
【AI論文解説】SynthCLIP: Are We Ready for a Fully Synthetic CLIP Training?
最終更新日:2025年01月27日
記事監修者:石川 裕地

こんにちは、現役機械学習エンジニアの石川です。
本記事では、
LLM + 画像生成モデル(text-to-image model)を用いて、人工的にテキストと画像のペアを生成し、それを使ってCLIPを学習する手法を提案する論文です。
CLIPは画像生成やゼロショット画像分類など、非常に汎用的に応用されるマルチモーダルモデルです。
一方、CLIP の学習には膨大な画像とテキストのペアが必要になり、そのデータの収集には多大なコストがかかります。さらに、ライセンスやプライバシー、不適切コンテンツのフィルタリングなどの面倒な問題もあるため、データの管理も容易ではありません。
そこで「データを収集するのではなく、生成してしまう」という視点で取り組んでいる本論文が非常に興味深いと感じたため、こちらの論文を紹介いたします。
本論文では合成データのみで CLIP を学習するアプローチ(SynthCLIP)を提案しています。これにより、安全かつ多様なデータを比較的低コストで用意できる可能性があると考えられます。
arXiv:https://arxiv.org/abs/2402.01832
本研究の背景
CLIP[1]は、さまざまな場面で応用される画像とテキストのマルチモーダルモデルです。
OpenAIが提供しているCLIPを用いることで、簡単にゼロショット画像分類などを行うことが可能ですが、使用できるテキストは英語に限られます。
そのため、日本語でCLIPを使用したい場合などには、独自で大規模なデータを用意し、モデルを再学習する必要があります。このようなCLIPの学習には、大量の画像とテキストのペアが必要になりますが、そのデータの収集コストは非常に大きいです。
また、データライセンス・プライバシー・不適切コンテンツの混入リスクなど、さまざまな課題が伴います。
これらの課題に対して、本研究ではLLM(大規模言語モデル)とテキストから画像を生成するモデル (text-to-image model) を使い、「合成データ (テキスト+画像ペア)」のみで CLIP を学習する SynthCLIP という枠組みを提案しています。
合成データを活用することで、ウェブから直接データを収集するよりも、コストを抑えながら安全なデータを収集することが可能になります。
提案手法の詳細
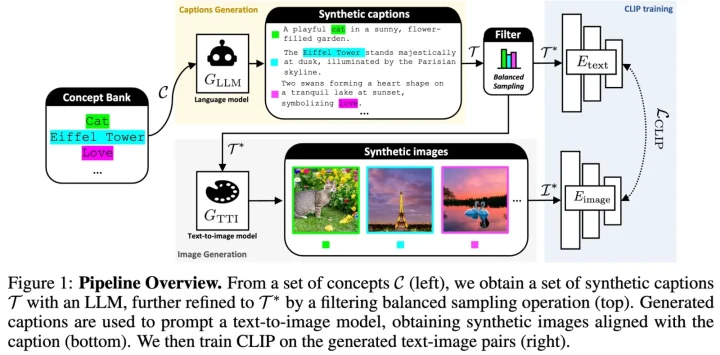
提案手法では、画像生成モデル(text-to-image model; TTI)と、大規模言語モデル(Large Language Model; LLM)を用いて、画像とテキストのペアを生成します。その後、生成されたデータを用いてCLIPの学習を行います。
これ以降では、データの生成部分に焦点を当てて、どのようにデータを生成するかを説明します。
本手法では、以下のステップを通して合成データを生成し、最終的に CLIP を学習します(図参照)。
- Concept Bankの構築
物体や固有名詞、漠然とした項目などのテキストを構築収集します。 - Synthetic Captionsの生成
- LLMを用いて、concept bankからキャプションを生成します。(concept bankは、MetaCLIP[2]で使用されているものを使用)。
- キャプション生成時には、特定のコンセプトにフォーカスさせる工夫であるconcept conditioningが重要であるとのこと。これにより、特定のガイアスにバイアスされるのを防ぎます。
- 以下のプロンプトを使用して、LLMがキャプションを生成します。

- Caption Filtering
- 特定のコンセプトcを含むキャプションを作ると、同時に他のコンセプトc’が含まれる場合があります。
(例: c=bird に対して “a bird is resting on a tree” が生成されると、実質的には別のコンセプトc’ = tree も含まれる)。
あるコンセプトcについてキャプションを生成すると、それに付随するコンセプトc’も同時に含まれてしまう - これが学習時にバイアスを生む恐れがあるため、MetaCLIP で提案されている balancing samplingを使い、頻度の多いコンセプトを減らすように調整します。
- MetaCLIPで使用されているbalancing samplingは以下を含みます。
- Substring Matching
キャプション中の各概念の出現頻度を計算 - Probability Balancing
ロングテールな概念の出現確率をあげることで、頻出する概念が過剰に表現されるのを防ぎつつ、ロングテールな概念も表現できるようにする
- Substring Matching
- 特定のコンセプトcを含むキャプションを作ると、同時に他のコンセプトc’が含まれる場合があります。
- Stable Diffusionで画像生成
上記で得られたフィルタ済みキャプションから、Stable Diffusionなどのtext-to-image modelである画像生成モデルを用いて画像を生成します。 - CLIPの学習
生成されたキャプションと画像のペアを用いて、通常のCLIPと同様に、contrastive learning (対照学習)によって学習を行います。
実験結果
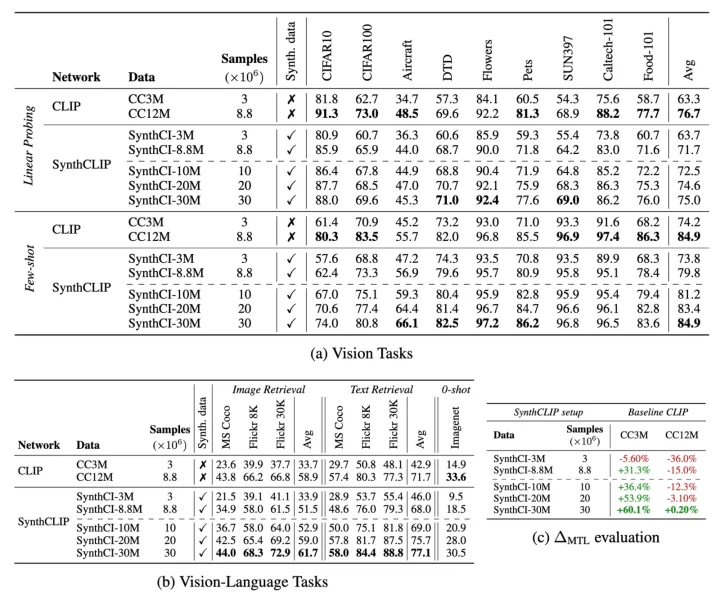
上記の表は、zero-shotの画像分類や画像検索での結果を示したものです。
- データスケールが揃っている状況では、実データを用いたCLIPの方が依然として優位です
- 人工データはデータ数を無限に増やせるので、それを増やしていくとSynthCLIPが強いです
- delta_MTLは、マルチタスクでの性能結果を集約して、Baselineと比べて優勢化を示したものです。
- M_{b,i}は、ベースラインモデルのi番目のタスクの性能
- M_{m,i}は、評価したいモデルのi番目のタスクの性能
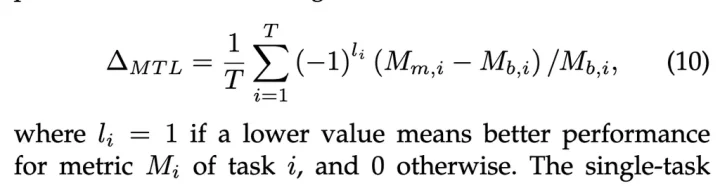
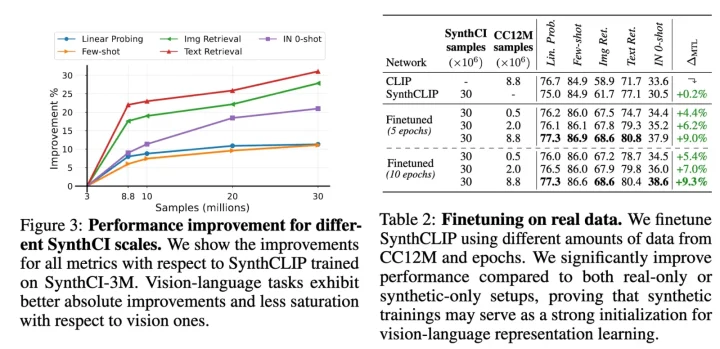
データを増やすと性能が上がることも確認されています。また、実データで転移学習するともっと性能上がります。
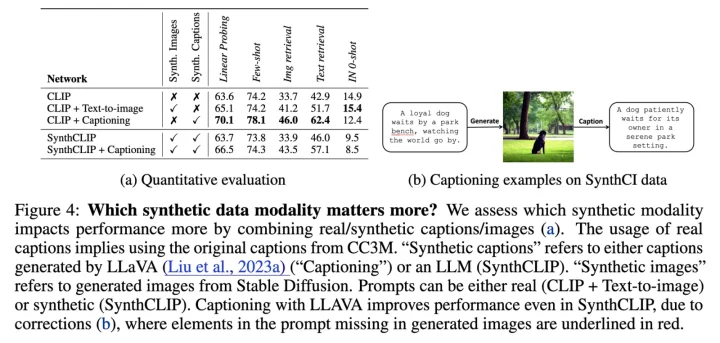
また実験では、合成画像よりも合成テキストの質が性能向上に寄与する傾向があると報告しています。
text-to-image modelがプロンプト中の要素を完全に再現できない場合もあるため、生成された画像を再度キャプションする “recaptioning” によって精度が上がるケースも確認されています。
提案されている SynthCLIP は、ロングテールな概念の影響を軽減しつつ、データ安全性を高められる点も特徴です。
現状では不適切コンテンツ検知の性能は十分に高くはなく、インターネット上のデータから収集しただけでは不適切コンテンツを完全には排除できない場合がありますが、合成データなら安全性をコントロールできる可能性があります。
今後の課題や応用について
本研究により、人工的に生成されたデータだけを用いて、CLIPの学習が可能になりました。性能面でも、十分な規模までデータ数を増やすことで、実データを用いたCLIPを上回る結果となりました。
一方で、同等の性能に達するには、CLIPよりもSynthCLIPの方が学習に必要なデータの数が多く、学習の効率性という観点では、実データに劣るのが現状です。
今後は、効率的な学習のためのデータの生成方法などの研究が進んでいくと考えられます。
引用
[2] Hu Xu, et al., “Demystifying CLIP Data” in arXiv preprint arXiv:2309.16671.
AI Marketでは、

慶應義塾大学大学院でAI研究を行いつつ、SoftBank社でAI研究開発に従事した後、現在は日本最大級のSNS企業にて、機械学習エンジニアをしています。画像・動画認識中心に研究開発を行い、国際学会での論文投稿実績も多数。本アカウントでは、AI関連の最新論文などの解説を行っています!
Xアカウントもぜひフォローお願いします!

