
Stable DiffusionのLoRAとは?checkpointとの違いは?概要、使い方、作成方法を徹底解説!
最終更新日:2025年10月27日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

画像生成AIの人気サービスであるStable Diffusionで利用するLoRAとは、あるモデルに対して追加学習を行ったファイルを意味します。
LoRAを活用することで、生成する画像のクオリティを劇的に上げたり、好きな画風や特徴を絵に加えることができるようになります。例えば、布の質感や光の反射の表現が自然になったり、ある有名な画家のスタイルを模倣した画像を作ることができたりします。
今回はStable DiffusionのLoRAに関して、概要やセットで出てくるcheckpointとの違いや使い方、作成方法まで解説しています。ぜひ、今回の内容をもとにAI導入の検討をしていけるように、ぜひ参考にしていきましょう。
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
画像生成システムに強いAI開発会社を自力で選びたい方はこちらで特集していますので併せてご覧ください。
目次
Stable DiffusionのLoRAとは?

LoRAとは、LLM(大規模言語モデル)や画像生成AIモデルの追加学習データを指します。LoRAはLow Rank Adaptationの略称で、Stable Diffusionでcheckpointと呼ばれるモデルファイルに対して追加学習を行い、差分を記録したファイルになります。
画像生成において、元のモデルのパラメータを直接変更するファインチューニングは高スペックマシンと高度な技術を必要とします。代わりにLoRAを導入して、さまざまなパラメータの変更を行うことができます。少ない計算量で元のモデルに修正を加えられるので、比較的低スペック(と言ってもプロユースの)PCでもファインチューニングが可能になりました。
いわば、元のモデルファイルに対して微調整を行う機能で、描く絵のクオリティを劇的に上げたり、好きな画風や特徴を絵に加えることが可能です。LoRAを活用することで、オリジナリティあふれた高品質作品をスピーディに生み出すことができます。
AIがただランダムに画像を生成するのではなく、LoRAの設定に基づいて、目指す美しさやスタイルにぴったり合った作品を作り出すことができるということです。
checkpointやLoRAが共有されているHugging faceやCivitaiといったサイトからダウンロードして、Stable Diffusion上で利用できます。
LoRAを活用しやすいクラウド環境の選択肢
CivitaiやHugging FaceからダウンロードしたLoRAを使うには、Stable Diffusion Web UI(AUTOMATIC1111)の環境が必要になりますが、ローカルPCでの運用は、高性能なGPUやセットアップ作業を必要とするため、導入のハードルがやや高いのが実情です。
こうした背景から、Stable Diffusionをクラウド上で手軽に利用できるサービスも注目されています。クラウド環境で利用できるため、高性能なハイスペックPCを準備する必要がありません。
例えば「ConoHa AI Canvas」では、Stable Diffusion(AUTOMATIC1111やComfyUI)をブラウザだけで扱うことができ、CheckpointやLoRAの読み込みにも対応しています。
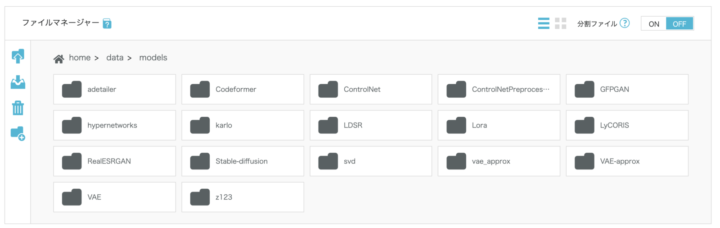
「LoRAを試してみたいけど、環境構築が不安」「動作が重くてうまくいかない」といった課題を感じている場合には、こうしたクラウドサービスの活用も一つの方法です。
CheckpointとLoRAはどう違う?
Stable Diffusionでは、モデルの本体と言えるcheckpointと、モデルに対して追加学習を行ったLoRAが存在します。checkpointは他の画像生成AIサービスでのモデルとほぼ同じ概念です。
Stable Diffusionでは他の画像生成AIと違い、テキストを入力して画像を生成するだけでなく、オリジナルのオープンソースモデルに追加学習を行って、自分の作成したい画像を生成できるモデル(checkpoint)を作成可能です。Hugging FaceやCivitaiのようなサイトでは、世界中のユーザーが作成したcheckpoint(モデル)をダウンロードできます。checkpointを使えば、一貫したトーンやタッチの画像を生成できます。
それに対してLoRAは、画像における背景や服装、キャラクターの髪などパーツのような位置付けとなり、微調整することを得意としています。1つのcheckpointに対して複数のLoRA を適用することもできます。
また、モデル全体を効率的に調整するLoRAに対して、画像の具体的な要素を制御するControlNetという拡張機能もあります。
LoRAの種類
LoRAには、以下のような種類が存在します
- キャラクターLoRA:生成したいキャラクターを指定するために利用
- スタイルLoRA:芸術的なスタイルを画像に適用でき、有名な画家の画風などを利用したいときに有効
例えば、「髪が宇宙」「スライムの少女」など、自身のイメージするテーマを幅広く反映できる - コンセプトLoRA:生成したい画像のコンセプトやアイデアを反映させたい時に利用
- ポーズLoRA:キャラクターに特定のポーズを適用したい時に利用
例えば、「指を指している」「お姫様ポーズ」などのポージングをした画像が生成可能 - 服装LoRA:キャラクターの服装を自身のイメージに合わせるために使用
服装や細かいアクセサリーまでさまざまな部分をコントロール可能 - オブジェクトLoRA:特定の物体やアイテムを生成したい時に利用
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
LoRAは何ができる?

LoRAのメリットは主に以下の3つがあります。これらのメリットを活用することで、企業は自社のプロダクトやサービスを効果的にプロモートし、ターゲット顧客に対して強い印象を残すことができます。ただし、LoRAを商用目的で利用する際には、著作権や利用規約に注意し、適切な使用を心がけることが重要です。
- 画風を調整できる
- キャラクターや人物を指定できる
- キャラクターを自分の好きな服装やポーズに調整できる
多様な画風の調整が可能
LoRAを使用すると、企業はプロモーション資料や製品紹介のための画像を、3D風、映画風、2Dアニメ風など、目的に応じた多様なスタイルで生成することが可能になります。これにより、ターゲットとする顧客層に合わせて最適なビジュアルコミュニケーションを行うことができます。
また、img2imgという機能でアップした画像を元に全く新しい画像を生成することもできます。
キャラクターや人物の指定が可能
LoRAを利用すれば、企業はブランドキャラクターやイメージキャラクターを指定し、一貫性のあるビジュアルイメージを多数生成することができます。これは、ブランディングやマーケティング活動において、キャラクターの一貫性を保ちながら様々なシーンを描出する際に非常に有効です。
キャラクターのカスタマイズが可能
さらに、LoRAではキャラクターを特定の服装やポーズにカスタマイズすることができます。これにより、特定のキャンペーンやイベントに合わせて、キャラクターを特別な衣装で登場させたり、特定のアクションをとらせたりすることが可能になります。
これは、企業のプロモーション活動をより魅力的で、ターゲットに訴求力のあるものにするための強力なツールとなり得ます。
LoRAはどこから入手できる?

LoRAの入手先はCivitaiとHugging Faceというサービスが代表的です。それぞれStable Diffusion上で使えるモデルやLoRAなどを共有しており、ユーザーは気軽にLoRAを入手することができます。ここではCivitaiとHugging Faceの概要やその特徴などを解説します。
Civitai
CivitaiはStable DiffusionのモデルやLoRAを共有しているプラットフォームです。アカウント作成が不要で、だれでも無料で利用開始することができます。
Civitaiではモデル(checkpoint)やLoRAだけでなく入力画像の圧縮と復元を行って新しい画像を生成するVAEなど、たくさんの種類のデータを共有しています。Civitaiでは生成画像のサムネイル表示がされているため、どのような画像を生成できるのか一目でイメージ可能です。
いろんなフィルタリングによって自分の生成したい画像を実現できるLoRAを見つけやすいサイト設計になっています。さまざまなデータをダウンロードできますが、複雑なコーディングは不要でシンプルな画面操作で完結するため、画像生成AIの分野では定番サービスです。
Hugging Face
Hugging FaceはStable Diffusionをはじめとして、LoRAを含むさまざまなAIモデルや学習に使うデータセットを共有しているプラットフォームです。Hugging Faceはチャットボットのような自然言語処理を得意としていますが、Stable Diffusionで利用できるモデルやLoRAも公開されています。
Hugging Faceではモデル名とLoRA名がまとめられているため、事前にどのモデルやLoRAの名称を調べておく必要があります。細かい部分まで調整したい方や、すべて自分で管理して画像生成したい方にとって、Hugging Faceは自由度が低いと感じる場合もあるので注意しましょう。
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
LoRAを使った画像は商用利用可能?

LoRAを使った画像は商用利用できる場合とできない場合があります。大前提として、Stable Diffusionで生成した画像は基本的に商用利用可能です。しかし、自分でインストールしたモデルの場合は、規定によって可能かどうかの判断が必要となります。
また、ダウンロード元のCivitaiやHugging Face上で公開する際の規約等もあるため、商用利用したい場合はまず利用するモデルの規約やライセンスを確認しましょう。
商用利用できないケースもある
商用利用できないモデルを利用した生成画像は商用利用できませんが、商用利用できないモデルをLoRAによって追加学習した場合も同様に商用利用できないので注意しましょう。
また、著作権をもつ特定のキャラクターや人物のLoRAを利用する場合も、申請が必要なケースやそもそも利用できないケースもあります。画像生成に関する著作権上の問題に関しては明確なガイドラインが確立されていませんが、十分に留意しましょう。
LoRAの具体的な活用シーン
従来、高品質なビジュアルコンテンツの制作は時間とコストがかかるプロセスでした。しかし、checkpoint、そしてLoRAの活用により、事前に定義されたブランドイメージやコンセプトをもとに、一貫性のあるビジュアルを低コスト・短時間で生み出すことが可能になります。
これにより、マーケティングチームはより多くのアイデアを試し、最適なビジュアル戦略を素早く見つけることができるでしょう。アニメやキャラクターに関する画像生成はもちろん、ビジュアルコンテンツの作成や教育現場におけるビジュアル化、個人制作の活動にも利用されています。
LoRAを自分で作成する方法
LoRAを作成する方法は、ローカルPCで生成する方法とStable Diffusion Web UIの拡張機能「sd-webui-train-tools」で作成する方法などがあります。
ローカルマシンで生成する場合、高いマシンスペックが必要です。大量のデータを処理し、複雑なAIモデルの学習を行うためです。また、プログラミングスキルを必要とし、AIモデルのトレーニングプロセスに関する深い理解が求められます。
時間とリソースの投資が大きく、高度な技術的知識を持つチームが不可欠ですが、企業が独自のLoRAを開発し、特定のビジネスニーズに合わせた高度なカスタマイズを目指す場合に適しています。
sd-webui-train-toolsを利用してLoRAを生成する手順は以下です。
- Stable Diffusion WebUIで拡張機能をインストールします。
- プロジェクトを作成
- 学習させたい画像を最低でも10枚ほど用意
- パラメータを調整
- AIに学習させればLoRAが生成
画面上のシンプルな操作で完結しますので、AIやプログラミングに関する専門知識がないユーザーでも、LoRAを生成し、ビジュアルコンテンツのカスタマイズを試みることが可能になります。初心者の方にはおすすめです。
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
Stable DiffusionのLoRAについてよくある質問まとめ
- Stable DiffusionのLoRAとは?
LoRAとは、LLM(大規模言語モデル)や画像生成AIモデルの追加学習データを指します。Stable Diffusionでcheckpointと呼ばれるモデルファイルに対して追加学習を行い、差分を記録したファイルになります。
画像生成において、元のモデルのパラメータを直接変更するファインチューニングは高スペックマシンと高度な技術を必要とします。代わりにLoRAを導入して、さまざまなパラメータの変更を行うことができます。少ない計算量で元のモデルに修正を加えられるので、比較的低スペック(と言ってもプロユースの)PCでもファインチューニングが可能になりました。
- CheckpointとLoRAはどう違う?
Stable Diffusionでは、モデルの本体と言えるcheckpointと、モデルに対して追加学習を行ったLoRAが存在します。checkpointは他の画像生成AIサービスでのモデルとほぼ同じ概念です。
Stable Diffusionでは他の画像生成AIと違い、テキストを入力して画像を生成するだけでなく、オリジナルのオープンソースモデルに追加学習を行って、自分の作成したい画像を生成できるモデル(checkpoint)を作成可能です。
それに対してLoRAは、画像における背景や服装、キャラクターの髪などパーツのような位置付けとなり、微調整することを得意としています。1つのcheckpointに対して複数のLoRA を適用することもできます。
まとめ
今回はLoRAとは何か、導入するメリットやcheckpointの違い、使い方などを解説してきました。LoRAとは、Stable Diffusion上でcheckpointに対して追加学習を行った差分を記録しているファイルです。checkpointは画像生成本体のアルゴリズムに対して、LoRAは追加学習を行った差分となるファイルという違いがあります。
LoRAによって生成画像のキャラクターやその服装などのパーツを細かく調整でき、自分の生成したい画像に近づけることができます。ぜひ、今回の内容を参考に、

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

