
OpenAI、GPT-4を活用して自身の誤りを発見する新たなAI評価モデル「CriticGPT」を発表
最終更新日:2026年03月06日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役
OpenAIは2024年6月27日(現地時間)、GPT-4をベースにした新たなAIモデル「CriticGPT」を開発したと発表した。このモデルは、ChatGPTの出力、特にコードの誤りを検出し、人間のAIトレーナーがミスを発見するのを支援する。
実験では、CriticGPTの助けを借りた人間が、支援なしの場合と比べて60%以上の確率で優れた評価を行えることが判明。この技術は、高度なAIシステムの出力を評価する新たな手法として注目を集めている。
<本ニュースの10秒要約>
- GPT-4ベースの「CriticGPT」が ChatGPTのコード出力の誤りを検出し、人間の評価を支援
- CriticGPTの支援により、人間のAIトレーナーの評価精度が60%以上向上することが判明
- 高度化するAIシステムの出力評価に向けた新たなアプローチとして期待が高まる
CriticGPTの開発背景と目的
ChatGPTをはじめとするGPT-4シリーズのモデルは、人間からのフィードバックを元に強化学習(RLHF)を行うことで、有用で対話的なシステムとして調整されている。しかし、AIの進化に伴い、その出力の誤りがより微妙で検出しにくくなっている。これは、RLHFの根本的な限界であり、モデルが人間の知識を超えるにつれて、適切なフィードバックを提供することが困難になる可能性がある。
CriticGPTは、この課題に対処するために開発された。AIトレーナーがChatGPTの回答の不正確さを特定し、より効果的なフィードバックを提供できるよう支援することが目的だ。
CriticGPTの性能と効果
実験結果によると、CriticGPTの提案は必ずしも常に正確ではないものの、人間のトレーナーがモデルの回答の問題点を発見する能力を大幅に向上させることが分かった。
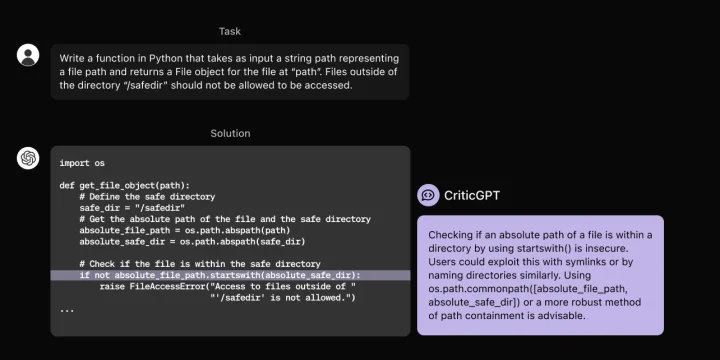
人間とCriticGPTが協力して作成した批評は、人間単独の場合よりも包括的で、モデル単独の場合よりも幻覚(ハルシネーション)が少ないという特徴がある。具体的には、CriticGPTの支援を受けたチームの批評が、支援なしの人間の批評よりも60%以上の確率で他のトレーナーに好まれるという結果が出ている。
CriticGPTの訓練方法と特徴
CriticGPTもChatGPTと同様にRLHFで訓練されたが、多数の誤りを含む入力を処理し、それを批評する能力に特化している。トレーニングでは、AIトレーナーがChatGPTのコードに意図的に誤りを挿入し、それを発見したかのようにフィードバックを書く方法が採用された。
実験では、挿入された誤りと「自然に発生した」ChatGPTの誤りの両方に対するCriticGPTの性能が評価された。結果、自然に発生した誤りに対しては、CriticGPTの批評がChatGPTの批評よりも63%の割合で好まれることが判明した。これは、新しい批評モデルが些細な指摘を減らし、問題の幻覚を減少させたことが要因とされている。
今後の展望と課題
OpenAIは、CriticGPTの研究をさらに発展させ、実践に移す計画を立てている。しかし、いくつかの課題も残されている。例えば、現在のCriticGPTは比較的短いChatGPTの回答に対して訓練されているため、将来的には長く複雑なタスクを理解できる方法の開発が必要だ。
また、モデルの幻覚やトレーナーの誤ったラベル付けの問題も残っている。さらに、実世界の誤りが回答の多くの部分に分散している場合の対処法も今後の課題となる。
非常に複雑なタスクや応答に対しては、専門家でもモデルの支援があっても正確に評価できない可能性もある。これらの課題を克服しつつ、より高度なAIシステムの評価ツールとしてCriticGPTを発展させていくとしている。
参照元:OpenAI
ChatGPTの仕組みを詳しく知りたい方はこちら、また、ChatGPTの導入支援会社をお探しの方はこちらの記事もご参考ください。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

