
VLMとは?画像認識と自然言語処理を統合処理する仕組み・メリット・デメリット・活用分野を徹底紹介!
最終更新日:2025年10月06日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

VLM(Vision Language Model)は、画像認識AIやLLM(大規模言語モデル)が組み合わさった技術として、ビジネスにおいて幅広い応用が期待されています。例えば、自動運転車における物体検出や、Eサイトのレコメンドシステムなど、さまざまなシーンでの活用が検討されています。
本記事では、
また、LLMとは何か?基本的な仕組みとその重要性についてはこちらで詳しく解説していますので併せてご覧ください。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
LLM導入・カスタマイズに強いAI開発会社を自力で選びたい方はこちらで特集していますので併せてご覧ください。
目次
VLMとは?

VLMとは、画像などの視覚情報と日本語の文章などのテキスト情報を統合的に処理するマルチモーダルなAIモデルです。
マルチモーダルとは、画像・テキスト・動画など複数の異なる形式のデータ(モダリティ)を同時に扱い、統合的に処理するAI技術のことです。その中でもVLMは以下を組み合わせ、視覚情報と言語情報を同時に処理することができます。
- 画像認識・画像生成技術:画像内の情報を識別して理解する技術、及び生成する技術
- 自然言語処理技術:言語情報を識別して理解する技術、及び生成する技術(いわゆるLLM)
このような技術を有するVLMは、デジタル広告、医療画像解析、eコマース、自動運転など、様々な分野で応用されています。
VLMとLLMとの違い
VLMは視覚情報と言語どちらも処理できるのに対し、LLMはテキストデータに特化している点が大きな違いと言えます。
LLM、VLM、VLAの最も大きな違いは、扱う情報の種類と最終的な出力形式にあります。それぞれのモデルは得意な領域が異なり、目的に応じて使い分けられます。
| LLM、VLM、VLA | 特徴 | 出力形式 |
|---|---|---|
| LLM(大規模言語モデル) | テキストデータに特化 文章の生成や要約、翻訳といったタスクが得意 | テキスト情報 |
| VLM(Vision-Language Model) | LLMの能力を拡張し、テキストに加えて画像情報も扱える 画像の内容を説明したり、画像に関する質問に答えたりできます | テキスト情報 |
| VLA(Vision-Language-Actionモデル) | VLMの「認識」能力をさらに一歩進め、物理的な「行動」に結びつけます | 現実世界で具体的なアクションを直接生成 |
また、これらのモデルを包括する概念としてMLLM(マルチモーダル大規模言語モデル)があります。MLLMは、テキストや画像だけでなく、音声や動画など複数の情報(モダリティ)を統合的に処理できるため、より複雑なタスクに対応可能です。
企業がどのモデルを採用するかは、テキスト分析だけで十分なのか、画像認識が必要か、あるいは物理的な作業の自動化まで目指すのかといった目的によって選択することが重要です。
加えて、SLM(小規模言語モデル)は、軽量で特定タスクに最適化されたモデルとして、効率性と実用性を重視する用途に適している点が特徴です。エッジLLMも、現場で迅速な応答が求められるシーンにおいて、その特性が活かされると期待されています。
関連記事:「LLM・SLM・VLM・MLLM・LVM・LMMなどの用語、意味が分かる!」
代表的なVLM
VLMの代表的な例として以下が挙げられます。
- GPT-4o(OpenAI)
- Gemini(Google)
- LLaVA(Microsoftなど)
- Japanese Stable VLM(Stability AI)
- CLIP(OpenAI)
例えば、VLMでは以下のように画像を入力することで、画像内の情報を認識(理解)し、言語情報として回答を行ってくれます。以下の画像では、オフィスの様子であること、女性従業員が会話をしているなど、画像内の重要な要素を抽出してくれています。

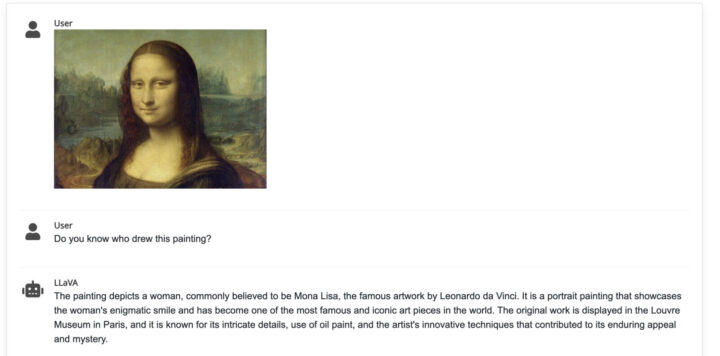
例えばLLaVAでは、以下のようにモナリザの画像を元に「誰がこの絵を描いた?」という質問に対して、何が描かれているか、という観点だけではなく、この絵画自体を理解して「モナリザとして知られるこの絵画はレオナルド・ダ・ヴィンチによって描かれた」ということまで説明を行ってくれています。
また、VLMモデルにもよりますが、テキストプロンプトを元に、画像生成を行うことも可能です。
このように、VLMは視覚と言語を融合し、より直感的かつ柔軟な方法で情報を扱うことが可能です。
VLMの仕組み
VLMは、画像とテキストのデータを同時に処理できるように設計されており、以下が重要な構成要素です。
- 事前学習:大規模な画像-テキストペアのデータセットを用いて、モデル全体を事前学習します。
- 画像エンコーダ:画像を入力として受け取り、画像の特徴を抽出します。一般的には畳み込みニューラルネットワーク(CNN)が使用されます。
- テキストエンコーダ:テキスト(質問文など)を入力として受け取り、テキストの特徴を抽出します。通常はTransformerベースのモデルが使用されます。
- マルチモーダル融合:画像特徴とテキスト特徴を統合します。Transformerの注意機構などを用いて両者の関連性を捉えます。
- デコーダ:融合された特徴から、タスクに応じた出力(回答文など)を生成します。
VLMの基本的な仕組みは「Transformer(トランスフォーマー)」に基づいています。以下二つをを組み合わせることで、画像の特徴をテキスト情報と関連付けを可能にしています。
画像とそれに対応するテキストで学習することにより、画像の内容からテキストの生成や分析が可能なモデルを構築しています。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
VLMでできること

VLMが対応できることは、以下のとおりです。
| VLMでできること | 機能の詳細 |
|---|---|
| 画像生成 | テキストの指示に基づいて関連する画像を生成 |
| 画像からサンプルコードを生成 | Webデザインの図や手書きスケッチから自動的にサンプルコードを生成 |
| 画像の内容を説明 | ユーザーの質問から画像内のオブジェクトや状況を正確に説明 |
| 画像の文章を要約・翻訳 | 専門的な技術書などの画像に含まれるテキストの多言語翻訳や要約を行う |
| 手書きの文字や図を読み取る | はがきの文字やマニュアルからデータを読み取り、デジタル化に役立てる |
| 視覚質問応答(VQA) | 画像に関する質問に答える機能 |
| 画像検索 | テキストクエリに基づいて関連する画像を検索する機能 |
VLMの活用分野
VLMのマルチモーダルな能力は、さまざまなシーンで活用され始めています。以下では、主な活用分野について紹介します。
- 自動運転:自動運転車のセンサーやカメラから取得した映像データを分析し、周囲の交通状況をリアルタイムで把握
- 医療:医師が行う診断に対して補助的な役割を果たすことで、早期発見や誤診のリスク低減に貢献
- 広告制作:年齢や性別、趣味などの広告ターゲットの情報から、より訴求力の強い広告画像を自動で作成
- カスタマーサポート:画像に関する質問にも対応でき、カスタマーサポートの対応サービスの拡大
- 商品検索:購入者が正確なアイテム名や詳細な商品情報を入力しなくても、自然言語でテキストクエリを入力するだけで商品を簡単に見つけられます。
VLMの5つのメリット
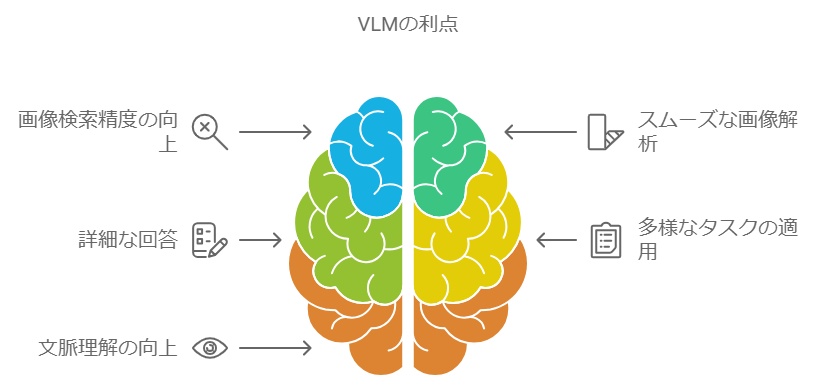
VLMには、従来のLLMや認識系AIモデルにはないメリットがいくつかあります。VLMのメリットについて、従来のLLMや認識系AIモデルと比較しながら解説します。
画像検索精度が向上する
VLMを活用すれば、テキストと画像を組み合わせて画像を検索ができるため、検索精度が大幅に向上します。
例えば、従来のキーワード検索では、ユーザーが「カジュアルな白いドレス」と入力した場合に、「白い」「ドレス」や「カジュアル」など個別キーワードに基づく結果が返される傾向がありました。結果として、白いウェディングドレスや黒いカジュアルな服が表示されるなど、ユーザーが求める意図が反映されないことも多くありました。
また、画像認識AIを用いた検索では、画像の特徴を抽出し、類似画像を検索します。そのため、テキストによる詳細な要求を理解できない限界がありました。
一方、VLMでは、「カジュアルな白いドレス」というテキスト情報と、ユーザーの好みを示す参考画像を同時に処理できます。
そのため、テキストの意味とビジュアル情報を組み合わせた、より正確な検索が可能です。結果として、ユーザーの意図により近い商品を提案できます。例えば、BitNet b1.58 のような先進的なシステムは、最新の画像と言語の統合処理技術を駆使しており、その高いパフォーマンスが実証されています。
このようなVLMのマルチモーダル検索により、従来のLLMや画像認識系AIモデルをはるかに超える精度でユーザーに最適な商品を提案でき、ユーザー体験の向上につながります。
画像解析がスムーズになる
従来の画像認識AIモデルでは、監視カメラなどから得られる映像に対して「画像内のどこに注目すべきか」が曖昧なため、不審者検出や異常検知が難しいケースも少なくありませんでした。
一方、VLMを用いることで、例えば「青い服の人物を追跡」といったように、テキストで画像のどの部分に注目すべきかを具体的に指示できるようになります。
VLMを活用すれば画像解析や物体検出の精度が飛躍的に向上し、製造現場や小売店など幅広い業界のセキュリティ強化に寄与するでしょう。
より詳細な回答ができる
近年、LLMを使用したFAQシステムやチャットボットが急速に普及しつつあります。オープンソースLLMを活用した事例も増加しており、これにより開発コミュニティが協力してより高品質なシステムの構築が期待されます。また、ローカルLLMを利用することで、企業内部でのデータ管理やセキュリティ対策が一層強化される可能性があります。
しかし、テキストのみでやり取りするため、製品の使い方など視覚情報が必要な場合には曖昧な回答しか得られないことも多く、活用シーンが限られる点が課題です。
一方、VLMを導入することで、ユーザーは質問をテキストと画像の両方で入力できるため、専門的な質問でも精度の高い回答が可能となります。例えば、ユーザーが製品画像をもとに使い方について質問した場合、画像を使った具体的で詳細な回答を得ることが可能です。
VLMは、従来のLLMと比べ、FAQシステムの活用領域を広げられるツールとして注目されています。
汎用タスクに適用可能
VLMは様々なタスクに適用可能です。従来の画像認識AIは、特定のタスク(物体検出、顔認識など)に特化しています。LLMも主に言語関連のタスクに限定されます。
一方、VLMは画像と言語に関連する幅広いタスクに対応可能です。例えば、同じVLMモデルを使って画像キャプション生成、視覚質問応答、画像検索などの異なるタスクを実行できます。
コンテキスト理解の向上
VLMは画像と言語の文脈を統合的に理解します。従来の画像認識AIは、画像の視覚的特徴のみしか理解できません。LLMは、テキストの文脈は理解できますが、視覚情報との関連付けはできません。
一方、VLMは画像の視覚情報とテキストの意味を関連付けて理解できます。これにより、より深い意味理解や推論が可能になります。例えば、画像内の物体間の関係性や、画像とテキストの間の微妙なニュアンスを捉えることができます。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
VLMのデメリット

VLMは有力なAI技術ですが、導入の際には開発コストや計算リソースなどいくつか課題も伴います。以下では、VLMのデメリットについて紹介します。
アノテーションコストが高い
VLMのトレーニングには、画像・動画・テキストの複合データが必要であり、これらのデータに対するアノテーション(ラベル付け)が不可欠です。
従来のLLMはテキストデータのみを扱い、認識系AIモデルは画像や動画に特化しているため、それぞれのデータに対するアノテーションは比較的シンプルでした。
しかし、VLMではテキストと画像などと複数のデータに対してアノテーションを行う必要があるためコストが増加します。特に、大量のデータセットに対して細かいラベル付けを行う必要があるプロジェクトでは、膨大な時間と費用がかかるため、開発者はこれを考慮に入れる必要があります。
アノテーション作業を外注できる会社をこちらで特集していますので併せてご覧ください。
計算コストが高い
VLMは、LLMと画像認識モデルの両方を統合した形で動作するため、計算リソースの要求が高くなります。従来のモデルに比べて、処理すべきデータが増える分、必要な計算リソースも倍増します。
そのため、VLMを動作させるには、高性能な計算インフラが必要になる分、ハードウェアやクラウドの利用コストも増加する点がデメリットです。特に、IoTデバイスなど計算能力の限られた環境での展開が困難です。
大規模なデータセットを用いたトレーニングやリアルタイム処理を求められるビジネス用途では、ハイエンドモデルのGPUが必要になり、導入コストが高くなる傾向にあります。
そのため、VLMを導入する際には、サービスの規模や用途に応じたコスト計画が重要です。
ハルシネーションのリスク
VLM(Vision-Language Model)におけるハルシネーション(幻覚)の問題は、AIの信頼性と安全性に関わる重要な課題です。例えば、画像に存在しない物体や人物について、あたかも存在するかのように説明したり、実際にはない詳細や背景情報を創作して提供することもあります。
主な原因は、特定のドメインや状況に偏ったデータセットで学習したことや、視覚情報よりも言語モデルの出力に依存しすぎる傾向です。
ハルシネーション問題に対処するための主な対策と課題は以下の通りです。
- より多様で偏りの少ないデータセットの構築
- 高品質なアノテーションデータの整備
- ハルシネーションを適切に検出・評価する指標の確立
- 重要な判断における人間の専門家による確認プロセスの導入
ハルシネーション問題は、VLMの実用化と社会実装において克服すべき重要な課題です。技術的な改善とともに、適切な運用ガイドラインの整備や社会的な理解の促進が求められています。
関連記事:「「AIがなぜ幻覚を生むのか?」また「それは人間にどのように影響するのか?」」
VLMについてよくある質問まとめ
- VLMとは何ですか?
VLM(Vision-Language Model)は、画像や映像とテキスト情報を統合的に処理し、理解するAI技術です。これにより、画像キャプション生成や画像検索、視覚質問応答などのタスクが可能になります。
- VLMの導入にはどのような課題がありますか?
VLMの導入には、画像やテキストデータへのアノテーション作業が必要であり、そのコストが高くなることが課題です。また、計算リソースも従来のモデルより大きくなるため、高性能なインフラが必要です。
まとめ
VLMは、視覚情報(画像や映像)とテキスト情報を統合的に処理するマルチモーダルなAI技術です。
今回の機会にVLMを導入し、ビジネスの成長を加速させましょう。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

