
Segment Anything Modelとは?Metaのセグメンテーションモデルの特徴、活用事例を徹底解説!
最終更新日:2026年01月14日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

AIを活用した画像認識技術は向上しており、画像内の対象物を正確に特定・分離するセグメンテーション技術を実務に導入しているケースも多く見られます。近年はさまざまなセグメンテーション手法が登場し、どんな物体でも検出できるようになっています。
しかし、従来の画像セグメンテーション技術では、専門的な知識や複雑な設定が必要となり、多くの企業で導入の障壁となっていました。
そこで、2023年4月にMeta社が開発したSegment Anythingは、特定のポイントを自動で検出し、セグメンテーションするのに特化したZero-ShotモデルとしてAI開発領域で非常に注目されています。ユーザーが入力するプロンプトからセグメンテーションを行うため、これまでのAI開発プロセスを大きく変えています。
この記事では、Segment Anythingの概要から特徴、注意点、活用事例を解説していきます。使いやすいセグメンテーション技術の導入を考えている方におすすめのモデルであるため、興味がある方はぜひ本記事を参考にしてみてください。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
画像認識に強いAI開発会社をご自分で選びたい場合はこちらで特集していますので併せてご覧ください。
目次
Segment Anything Modelとは?
Segment Anything Model (SAM)とは、2023年4月にMeta AIによってリリースされたプロンプトベースで動作する画像セグメンテーションモデルです。ユーザーが指定したプロンプトに基づいて画像内の任意の領域を自動的に識別・分割できます。
画像セグメンテーションとは、画像中のオブジェクトやエリアをピクセル単位で区別する技術を指します。
Segment Anything(SAM)は、その名の通り「何でもセグメントする」ことを目指した汎用性の高いモデルです。領域やオブジェクトに特化した従来のセマンティックセグメンテーションやインスタンスセグメンテーションと言った画像セグメンテーション技術の特徴を併せ持ちつつ、それらを超えた柔軟性と汎用性を有しています。
例えば、ユーザーがテキストプロンプトやクリック操作等によって指示を出すだけで、その対象物を画像内から即座に抽出し、セグメント化することが可能です。
Zero-Shot 推論が可能で、事前学習なしに多様な画像やドメインに対応できるという特徴を持ちます。以下のように、対象物をクリックしたり、バウンディングボックスで囲うだけで、対象物をセグメンテーションすることができます。

このように、Segment Anythingは、多様な利用シーンに対応できる汎用的なモデルとして、画像解析の新たな可能性を広げ、AI技術の実用化において重要な役割を果たしています。
モデルアーキテクチャ
Segment Anythingのモデルアーキテクチャは、画像セグメンテーションを高精度かつ迅速に行うために設計された以下の3つのコンポーネントから構成されています。
- 画像エンコーダ
- プロンプトエンコーダ
- 軽量マスクデコーダ
画像エンコーダはVision Transformer (ViT) をベースとしたアーキテクチャを採用し、入力画像を高次元の特徴マップに変換します。画像全体の情報を効果的に捉える役割を果たします。これにより、モデルは細かなディテールから広範な文脈まで、多様なレベルで情報を解析できます。
プロンプトエンコーダは、ユーザーが提供するプロンプトを処理し、画像エンコーダによって生成された特徴マップと統合します。モデルはユーザーの指示を理解し、セグメント化の対象を正確に特定することが可能です。
そして、軽量マスクデコーダが画像の特徴マップとプロンプトの情報をもとに、セグメント化されたマスクを迅速に生成します。このデコーダは計算負荷が少ない設計になっており、リアルタイムでの応答が求められるアプリケーションにも対応可能です。
これら3つのコンポーネントが連携することで、Segment Anythingは幅広いシーンやオブジェクトに対して高い柔軟性と精度を持つ画像セグメンテーションを実現しています。
Segment Anything Model のバージョンヒストリー
| バージョン | リリース | コアコンセプト | 入力プロンプト | アーキテクチャの特徴 |
| SAM 1 | 2023年4月 | ゼロショットでの画像の切り抜き |
| ViT + Mask Decoder |
| SAM 2 | 2024年7月 | 動画への拡張 |
| + Memory Mechanism |
| SAM 3 | 2025年11月 | 概念の理解と統合 |
| + Concept / Presence Head |
SAMはバージョンを追うごとに処理対象を「静止画(2D)」→「動画(2D+Time)」→「意味空間(Semantic)」へと拡大しています。これは、AIが単なるツールから、人間の意図を理解するパートナーへと進化していることを示しています。
Segment Anything Model (SAM) ファミリー比較
MetaのSegment Anything(あらゆるものを切り出す)という思想は、画像から始まり、現在では動画、3D、そして音声へとその領域を急速に広げています。
これらのモデル群は、特定の対象を学習し直すことなく、プロンプト(指示)だけで未知の対象を抽出できるゼロショット性能を共通の核としています。SAMファミリーの主要モデルを整理しました。
| モデル名 | 対象(モダリティ) | 主要な特徴・機能 |
| SAM | 動画 / 静止画 | 動画内の動く物体をリアルタイムで追跡・分離。一貫したマスク生成。 |
| SAM Audio | 音声 / 音響 | テキストや映像内の物体指定により、混ざり合った音源から特定の音を抽出。 |
| SAM 3D | 3D空間 (NeRF等) | 2DのSAMを3D空間に投影し、立体データから特定の物体を分離。 |
| MedSAM | 医療画像 | 専門的な医療用画像(CT/MRI等)に特化して調整されたセグメンテーション。 |
| MobileSAM | モバイル/エッジ | SAMの精度を維持しつつ、軽量化。スマートフォン等での高速動作。 |
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
Segment Anythingの特徴

Segment Anythingは、従来の画像セグメンテーション技術の常識を塗り替える特徴を備えています。
プロンプトでセグメント化を指定できる
Segment Anythingの大きな特徴として、プロンプトを使って直感的にセグメント化を指定できる点が挙げられます。これにより、ユーザーは複雑な画像認識AIモデルを構築したり、アノテーションを行うことなく、簡単に任意のオブジェクトやエリアを画像内から抽出することが可能です。
例えば、テキストプロンプトで「猫」や「車」などの対象物を指定したり、画像上の特定の位置をクリックしてセグメント化の範囲を示したりすることで、モデルはその指示に基づいて対象をセグメント化します。従来の固定的なセグメンテーション方法と異なり、ユーザーの目的に応じた多様なシーンでの応用が可能となります。
プロンプトによるセグメント化は、手作業による編集やデータ準備にかかる手間を大幅に軽減し、効率的な画像解析を実現するための要素となっています。
画像認識技術は急速に進化しており、様々なモデルやサービスが登場しています。以下に、代表的な画像認識モデルとサービスを紹介します。
- U-Net:医用画像のセグメンテーションに特化したCNNアーキテクチャで、エンコーダ-デコーダ構造とスキップ接続が特徴的です。
- ResNet:深層ネットワークの学習を可能にしたモデルで、残差接続により勾配消失問題を解決しました。
- EfficientNet:モデルのスケーリングを最適化することで、少ないパラメータ数で高い精度を実現したCNNアーキテクチャです。
- Vision Transformer:画像認識にTransformerを利用したモデル。自然言語処理で成功を収めたTransformerアーキテクチャを画像認識タスクに適用
- CLIP:画像と自然言語を組み合わせて学習するマルチモーダルモデルで、柔軟な画像認識タスクに対応できます。
曖昧なプロンプトにも対応
Segment Anythingでは、ユーザーが曖昧なプロンプトを与えた場合でも柔軟に対応することが可能です。従来の画像セグメンテーション技術ではプロンプトでの具体的な指示が必要でしたが、Segment Anythingは大規模な学習データに基づいて適切なセグメント化を行います。
例えば、「中央の物体」や「青い部分」など具体的なオブジェクト名を指定しないプロンプトでも、モデルは画像のコンテキストを理解し、該当する領域を自動的に検出します。これにより、ユーザーが必ずしも明確な指示を与えなくても、画像内の興味のある部分を迅速かつ的確に抽出することが可能です。
曖昧なプロンプトへの対応が可能になることで、利便性が高まります。これにより、さまざまな応用分野で幅広いユーザー層に利用されやすくなるでしょう。
画像内のすべてを自動セグメントが可能
Segment Anythingは、画像全体を自動的にセグメント化する機能を備えています。ユーザーが特定のプロンプトを与えなくても、画像内のオブジェクトや領域を識別して分割することが可能です。
例えば以下のように、画像内にある建物や橋、空、雲、といった要素を自動で識別してセグメンテーションが行われます。

この機能は、大規模な画像データセットや複雑なシーンを扱う際に有用です。事前のラベル付け作業を行わなくても、迅速にセグメント化を行うことができます。
また、自動的にセグメントされたマスクは、後からユーザーが必要に応じて修正や微調整を行うことも可能で、編集作業の柔軟性が大幅に向上します。画像内のすべてを自動的にセグメント化できる機能は、セグメンテーション作業の効率を高めることが期待されています。
Zero-Shot Learning(ゼロショット学習)
Segment AnythingではZero-Shot Learning(ゼロショット学習)を活用して、新しいシーンや未知のオブジェクトに対しても高精度にセグメント化を行います。通常、従来の画像セグメンテーションモデルは特定のデータセットでトレーニングされるため、そのデータセットに含まれるオブジェクト以外には対応が難しい課題がありました。
しかし、Segment Anythingは大規模で多様なデータセットで事前学習されているため、特定のドメインやタスクに依存せずにさまざまなシーンに対応可能です。プロンプトを介してユーザーが指定した対象に対して、事前に学習していないオブジェクトでも即座にセグメント化を行うことができます。
ゼロショット能力はセグメント化において新たな可能性を広げており、特定のデータセットに依存しない汎用性の高いソリューションを提供することで、さまざまな分野での実用化が期待されています。
関連記事:「Zero-Shot Learning(ゼロショット学習)とは何なのか、メリットデメリット、他の手法との違い、活用事例などを詳しく解説」
オープンソースとして利用できる
Segment Anythingはオープンソースとして提供されているため、誰でも自由にアクセスでき、モデルのカスタマイズやアプリケーションの開発が可能です。これによってコミュニティ全体の技術発展を加速させ、多様な分野での応用を促進します。
Segment Anythingのソースコードや事前学習されたモデルはGitHubなどのプラットフォームで公開されており、自由にダウンロードして利用できます。また、他のオープンソースプロジェクトと組み合わせて使用することで、より高度なシステムやアプリケーションの開発が可能となります。
Apache 2.0ライセンスで公開されていますので、商用利用を含む幅広い用途での使用を許可しています。ただし、Segment Anything Model 2の一部のコンポーネントはBSD-3-Clauseライセンスで、商用利用に制限がある可能性があります。
オープンソースとして利用できるSegment Anythingは、ユーザーが自由に技術を活用し、革新的なモデルを生み出すための土台となるでしょう。多くの開発者が技術を進化させていくことで、セグメンテーション技術のさらなる発展が期待されています。
大量の画像学習データで学習している
Segment Anythingは、11百万枚の画像と11億のセグメンテーションマスクで学習された大規模な画像データセットで学習してています。膨大なデータを学習することで、Segment Anythingは新しい環境や未知のオブジェクトに対しても高い精度でセグメント化を行うことが可能です。
大規模な学習データで学習していることは、Segment Anythingの解析精度を支える要素となっており、さまざまなユースケースにおいて優れたパフォーマンスを発揮する要因となっています。
Segment anythingの注意点
Segment Anythingは優れた画像セグメンテーション技術を持つ一方で、いくつかの注意点も存在します。これらの点を理解することで、モデルを効果的に活用し、期待通りの結果を得ることが可能になります。
特定のドメインに特化したモデルと比べると精度が劣る
Segment Anythingは汎用性の高い画像セグメンテーションモデルとして設計されています。そのため、特定のドメインに特化したモデルと比べると精度が劣る場合があります。
例えば、医療画像や特定の工業製品の検査といった専門的な領域では、その分野に特化したモデルのほうが高い精度でセグメント化を行えることが多いです。
Segment Anythingは多様なデータセットで学習しているため、幅広いシーンに対応できる汎用的な能力を持つ一方で、個別ドメインの詳細な特徴を深く学習しているわけではありません。そのため、特定の業界や用途における識別が必要な場合には、ドメイン固有のモデルや追加の微調整が求められることがあります。
出力結果の質はプロンプトの与え方に大きく依存
Segment Anythingの出力結果は、プロンプトの与え方によって大きく左右されます。適切なプロンプトを提供することで高精度なセグメント化が可能になりますが、曖昧な指示や不適切なプロンプトでは期待通りの結果が得られない、ということにもなります。
特に、細かな境界や複雑なオブジェクトをセグメント化する場合には、具体的なプロンプトが求められます。プロンプトが明確であればモデルは対象物を正確に識別しますが、不十分な情報しか与えられない場合、意図しない領域がセグメント化されるリスクがあります。
このように、出力結果の質はプロンプトの品質に依存するため、セグメント化を行う際にはプロンプトの書き方を工夫しなければいけません。
オブジェクトの分類やラベリングは不可能
Segment Anythingは画像中のオブジェクトを自動的にセグメント化する機能を持っていますが、セグメント化された領域に対して分類やラベリングを行うことはできません。つまり、画像内の物体を境界で区切ることには優れていますが、それらのオブジェクトが何であるかは特定できないということです。
そのため、オブジェクトの具体的な分類や名前付けが必要な場合には、別のモデルや追加の処理が必要となります。用途によってはResNetやEfficientNetなど他の分類モデルと組み合わせ、実用的なワークフローを構築することが求められます。
関連記事:「AIの画像分類に関して概要から活用シーン、画像分類の流れを分かりやすく解説」
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
Segment Anythingの実務での活用事例

Segment Anythingの汎用的なセグメンテーション技術は、さまざまな実務分野での活用が進んでいます。ここでは、具体的な応用事例を通じて、どのように実務で役立っているのかを解説していきます。
医療画像の診断
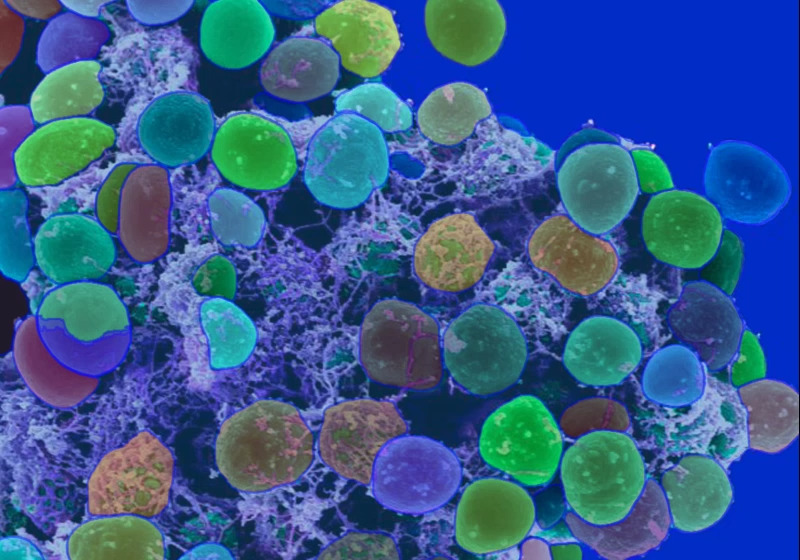
医療分野では、MRIやCTスキャンなどの画像から病変部位や異常を識別することが求められます。
この作業は従来、専門家による手作業のセグメンテーションに依存していました。そのため、Segment Anythingを使用することで画像内の組織や病変の領域を自動的にセグメント化でき、診断の効率と精度を向上させることが可能です。
特に、皮膚がんの早期発見や脳の異常部位の特定、細胞画像のセグメンテーションは迅速な対応が求められるため、Segment Anythingは医療従事者の負担を軽減し、診断プロセスの短縮を実現します。さらに、セグメント化された領域をもとに追加の解析や定量的評価を行うことで、医師のノウハウを反映させた詳細な診断情報を提供することが可能です。
Segment Anything Model 2の導入により、動画ベースの医療イメージング(例:内視鏡検査)でのリアルタイム解析も可能になっています。
自動運転技術
Segment Anythingは、自動運転技術においても重要な役割を果たしています。カメラやセンサーにSegment Anythingを用いることで、周囲の状況を記録した動画像を自動的にセグメント化し、リアルタイムでの周囲認識を支援します。
特に、従来のセグメンテーションモデルでは難しかった未知のオブジェクトや予測が困難なシーンにおいて、Segment Anythingのゼロショット能力が効果的です。これにより、事前に学習していない交通状況でも適切に認識し、自動運転の安全性の向上に貢献します。
Segment Anything Model 2の動画セグメンテーション能力はリアルタイムで物体を追跡できるため、自動運転システムの性能を大幅に向上させる可能性があります。
ロボティクス
Segment Anythingは、ロボティクスの分野でも活用することができます。産業用ロボット、医療ロボット、農業ロボット、消費者向けロボットなど、幅広い分野での応用が期待されています。
ロボットが複雑な作業環境で動作するには、周囲の物体や障害物を正確に認識し、適切に操作することが不可欠です。Segment Anythingは、ロボットがカメラを通じて取得した映像をもとに周囲の物体をリアルタイムでセグメント化し、それらの形状や位置を把握することを可能にします。
特に、Segment Anything Model 2で導入されたリアルタイムの動画セグメンテーション能力により、ロボットの環境認識と対話能力を向上させることができます。
これにより、ピッキング作業や部品の選別など多様なタスクでの自動化をサポートします。特に、予期しない物体や新しい環境に対してもゼロショットで対応できるため、従来のルールベースのシステムでは困難だった環境にも適応することが可能です。
Segment Anythingについてよくある質問まとめ
- Segment Anythingとは何ですか?
Segment Anything Model(SAM)は、画像内の対象オブジェクトを抽出するための高性能なセグメンテーションモデルです。オブジェクトを点やバウンディングボックスなどで指定するプロンプトを用いることで、柔軟かつ高精度なセグメンテーション結果が得られます。
- Segment Anythingは特定業界向けの既存のセグメンテーションツールと比べてどうですか?
Segment Anything Model(SAM)は汎用性が高く導入が容易である一方、医療画像分析など特定領域では専用モデルの方が高精度な場合があります。用途に応じて使い分けや組み合わせの検討が推奨されます。
まとめ
汎用的な画像セグメンテーションモデルであるSegment Anything Modelは、多様なシーンやオブジェクトに対応できる柔軟性を兼ね備えています。直感的なプロンプトの指定や、画像全体の自動セグメント化を可能にするオープンソースとして、さまざまなユーザーが利用できます。
一方で、特定の分野に特化したモデルと比較すると精度が劣る場合があるなど、用途によっては従来のモデルが有効というケースもあるため、使い分けることが重要です。実際の業務への適用においては、既存のワークフローとの統合や、特定業務に最適化されたモデルの選択など、専門的な判断が必要となる場面も多くあります。
現状のセグメンテーション技術を向上させたい、AI開発スピードを高速化したいと考えている方は、Segment Anythingの活用を検討してみましょう。なお、導入を検討する際は、専門家に相談するのがおすすめです。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

