
AIでリバースエンジニアリングを効率化・自動化?仕組み・メリット・LLM活用事例・注意点を徹底解説!
最終更新日:2025年08月27日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- AIはブラックボックス化したレガシーシステムのリバースエンジニアリングが抱える「工数増大」「属人化」といった課題を解決
- LLMを活用することで、古い言語のソースコードを自然言語で解釈・要約したり、仕様書やフローチャートなどのドキュメントを自動生成
- AI導入を成功させるには、目的の明確化、適切なツール選定、AIの出力を専門家が検証するハイブリッドな体制の構築と、情報漏洩を防ぐ運用ルールの整備が不可欠
近年、ソフトウェアやハードウェアの解析・改良を目的とする「リバースエンジニアリング」の分野でも、AI(人工知能)のコード生成・解析能力活用が進んでいます。
特に注目されているのがLLM(大規模言語モデル)を活用したアプローチです。人手では膨大な時間と専門知識を要する作業が、AIの高度な自然言語処理能力によって効率化されつつあります。
この記事では、
コード生成・解析に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・リファクタリング、ソース解析、AI駆動開発等
完全無料・最短1日でご紹介 コード生成・解析に強い会社選定を依頼
LLM(大規模言語モデル)の活用に強いに強いAI開発会社をご自分で選びたい場合はこちらで特集していますので併せてご覧ください。
目次
なぜリバースエンジニアリングにAI活用が求められるのか?
従来のリバースエンジニアリングの手法や解析現場は、多くの課題を抱えています。
以下では、リバースエンジニアリングの従来課題を紹介します。これらの課題を解決する切り札として、AI、特にLLM(大規模言語モデル)の活用に大きな期待が寄せられているのです。
COBOLやPL/Iレガシー言語システムのブラックボックス化
COBOLやPL/Iのようなレガシー言語で構築されたシステムは何十年も前に設計・開発されたものであり、仕様や意図を把握する技術者の多くがすでに退職しています。そのため、システム全体の構造や処理内容が文書化されておらずブラックボックス状態に陥っています。
情報が不足したブラックボックス状態ではリバースエンジニアリングが困難なため、正確な解析や仕様の再現に多大な工数とコストを要しています。
解析に必要な専門知識の不足
レガシーシステムの多くは、独自の開発ルールや特殊な構文を用いて記述されています。これらを正確に読み解くには、過去の開発慣習や業務フローに精通した高度な知識が必要です。
しかし、レガシーシステムに関する専門知識を持つ人材は年々減少しており、属人化が進んでいます。
特にリバースエンジニアリングでは、仕様書やドキュメントが存在しない中でソースコードだけを手がかりにシステムの全体像を再構築しなければなりません。従来のリバースエンジニアリングは、専門のエンジニアが手作業でソースコードを一行ずつ読み解き、仕様を推測していく、まさに「職人技」に頼っていました。
リバースエンジニアリングの正確性や再現性を損なうだけでなく、システム移行や保守において判断ミスや仕様誤解を招き、重大な障害や業務停止リスクを高めます。
膨大なコード量・複雑な依存関係の可視化不足
長年にわたる改修や追加開発により、コード量は膨れ上がり、サブプログラムやモジュール間の依存関係は複雑化しています。このようなシステム状況にもかかわらず、全体構造が十分に可視化されていないことが多く、各処理がどこに影響を与えているのかを把握しにくくなっています。
依存関係が不明瞭な状態では、リバースエンジニアリングの際に全体構造の把握ができません。処理の影響範囲の誤認につながり、誤った仕様再現や改修ミスが生じます。
ドキュメント欠如による仕様把握の困難さ
レガシーシステムでは、設計書や仕様書、変更履歴といったドキュメントが紛失・未整備であるケースも多くあります。そのため、当時の開発意図や業務要件を確認する手段がなく、現場の担当者が口頭や暗黙知に頼って対応していることも珍しくありません。
特にリバースエンジニアリングでは、正確な仕様の再現が求められます。しかしドキュメントが存在しない場合、ソースコードの断片的な情報だけを頼りに全体像を再構築する必要があり、作業の難易度が上がります。
手作業による解析では、どうしても見落としや解釈の間違いといったヒューマンエラーが発生しやすくなります。
結果として、設計の意図を誤解釈や不要な機能を残す可能性が高まり、システム移行や再構築において重大な障害や品質低下を招きます。
解析工数とコストの増大
リバースエンジニアリングは、人手に依存する作業であり、解析には膨大な時間と労力が必要です。特にブラックボックス化されたシステムでは、コードの読解や依存関係の整理、仕様の再現といった作業が連続的に発生し、解析だけで数か月〜年単位の工期が必要になることもあります。
その分、人的リソースや外部委託費用などのコストもかさみ、プロジェクトの負荷が大きくなります。
ビジネスのスピードが求められる現代において、長期化・高コストの解析プロセスは、競争力の低下やシステム刷新の遅延といった重大なビジネスリスクにつながります。
コード生成・解析に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・リファクタリング、ソース解析、AI駆動開発等
完全無料・最短1日でご紹介 コード生成・解析に強い会社選定を依頼
リバースエンジニアリングにLLMを活用する仕組み

LLMをリバースエンジニアリングに活用することで、コードの解析や仕様の把握の効率化が可能です。以下では、リバースエンジニアリングにLLMをどのように活用できるか、その仕組みを紹介します。
コードの自然言語解釈
LLMは、COBOLやPL/Iなどの古いコードや、逆コンパイルされたバイナリコードを解析し、処理目的や機能を自然言語での要約が可能です。また、LLMは関数や変数の役割をコンテキストから推定し、命名の補助や処理内容の説明を日本語文で付け加えられます。
LLMによる要約は、過去に学習した膨大なプログラミングパターンや構文、自然言語の対応関係をもとにコードの文脈を読み取り、関数や変数の意味を推論することで実現されています。
関連記事:「COBOL解析のChatGPT活用方法とは?メリット・注意点・他ツールとの比較も徹底解説!」
モダナイゼーション支援
レガシーシステムを新しい言語やプラットフォームへ移行する「モダナイゼーション」においても、AIは強力な支援ツールとなります。古い言語で書かれたコードを、JavaやPythonといったモダンな言語のコードに自動変換します。
膨大なコードの構造解析
高いコード解析能力を持つLLMは、数十万行に及ぶ大規模なコードベースに対しても高速に解析可能です。関数間の依存関係やモジュールの呼び出し構造を体系的に整理・可視化することで全体像を把握しやすくし、従来手法では見落とされる複雑な構造も明らかにします。
構造解析は、LLMがコード中の関数・変数・制御フローなどのパターンを読み取り、自然言語処理と構造推論を組み合わせてコードの意味的なつながりを理解することで実現しています。
また、LLMは実行パスや依存関係を仮想的に追跡することで、関数や処理の影響範囲と構造的なつながりを把握可能です。
バグの特定と脆弱性診断
LLMは、膨大なソースコードの中から、潜在的なバグやセキュリティ上の脆弱性につながるパターンを高速で検出します。これにより、システムの品質向上とセキュリティ強化に貢献します。
疑似コードの自動生成
LLMはコード間の翻訳が可能で、逆アセンブリされた低レベルなバイナリコードやアセンブリコードからC言語やPythonの疑似コードの自動生成が可能です。
具体的には、LLMの文脈理解能機能で対象コードの命令処理の意図や変数の用途を解釈し、高級言語の構文パターンに置き換える仕組みです。単なる構文変換ではなく、人が読んで理解しやすいように整理し、意味の通った擬似コードを生成します。
解析レポートやドキュメント作成の自動化
LLMは、解析結果をもとに、以下のようなドキュメントを自動で生成することが可能です。
- 仕様書・設計書:ソースコードからシステムの全体像や機能一覧、処理の流れをまとめたドキュメントを生成
- フローチャートやシーケンス図:プログラムの制御フローやオブジェクト間のやり取りを視覚的に分かりやすく図式化
- コメントの自動付与:コードの各部分がどのような処理を行っているのかを自然言語で記述したコメントを追記
内部的には、コードを文として解釈し、要約や説明文を生成する自然言語処理の技術を応用しています。
例えば、関数単位の処理概要やシステム全体の構成、依存関係の説明、修正履歴の整理など、従来エンジニアが手作業で行っていた文書作成業務を効率化できます。成果物の品質が均一化され、チーム間の情報共有もスムーズに行えるようになります。
リバースエンジニアリングにLLMを活用するメリット

LLMを活用することで、従来のリバースエンジニアリングの課題を解消し、作業効率や品質を向上できます。ここでは、主なメリットを具体的に紹介します。
ソースコードの可読性が向上
LLMは、複雑でコメントのないコードや、逆コンパイルされた低レベルなコードを自然言語で要約し、それぞれの処理内容や関数の目的をわかりやすく説明できます。変数や関数名の意図を推定しながら文脈に応じた解釈を行うため、開発者がコードを読み解く手間の削減が可能です。
初見のコードでも短時間で構造や意図を把握でき、結果的に解析の正確性とスピードが向上します。
作業スピードの大幅な向上
従来、経験豊富な技術者が数日かけていたコード解析や仕様把握も、LLMにより数分〜数時間で完了するケースがあります。例えば、関数の説明文や処理フローの生成、疑似コードの作成などをLLMが自動で行うことで作業の大部分を効率化できます。
結果的に、リバースエンジニアリングにかかる工数が大幅に削減され、プロジェクト全体のスケジュール短縮や人的リソースの最適化に貢献します。
属人化を低減
LLMは、過去に学習した膨大なコード事例をもとに、コードの構造や処理内容を推定できます。そのため、レガシー言語や特殊な業務ロジックに不慣れなエンジニアがLLMを活用することで一定レベルの解析や理解が可能になります。
また、専門知識のギャップを埋めることができ、属人化の回避にもつながります。
属人化を防ぐことにより、チーム全体での共同作業がしやすくなるほか、担当者の変更に伴う技術継承リスクも軽減されます。
ドキュメント資産の標準化・再活用が進む
LLMは、社内テンプレートやフォーマットに沿って、生成するコードの説明文や仕様情報の整形が可能です。そのため、属人性の高いメモや非構造なドキュメントではなく、統一された形式の技術文書として蓄積・共有できます。
また、LLMは過去の説明やコードを応用できるため、ナレッジの再利用が進み、類似プロジェクトへの素早い展開が可能となります。
モダナイゼーションに活用可能
LLMは、現行のプログラムソースをリバースエンジニアリングし、処理内容やシステム構造を可視化することで、レガシーシステムのモダナイゼーションを支援します。例えば、COBOLやPL/Iの古いコードを自然言語で整理して変換することで、現代的な言語や開発環境へのマイグレーション(移行)が容易になります。
また、LLMは既存コードの改善ポイントや非効率な処理パターンを自動的に指摘することも可能であり、単なる移行にとどまらず、システム全体の最適化にも貢献します。ブラックボックス化した旧システムを段階的かつ効率的に刷新できるため、リスクを抑えたモダナイゼーションが実現します。
コード生成・解析に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・リファクタリング、ソース解析、AI駆動開発等
完全無料・最短1日でご紹介 コード生成・解析に強い会社選定を依頼
リバースエンジニアリング×LLMの活用事例
近年、リバースエンジニアリングにLLMを活用する企業も増えつつあります。本章では、リバースエンジニアリングにLLMを活用した事例について紹介します。
【東芝デジタルエンジニアリング】生成AIとITエンジニアのハイブリッドな検証で高精度な解析
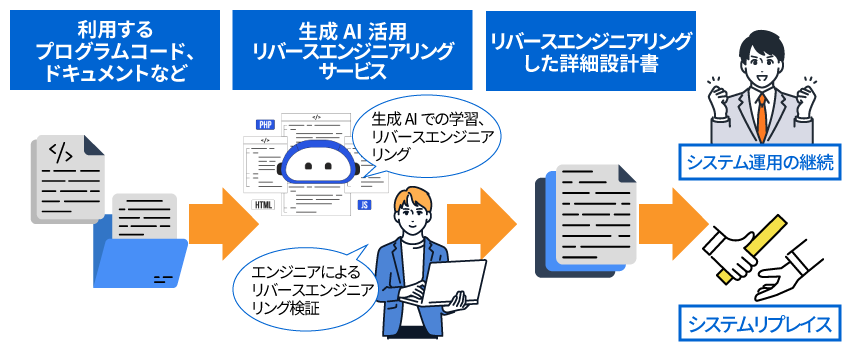
東芝デジタルエンジニアリングでは、「生成AI活用 リバースエンジニアリングサービス」を提供しています。このサービスは、既存のソースコードや運用マニュアルをAIに取り込んでプログラム構造を解析し、熟練エンジニアが解析結果を検証して設計書を整備するものです。
また、生成AIの解析結果をもとに、システムの安定稼働を支援する各種ドキュメントの作成やプログラムの最適化、システム試験のテストケース生成などの提案も可能です。
実際の運用ケースでは、PL/SQLやVBAの大規模レガシーコードに対してプログラムコードの最適化を実施し、わずか3カ月でシステムの延命に成功した事例もあります。
生成AIと熟練のITエンジニアにより精度とスピードを両立し、設計書の再整備からコード最適化、システム刷新の要望まで包括的なサポートを提供します。
【Jitera】ソースコードから設計書を自動生成
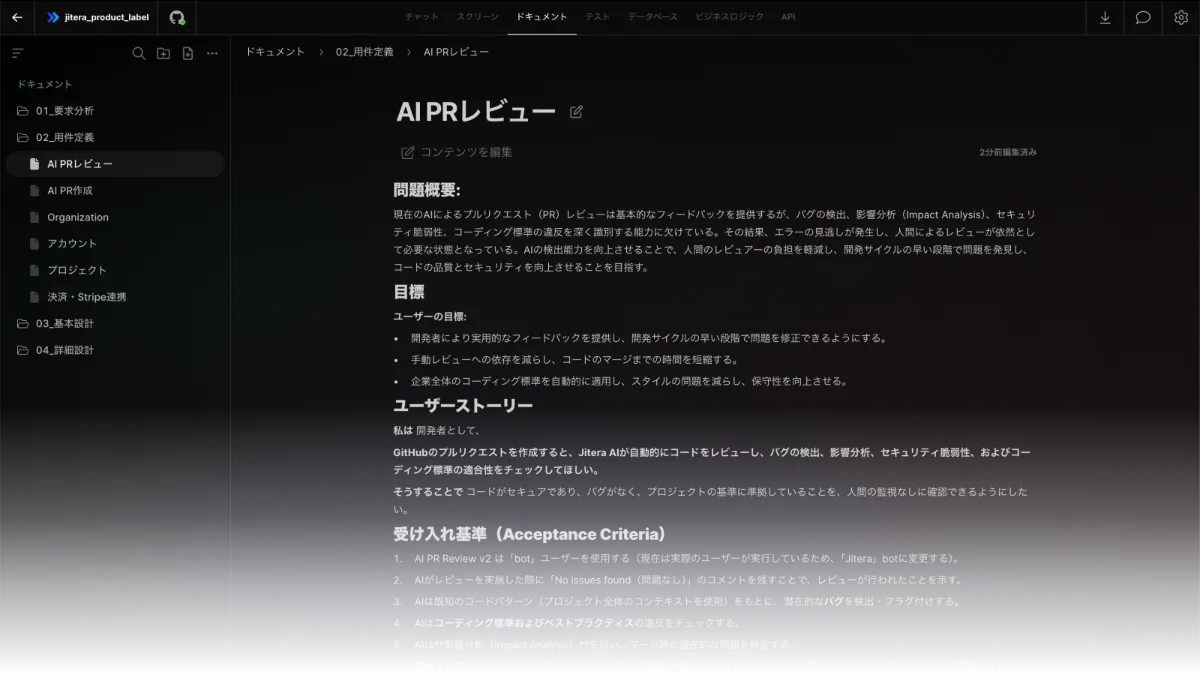
Jiteraは、AIがシステム設計書の生成からソースコードの生成まで、システム開発全般を支援するAIエージェントです。Webの情報やソースコード、Github上に存在する既存プロジェクトのデータを読み込み、設計書を自動で生成します。
リバースエンジニアリングでは、既存プロジェクトを理解したうえで改善する能力を活かし、複雑化・煩雑化した長期運用システムに対しても高精度な設計書を生成可能です。
また、生成した設計書や参照情報をもとに、機能追加や修正もスムーズに行え、フルスクラッチ並みの高速な開発スピードを実現します。
【SHIFT】エンジニアの知見に左右されないコード解析を支援
SHIFTは、生成AIを活用したリバースエンジニアリングツールを搭載するマイグレーション支援サービス「AIドキュメントリバースサービス」を提供しています。
このサービスでは、日本語の自然な文章でフローチャートやシーケンス図、クラス図などの技術ドキュメントを自動生成します。
エンジニアの経験に依存せず、複雑なプログラムを明確に可視化できるため、マイグレーションやモダナイゼーションを迅速かつ高度に実現可能です。
SHIFTはこのサービスを通じて、金融・流通・自治体など長年マイグレーション・モダナイゼーションに課題を抱える業界に対する支援を進めています。
リバースエンジニアリングにAIを導入する手順

AIをリバースエンジニアリングに導入するプロセスは、単にツールを導入するだけでは完了しません。以下では、リバースエンジニアリングにAIを導入する基本的な手順とポイントを紹介します。
現状分析と対象の選定
最初のステップは、AIを適用する対象を正確に理解することです。まず、解析対象となるシステムやソフトウェアがどのようなもので、どの程度の規模なのかを詳細に確認します。
この際、以下を把握することが重要です。
- 既存のドキュメント(設計書、仕様書など)がどの程度残っているか
- システムの構造が複雑化しているなどの「技術的負債」がどの程度存在するのか
さらに、リバースエンジニアリングは著作権やライセンス契約に抵触する可能性があるため、法務部門と連携し、法的なリスクがないかを事前に精査しておく必要があります。
AI活用の目的と適用範囲の明確化
次に、AIを導入して「何を達成したいのか」という目的を具体的に定めます。例えば、以下のような目的を明確にすることで後のツール選定や評価が容易になります。
- 「ソースコード全体をAIで自動的に要約させたい」
- 「難解な部分を誰にでも理解できる疑似コードに変換したい」
また、全てのプロセスをAIで完全自動化するのか、あるいは専門家によるレビューを挟むなど手作業と組み合わせたハイブリッドで運用するのか、適用範囲を判断することも重要なポイントです。
必要なAIツール・モデルの選定と準備
目的が明確になったら、それを実現するためのAIツールやモデルを選定します。ソースコードの解析や生成には、Meta社の「Code Llama」や「GitHub Copilot」といった、コーディング能力に特化したサービスが有力な選択肢となります。
機密性の高いソースコードを扱う場合は、情報漏洩を防ぐために、クラウドサービスではなく自社内に閉じたローカル環境を構築するなどのセキュリティ対策が必須です。AIにデータを投入する前には、解析精度を高めるために不要な情報を取り除いたり形式を整えたりする「前処理」や「正規化」といった準備も行います。
AI解析の実行と出力結果の検証
準備が整ったら、いよいよAIによる解析を実行します。ソースコードやバイナリファイルなどをAIに入力し、要約やコード変換、ドキュメント生成などの処理を行わせます。
ここで重要なのは、AIの出力を鵜呑みにしないことです。生成された結果が正確か、必要な情報が網羅されているかを専門のエンジニアがレビューし、検証します。
もしAIの出力に誤りや解釈のミスがあった場合は、それをフィードバックしてAIを再学習させることで、徐々に精度を高めていくことができます。
結果の活用とドキュメント化
AIによる解析結果は、具体的な成果物として活用してこそ価値が生まれます。生成された仕様書や技術文書は、自動的にドキュメント管理システムに反映させ、関係者がいつでも参照できるようにします。
これらのドキュメントは、レガシーシステムを最新環境へ移行・改修するプロジェクトにおいて、極めて重要な情報となります。また、得られた知見を社内の知識資産として体系的に管理することで、将来的なシステムの保守性向上にも繋がります。
導入後の継続的改善と活用拡大
AIの導入は一度きりで終わりではありません。導入によってどのような成果が得られたのかを定期的に振り返り、改善点を抽出して、さらなる効率化を目指します。
あるプロジェクトで成功すれば、そのノウハウを他部門や他のプロジェクトにも展開できる可能性があります。
市場には常に新しいAIモデルや技術が登場します。そのため、継続的に最新情報を収集し、自社のAIモデルを更新・最適化していくことで企業の競争力を維持・強化していくことができます。
コード生成・解析に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・リファクタリング、ソース解析、AI駆動開発等
完全無料・最短1日でご紹介 コード生成・解析に強い会社選定を依頼
リバースエンジニアリングにAIを活用する際の注意点

リバースエンジニアリングにおいてAIを実運用する際は、いくつか重大なリスクと配慮点があります。以下では、実務で見落とされがちな代表的な注意点とその対策を紹介します。
機密情報の取り扱い
AIツールがクラウド型で提供されている場合、入力したソースコードや設計情報が外部のサーバーに送信されることで、情報漏えいのリスクが生じます。また、活用するLLMによっては、入力情報が学習データに使用され、競合他社の出力結果に反映される可能性があります。
情報漏えいのリスクを避けるためには、ローカル環境で動作するオンプレミス型のAIツールを活用することが有効です。また、AIツールのプライバシーポリシーや利用規約を事前に精査し、情報の取り扱い範囲や学習可否について確認することも大切です。
人間とのハイブリッドな体制の構築
解析結果に対する「説明責任」や「判断の根拠」を必要とするリバースエンジニアリングにおいては、AI単独での運用には限界があります。
AI単独の運用が難しいのは、ハルシネーション(AIが事実に基づかない内容を出力する現象)の発生が大きな理由です。ハルシネーションにより誤った仕様や処理内容が生成されると、設計ミスや再現性の低下、移行先システムの不具合といった深刻な影響を及ぼします。
そのため、AIが出力した内容は必ず技術者がレビューし、妥当性を確認する体制を整えることが重要です。AIの生成内容はあくまで参考情報として扱いつつ、最終的な判断は人間が行う運用ルールを確立することで、品質と信頼性の担保につながります。
社内運用ルールの整備
AIツールを明確なルールなしに導入すると、判断基準が部署ごとに異なり、セキュリティや成果物の品質にばらつきが生じます。また、不適切な使い方で運用すると、誤出力やシステムトラブルを促進します。
そのためAIを活用する際はAIの利用に関する社内ポリシーやガイドラインをあらかじめ策定し、従業員全体への周知が欠かせません。
特に導入初期は小規模なパイロットから始め、成果とリスクを評価して段階的に本格導入へ進めるとAI活用のリスクを抑えられます。
リバースエンジニアリングとAIについてよくある質問まとめ
- なぜリバースエンジニアリングにAIの活用が求められているのですか?
従来のリバースエンジニアリングが抱える、以下のような課題を解決するためです。
- COBOLなどのレガシー言語で書かれたシステムがブラックボックス化している
- 解析に必要な専門知識を持つ人材が不足し、属人化が進んでいる
- コード量が膨大で、複雑な依存関係の可視化が困難
- ドキュメントが欠如しており、手作業での仕様把握が難しい
- 結果として、解析に膨大な工数とコストがかかっている
- リバースエンジニアリングにLLM(大規模言語モデル)はどのような仕組みで活用されるのですか?
LLMは主に以下の仕組みでリバースエンジニアリングを支援します。
- コードの自然言語解釈:古いコードの処理内容や目的を日本語などで要約します。
- モダナイゼーション支援:古い言語のコードをJavaやPythonなど現代的な言語へ自動変換します。
- 膨大なコードの構造解析:大規模なコードの依存関係や構造を体系的に整理・可視化します。
- バグ・脆弱性の特定:潜在的なバグやセキュリティ上の問題点を高速で検出します。
- 疑似コードの自動生成:低レベルなコードから、人間が理解しやすい高級言語の疑似コードを生成します。
- ドキュメント作成の自動化:仕様書やフローチャートなどを自動で作成します。
- リバースエンジニアリングにAIを導入する手順を教えてください。
一般的に以下の6つのステップで進めます。
- 現状分析と対象の選定:システムの規模や技術的負債、法的リスクを把握します。
- 目的と適用範囲の明確化:何を自動化したいのか、どこまでAIに任せるかを決定します。
- AIツール・モデルの選定と準備:目的に合ったツールを選び、セキュリティ対策やデータの前処理を行います。
- AI解析の実行と出力結果の検証:AIの出力を専門家がレビューし、正確性を確認します。
- 結果の活用とドキュメント化:生成物を仕様書などに反映し、知識資産として管理します。
- 継続的改善と活用拡大:成果を評価し、他プロジェクトへの展開を検討します。
- リバースエンジニアリングにAIを活用する際に注意すべき点は何ですか?
以下の3つの点に特に注意が必要です。
- 機密情報の取り扱い:情報漏洩を防ぐため、オンプレミス型ツールの利用や利用規約の確認が重要です。
- 人間とのハイブリッドな体制:AIの誤出力(ハルシネーション)のリスクに備え、必ず技術者が結果をレビューする体制を構築します。
- 社内運用ルールの整備:利用に関するガイドラインを策定し、全社で統一した品質とセキュリティ基準を保ちます。
まとめ
近年AIの進化に伴い、リバースエンジニアリングは専門家のみ扱える高度な技術ではなく、専門知識がなくても扱える汎用的な解析手法へと広がりを見せています。特に
しかし、AIの出力が常に正しいとは限らず、その精度は対象システムの複雑さや利用するモデルに依存します。また、機密性の高いソースコードを扱う上でのセキュリティ対策も欠かせません。
AIの能力を最大限に引き出し、安全かつ効果的にプロジェクトを成功に導くためには、ツールの選定から運用体制の構築、生成された結果の専門的な検証まで幅広い知見が必要です。自社だけで判断が難しい場合や、より具体的な導入計画を検討される際にはAIとシステム開発の両方に精通した専門家へ相談することをおすすめします。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

