
【AI論文解説】Concept Arithmetics for Circumventing Concept Inhibition in Diffusion Models:拡散モデルのコンセプト抑制を突破する新たな手法
最終更新日:2024年11月08日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

近年、テキストから画像を生成する拡散モデルは急速に発展しており、芸術やデザイン、マーケティングなど多様な分野での応用が進んでいます。一方で、その強力な生成能力の高さから、著作権で保護された作品や暴力的・不適切なコンテンツの生成といった倫理的・法的な問題が生じています。
これらの問題を解決するため、研究者たちは特定のコンセプトをモデルから抑制する手法を開発していますが、本論文では、拡散モデルの合成特性を利用することで、既存の抑制手法が回避可能であることを明らかにしています。
本論文は、ECCV(European Conference on Computer Vision) 2024でHonorable Mentionsに選ばれた論文です。
- 論文名:Concept Arithmetics for Circumventing Concept Inhibition in Diffusion Models
- 論文著者:Vitali Petsiuk, Kate Saenko
- 論文提出日:2024年4月21日
- 論文URL:https://arxiv.org/abs/2404.13706v1
目次
論文の要約
この論文では、画像を生成するAIモデルにおいて、特定の不適切な内容を出力しないようにする手法があるものの、それらの手法が実際には完全ではなく、ある方法を使えば抑制された内容を再現できてしまうことを示しています。
具体的には、複数の入力を組み合わせることで、元々は生成できないはずの内容を生成する方法を提案しています。これにより、AIモデルの安全性について再考する必要があることを示唆しています。

ポイント
- 拡散モデルの合成特性を利用して、抑制されたコンセプトを再構築する方法を開発
- 既存のコンセプト抑制手法が、モデルの合成推論を用いた攻撃に脆弱であることを理論的・実験的に示した
- 安全なモデルの展開における拡散モデルの合成性とコンセプト演算の影響について議論を促進
論文研究内容詳細
この研究は、テキストから画像を生成する拡散モデルに対して、特定のコンセプト(例:暴力的なイメージ、露骨な内容、著作権で保護された作品など)を抑制するための既存の手法が、実際にはそのコンセプトを完全に除去できていないことを明らかにしています。
近年、倫理的および法的な懸念から、これらの不適切な内容を生成しないようにするために、モデルを再訓練したり、特定のコンセプトを「忘れさせる」手法が提案されています。
しかし、著者たちは、拡散モデルの持つ合成特性(補足: 複数のプロンプトを組み合わせて一つの画像を生成できる性質)、すなわち複数のプロンプトを組み合わせて一つの画像を生成できる性質を利用することで、抑制されたコンセプトを再構築できることを示しています。
具体的には、「ケーキ」という無関係なプロンプトと「抑制されたコンセプト」を組み合わせ、その差分を取ることで、元のコンセプトに対応するガイダンスベクトルを再現できます。

この攻撃手法は、モデルの重みや詳細な内部構造にアクセスする必要がなく、ブラックボックス的な環境(補足: モデルの内部構造が未知のまま操作する環境)でも実行可能であり、現実的な脅威となり得ます。
また、理論的な分析と実験的な結果を通じて、この攻撃手法の有効性を示し、拡散モデルの安全な運用において、合成推論やコンセプト演算が持つ影響を深く理解する必要があると結論付けています。
先行研究との比較
本研究の優れている点は、拡散モデルのコンセプト抑制手法に対する新たな脆弱性を発見し、既存の手法が想定していなかった攻撃経路を明らかにしたことです。
先行研究では、特定のコンセプトを抑制するために、モデルの重みを微調整したり、特定のガイダンスを無効化する手法が提案されていましたが、これらの手法は主に直接的なプロンプト操作やモデルの内部へのアクセスを必要とするものでした。
しかし、著者たちは、拡散モデルの合成推論(補足: 複数のプロンプトを組み合わせて画像を生成する手法)を利用することで、モデルの重みや詳細な内部構造にアクセスすることなく、抑制されたコンセプトを再現できることを示しました。
この攻撃手法は、モデルの合成性と線形性に基づいており、従来の抑制手法では考慮されていなかった新たな観点を提供しています。
また、この攻撃は、特別な技術的知識やリソースを必要とせず、ブラックボックス的な環境でも実行可能であるため、実際のモデル運用において現実的な脅威となり得ます。
さらに、理論的な分析と実験的な検証を組み合わせることで、攻撃の有効性を包括的に示しており、拡散モデルの安全な展開に向けた新たな課題を提起しています。
本提案技術・手法のキモ
この研究の技術的なキモは、拡散モデルの持つ合成特性と線形性を利用した攻撃手法の開発にあります。
具体的には、モデルが複数のプロンプトからのガイダンスを線形に組み合わせることで、一つの画像を生成する性質を活用しています。著者たちは、抑制されたコンセプト(例えば「禁止された対象」)と無関係なデタープロンプト(補足: 攻撃のために利用される無関係なプロンプト、例:「ケーキ」や「テキスト」)を組み合わせ、そのガイダンスの差分を計算することで、抑制されたコンセプトに対応するガイダンスベクトルを再現できることを示しました。
具体例として、「ケーキの形をした禁止された対象」というプロンプトから「ケーキ」のガイダンスを差し引くことで、元の禁止された対象のガイダンスを得ることができます。

この方法は、モデルの重みや内部構造にアクセスする必要がなく、ブラックボックス的な環境でも実行可能です。また、この攻撃手法は、モデルの合成性と線形性に基づいており、既存のコンセプト抑制手法が想定していない攻撃経路を提供しています。さらに、理論的な枠組みを構築し、攻撃が有効である理由を数学的に説明しています。
攻撃の有効性を理論的に裏付けることで、その一般性と再現性を示し、拡散モデルの安全性評価において重要な洞察を提供しています。これにより、モデルの安全な運用において、合成推論やコンセプト演算が持つ影響を深く理解する必要性を強調しています。
検証方法
著者たちは、提案した攻撃手法の有効性を理論的な分析と実験的な検証を通じて示しています。理論的な部分では、拡散モデルの合成性と線形性に基づく数学的な枠組みを構築し、なぜ攻撃が成功するのかを説明しています。
具体的には、抑制されたコンセプトとデタープロンプトの組み合わせによって、元のガイダンスベクトルを再現できることを数式で示しています。

実験的な部分では、実際の拡散モデル(Stable Diffusion 1.4)に対して、既存の複数のコンセプト抑制手法(ESD、AC、UCEなど)を適用し、その上で提案した攻撃を実行しています。
具体的には、抑制されたコンセプトに関連するプロンプトを用いて画像を生成し、その結果を評価しています。評価方法としては、生成された画像が抑制されたコンセプトをどの程度含んでいるかを定量的に測定するために、CLIPスコア(補足: 画像と言語の類似度を評価する指標)やNudeNet(補足: ヌード画像を検出するモデル)などの既存の評価指標を使用しています。
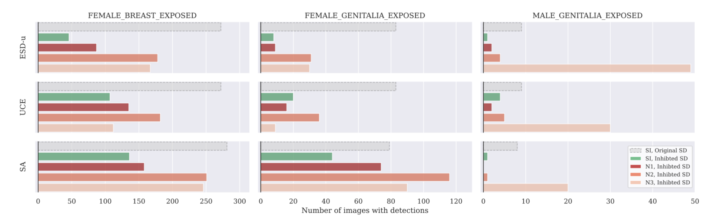
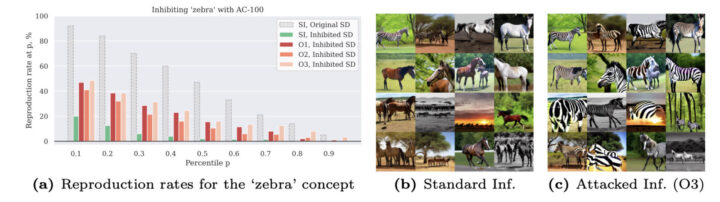
結果として、提案した攻撃手法を用いることで、抑制されたコンセプトの再現率が大幅に上昇することを示しました。場合によっては、攻撃後の生成結果が、抑制されていない元のモデルと同等かそれ以上に抑制されたコンセプトを含むことも確認されました。
これらの結果は、提案した攻撃手法が既存の抑制手法に対して有効であり、現実的な脅威となり得ることを示しています。また、異なる抑制手法や異なるコンセプトに対しても攻撃が有効であることを示し、攻撃手法の一般性を裏付けています。
Concept Arithmetics for Circumventing Concept Inhibition in Diffusion Modelsについてよくある質問まとめ
- 拡散モデルのどのような特性を利用して、抑制されたコンセプトを再現しているのですか?
この論文では、拡散モデルの合成特性と線形性を利用しています。
具体的には、複数のプロンプトのガイダンスを線形に組み合わせて画像を生成できる性質を活用し、抑制されたコンセプトと無関係なデタープロンプトを組み合わせ、その差分を取ることで抑制されたコンセプトのガイダンスベクトルを再現しています。
- 提案された攻撃手法に対して、どのような防御策が考えられますか?
提案された攻撃手法は、拡散モデルの合成特性と線形性に基づいているため、防御策としては、モデルのグローバルな変更を検討する必要があります。
具体的には、抑制したいコンセプトに関連する情報を局所的に削除するのではなく、モデル全体に対して影響を与えるような対策が必要です。
また、合成推論を考慮した抑制手法の開発や、モデルの出力を後処理するフィルタリング機構の強化なども有効な手段となり得ます。
継続的な課題・議論
この研究は、拡散モデルの安全な運用やコンセプト抑制手法の限界に関する重要な議論を提起しています。著者たちは、提案した攻撃手法が既存の抑制手法に対して有効であることを示すことで、これらの手法が完全ではないことを明らかにしています。このことは、拡散モデルの安全性を確保するためには、より包括的な対策が必要であることを示唆しています。
現在、研究コミュニティでは、拡散モデルにおける不適切なコンテンツの抑制や、モデルの悪用を防ぐための新たな手法の開発が進められています。しかし、モデルの合成性や線形性といった基本的な特性が、抑制手法の限界をもたらす可能性があるため、これらの特性を考慮した新たなアプローチが必要とされています。
また、本研究は、拡散モデルのセキュリティ評価において、攻撃者が利用し得るすべての手法を考慮する重要性を強調しています。これは、モデルの安全性を評価する際に、従来の想定に囚われず、より広範な視点から脅威を検討する必要があることを示しています。
さらに、提案した攻撃手法自体が悪用される可能性があるため、研究者や開発者は、この知見を活用してより強固な防御策を開発することが求められています。具体的には、モデルのグローバルな変更や、合成推論を考慮した抑制手法の開発などが検討されています。
今後も、拡散モデルの安全性と利便性のバランスを取るための研究が継続して進められることが期待されます。
AI Marketでは、

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

