方を扱うことができるため、ロボットが視覚的な情報とテキスト情報を統合して理解することが可能です。これにより、ロボットは自然言語で与えられた指示を理解し、それに基づいて行動することができます。また、複雑な物体操作タスクの精度が向上します。
ナビゲーション
CLIPの技術は、ナビゲーションシステムにおいても活用されます。従来のナビゲーションシステムは地図データとGPS情報に基づいてルートを設定しますが、CLIPはこれに視覚情報とテキストの関連付けを加えることで、より直感的で精度の高いナビゲーションを実現することが可能です。
「赤い屋根の建物の角を右に曲がる」といったテキストでの指示に対応できるようになるため、地名や店舗名を覚えなくても、視覚的な手がかりを頼りに道を見つけやすくなります。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
CLIPが抱えている課題

CLIPはマルチモーダルなAI技術として応用が期待されていますが、「初めて聞いた」という方もいるでしょう。実はCLIPの実用化にはいくつか課題があります。
計算負荷と応答速度
CLIPは、膨大なデータを解析するため、計算負荷が高く、特にリアルタイムでの画像検索やナビゲーションにおいて、応答の遅延が発生する可能性があります。これはユーザーエクスペリエンスに影響を及ぼすため、ハードウェアの性能向上やアルゴリズムの最適化が求められます。
データの質とバランス
CLIPでは高度なアルゴリズムを使用していますが、性能は学習に使用されるデータセットの質やバランスに大きく依存します。データセットが偏っている場合、モデルのパフォーマンスにムラができ、安定したクオリティの画像処理ができないリスクもあります。これを解決するためには、多様でバランスの取れたデータセットの構築が必要です。
CLIPについてよくある質問まとめ
- CLIPとは何ですか?
CLIPはOpenAIが公開した、ゼロショット学習を行う機械学習モデルで、画像と言語のマルチモーダルな情報の処理が可能です。画像と言語を相互に関連付けながら、ラベルの設定や画像の分類を行います。
- CLIPはどんなシーンで活用できますか?
CLIPは以下のようなシーンでの活用が可能です。
- 画像検索
- テキストによる画像生成
- ナビゲーション
まとめ
CLIPは、画像と言語を融合させた画期的なAI技術として、画像検索の精度向上から、直感的なナビゲーション、さらには高度な物体認識まで、その応用範囲は多岐にわたります。視覚と言語の壁を越えたAIとの対話は、新たな創造性を引き出し、問題解決の手法を変え、そして私たちの世界の見方さえも変えるかもしれません。
しかし、計算負荷の高さやデータの質の問題など、CLIPにはまだ克服すべき課題も存在します。これらの課題を解決し、技術をさらに洗練させていくことで、CLIPは人間とAIのコミュニケーションをより自然で効果的なものにしていくでしょう。
CLIPの進化は、

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

