
LLaVAとは?アーキテクチャ・特徴・マルチモーダル競合との比較を徹底解説!
最終更新日:2025年08月21日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

Microsoftとウィスコンシン大学マディソン校が公開したマルチモーダルAIであるLLaVA(Large Language and Vision Assistant)が注目を集めています。従来の画像認識AIと異なり、画像の内容について自然な対話ができる点が特徴です。
学習済みモデルとソースコードが公開されており、研究目的での利用が可能です。
本記事では、LLaVAの仕組みと性能、実用化に向けた可能性を交えながら徹底解説します。AI活用による業務改善を検討する開発者の方々に、実践的な知見をお届けします。
マルチモーダルAIにおいても中心的な役割を担う「LLM(大規模言語モデル)」とは何か?基本的な仕組みとその重要性についてはこちらで解説していますので、併せてご覧ください。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
ChatGPT/LLM導入・カスタマイズに強いAI開発会社を自力で選びたい方はこちらで特集していますので併せてご覧ください。
目次
LLaVAとは?
LLaVAは、Large Language and Vision Assistantの略称で、画像とテキストを組み合わせて理解・対話できるマルチモーダルAIモデルです。視覚情報と言語情報を統合的に処理し、人間のような自然な対話を実現することを目指して開発されました。
Microsoftとウィスコンシン大学マディソン校の研究者たちによって開発された、オープンソースのAIモデルで、現状は研究目的に限って使用できます。
LLaVAはHugging Faceでモデルを公開しており、GitHubでコードを提供しています。また、Microsoft ResearchのプロジェクトページでもLLaVAに関する情報が公開されています。
導入にはGPUが必要で、VRAMの容量に応じて8bitや4bit量子化オプションを使用できます。
LLaVAの特徴
| 特徴 | 説明 |
|---|---|
| マルチモーダル性能 |
|
| 学習方法 |
|
| データセット |
|
| オープンソース | コードと学習済みモデルが公開されており、研究目的で利用可能 |
LLaVAの学習アーキテクチャ
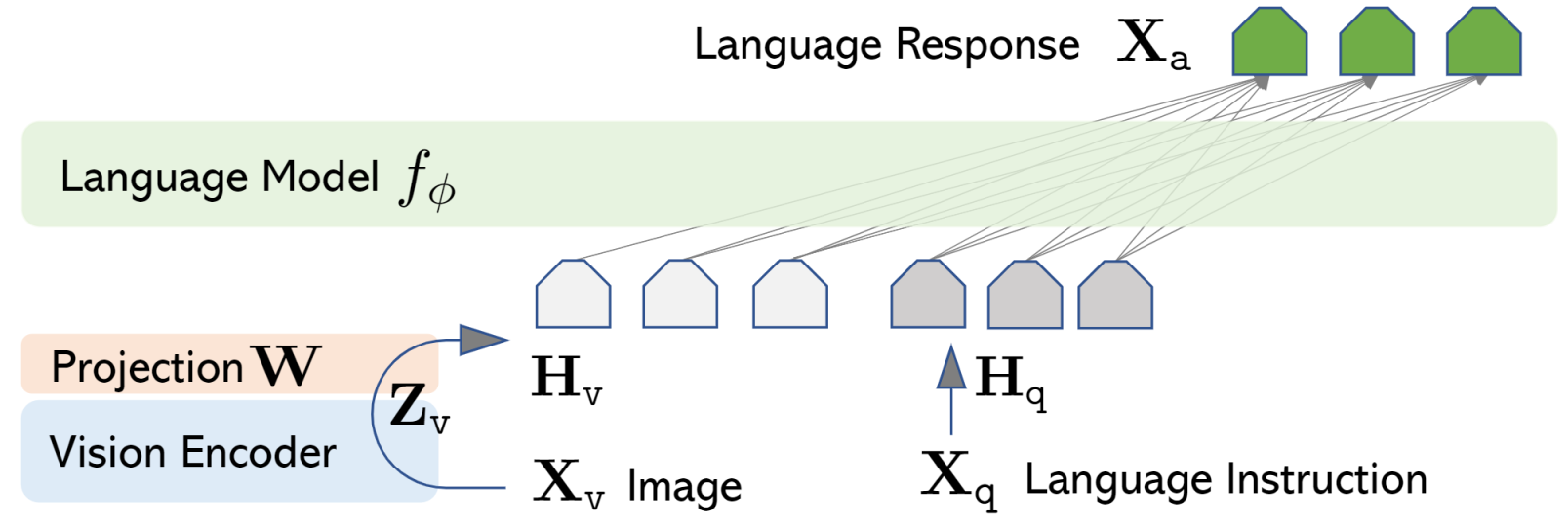
LLaVAの核となるアーキテクチャは、以下から構成されています。
- Vision Encoder:CLIP ViT-Lシリーズを使用
- LLM:LLaMAの派生モデルVicunaを使用
- Projector:上記2つを接続
このアーキテクチャの特徴は、画像特徴量と言語特徴量を効率的に結合できる点にあります。Vision Encoderで抽出された視覚情報は、Projectorを通じてLLMが処理可能な形式に変換されます。
両モジュールが事前学習済みであるため、比較的少量のデータ(約120万サンプル)で高性能なマルチモーダルモデルを構築できます。また、それぞれが独立して改善・更新できるため、各分野の最新の進展を容易に取り入れられます。
この構造により画像の文脈を考慮した自然な応答が可能となっています。
競合マルチモーダルAIモデルとの性能比較
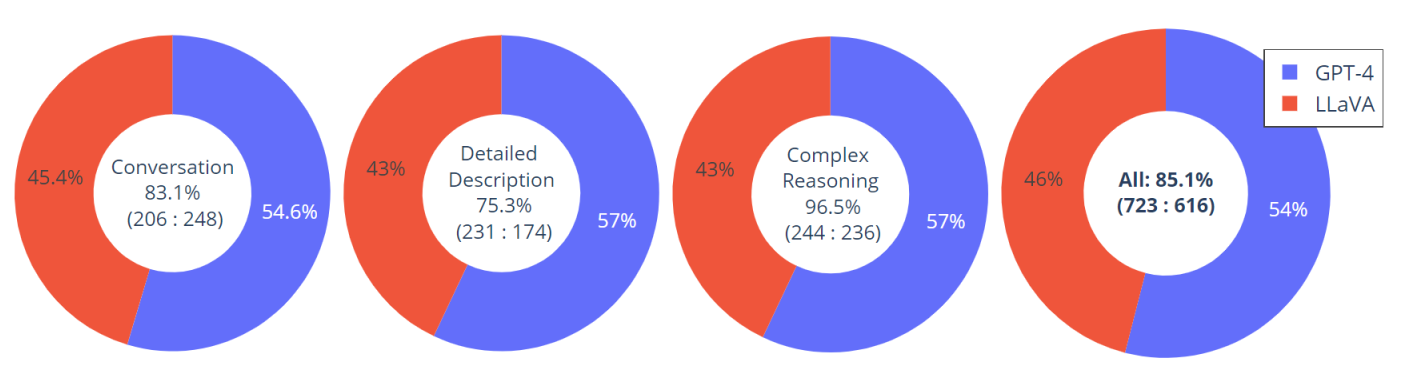
マルチモーダルAI市場において、LLaVAは特に注目すべき存在として位置づけられています。例えば、LLaVA-1.5は画像識別テストのVQAv2において80.0のスコアを達成し、より大規模なモデルであるPALM-e-562Bと同等の性能を示しています。
また、ChatGPTに搭載されているGPT-4Vとの比較においても、画像内容の事実確認や詳細な説明において、LLaVA-1.5は高い正確性を維持しながら、より自然な対話を実現しています。
このような性能の高さは、効率的な学習アーキテクチャと適切なデータセットの選択によって実現されており、オープンソースのマルチモーダルAIモデルとして高い評価を得ています。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
LLaVAの主要機能と対応タスク
LLaVAは、画像とテキストを組み合わせた高度な対話や分析が可能なマルチモーダルAIモデルとして、幅広い機能と応用性を備えています。様々な実用的なタスクに対応できる柔軟性を持っています。
現状は研究目的に限ったオープンソースですが、将来的にはLLaVA、またはLLaVAをベースにした商用利用可能なマルチモーダルAIモデルが公開されることが期待されます。
画像とテキストの双方向対話
LLaVAの最も特徴的な機能は、ユーザーとの自然な対話の中で画像を理解し、適切な応答を生成できる点です。
例えば、ユーザーが冷蔵庫の中身の写真を見せながら料理のアイデアを尋ねると、画像内の食材を正確に認識し、具体的なレシピや調理方法を提案できます。この双方向対話は、単なる画像認識を超えて、文脈を理解した上で関連性の高い情報を提供する高度な機能となっています。
また、倉庫や小売店舗における在庫管理は、LLaVAの導入により大きく効率化できます。従来の在庫管理では、作業員が商品を目視で確認し、手作業でデータを入力する必要がありました。しかし、LLaVAを活用することで、商品棚を撮影するだけで自動的に在庫状況を把握し、詳細なレポートを生成することが可能になります。
LLaVAは商品の種類、数量、配置状況を正確に認識し、自然言語で状況を説明できます。そのため、在庫の過不足や不適切な商品配置などの問題を即座に特定することができます。
また、画像による記録と分析により、季節変動や需要傾向の把握も容易になり、より効率的な在庫管理が実現できます。
複雑な視覚的推論と分析

視覚的推論においては、単純な物体認識を超えた高度な分析が可能です。LLaVAは画像内の要素間の関係性を理解し、論理的な推論を行うことができます。
例えば、映画のワンシーンから物語の文脈を読み取ったり、技術的な図面から実装方法を提案したりすることが可能です。特に医療分野では、LLaVA-Medとして特化型モデルも開発され、生物医学的な画像の詳細な分析と専門的な知見の提供を実現しています。
また、製造ラインにおける品質管理においても、LLaVAは重要な役割を果たします。製品の外観検査や不良品の検出において、LLaVAは人間の目では見落としがちな微細な欠陥も正確に検出することができます。
特に、LLaVAの高度な視覚的推論能力により、製品の異常を単に検出するだけでなく、その原因や対策までを自然言語で説明することが可能です。
製造工程で発生する様々な不具合パターンをLLaVAに学習させることで、品質管理の精度が向上し、不良品の発生を未然に防ぐことができます。また、作業員との自然な対話を通じて、複雑な品質基準の確認や製造プロセスの改善提案も行えるようになります。
マルチモーダルなデータ処理と出力生成
LLaVAのマルチモーダルデータ処理能力は、画像データをテキストトークンに変換し、言語モデルが処理可能な形式に変換することで、シームレスなマルチモーダル処理を実現しています。
不動産評価においても、LLaVAは変化をもたらしています。物件の内外装写真をLLaVAで分析することで、建物の状態、設備の劣化度、修繕の必要性などを客観的に評価できます。LLaVAは画像から物件の特徴を詳細に読み取り、市場価値に影響を与える要素を包括的に分析します。
さらに、LLaVAは物件写真から間取りや空間の使い方を理解し、改善点や価値向上のための提案を自然な言葉で説明できます。これにより、不動産業者は効率的に物件評価を行い、客観的なデータに基づいた提案を顧客に提供することが可能になります。また、時系列での物件状態の変化も正確に追跡できるため、長期的な資産管理にも活用できます。
これにより、画像の説明生成、視覚的な質問への回答、画像に基づく推論など、多様な出力形式に対応することが可能となっています。
まとめ
LLaVAは、画像分析と自然な対話を組み合わせることで、様々な業務課題の解決に活用できる可能性を秘めています。一方で、効果的な導入には業務プロセスの綿密な分析と、適切なデータ準備が欠かせません。
特に、GPT-4Vと同等の性能を持ちながらオープンソースで提供されている点は、導入を検討する企業にとって大きな魅力でしょう。
LLaVAについてよくある質問まとめ
- LLaVAはどのような技術で構成されているのですか?
LLaVAは、Vision EncoderとLLM、Projectorから構成されています。Vision EncoderにはCLIP ViT-Lシリーズを採用して画像特徴を抽出し、LLMにはVicunaを使用しています。これらをProjectorで接続することで、画像の文脈を考慮した自然な対話を実現しています。
- LLaVAの性能は他のAIモデルと比べてどうですか?
LLaVA-1.5は画像識別テストのVQAv2において80.0のスコアを達成し、より大規模なモデルであるPALM-e-562Bと同等の性能を示しています。また、GPT-4Vとの比較でも、画像内容の事実確認や詳細な説明において高い正確性を維持しています。
- LLaVAはどのようなライセンスで提供されていますか?
現在は研究目的での利用に限定されています。商用利用を検討する場合は、LLaVAをベースにした独自モデルの開発や、将来リリースされる可能性のある商用ライセンスの確認が必要です。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

