
【AI論文解説】HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems:HTMLそのものを活用し、LLMの知識強化を革新する新手法『HtmlRAG』の提案
最終更新日:2024年11月08日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

近年、LLM(大規模言語モデル)の性能向上とともに、外部知識を活用するRAG(検索拡張生成:Retrieval-Augmented Generation)システムが注目されています。
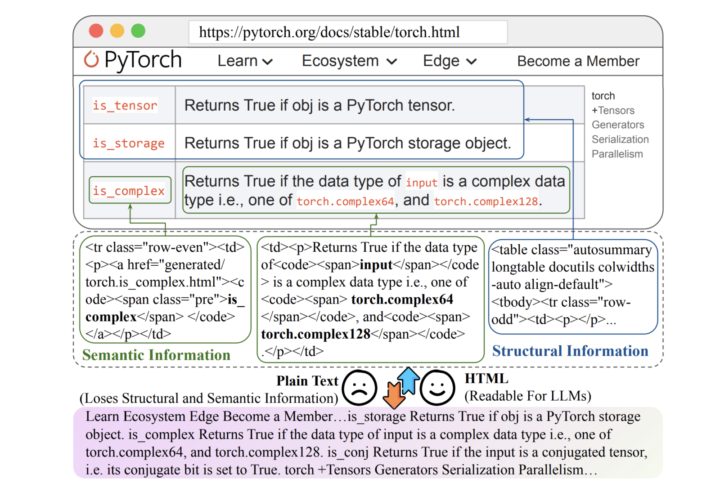
しかし、従来のRAGシステムでは、ウェブから取得したHTML文書をプレーンテキストに変換する際に、HTML固有の構造的・意味的情報が失われていました。
本論文では、この問題を解決するために、HTMLそのものを知識形式として利用する「HtmlRAG」を提案し、情報損失を最小限に抑えつつLLMの性能を向上させる手法を示しています。
- 論文名:HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems
- 論文著者:Jiejun Tan, Zhicheng Dou, Wen Wang, Mang Wang, Weipeng Chen, Ji-Rong Wen
- 論文提出日:2024年11月5日
- 論文URL:https://arxiv.org/abs/2411.02959
目次
論文の要約
この論文では、LLMが外部から知識を取り込む際に、ウェブから取得した情報をプレーンテキストに変換することで重要な情報が失われる問題を指摘しています。
具体的には、HTMLの見出しや表などの構造情報がプレーンテキスト化で失われ、LLMの回答精度に影響を与えていました。そこで、HTMLそのものをLLMの入力として利用することで、構造情報を保持し、より正確な回答を生成できるようにしています。
また、HTMLには不要なタグやスクリプトが多く含まれるため、それらを効果的に除去・圧縮する手法も提案しています。
ポイント
- HTMLをそのまま活用:HTMLをプレーンテキストに変換せず、そのままLLMの入力として利用
- 不要な情報を除去:CSSやJavaScriptなどのノイズを削減し、効率的な情報抽出を実現
- ブロックツリープルーニングの活用:HTMLの構造を活かし、関連性の高い情報を効率的に抽出
論文研究内容詳細
本研究は、LLMが外部知識を取り込む際の情報損失を最小限に抑えるため、ウェブから取得したHTML文書をそのままLLMの入力として利用する手法「HtmlRAG」を提案しています。
従来のRAGシステムでは、ウェブから取得したHTML文書をプレーンテキストに変換していましたが、その際に見出し、表、リスト、リンクなどの重要な構造的・意味的情報が失われていました。これにより、LLMが本来持つ知識獲得能力を十分に活用できず、回答の正確性や信頼性が低下する問題がありました。
HtmlRAGでは、HTMLの構造情報を保持することで、LLMがより豊富な文脈情報を活用できるようにしています。しかし、HTMLにはCSSやJavaScript、コメントなどの不要な情報も多く含まれており、そのままではLLMのコンテキストウィンドウを超えてしまう問題があります。
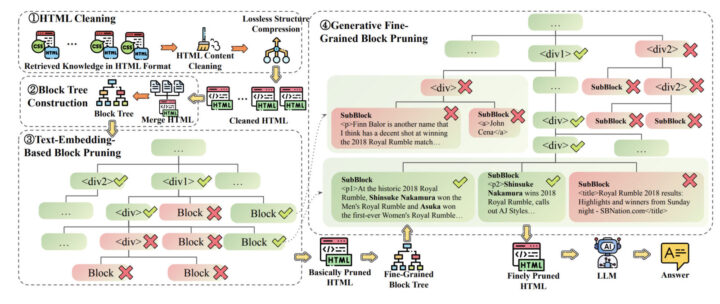
そこで、著者らはHTMLのクリーニングと圧縮、さらにブロックツリープルーニングという二段階のアルゴリズムを開発し、情報損失を最小限に抑えつつ、効率的に重要な情報を抽出しています。
具体的には、まずHTMLから不要なCSS、JavaScript、コメントを除去し、冗長なタグを統合・削減します。その後、HTMLのドキュメントオブジェクトモデル(DOM)を基にブロックツリーを構築し、ユーザーのクエリとの関連性に基づいて不要なブロックを剪定します。
このプロセスにより、LLMのコンテキストウィンドウに収まる形で、重要な構造情報を保持したHTMLを生成し、より正確な回答生成を可能にしています。
先行研究との比較
従来のRAGシステムでは、ウェブから取得した情報をプレーンテキストに変換してLLMに入力していましたが、その際に重要な構造情報が失われるという問題がありました。また、プレーンテキスト化によって情報の文脈や階層構造が崩れ、LLMが正確な回答を生成する妨げとなっていました。
これを解決するための手法として、テキスト要約や抽出などのアプローチも試みられていましたが、HTMLの持つリッチな構造情報を完全には活用できていませんでした。
本研究の革新性は、HTMLそのものを知識形式としてLLMに入力するという斬新なアプローチにあります。これにより、見出し、段落、リスト、表、リンクなどの構造情報を保持し、LLMがより深い理解を持って回答を生成できます。
また、HTML特有のノイズを効果的に除去するアルゴリズムを開発し、LLMのコンテキストウィンドウの制限を超えないように工夫しています。

さらに、ブロックツリープルーニングという手法を用いて、HTMLのDOM構造を活用しつつ、ユーザーのクエリに関連する部分のみを効率的に抽出しています。この二段階のプルーニングアルゴリズムは、情報の取捨選択を精密に行うことができ、従来の手法よりも高い精度で回答を生成することを可能にしています。
本提案技術・手法のキモ
本手法の核心は、HTML文書を効率的に処理するための「HTMLクリーニング」と「ブロックツリープルーニング」にあります。
まず、HTMLクリーニングでは、HTML文書から不要な要素を除去します。具体的には、以下のステップを踏みます。
- 不要なコンテンツの削除:CSSスタイル、JavaScriptコード、コメントなど、LLMの理解や回答生成に不要な部分を削除します。これにより、LLMのコンテキストウィンドウを大幅に削減できます。
- 構造の簡素化:冗長なタグのネストを解消し、空のタグを削除します。例えば、連続する単一の子要素を持つタグを統合することで、ツリーの深さを浅くします。
次に、ブロックツリープルーニングでは、HTMLのDOMツリーをブロック単位で整理し、ユーザーのクエリに対する関連性に基づいて不要なブロックを剪定します。これには二段階のアルゴリズムがあります:
- テキスト埋め込みに基づくブロックプルーニング:各ブロックのテキストを埋め込みモデルでベクトル化し、ユーザーのクエリとの類似度を計算します。類似度が低いブロックを順次削除し、LLMのコンテキストウィンドウに収まるように調整します。
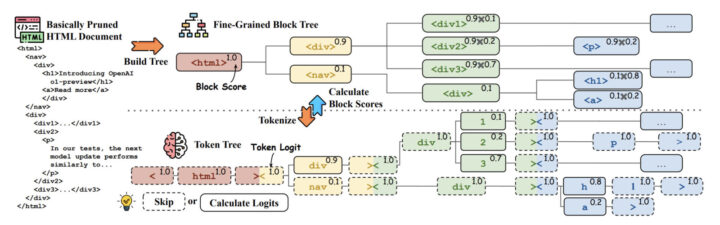
- 生成モデルを用いた微細なブロックプルーニング:さらに詳細なブロック単位で、生成モデルを用いてブロックの重要度を評価します。生成モデルは、ブロックのパス(HTMLタグの階層)を生成し、その確率を計算します。この確率に基づいて、より精密に不要なブロックを削除します。
これらの手法により、LLMが必要とする重要な情報を保持しつつ、コンテキストウィンドウを最適化しています。
検証方法
著者らは、6つのQAデータセット(ASQA、Hotpot-QA、NQ、Trivia-QA、MuSiQue、ELI5)を用いて実験を行い、提案手法の有効性を検証しました。これらのデータセットは、曖昧な質問、自然な質問、複数の段階を経る質問、長文の回答が必要な質問など、多様な種類の質問を含んでいます。
実験では、提案手法と従来のプレーンテキストベースの手法を比較し、LLMが生成する回答の正確性や完全性を評価しました。評価指標として、正解率(Exact Match)、ヒット率(Hit@1)、ROUGEスコア、BLEUスコアなどを用いています。
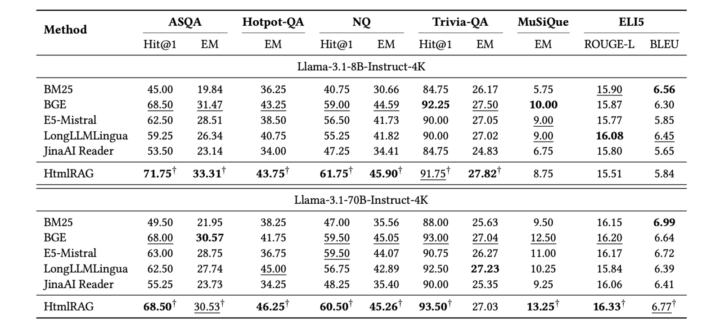
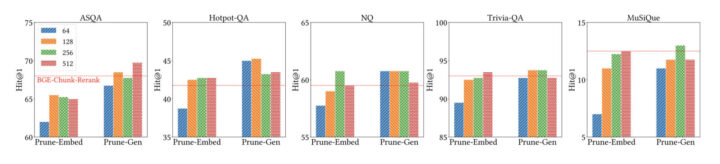
結果として、上記図のように、提案手法であるHtmlRAGは、従来の手法よりも一貫して高い性能を示しました。
特に、HTMLの構造情報を保持することで、LLMがより正確な回答を生成できることが確認されました。また、ブロックツリープルーニングによる効率的な情報抽出が、LLMのコンテキストウィンドウの制限を超えない範囲で効果的に機能していることも示されました。
さらに、アブレーションスタディ(各要素の効果を個別に検証する実験)を通じて、HTMLクリーニングやブロックツリープルーニングの各段階が性能向上に寄与していることを明らかにしています。
HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systemsについてよくある質問まとめ
- HtmlRAGとはなんですか?
HtmlRAG(HTML Retrieval-Augmented Generation)とは、ウェブから取得したHTML文書をプレーンテキストに変換せずにそのままLLMに入力して活用する手法です。
これにより、HTMLが持つ見出しや表、リストなどの構造的・意味的情報を保持し、LLMがより正確で文脈に沿った回答を生成できます。
- なぜHTMLをそのままLLMに入力することで、より良い結果が得られるのですか?
HTMLにはプレーンテキストにはない構造的・意味的情報が含まれています。例えば、見出しタグは文章の階層構造や重要度を示し、リストや表は情報のグループ化や関連性を示します。
LLMはこれらの構造情報を活用することで、より正確で文脈に沿った回答を生成できます。
継続的な課題・議論
本研究は、LLMがHTMLをどの程度理解できるかに依存しており、LLM自体の性能向上や学習データの拡充が今後の課題として挙げられます。また、HTML以外のドキュメント形式(PDFやWordなど)をどのように同様の手法で処理できるか、他のデータ形式への適用可能性も議論の余地があります。
さらに、LLMのコンテキストウィンドウの制限を超える長大な文書の処理や、より高度なノイズ除去手法の開発、ユーザーのクエリに対する関連性の高い情報を自動的に強調する手法など、継続的な研究が期待されます。
AI Marketでは、

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

