
ResNetとは?構造的特徴と2026年における画像認識モデル選定の判断基準・メリット・デメリットを徹底解説!
最終更新日:2026年02月23日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- 画像認識プロジェクトの社会実装において、ResNetは2026年現在も推論速度と投資対効果(ROI)のバランスが最も優れた標準的選択肢
- 残差学習(スキップ接続)が深層ネットワークの勾配消失を防ぎ、主要なAIフレームワークやエッジチップにおいてハードウェアレベルの最適化が完了している
- 独自ドメインの学習データが10万件未満のケースや、エッジデバイス上でのリアルタイム解析が必要な環境において、ResNetの優位性が最大化
- ResNet単体では画像全体の細かな関係性の把握に限界があるため、精度向上が停滞した際はバックボーンとして最新モデルへ組み込む設計変更を考慮する必要
「画像認識にAIを」と考えた際、まず名前が挙がるのがCNN系モデルのResNetです。2015年の登場から10年以上が経過しましたが、ResNetは過去の遺産ではありません。
膨大な計算リソースを消費する巨大なVision Transformer(ViT)やマルチモーダルLLMが台頭する一方で、実務でのROIの高さとエッジ環境での推論速度において、ResNet系アーキテクチャは依然として最適解であり続けています。
本記事では、
画像認識AI(人工知能)の実用化に興味がある企業担当者は、ぜひ最後までご覧ください。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
画像認識に強いAI開発会社をご自分で選びたい場合はこちらで特集していますので併せてご覧ください。
目次
ResNetとは?
ResNet(Residual Network)は、2015年に発表された画像認識のためのCNN(畳み込みニューラルネットワークモデル)の一つです。ResNetは、残差ブロックとスキップ接続の導入により、従来のディープラーニング手法では対応できなかった深層化を実現しています。
ResNetは、現代の画像認識技術の基礎となる重要なモデルとして位置づけられており、シンプルながら効果的な設計思想は、その後のディープラーニングモデルの開発に大きな影響を与えています。
参照:arXiv|Deep Residual Learning for Image Recognition
残差学習(Residual Learning)による勾配消失問題の解決と学習効率化の仕組み
ResNetは、従来のCNN(畳み込みニューラルネットワーク)で問題となっていた「勾配消失問題」や「学習時間の長さ」といった課題解決に大きく貢献し、ディープラーニングの分野において大きな進歩をもたらしました。
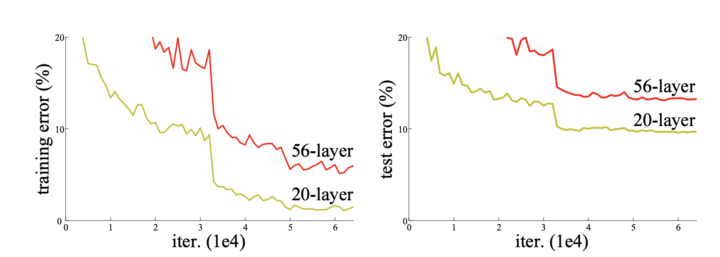
勾配消失問題とは、ネットワークがバックプロパゲーションで学習を進める際に、層を深くすると精度が低下する問題です。
単純に考えるとネットワークが深くなるほど高精度なアウトプットが期待されます。しかし、勾配消失により従来のディープラーニングでは20層以上になると学習が進まなくなり、精度が横ばい、もしくは悪化します。
また、従来のCNNでは層が深くなるとパラメータ量が増えるため処理が複雑化し、学習時間が膨大になる問題もありました。
これらの問題を、非常にシンプルな方法で解決したのがResNetです。残差ブロックと呼ばれる構造を導入し、入力をショートカットして後の層に直接足し合わせる「スキップ接続」を実装しました。この構造で、50層から152層という非常に深いネットワーク構造を実現しました。
尚、厳密には勾配消失問題を完全に解決したわけではなく、解決に近づくためのアプローチとなります。
ResNetと併用・比較されるVision TransformerやConvNeXt等の画像認識モデル一覧
画像認識技術は急速に進化しており、様々なモデルやサービスが登場しています。以下に、代表的な画像認識モデルとサービスを紹介します。
- U-Net:医用画像のセグメンテーションに特化したCNNアーキテクチャで、エンコーダ-デコーダ構造とスキップ接続が特徴的です。
- Vision Transformer (ViT):自然言語処理で成功を収めたTransformerを画像認識に応用したモデルで、大規模データセットで高い性能を示します。
- EfficientNet:モデルのスケーリングを最適化することで、少ないパラメータ数で高い精度を実現したCNNアーキテクチャです。
- CLIP:画像と自然言語を組み合わせて学習するマルチモーダルモデルで、柔軟な画像認識タスクに対応できます。
- Segment Anything Model (SAM):Meta AIが開発した汎用的なセグメンテーションモデルで、プロンプトベースで柔軟な領域抽出が可能です。
- ConvNeXt:ResNetのシンプルさを維持しつつ、Vision Transformerの学習手法を取り入れた「純CNN」の進化系
- OpenCLIP / SigLIP:生成AIで使われるモデル。ResNetはこれら巨大なマルチモーダルモデルの「画像特徴抽出器(バックボーン)」として今なお現役で組み込まれています。
Transformerの重さに課題を感じる現場ではConvNeXtが有力な移行先です。OpenCLIPやSigLIPと言った、生成AIの眼として使われるモデルでもResNetは画像特徴抽出器(バックボーン)として今なお現役で組み込まれています。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
画像認識AIにResNetを導入することで得られる7つの技術的・実務的メリット

ResNetは、その構造の優れた設計により、計算効率と精度の両立を実現します。本セクションで解説する主なメリットは以下です。
- エッジデバイス・省電力環境への高い適応性
- 高速処理が可能: シンプルな構成による計算リソースの節約
- 他のニューラルネットワークへの拡張性が高い: バックボーンとしての汎用性
- 世界モデルやAIエージェントの眼の役割
- 汎用性の高さ: 未知のデータに対する高い汎化性能
- 転移学習への応用: 事前学習済みモデルの活用によるコスト削減
- 実装の容易さ: 主要フレームワークでの標準サポート
エッジデバイスおよび省電力環境におけるResNetの推論効率と適応性
2015年当時は「152層の巨大モデル」として注目されたResNetですが、GPU性能が飛躍した現在では、むしろ「高い精度を維持したまま、FPGAやモバイルチップでも高速に動く軽量モデル」としての地位を確立しています。
特に、監視カメラ内でのリアルタイム解析や、ドローン、スマート工場の製造ラインといった「コンピュートリソースに制限がある現場」において、ResNetはViTを圧倒するコストパフォーマンスを発揮します。
計算リソースを抑えたResNetの高速処理能力とリアルタイムシステムへの適用
ResNetは、画像認識AIのなかでも比較的モデルの構成がシンプルなため、必要な計算リソースが少なくて済みます。また、残差接続によって勾配が減衰せずに伝わるため、学習速度が向上し、効率的なトレーニングが可能です。
これにより、システム全体の処理が高速化され、リアルタイム性が求められるようなシステムでも活用が期待できます。自動運転や監視システムなど、迅速な画像処理が求められる環境でResNetが積極的に活用されています。
特徴抽出器(バックボーン)としてのResNetの高い拡張性
ResNetは特徴抽出器として非常に優れた性能を持っています。そのため、セグメンテーションなど他のタスク向けのネットワークアーキテクチャにおいて、特徴抽出部分(エンコーダー部分)としてResNetを採用することが一般的になっています。
例えば、U-Netは元々独自のエンコーダー構造を持っていましたが、ResNetをエンコーダーとして採用することで性能が向上します。この組み合わせは「U-Net with ResNet backbone」や「ResNet-UNet」と呼ばれることがあります。
U-Net以外にも、FCN(Fully Convolutional Network)、DeepLab、PSPNet(Pyramid Scene Parsing Network)などの様々なセグメンテーションモデルでもResNetをバックボーンとして使用できます。
世界モデルやAIエージェントの視覚理解ブロックにおけるResNetの役割
OpenAIのSoraに代表される動画生成AIや、自律型AIエージェントが注目されていますが、これらの先端モデルの視覚理解ブロックには、ResNetの設計思想(特に残差ブロック)が色濃く残っています。
また、計算リソースを抑えつつ世界の状態をリアルタイムに認識する必要がある世界モデルにおいて、ResNet系アーキテクチャは「最も信頼性の高い軽量バックボーン」として再評価されています。
未知のデータに対するResNetの汎化性能と多種タスクへの適合性
ResNet の構造により、これらのモデルはデータ内のより一般的な構造を学習し、データセット固有の機能に焦点を当てません。これにより、モデルの一般化が向上し、未知のデータでより良い結果が得られます。
ResNetの構造は、データセット固有の特徴に偏らず、より一般的なパターンを学習することに優れています。これにより、未知のデータに対しても優れた性能を発揮します。
幅広いデータに対して柔軟に適用し、さまざまな画像認識タスクにおいて高精度な認識が可能です。また、画像分類、物体検出、セグメンテーションなど様々なコンピュータビジョンタスクに適用可能です。
ResNetを用いた転移学習による開発コスト削減と学習データの効率的活用
ResNetは、転移学習へ応用しやすい点が大きなメリットです。転移学習とは、あるタスクで学習したモデルを別の関連するタスクへ適用する学習方法です。
例えば、小規模な画像認識モデルしか使えない場合でも、ImageNetで事前学習されたResNetの重みを使用することで少ないデータでも効果的に学習できます。ResNetを転移学習に活用することで、計算リソースの大幅な節約が可能です。
関連記事:「AIの転移学習とは?ファインチューニングとの違い・仕組みやメリットを徹底解説!」
主要フレームワークにおけるResNetの標準サポートと実装・展開の容易性
ResNetの構造は高度にモジュール化されています。基本的な残差ブロックの繰り返しで構成されているため、コードの再利用性が高く、実装が比較的容易です。
また、PyTorch、TensorFlow、Kerasなどの主要なフレームワークでは、ResNet-18、ResNet-50、ResNet-101などの様々なバリエーションが事前に実装されています。使用方法も他のモデルと類似しており、モデルの定義、重みの読み込み、推論の実行などが統一されたAPIで行えます。
一度ResNetを実装すれば異なるタスクやシステムにも簡単に展開できるため、開発工数の削減につながります。
ResNetベースの画像認識システム導入における3つの制約とリスク

非常に強力なResNetですが、ViTやConvNeXtなどと比較した際には、いくつかの制約も明確になっています。導入判断の鍵となる、以下の3つの懸念点を整理します。
- 複雑なコンテキスト把握の限界:局所的な特徴抽出に依存するCNN特有の課題
- 過学習(オーバーフィッティング)のリスク
- モデルのブラックボックス性
Vision Transformerと比較して広域コンテキスト理解に関する表現力に限界
かつては「高い計算リソースが必要」とされていましたが、現在の課題はむしろ、「非常に複雑で広範なコンテキスト(文脈)の理解能力」において、最新のVision Transformerに一歩譲る点にあります。
例えば、画像全体の細かな関係性を把握する必要がある高度なセグメンテーションタスクでは、ResNet単体では限界があります。これを補うために、最新モデルのバックボーンとしての活用という戦略が必要になります。
過学習(オーバーフィッティング)リスク
ResNetは非常に深いネットワークであるため、特定の学習データに対して過度に適合してしまう、いわゆる「過学習」のリスクがあります。特に小規模なデータセットでは過学習が起こりやすくなります。
過適合は過剰適合(オーバーフィッティング)とも呼ばれ、AIモデルが訓練データの特徴を「暗記」してしまい、汎化性能が低下する可能性が高くなる問題です。つまり、未知のデータに対しては汎用性が低くなり、予測精度が落ちるのです。
ResNetのように層が深くなるにつれて、ネットワークの表現力が向上しますが、同時にパラメータの数も増加し、過学習のリスクが高まります。
そのため、汎用性の高いResNetを目指す場合には、適切な正則化やドロップアウトなどの手法を取り入れ、過適合を防ぐ対策が必要です。
モデルの説明可能性(XAI)に関する課題
ResNetは多層構造を持つため内部動作や学習プロセスを理解するのが難しい場合があります。特に、スキップ接続や残差ブロックの効果を直感的に把握するのは容易ではありません。
これは、説明可能性が重要な応用分野(医療診断など)では問題となる可能性があります。
ただし、Grad-CAMなどの手法を用いることで、「画像のどの部分が判断の根拠になったか」を熱分布(ヒートマップ)として可視化する手法があります。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
【2026年最新】ResNetの主な活用分野と実装事例

ResNetの「高速・安定」という特性は、特定の産業において代替不可能な価値を提供しています。現在、特に導入が加速している主要分野について、その理由とともに解説します。
- AIエージェント:視覚情報のトークナイザー
- コンピュータビジョン: 自動運転から自律型AIエージェントの「眼」としての活用
- 次世代医療画像解析: MRI・CTスキャンにおける微細病変の超高速検知
- バイオインフォマティクス: タンパク質構造予測や遺伝子解析への応用
律型AIエージェントにおける視覚情報の高速トークナイザー
ロボットが自ら判断して動くAIエージェントの分野では、視覚情報を高速にトークン化(デジタル処理可能な形式に変換)する必要があります。ここでResNetの「特徴抽出スピード」が重宝されています。
また、デジタルツインにおけるリアルタイムな物理現象のシミュレーションの入力層としても、その安定性からResNetが選ばれ続けています。
物体検出・画像分類等のコンピュータビジョン分野
ResNetは、コンピュータビジョン分野で最も広く利用されているモデルの一つです。画像分類や物体検出、セグメンテーションに対応できるため、特に以下の分野でResNetの導入が進んでいます
ResNetは、物体検出フレームワーク(例:Faster R-CNN)のバックボーンとしても広く使用されています。また、セマンティックセグメンテーション(DeepLabv3など)でも重要な役割を果たしています。
その高精度な認識能力により、リアルタイムでの映像処理が必要なシステムや、複雑なシーンの解析を行うシステムでの使用が特に効果的です。
MRI・CTスキャン等の次世代医療画像診断支援
医療分野では、ResNetがMRIやCTスキャンなどの医療画像の解析に利用されています。疾患の早期発見や診断支援において、ResNetの高精度な解析能力が活用され、医療の精度向上と診断の迅速化に貢献しています。
特に、臓器や腫瘍のセグメンテーション、異常部位の検出で効果を発揮することから、さまざまな医療用画像診断システムへ導入されています。
医療業界に強いAI開発会社をこちらで特集していますので併せてご覧ください。
タンパク質構造予測や遺伝子解析等のバイオインフォマティクス分野
ResNetはタンパク質構造予測や遺伝子発現解析などの生物学的データ解析にも応用されています。
タンパク質構造予測は生物学や薬学において重要な課題で、バイオインフォマティクスの中心課題となっています。ResNetはアミノ酸配列からその立体構造を推定する際に役立ちます。ResNetの残差接続は、非常に深いネットワークでも効果的に学習を進めることができるため、複雑なタンパク質構造の特徴を捉えるのに適しています。
遺伝子発現解析では、ResNetが遺伝子の発現パターンを解析するために利用されます。これにより、特定の条件下でどの遺伝子が活性化されるかを理解し、病気のメカニズムや治療法の開発に貢献します。ResNetは、大量の遺伝子データから有意義なパターンを抽出する能力があり、高精度な解析結果を提供します。
2026年の画像認識プロジェクトにおけるResNetと次世代モデルの選定判断基準3ポイント
画像認識AIの世界では「Vision Transformer(ViT)こそが正義」という潮流が一巡し、ROIと環境」に基づいた使い分けが主流となっています。既存のResNetベースのシステムを最新アーキテクチャへリプレイスすべきか、あるいは維持すべきかの判断基準となる重要な3つの論点を整理します。
- データセットの経済的な境界線: 10万件未満のデータ量におけるResNetの優位性
- 極限のリアルタイム性: 推論レイテンシ10ms以下の要件とハードウェア最適化
- 監査・説明責任のハードル: XAI(説明可能なAI)の観点から見たモデル選定
データセットが10万件未満ならまだまだResNet
独自のドメインデータ(自社工場の不良品画像や特定の医療画像など)が10万件に満たない場合、ResNetからTransformer系への移行は精度の低下とコストの増大を招くリスクがあります。
これは、学習効率の構造的な違いに起因します。
ResNetなどのCNNは、「近接する画素同士には関連がある」という画像特有のルール(帰納バイアス)が構造に組み込まれています。そのため、少ないデータからでも効率的に特徴を学習できます。
一方のViT(Vision Transformer)は、こうした前提を持たず、ゼロからデータ間の関係性を学習します。確かに、大規模なデータセット(数百万〜億単位)があればResNetを凌駕します。
しかし、小規模データでは「何が重要か」を学習しきれず、過学習を起こしやすくなります。
特殊なニッチ分野でのAI活用や、データ収集コストが高い現場においては、ResNetを維持し、余った予算を「データの質」の向上に投資する方がROIは高まります。
推論レイテンシ(応答速度)が10msを切る必要がある場合の選択肢
自動運転、高速移動する検品ライン、あるいはAR(拡張現実)デバイスといった推論レイテンシ10ms以下(100FPS超)が求められる現場では、現在もResNet系が最強の選択肢の一つです。
最新のGPUやNPU(AI専用プロセッサ)において、ResNetのアーキテクチャは最も最適化が進んだ(いわゆる枯れた)構造です。
Transformerが採用する「Attention(注意機構)」は、画像サイズが大きくなるほど計算量が二次関数的に増大します。対してResNetの畳み込み演算は定量的で、メモリ帯域を効率的に使い切ることができます。
NVIDIAのTensorRTや各種エッジAIチップにおいて、ResNetの「スキップ接続」はハードウェアレベルで高速化の恩恵を受けられます。
10msの壁を突破する必要があるなら、無理にモデルを最新化するのではなく、ResNetをTensorRT等で極限まで最適化するか、あるいはResNetの構造を継承しつつ近代化したConvNeXtなどの派生モデルを検討すべきです。
説明可能性(XAI)の観点から見たResNetの優位性と限界
「なぜAIがその判断を下したのか」という説明責任(アカウンタビリティ)が重視されるビジネス環境において、ResNetの分かりやすさは大きな武器になります。
ResNetは、Grad-CAMなどの手法を用いることで、「画像のどの部分が判断の根拠になったか」を熱分布(ヒートマップ)として可視化しやすい特性があります。これは、エンジニアではない上層部や現場の医師、検査員に納得感を与える上で極めて有効です。
Transformer系でも注意機構の可視化は可能ですが、画像全体の広範な関係性を考慮するため、人間にとって「直感的ではない」根拠が提示されることが少なくありません。
医療、法規制、安全管理など、判断ミスが許されず、かつ「理由」が求められる業務プロセスにおいては、精度が数%劣ったとしても、説明性の高いResNetを選択する経営判断が正解となるケースが多々あります。
ResNetについてよくある質問まとめ
- ResNetを導入する際の主な課題は何ですか?
ResNet導入時の主な課題は以下の通りです:
- 過学習のリスク:深層構造ゆえに、特に小規模なデータセットでは過学習が起こりやすくなります。適切な正則化やデータ拡張などの対策が必要です。
- モデルの解釈性:多層構造のため、内部動作や学習プロセスの理解が難しい場合があります。説明可能性が重要な分野では課題となる可能性があります。
- 適切なモデル選択:ResNetには様々な層数のバリエーションがあり、タスクに適したモデルの選択が重要です。
これらの課題に対しては、専門家のアドバイスを受けながら、適切な設計と運用戦略を立てることが重要です。また、小規模な実験から始め、段階的に規模を拡大していくアプローチも効果的です。
- ResNetは他のCNNモデルと比べてどのような点が優れていますか?
ResNetの主な優位点は以下の通りです。
- 深層化による高精度化:残差ブロックとスキップ接続により、非常に深いネットワーク(50層以上)でも安定した学習が可能です。
- 勾配消失問題の解決:スキップ接続により、勾配が直接伝わりやすくなり、深層でも効果的な学習が可能です。
- 汎用性:様々な画像認識タスクに適用でき、他のモデルのバックボーンとしても利用可能です。
- 転移学習の容易さ:事前学習済みモデルを使用することで、少ないデータでも効果的に学習できます。
これらの特徴により、ResNetは多くの画像認識タスクで高い性能を発揮し、幅広い分野で活用されています。
- 自社のプロジェクトで、最新のTransformer系ではなくResNetを使い続ける「経営的なメリット」は何ですか?
最大のメリットは、「不確実性の低減」と「インフラコストの抑制」にあります。ResNetは10万件以下のデータセットでも学習が収束しやすく、高価な最新GPUを積めないエッジ環境(工場内カメラやドローン等)でも高速に動作します。最新技術を追うあまり、過剰な計算リソースと膨大なデータ収集コストを投じてROIを悪化させるリスクを避けられます。
「自社の要件にどのモデルが最適か判断が難しい」という場合は、ぜひAI Marketへご相談ください。貴社の課題をヒアリングした上で、ResNetの最適化に強い会社や、次世代モデルへの移行タイミングを的確にアドバイスできる専門家を無料で選定し、ご紹介します。
- 社内のエンジニアから「精度向上のためにモデルの最新化が必要」と言われていますがどう判断すべきでしょうか?
「精度向上が事業利益に直結するか」と「説明可能性の担保」の2点で判断してください。もし数%の精度向上が数億円の利益を生むならリプレイスの価値がありますが、同時に「なぜAIがその判断をしたか」という説明責任(XAI)が求められる現場では、可視化手法が確立されているResNetの方が適している場合もあります。
エンジニアの技術的提案をビジネス言語に翻訳し、最適な開発パートナーを探すのは手間がかかる作業です。AI Marketのコンシェルジュにご相談いただければ、技術とビジネスの橋渡しができる審査済みの開発会社を、独自のノウハウに基づいて厳選してお繋ぎします。
まとめ
ResNetは、画像認識技術に革新をもたらし、ビジネスの様々な分野で活用されています。コンピュータビジョン、医療用画像解析など、幅広い領域での応用が進み、業務効率化と精度向上に大きく貢献しています。
一方で、高い計算リソースの必要性や過学習のリスクなど、導入に際して考慮すべき点もあります。これらの課題に対しては、適切な設計と運用戦略が重要です。
ResNetを活用することで、計算リソースを最小限にした高精度な画像認識システムを開発できます。画像認識技術は日々進化しています。ResNetの導入を検討し、ビジネスの競争力強化に向けた一歩を踏み出してみませんか?

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

