
【AI論文解説】DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning:LLMの推論力を強化学習で引き出し、小型モデルへ蒸留する
最終更新日:2025年09月08日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

近年、LLM(大規模言語モデル)は数学、プログラミング、論理推論といった高度なタスクにも対応できるほど精度が向上し、汎用的なAIシステムとして急速に進化しています。
しかし、その一方で、「どのようにしてモデルに人間のような推論過程を学習させるか」や「長い思考をモデルが自発的に活用できるようにするにはどうすればよいか」といった課題は依然として解決されていません。
そこで本研究では、事前の教師あり学習に依存せずに強化学習のみで推論力を高めるアプローチ、さらに少数の高品質データと複数ステージの学習を組み合わせるアプローチを提示し、モデルが自発的に深い思考過程を発揮できる可能性を探っています。
本稿で報告される「DeepSeek-R1」シリーズは、高い推論性能を獲得すると同時に、汎用性や可読性の面でも優れた性能を示しており、今後のLLM研究に新たな方向性を提案するものとなっています。
- 論文名:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- 論文著者:DeepSeek-AI
- 論文提出日:2025年1月22日
- 論文URL:https://arxiv.org/abs/2501.12948
目次
本論文の概要
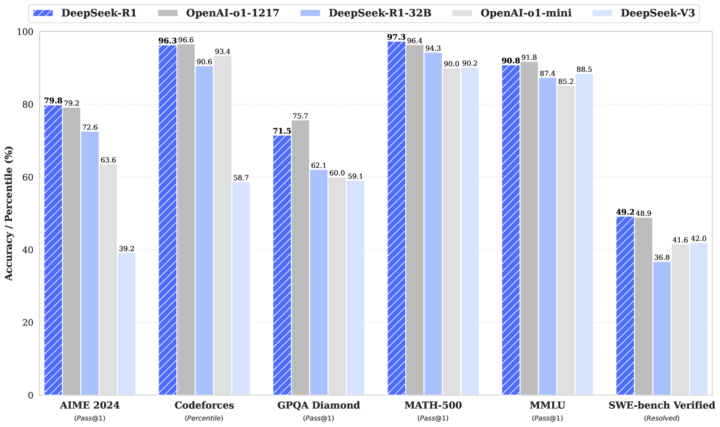
本論文では、LLMの推論能力を大幅に向上するために、強化学習を活用する手法が提案されています。特に、次の2つのモデルが中心的に扱われています。
- DeepSeek-R1-Zero:事前の教師あり微調整(SFT)なしで、ベースモデルに直接強化学習を適用して得られたモデル。純粋な強化学習のみで高い推論性能を達成しています。
- DeepSeek-R1:わずかな数の高品質データ(コールドスタートデータ)を使った初期SFTやマルチステージの強化学習を取り入れることで、さらに可読性や一般的なタスク適応力を向上させたモデル。
これらのモデルは、数学やプログラミング、科学的推論など、明確な正解があるタスクを中心に性能を高める設計になっています。さらに最終的には、DeepSeek-R1の推論能力を小~中規模のモデル(Qwen, Llamaシリーズ)へ蒸留し、パラメータ数の少ないモデルにおいても大きな性能向上が得られたことが報告されています。
論文全体を通して、「大規模LLMの推論力は強化学習によって引き出せるのか」という重要なテーマに対して肯定的な結果が示されており、今後のLLM研究に大きなインパクトを与える内容となっています。
ポイント
- 教師ありデータなしで強化学習を行う「DeepSeek-R1-Zero」が高い推論力を自発的に獲得
- 少数の高品質データで初期微調整を行い、大規模強化学習を組み合わせる手法「DeepSeek-R1」を提案
- DeepSeek-R1の推論能力を抽出し、1.5B~70BパラメータのQwen・Llamaなどへ蒸留することで、小規模モデルでも大きく推論力が向上することを検証
DeepSeek-R1-Zero: 事前SFTなしの大規模強化学習
アプローチの概要
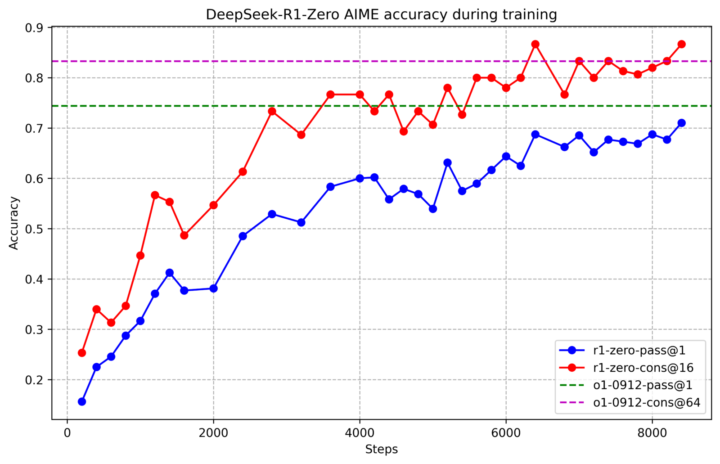
DeepSeek-R1-Zeroは、事前の教師ありデータ(SFT)を一切使わず、ベースモデルに直接大規模強化学習を適用するという特徴的な手法で開発されました。これにより、モデルが自発的に自分の「思考プロセス」を長く生成するようになり、複雑な数学問題やプログラミング問題で大幅に精度が上昇することが確認されています。
強化学習アルゴリズム
著者らは、GRPO (Group Relative Policy Optimization) というアルゴリズムを採用しています。これは、従来のPPOのような大容量のcriticモデルを用いず、同じバッチ内の報酬を正規化して勾配を更新する手法です。これにより、大規模モデルに強化学習を適用しても計算コストを抑えつつ安定した学習が可能になっています。
報酬設計
強化学習で重要となる報酬設計として、次の2種類が挙げられています。
- 正解報酬: 数学ならば正しい数値の答えを導けたか、コードなら実行テストを通過できるかなど、「答えが合っているか」をルールベースで自動判定し、その合否を報酬とする。
- フォーマット報酬: 推論過程を thinkタグ、最終回答をanswerタグで囲むという形式に従うかどうかをチェックし、従っていれば報酬を与える。
DeepSeek-R1-Zeroの性能と「自己進化」
DeepSeek-R1-Zeroは何千ステップもの大規模強化学習を行うと、高い推論性能に達するだけでなく、モデルが自ら非常に長い思考チェーンを出力するようになる現象が観察されました。特筆すべき点として、「反省」や「再度検証」などの人間的な思考過程を擬似的に模倣する挙動がRLの途中で自然発生したことです。
一方で、DeepSeek-R1-Zeroは回答文が読みにくい、複数言語が混在するなどの欠点も見られました。著者らはこれを踏まえ、次のステップとして、少量のコールドスタートデータを導入するDeepSeek-R1へと進みます。
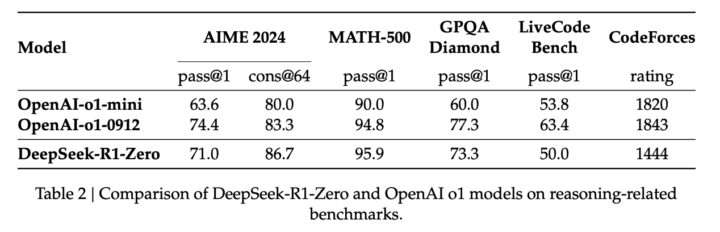
DeepSeek-R1: コールドスタートを活用したマルチステージ強化学習
DeepSeek-R1は、小規模の高品質な「コールドスタート」データを用いてモデルを微調整(SFT)したうえで、大規模強化学習を行うことでさらに性能と可読性を向上させています。学習全体は、以下の4ステージに分けて行われます。
- コールドスタート
数千件規模の長いChain-of-Thought付きデータを作成・収集し、ベースモデルを微調整する。これにより、学習初期からある程度可読性の高い回答が得られる。 - 推論重視の大規模強化学習
コールドスタートで微調整したモデルに対し、数学・プログラミング・論理クイズなど正解が明確なタスクで大規模な強化学習を施す。最初のDeepSeek-R1-Zeroと同様に、正解かどうかを自動チェックする報酬を用いつつ、言語混在を抑えるための追加報酬などを組み込み、モデルの推論力と可読性を高める。 - リジェクションサンプリング + 新SFT
推論重視強化学習で得られた中間モデルに、改めて幅広いタスク(推論以外の質問や文章生成など)を投入し、正解や良質な回答のみを「リジェクションサンプリング」で抽出。さらに、DeepSeek-V3の一部データも加え、合計80万件ほどの大規模データを作成してSFTを行う。これにより、モデルは数学・プログラミング以外の領域(文章生成やQAなど)も再度学習する。 - 全領域強化学習
最後にあらゆるシナリオを含むプロンプトを対象として、数学やプログラミングだけでなく一般的なタスクに対する人間の好み(ヘルプフル・ハームレス等)を反映させる強化学習を行い、最終チェックポイントを完成させる。これがDeepSeek-R1である。
実験結果
DeepSeek-R1の総合性能
DeepSeek-R1は、数学やプログラミングのベンチマークで非常に高いスコアを示します。また、教育的な知識問題や一般QAタスクにも対応でき、書き出しや文章要約、長いコンテキストの解析などにおいても前世代モデルより優位に立っています。
特に数学系(AIMEやMATH-500)でOpenAI-o1-1217と同程度の性能を発揮し、コード生成(特にアルゴリズム領域)では上位数%に入る力を示しました。
一方、ソフトウェアエンジニアリングのように実装・保守・設計など幅広い観点が必要となるタスクでは、まだ更なる改良の余地があることが述べられています。
蒸留による小型モデルの強化
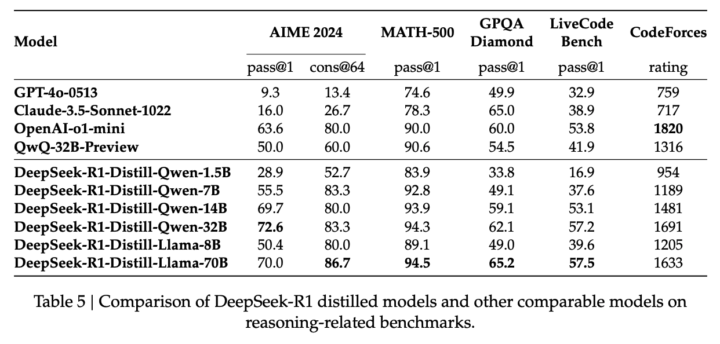
DeepSeek-R1が生成した大規模なSFT用データを用いて、Qwen (1.5B, 7B, 14B, 32B) や Llama (8B, 70B) などのモデルを微調整することで、小規模~中規模モデルでも数学・プログラミングの成績を大きく向上させることに成功しています。
例えば、14B規模のモデルであっても、AIMEやコードベンチマークでQwen-32Bより高いスコアを示す例があり、「大規模強化学習で獲得した推論パターン」を蒸留する効果の高さが示されています。
考察と今後の課題
論文後半では、次のような考察が提示されています。
- 小型モデルでは強化学習より蒸留が効果的
小型モデルに同様の大規模強化学習を直接適用する場合、それほど性能が伸びないことがわかったのに対し、DeepSeek-R1の出力を蒸留する方式は大きな成果をあげています。 - 推論以外の機能強化
推論能力を高めるだけでなく、関数コールやマルチターン対話、構造化出力などについては現状DeepSeek-V3などに劣る場合があります。今後は、推論力向上と汎用タスクの両立を図る必要があると指摘しています。 - 言語混在への対策
DeepSeek-R1は英語と中国語に特化しているため、それらが混在しやすい課題が残っています。他言語への拡張や混在を抑える工夫が将来的な検討課題です。 - ソフトウェア開発支援の深掘り
コード生成の強化学習では評価コストが大きく、学習サイクルを回しにくい課題があるとされます。効率的な評価手法が導入されれば、ソフトウェアエンジニアリング的な応用でも飛躍が期待できると論じられています。
DeepSeek-R1についてよくある質問まとめ
- DeepSeek-R1は既存のLLMと何が違うの?
事前の教師あり微調整なしに強化学習のみでスタートしたモデル(DeepSeek-R1-Zero)を基盤に、少量の高品質データでコールドスタートを行い、その後大規模な強化学習を実施する点が最大の特徴です。これにより推論能力と可読性の両立を図っています。
- 小規模モデルでもDeepSeek-R1の推論能力を再現できる?
はい。DeepSeek-R1で獲得した推論プロセスを蒸留することで、1.5B〜14Bクラスのモデルでも大幅に推論精度が向上します。大規模な強化学習を直接小規模モデルに適用するより、蒸留のほうが効果的であることが示されています。
まとめ
本論文では以下の成果が強調されています。
- DeepSeek-R1-Zero: 事前SFT不要の純粋な強化学習で、推論能力が飛躍的に向上。数学やプログラミングなど明確な正解のあるタスクに強い。
- DeepSeek-R1: 少量のコールドスタートデータ + マルチステージ強化学習により、推論力だけでなく回答の可読性や一般タスク対応力も高めたモデル。性能はOpenAI-o1-1217と肩を並べる水準に到達。
- 蒸留の有効性: DeepSeek-R1を教師モデルとして生成したデータを小型モデルに蒸留すると、小型モデルでも大きな推論力向上が得られる。大規模モデルを直接強化学習するよりも計算コストを抑えつつ効果を発揮。
今後は、多言語化やソフトウェアエンジニアリングタスクへの応用拡大などが展望として挙げられており、論文末ではこれらの新しいバージョンの開発計画が示唆されています。
研究コミュニティ向けには、DeepSeek-R1や蒸留モデルがオープンソースとして公開されており、多くの分野での活用が期待されています。
AI Marketでは、

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

