
Stable Diffusion 3.5とは?3との違い・特徴・性能を徹底解説!実画面での使い方ガイド付き
最終更新日:2025年08月27日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- Stable Diffusion 3.5は、Stability AIが開発した高精度・高速な画像生成モデルで、忠実度・画質・推論速度のバランスに優れる
- 用途に応じた3つのモデル(Large / Large Turbo / Medium)が提供され、商用ビジュアル制作から個人開発まで幅広く対応
- Webブラウザ・ローカル環境・API経由の3通りで利用可能で、誰でも柔軟に導入・活用できる
Stable Diffusion 3.5はStability AIが開発した画像生成AIモデルで、従来バージョンよりも高精度かつ高速な画像生成を実現しています。複数のモデルバリアント(Large、Large Turbo、Medium)、ローカル環境での動作、商用利用も可能な点が大きな魅力です。
本記事では、Stable Diffusion 3.5の概要から特徴、性能、実画面UIで説明する使い方、注意点を詳しく解説します。
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
画像生成システムに強いAI開発会社を自力で選びたい方はこちらで特集していますので併せてご覧ください。
目次
Stable Diffusion 3.5とは?
Introducing Stable Diffusion 3.5, our most powerful models yet.
This open release includes multiple variants that are highly customizable for their size, run on consumer hardware, and are free for both commercial and non-commercial use under the permissive Stability AI Community… pic.twitter.com/KlyE8OjrxN
— Stability AI (@StabilityAI) October 22, 2024
Stable Diffusion 3.5は、Stability AIが2024年10月に公開したテキストから画像を生成する画像生成モデルです。前バージョン(Stable Diffusion 3 Medium)の課題を踏まえ、より高品質な画像生成とプロンプトの忠実性向上を実現するために設計されました。
開発背景には、研究者・クリエイター・スタートアップからエンタープライズまで幅広い層のニーズに対応する目的があり、柔軟なカスタマイズ性と軽量な動作環境が重視されています。
年間収益が100万ドル未満の企業やクリエイターであれば、商用利用も無料で使用可能です。生成した画像の著作権は利用者に帰属するため、多くのスタートアップや中小企業にとって、非常に導入しやすいライセンス体系となっています。
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
Stable Diffusion 3.5の特徴
Stable Diffusion 3.5の特徴は以下の通りです。
- 用途別に選べる3つのモデルバリアント
- 多様なスタイルと自然なバリエーション
- 高速推論・軽量化と多様な出力に対応
- 調整しやすく開発に向いた設計
用途別に選べる3つのモデルバリアント
Stable Diffusion 3.5は、ユーザーのニーズに応じて設計された3種類のモデルが用意されています。科学研究、ホビー用途、スタートアップやエンタープライズ環境まで幅広く対応できる柔軟な構成です。
| モデル名 | パラメータ数 | 解像度 | 特徴 | 主な用途 |
|---|---|---|---|---|
| Stable Diffusion 3.5 Large | 約81億 | 1MP | 高い忠実性と画質を両立した最上位モデル |
|
| Stable Diffusion 3.5 Large Turbo | 約81億(蒸留) | 1MP |
|
|
| Stable Diffusion 3.5 Medium | 約25億 | 0.25〜2MP |
|
|
多様なスタイルと自然なバリエーション


各モデルは、写真・3D・アニメ・イラスト・線画など、幅広いスタイルの出力に対応しています。また、プロンプトに人種や文化的要素を明示しなくても、多様性のある人物像やシーンが自然に生成されやすいよう訓練されています。
短いプロンプトでも高品質なアウトプットが得られるよう調整されており、プロンプトエンジニアリングの専門家でなくてもアイデアを直感的にビジュアル化できます。
高速推論・軽量化
Stable Diffusion 3.5シリーズでは、推論性能も大きく向上しています。特にLarge Turboは、4ステップでの生成を実現しており、生成時間の短縮と品質維持を同時に達成しています。
Mediumモデルも標準的なGPU(約9.9GB VRAM)での実行を可能とし、軽量かつ実用的な構成です。これにより、高価な専用サーバーを導入することなく、AI活用のスモールスタートが可能になります。
調整しやすく開発に向いた設計
Stable Diffusion 3.5の最大の強みはカスタマイズ性にあります。企業が持つ独自のデータセットを使ってモデルをファインチューニング(追加学習)したり、「LoRA」と呼ばれる軽量な手法で特定の画風やキャラクターを学習させたりすることが容易です。
すべてのモデルでTransformerブロックにQuery-Key Normalization(QK正規化)が導入されており、モデルの訓練を安定化し、微調整やLoRA適用などを容易にしています。
この設計は、開発者・研究者による下流タスクへの応用を強く意識した構造です。自社のブランドイメージに沿ったビジュアルや、特定の製品画像を高い精度で生成する、といった専門的な用途に対応できます。
参考:Introducing Stable Diffusion 3.5
Stable Diffusion 3.5の性能
Stable Diffusion 3.5は、以下の3つのバランスに優れています。
- 忠実性
- 生成品質
- 推論速度
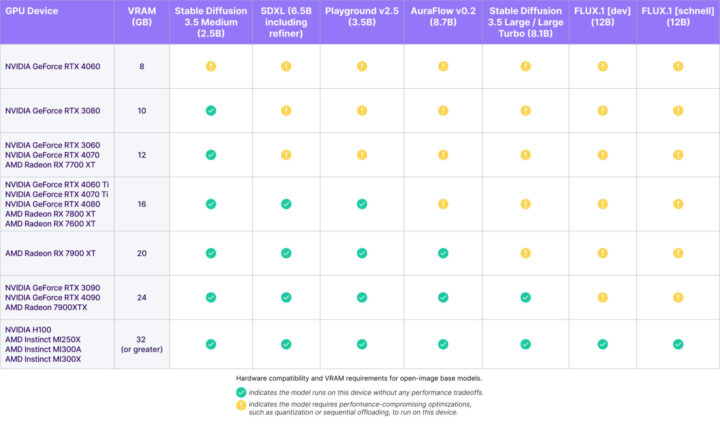
上記の表は、各画像生成モデルが、VRAM容量ごとのGPU構成でどのように動作するかを示したものです。
特に3.5 Large Turboは、4ステップで高品質な画像を出力でき、速度面で大きな優位性を持ちます。また、3.5 Mediumも2.5Bのパラメータながら、最大2MPの解像度に対応し、同規模モデルの中でも一貫した性能を示します。
Stable Diffusion 3.5 Medium(2.5B)は、VRAMが10GBあれば快適に動作します。LargeやLarge Turboなど8Bクラスのモデルは、16GB以上のVRAMを搭載した構成での使用が推奨されます。
最上位クラスのモデル(12Bなど)では、24GB〜32GB以上のVRAMが必要となるケースもあり、使用環境に応じたモデル選択が重要です。
他の画像生成AIモデルとの性能比較(プロンプト忠実度・美的品質)
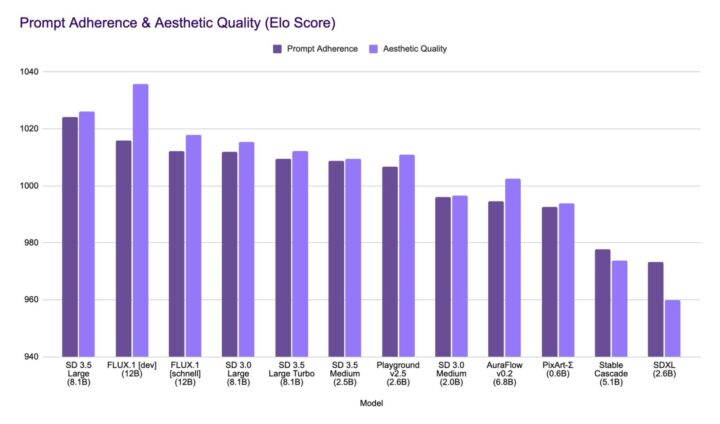
Stable Diffusion 3.5 Largeは、プロンプトの再現性と美的な表現のバランスにおいて高いスコアを記録しており、特に商用やクリエイティブ用途での信頼性の高さが示されています。
また、Stable Diffusion 3.5 Mediumは中規模モデルでありながら上位モデルと忠実度を示し、効率性と品質の両立が図られています。
上記のグラフは、Stable Diffusion 3.5を含む主要な画像生成モデルを対象に、「プロンプト忠実度(Prompt Adherence)」と「美的品質(Aesthetic Quality)」のEloスコアを比較したものです。
SDXLやStable Cascadeなど一部モデルは、両指標で相対的に低いスコアとなっており、出力品質において差があることがわかります。
参考:Introducing Stable Diffusion 3.5
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
Stable Diffusion 3との違い
以下の表は、Stable Diffusion 3と3.5の主な違いをまとめたものです。
| 項目 | Stable Diffusion 3 | Stable Diffusion 3.5 |
|---|---|---|
| 公開時期 | 2024年2月22日(早期プレビュー) | 2024年10月(正式リリース) |
| 主なモデル | 3 Medium | 3.5 Large / Large Turbo / Medium |
| パラメータ数 | 約8億〜80億 | Large: 81億 / Medium: 25億 |
| 推論速度 | 標準(通常ステップ) | Turboモデルで4ステップの高速生成 |
| 忠実性と画質 | マルチ被写体やスペル精度が改善 | 非常に高いプロンプト忠実性と画像品質 |
| 出力スタイル | 限定的 | 写真・3D・アニメ・線画など多様なスタイル |
| 構造面の改善 | Diffusion Transformer + Flow Matching | MMDiT + QK正規化により安定性と拡張性向上 |
| 対応解像度 | 非公開 | Medium: 最大2MP / Large: 1MP |
| 消費VRAM | 比較的重い | Mediumモデルは9.9GBでフル性能 |
参考:Introducing Stable Diffusion 3.5
参考:Stable Diffusion 3
Stable Diffusion 3.5を使うには?(実画面付き)
Stable Diffusion 3.5を使うには以下の方法があります
- Webサイト上で使う方法
- ローカル環境で使う方法
- APIを使って画像生成する方法
Webサイト上で使う方法(画像生成操作動画付き)
Stable Diffusion 3.5は、Stability AIの公式ウェブインターフェースを通じて利用できます。Stable Diffusionを提供するStability AI社が公式に提供しているDream Studioでは、無料範囲内であれば気軽に使用可能です。
アカウントを作成し、ログインすることで、テキスト入力から画像を生成するシンプルな操作が可能です。
- Dream Studioにアクセス
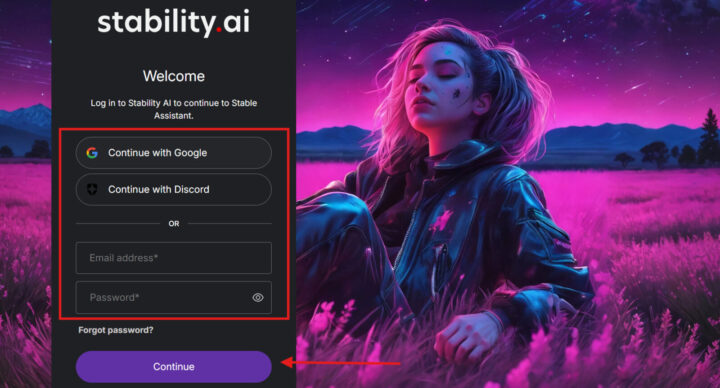
- アカウント作成またはログイン
メールアドレスやGoogleアカウントなどでアカウントを作成し、ログインします。
- 画像生成画面を開く
「Image」セクションを選び、プロンプト入力画面を開きます。 - プロンプトを入力して生成
テキストボックスに英語のプロンプトを入力し、生成ボタンを押すと、数秒で画像が生成されます。 - 生成結果を確認・ダウンロード
生成された画像は画面に表示され、クリックすることで高解像度版のダウンロードも可能です。
以下は、手順3・4・5にあたる一連の操作が行われた動画です。
ローカル環境で使う方法
- Hugging FaceまたはGitHubからモデルファイルを取得。
- ComfyUIまたはDiffusersライブラリを導入(Python環境)
他に、初心者にも比較的扱いやすい「Stable Diffusion web UI (AUTOMATIC1111版)」やそのフォーク(派生版)である「Forge」も広く使われています。 - GPU(VRAM10GB以上推奨)搭載PCで実行
参考:Introducing Stable Diffusion 3.5
APIを使って画像生成する方法
エンドポイント/v2beta/stable-image/generate/sd3
- 必要な項目:prompt、モデル名指定(例:sd3.5-large) 、出力形式(例:png/jpeg)など
- 出力形式:画像バイナリ、または base64
- 任意パラメータ:aspect_ratio、negative_prompt、seed、style_preset など
参考:StabilityAI REST API (v2beta)
画像生成・動画生成に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 画像・動画生成に強いAI会社選定を依頼
Stable Diffusion 3.5に関するよくある質問まとめ
- Stable Diffusion 3.5はどのような環境で使用できますか?
公式ウェブインターフェース、ローカル環境、APIの3つの方法で利用可能です。
ローカル環境では、MediumモデルがVRAM10GB以上のGPUで快適に動作し、LargeやLarge Turboは16GB以上のVRAMが推奨されます。
ComfyUIやDiffusersライブラリを使用してPython環境で実行できます。
- Stable Diffusion 3.5と従来版(3)の主な違いは何ですか?
主な違いは推論速度の向上、忠実性と画質の改善、多様なスタイル対応です。
3.5では特にTurboモデルで4ステップの高速生成が可能となり、写真・3D・アニメ・線画など幅広いスタイルに対応しています。
また、QK正規化により訓練安定性と拡張性が向上しています。
まとめ
Stable Diffusion 3.5は、速度・精度・汎用性・コストのすべてを高次元で両立した画像生成AIです。オープンソースかつ商用可能な点や、ローカル/APIの両対応もあり、プロフェッショナルから個人利用まで幅広く活用できます。
生成AIの導入にあたってコンサルを依頼するメリット、コンサルの選び方はこちらで特集していますので併せてご覧ください。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

