
【AI論文解説】LLaVA-CoT: Let Vision Language Models Reason Step-by-Step:VLMに段階的な推論力を与えるLLaVA-CoT
最終更新日:2024年11月30日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

近年、LLM(大規模言語モデル)は推論能力で大きな進歩を遂げていますが、画像とテキストを扱うVLM(Vision Language Model)は複雑な視覚的質問応答での推論に課題があります。
本論文では、LLaVA-CoTという新しいVLMを提案し、独立した多段階の推論を可能にし、精度を向上させました。
- 論文名:LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
- 論文著者:Guowei Xu, Peng Jin, Hao Li, Yibing Song, Lichao Sun, Li Yuan|School of Electronic and Computer Engineering, Peking University, Institute for Interdisciplinary Information Sciences, Tsinghua University, Rabbitpre AI & PKU Shenzhen AIGC Joint Lab, Peng Cheng Laboratory, DAMO Academy, Alibaba Group, Hupan Lab, Computer Science and Engineering, Lehigh University
- 論文提出日:2024年11月15日
- 論文URL:https://arxiv.org/abs/2411.10440
論文の要約
近年、AIは文章の理解や推論がとても得意になっていますが、画像を理解して質問に答えるAIは、複雑な問題に対する推論がまだ苦手です。
この論文では、画像と言葉を組み合わせて、段階的に考える新しいVLMモデル「LLaVA-CoT」を提案しています。
このモデルは、まず問題を整理し、次に画像の内容を説明し、その後論理的に考え、最終的な答えを出すというステップを踏みます。その結果として、より正確に複雑な質問に答えることができ、他の大きなモデルよりも良い成績を収めました。

ポイント
- LLaVA-CoTは、要約、キャプション、推論、結論の四つの段階で自律的な多段階推論を行うVLM
- 多様な視覚的質問応答データを統合したLLaVA-CoT-100kデータセットを構築し、構造化された推論アノテーションを提供
- 推論時間におけるステージレベルのビームサーチを提案し、推論能力をさらに向上
論文研究内容詳細
本論文は、VLMが複雑な視覚的質問応答において推論能力が不足しているという課題に取り組んでいます。
特に、既存のVLMは体系的かつ構造化された推論を行うのが難しく、複雑なタスクで誤りや幻覚的な出力を生成しがちです。これに対し、著者らはLlama-3.2(11B)をベースモデルとしたLLaVA-CoTという新しいVLMを提案しました。
このモデルは、要約、キャプション、推論、結論の四つの段階で自律的に推論を行い、各段階で明確な目的を持ち、問題を整理し、画像の関連部分を解釈し、論理的な推論を行い、最終的な結論を導き出します。

これにより、複雑な視覚的質問応答タスクにおいて精度が大幅に向上しました。
先行研究との比較
先行研究では、VLMは直接的な予測アプローチを採用し、質問に対して即座に簡潔な答えを生成することが一般的でした。
しかし、この方法では構造化された推論プロセスが欠如しており、論理的な推論を必要とするタスクには効果的ではありませんでした。また、従来のChain-of-Thought(CoT)推論を取り入れたモデルでも、推論の過程で誤りや幻覚を生じることが多く、複雑なタスクには不十分でした。
これに対し、LLaVA-CoTは自律的かつ段階的な推論を行うことで、これらの問題を解決しています。
特に、モデルが各推論段階を明確に識別し、それぞれの段階で取り組むべき主要なタスクを理解することで、推論の正確性と信頼性が向上しています。
本論文のキモ
LLaVA-CoTの技術的な核心は、自律的な多段階推論とステージレベルのビームサーチにあります。
まず、モデルは要約、キャプション、推論、結論という四つの段階で推論を行います。各段階は専用のタグでマークされており(例(下記図):<SUMMARY>…</SUMMARY>)、これによりモデルは推論プロセス全体を通じて明確さを維持することができます。
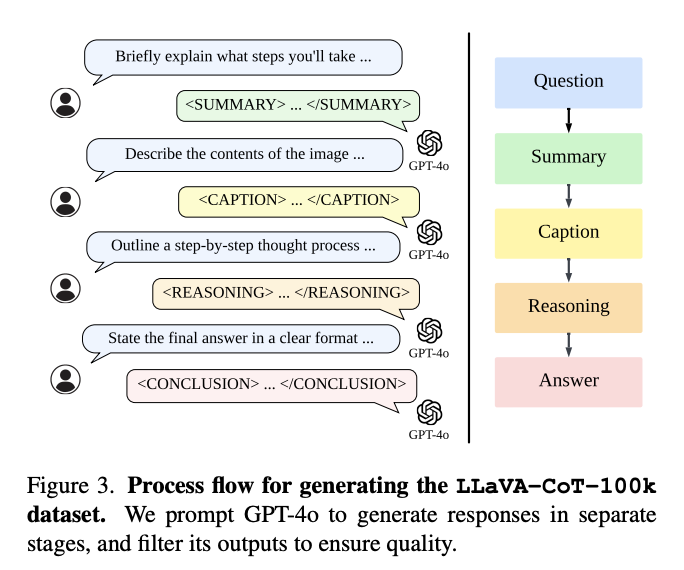
この構造化されたアプローチにより、モデルは問題を整理し、関連する画像情報を解釈し、論理的な推論を行い、最終的な結論を導き出すことが可能になります。
また、推論時間においては、ステージレベルのビームサーチを導入しています。これは、各推論段階で複数の候補結果を生成し、最良のものを選択して次の段階に進む方法です。
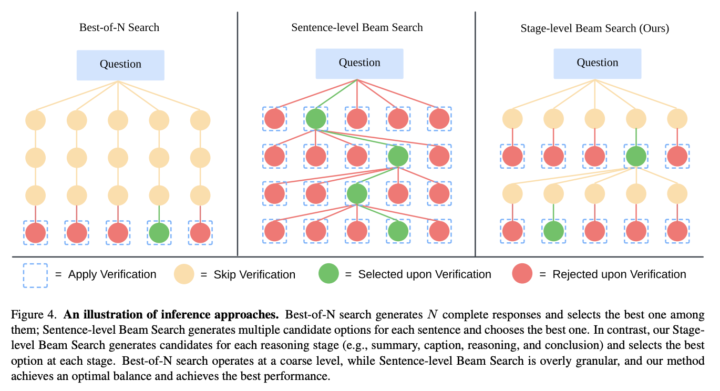
これにより、推論の精度と信頼性がさらに向上し、複雑なタスクにおいても安定した結果を得ることができます。
さらに、LLaVA-CoT-100kデータセットの構築により、モデルがこのような段階的な推論を学習できる環境を提供しています。
検証方法・結果
著者らは、MMStar、MMBench、MMVet、MathVista、AI2D、HallusionBenchといった複数のマルチモーダル推論ベンチマークで実験を行いました。
その結果、LLaVA-CoTは基礎となるLlama-3.2モデルよりも平均で6.9%の性能向上を達成しました。特に、論理的な推論や数学的な推論が必要なタスクで顕著な改善が見られました。
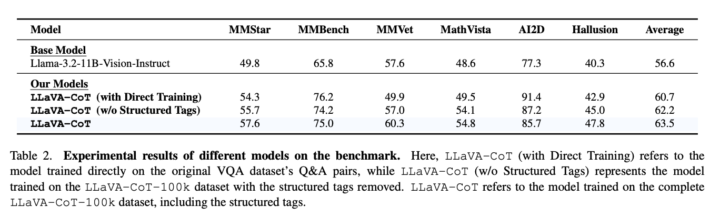
また、モデルサイズが小さい(11B)にもかかわらず、多くの大規模なオープンソースモデル(例えば、InternVL2-Llama3-76B、Llama-3.2-90B-Vision-Instructなど)やクローズドソースモデル(GPT-4o-mini、Gemini-1.5-Proなど)を上回る性能を示しています。
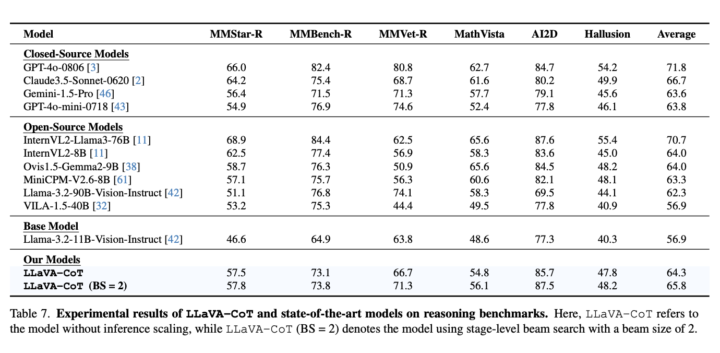
LLaVA-CoTについてよくある質問まとめ
- LLaVA-CoTは従来のVLMと比べて何が違いますか?
LLaVA-CoTは、従来のモデルが苦手とする複雑な推論タスクに対処するために設計された新しいVLMです。
従来のモデルは直接的に答えを生成する傾向があり、推論過程が明確でないため、論理的な推論が必要なタスクで誤りを生じやすくなっています。
LLaVA-CoTは、要約、キャプション、推論、結論の四つの段階で自律的に推論を行い、各段階で明確な目的を持つことで、推論の正確性と信頼性を向上させています。
- ステージレベルのビームサーチとは何ですか?
ステージレベルのビームサーチは、LLaVA-CoTが推論時間において採用する手法で、各推論段階で複数の候補結果を生成し、その中から最適なものを選択して次の段階に進む方法です。
これにより、推論の精度と安定性が向上し、複雑なタスクにおいてもより良い結果を得ることができます。
従来のビームサーチよりも効果的で、計算コストと性能のバランスが良い方法です。
継続的な課題・議論
LLaVA-CoTは、VLMにおける推論能力向上のための新しい方向性を示していますが、まだいくつかの課題や議論が残っています。
例えば、推論の各段階での最適な設計や、ステージレベルのビームサーチの計算コストと性能向上のバランスなどが挙げられます。
他にも、外部の検証器を用いた推論の強化や、強化学習を活用したさらなる推論能力の向上など、今後の発展可能性が議論されています。倫理的な観点からは、大規模なデータセットの使用に伴う偏りや、公平性、プライバシーの問題についても考慮が必要です。
これらの議論は、LLaVA-CoTをさらに改良し、実世界のアプリケーションに適用するための重要なステップとなります。
AI Marketでは、

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

