
モルフォAIソリューションズ、国立国会図書館の最新AI技術を活用したOCR処理プログラムの開発を完了
最終更新日:2022年05月13日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

モルフォグループにおいてAIの事業化を担う、株式会社モルフォAIソリューションズは、国立国会図書館からの「OCR処理プログラムの研究開発」委託事業を完了したと公表しました。
<本ニュースの10秒要約>
- モルフォAIソリューションズが、国会図書館のOCR処理プログラムの開発を実施
- 本OCRでは、明治期から昭和期までの複雑なレイアウトや文字種に対応してテキスト化を実現
- OCRの認識精度は90%を超え、市販のOCRの約2倍の精度を実現
実施背景及び実施概要
国立国会図書館では、『ビジョン2021-2025 国立国会図書館のデジタルシフト』の一環として、将来にわたる全ての利用者に多様な情報資源の提供を実現するユニバーサルアクセスを実現する事業と、そのための恒久的なインフラとなる国のデジタル情報基盤の拡充を図る事業に取り組んでいます。
『ビジョン2021-2025 国立国会図書館のデジタルシフト』:https://vision2021.ndl.go.jp/
今回の委託事業では、国立国会図書館デジタルコレクション上で提供される資料画像について、今後本文テキストデータの作成を可能とすることを目的に、モルフォの保有する最新AI技術・画像処理技術を取り入れたOCR処理プログラムの研究開発を実施しました。
また、凸版印刷株式会社の協力を得て、約1,300万文字のOCR学習用データセットも構築しました。
令和3年度に開発したOCR処理プログラムは、多様なレイアウト・文字種に対応しており、既存のOCRサービスでは対応ができなかった明治期~昭和期までの複雑な資料のテキスト化までも可能になったとのことです。
■明治期~昭和期の書籍画像(2億枚)のテキスト化処理の研究開発
①複雑なレイアウトへの対応
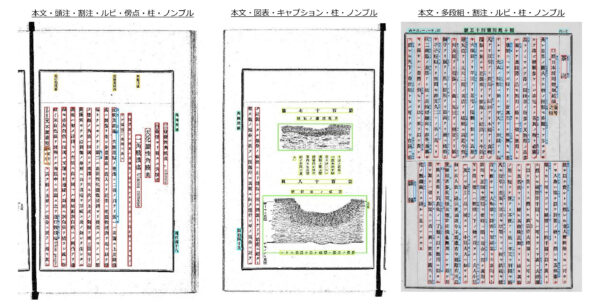
②多様な文字種(旧字旧仮名)への対応

③OCR処理プログラムの精度向上
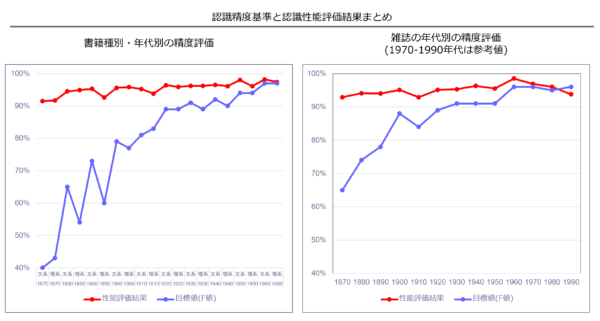
1860年代以降の書籍・雑誌において、市販されているOCRより高い90%以上の精度で認識可能となりました。
特に明治期~昭和初期の近代書籍・雑誌において、市販OCRの約2倍(約40%→90%以上)の読み取り精度となりました。
<国立国会図書館次世代システム開発研究室様コメント>
今回の取組の成果である日本語のOCR処理プログラム「NDLOCR」は、NDLラボ公式GitHubアカウント(https://github.com/ndl-lab)からオープンソースで令和4年4月25日に公開しました。
NDLOCRは、学習用データを用意することで追加の学習が可能なOCRであり、今後国立国会図書館がデジタル化する資料の全文テキストデータ作成に使用します。
プログラムのほかに、開発に用いた機械学習用データセット(著作権保護期間が満了したデジタル化資料から作成した分のみ)も近々に公開予定です。
日本語OCR全体の精度向上に資することになれば、と考えておりますので、関心のある多くの方々にご活用いただきたいと思っております。
参照元:PR TIMES
OCRについて詳しく知りたい方は、【10製品比較】AI-OCRを徹底理解!AI-OCR活用のメリットとは?もぜひご参考ください。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

