
Google、LLMのハルシネーション問題に挑むDataGemmaを発表
最終更新日:2024年09月16日
記事監修者:AI Market ニュース配信チーム

2024年9月12日(現地時間)、Googleは実世界の統計データを活用して生成AI、特にLLM(大規模言語モデル)のハルシネーション問題に対処する新たなオープンモデル「DataGemma」を発表した。
Data Commonsの膨大なデータを基盤とし、LLMの精度向上を目指すこの革新的な取り組みは、AI技術の信頼性向上に大きな一歩を記すものとして注目を集めている。
<本ニュースの10秒要約>
- DataGemma:Data Commonsの統計データを活用し、AIのハルシネーション問題に対処する世界初のオープンモデル
- RIGとRAGという2つのアプローチを採用し、LLMの事実性と推論能力を大幅に向上させる取り組み
- 研究者や開発者向けに公開され、AIの信頼性向上と幅広い応用を目指す画期的な技術革新
Data CommonsとDataGemmaの概要
Data Commonsは、国連やWHOなど信頼できる組織から収集した2,400億以上のデータポイントを含む公開知識グラフだ。DataGemmaは、このData Commonsの膨大なデータを活用し、AIのハルシネーション問題に対処するために設計された世界初のオープンモデルである。
GemmaモデルファミリーにData Commonsを統合することで、AIの生成結果をより正確かつ信頼性の高いものにすることを目指している。
DataGemmaが採用する2つのアプローチ
DataGemmaは、AIの精度向上のために2つの主要なアプローチを採用している。
1つ目はRIG(検索挟み込み生成)で、Gemma 2モデルにData Commonsからの情報を積極的に問い合わせ、事実確認を行う機能を追加している。
2つ目はRAG(検索拡張生成:Retrieval-Augmented Generation)で、Gemini 1.5 Proの長文脈ウィンドウを活用し、応答生成前にData Commonsから関連情報を取得することで、より包括的で正確な出力を可能にしている。
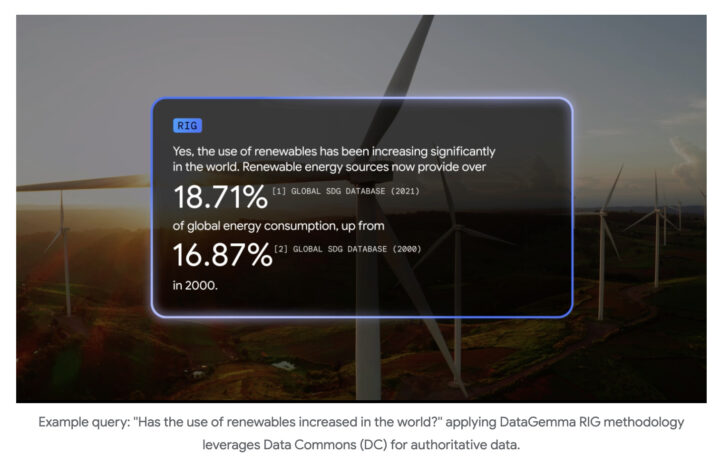

これらのアプローチにより、数値データの扱いに関して顕著な精度向上が観察されている。
研究成果と今後の展望
GoogleのDataGemma研究チームは、RIGとRAGのアプローチを用いた初期の調査結果に対して前向きな反応を示している。数値的事実の扱いにおいて、言語モデルの精度が著しく向上したことが確認された。
これにより、研究、意思決定、一般的な情報探索など、幅広い用途でAIのハルシネーションが減少すると期待されている。
Googleは今後、これらの手法をさらに洗練させ、GemmaおよびGeminiモデルへの段階的な統合を計画している。また、研究成果とDataGemmaモデルをオープンにすることで、LLMを事実データに基づかせるこの技術の広範な採用を促進することを目指している。
AI Market の見解
DataGemmaの発表は、AI技術(特にLLMにおける)の信頼性向上に向けた重要な一歩だ。実世界の統計データを活用してAIのハルシネーション問題に対処するこのアプローチは、AIの応用範囲を大きく拡大する可能性がある。
特に、政策立案、科学研究、ビジネス戦略立案など、正確な情報が不可欠な分野での活用が期待される。また、オープンモデルとして公開されることで、AI技術の浸透と透明性向上にも寄与するだろう。
ただし、データの質と更新頻度、プライバシーへの配慮など、今後解決すべき課題も残されている。DataGemmaの進化は、AI業界全体に波及効果をもたらし、より信頼性の高いAIシステムの開発を加速させる可能性が高い。
参照元:Google
LLMについて詳しく知りたい方はこちらの記事もご参考ください。

AI Market ニュース配信チームでは、AI Market がピックアップするAIや生成AIに関する業務提携、新技術発表など、編集部厳選のニュースコンテンツを配信しています。AIに関する最新の情報を収集したい方は、ぜひ𝕏(旧:Twitter)やYoutubeなど、他SNSアカウントもフォローしてください!
𝕏:@AIMarket_jp
Youtube:@aimarket_channel
TikTok:@aimarket_jp
過去のニュース一覧:ニュース一覧
ニュース記事について:ニュース記事制作方針
運営会社:BizTech株式会社
ニュース掲載に関するご意見・ご相談はこちら:ai-market-press@biz-t.jp

