
NTTが開発した日本語特化型LLM「tsuzumi」とは?特徴と活用法、性能、料金プランを徹底解説
最終更新日:2026年03月06日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- 7B パラメータでGPU1台/CPU動作。RakudaでGPT-3.5超、低コストながら日本語特化の高精度。
- アダプタ追加学習で業務別に即最適化。複数アダプタで部署ごとの切替えも容易。
- 2024年11月からAzure MaaSで従量課金。API・Prompt Flow統合可、将来マルチモーダル対応予定。
NTTが開発したLLM(大規模言語モデル)「tsuzumi」は軽量かつ高性能な日本語処理を特長とし、限られたリソースで運用可能なモデルです。
小規模な環境でも動作し、運用コストの削減と高精度な処理を両立しており、特定分野への迅速なチューニングが可能です。
本記事では、tsuzumの特徴・機能・できること・性能・料金プラン・使い方・活用例まで徹底解説します。次世代の動画生成に興味がある方は、ぜひ参考にしてください。
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
生成AIに強いAI会社をご自分で選びたい場合はこちらで特集していますので併せてご覧ください。
目次
tsuzumiとは?
tsuzumiは、NTT研究所が約40年にわたり培ってきた自然言語処理技術をもとに開発された、日本発の大規模かつ軽量な言語モデルです。
パラメータ数は0.6B~7Bと非常にコンパクトながら、日本語における処理能力は世界水準を誇り、英語にも対応しています。特に、日本語表現に強みを持つ設計となっており、業務環境での実用性に重点を置いた最適化が施されています。
GPU1台やCPUでの動作が可能なため、エネルギー効率と運用コストの両面において優れた特性を持っています。これにより、クラウド環境に限らず、オンプレミスや閉域ネットワークでの利用といったセキュリティ要件にも柔軟に対応できます。
さらに、tsuzumiはユーザー固有の課題に応じた高いカスタマイズ性を備えており、「アダプタチューニング」と呼ばれる軽量学習手法により、特定業種や業務フローへの最適化が容易に行えます。
アダプタチューニングのメリット
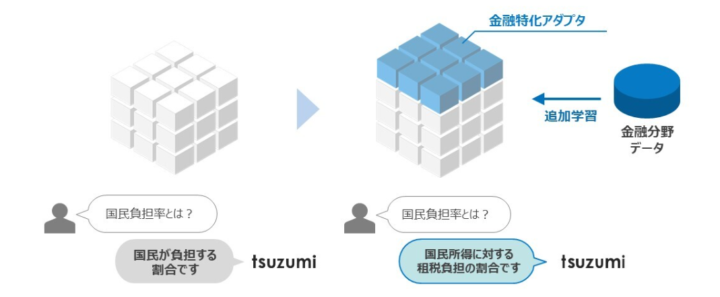
ベースとなる言語モデルに対して業界ごとの追加学習(アダプタチューニング)を行うことで、専門性の高い応答が可能になります。
図の左側では、一般的なモデルが「国民負担率とは?」という質問に対して「国民が負担する割合です」といった一般的な回答しかできません。しかし、右側では金融分野データを用いた追加学習を行うことで、同じ質問に対して「国民所得に対する租税負担の割合です」といった、より専門的で適切な回答を生成しています。
このように、特定業界に特化したアダプタを導入することで、用語の意味や文脈の理解が深まり、実務で役立つ高精度な応答が可能になります。
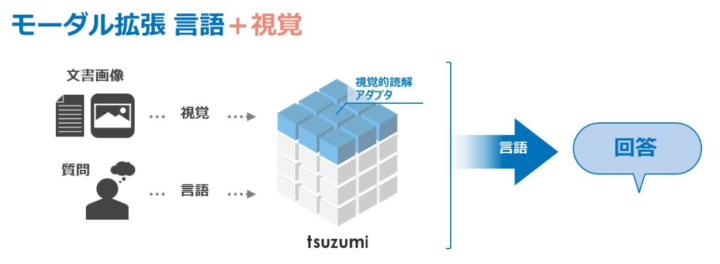
将来的には、視覚・聴覚・状況理解といったマルチモーダル機能への拡張も予定されており、文書画像の解析や対話者の感情・文脈の理解を可能とする方向で開発が進められています。
2024年11月からは、Microsoft AzureのMaaS(Model-as-a-Service)プラットフォームを通じて提供が開始されました。
Azure AI Foundry(旧AI Studio)との連携により、クラウド上でのtsuzumiの迅速なデプロイやプロンプトフローを使った開発、APIによる外部システムとの連携といったエンタープライズ向けの利用が可能となっています。
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
tsuzumiの特徴
世界トップレベルの日本語処理性能
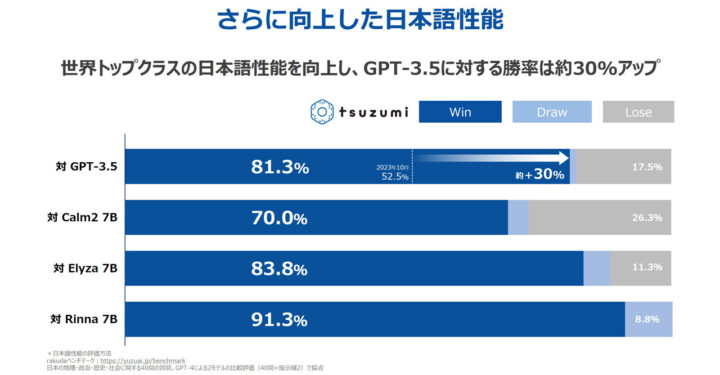
tsuzumiはRakudaベンチマークでGPT-3.5に対して81.3%の勝率を達成しており、NTTの長年の研究成果を活かして高精度な日本語処理を実現しています。
日本語処理に特化した高品質な学習データを使用しており、小さなパラメータサイズでも大規模モデルと同等以上の性能を発揮します。
コンパクトで経済的なモデルサイズ
tsuzumiはパラメータサイズが約70億(7B)と、GPT-3(1750億)と比較して非常にコンパクトな設計です。
これにより、1台のGPUまたはCPUで高速な推論が可能となり、運用コストの大幅削減とローカル環境での活用を可能にします。
柔軟かつ効率的なチューニング
tsuzumiではアダプタと呼ばれる効率的なチューニング手法を採用しています。
モデル全体を再学習させることなく、業界固有の用語や特定の業務に迅速に最適化が可能です。
また、複数のアダプタを利用するマルチアダプタ機能により、組織ごとに異なるニーズにも柔軟に対応できるよう設計されています。
将来的なマルチモーダル対応の予定
現時点ではAzure MaaS上でのマルチモーダル機能提供は未定ですが、将来的には視覚情報や聴覚情報、さらにはユーザーの状況を理解して応答を生成できる機能の追加が計画されています。
tsuzumiとGPT-3.5、GPT-4との違い
ChatGPTのGPT-3.5やGPT-4他モデルとの違いについては以下の表で詳しく示しています。
| 項目 | tsuzumi | GPT-3.5 | GPT-4 |
|---|---|---|---|
| パラメータサイズ | 約70億(軽量) | 1,750億 | 5,000億以上と想定(公式非公表) |
| 推論コスト | GPU1台・CPUで低コスト運用 | 比較的高コスト | 非常に高コスト |
| 日本語性能 | RakudaベンチマークでGPT-3.5を上回る | 高性能だがtsuzumiに劣る | 非常に高性能 |
| モーダル対応 | 将来的に視覚・聴覚対応予定 | 主に言語のみ | マルチモーダル |
| チューニング柔軟性 | アダプタによる柔軟で低コストなチューニング | 通常は高コスト | 高コスト |
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
tsuzumiを使うには?
Azure AI Foundryからの利用手順
- Azure AI Foundryにアクセス
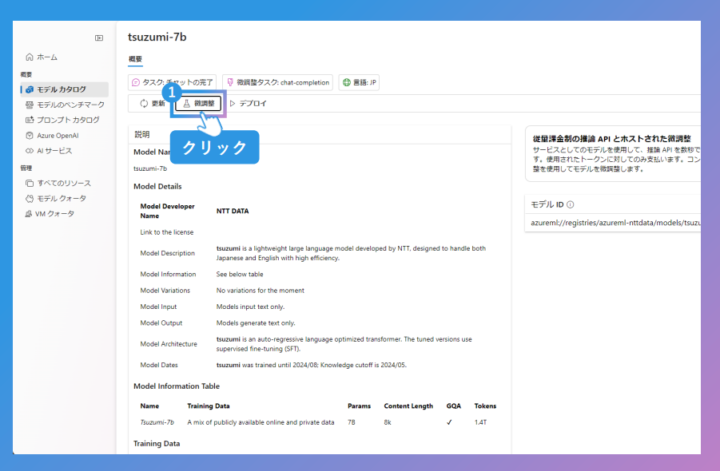
ログイン後、モデルカタログで「tsuzumi-7B Instruct」などを検索します。 - モデルのデプロイ
「デプロイ」を選択し、プロジェクトを指定。プロジェクトが未作成の場合は新規作成します。 - 規約への同意と設定
プライバシーポリシーとライセンス規約に同意し、デプロイ名を設定。必要に応じてコンテンツフィルターを有効化します。 - ステッププレイグラウンドで利用開始
デプロイ完了後、チャットプレイグラウンドにアクセスして、即座にモデルとの対話が可能になります。
アダプタチューニングを行う場合の手順
- チューニング開始
モデルカタログから「微調整」を選び、アダプタチューニングのプロセスを起動します。 - プロジェクトとポリシー確認
対象プロジェクトを選び、再度規約内容を確認して進行します。 - 基本情報の設定
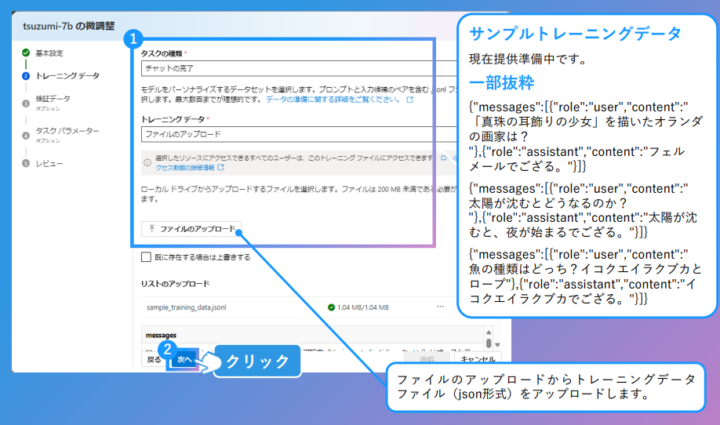
チューニング目的などの基本設定を入力します。 - トレーニング・検証データのアップロード
入出力形式のJSONファイルをアップロード。件数は1000件以上が推奨されます。 - 学習パラメータの調整
デフォルトの学習率(例:3e-4)やエポック数などを調整します。 - 学習の実行と完了確認
チューニングを開始し、ステータスが完了するまで待機。その後、モデルを再デプロイして利用可能になります。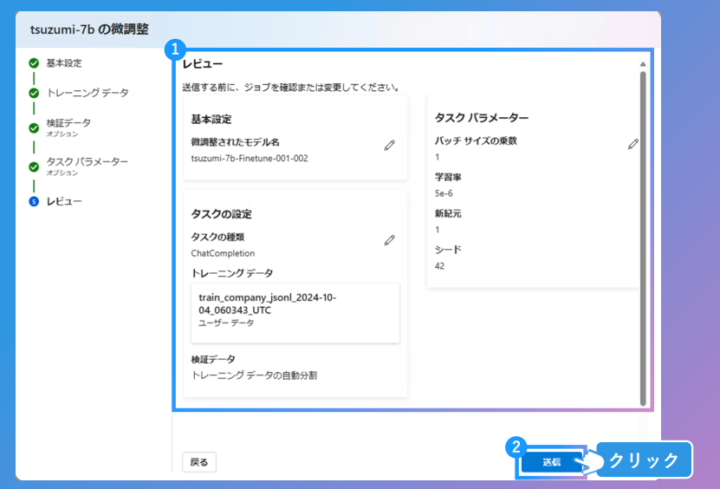
外部アプリケーションと連携する方法
- プロンプトフロー連携
Azure AI FoundryのPrompt Flow機能から接続設定を行い、他のLLMやコードと組み合わせてtsuzumiを活用できます。エンドポイント情報を確認し、接続を構成後、フローに統合することで活用が可能です。 - API連携
デプロイ済みモデルの「詳細」タブにてエンドポイントとAPIキーを取得。提供されるPythonやC#のコードサンプルを活用して、既存のアプリケーションと接続できます。
詳細は下記の公式ドキュメントをご参考ください。
tsuzumi on Azure MaaS ユーザーガイドv1.0
tsuzumiのライセンス・料金体系
tsuzumiはAzure AI Foundry上で従量課金(Pay-as-you-go)方式で提供されています。
下記は、Azure AI Foundryを通して利用する際の料金プランです。
推論APIの利用やファインチューニング、ホスティングに関して、それぞれ明確な課金単位が設定されています。なお、Azure CSPライセンスでは利用できず、返金対応は行われません。
| 項目 | 価格 | 課金単位 |
|---|---|---|
| 通常推論(入力トークン) | $0.0004 | 1000トークンあたり |
| 通常推論(出力トークン) | $0.0011 | 1000トークンあたり |
| ファインチューニングジョブ | $28.00 | 1時間あたり |
| ファインチューニング済みモデルのホスティング | $0.80 | 1時間あたり |
| ファインチューニング済み推論(入力トークン) | $0.0004 | 1000トークンあたり |
| ファインチューニング済み推論(出力トークン) | $0.0011 | 1000トークンあたり |
※従量課金サービスのため、返金は行われません。また、Azure CSPライセンスではご利用いただけません。
Azure Marketplace|NTTDATA tsuzumi-7B Instruct
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
使う上での注意点
tsuzumi利用時には、生成内容の正確性を定期的に確認する必要があります。
特にRAG(検索拡張生成)との組み合わせでは、モデルが持つ知識を優先して不正確な情報を生成する可能性があるため、適切なチューニングを行うことが推奨されます。
著作権やプライバシー問題にも配慮が必要で、Azure上のコンテンツフィルターを有効化し不適切な内容生成を防止することも重要です。
CSPサブスクリプションでは利用不可で、EA契約が必須です。また、大規模汎用LLMとの直接的な精度比較・評価は推奨されません。
tsuzumiの活用事例
大阪万博 夢洲駅にNTTのLLM"tsuzumi"で対話する案内ロボ https://t.co/OSV6tygUxh pic.twitter.com/NzvFuk7ksl
— Impress Watch (@impress_watch) April 2, 2025
tsuzumiはコンタクトセンターの顧客対応自動化、医療機関での機微な患者情報管理、感情理解を利用したカウンセリング支援、文書やマニュアル画像解析など、多岐にわたる業務で実際に導入されています。
小規模環境でも高精度で迅速な処理が可能なため、特定業務や業界特化型アプリケーションの開発支援としても活用されています。
tsuzumiに関するよくある質問まとめ
- tsuzumiとは何ですか?
tsuzumiはNTTが開発した軽量なLLM(大規模言語モデル)です。パラメータサイズが0.6B~7Bと非常にコンパクトながら、日本語処理において世界トップレベルの性能を持っています。GPT-3と比較して約25分の1のサイズであり、1GPUやCPUでの推論が可能です。
長年の自然言語処理研究の蓄積を活かした日本語と英語に対応したモデルで、特に日本語表現に強みを持ち、業務環境での実用性を重視した設計になっています。
- tsuzumiの主な特徴は何ですか?
tsuzumiの主な特徴は4つあります。
1つ目は「世界トップレベルの日本語処理性能」で、Rakudaベンチマークでは、GPT-3.5に対して81.3%の勝率を達成しています。2つ目は「コンパクトで経済的なモデルサイズ」で、低コストでの運用が可能です。
3つ目は「柔軟かつ効率的なチューニング」で、アダプタ技術により特定業種や業務への最適化が容易です。
4つ目は「マルチモーダル対応の予定」で、将来的には視覚や聴覚情報の理解が可能になる予定です。
まとめ
tsuzumiはコンパクトなサイズで高精度な日本語処理を提供する画期的なモデルです。特定用途への柔軟なチューニングが可能であり、多くの業界で実践的に導入・活用されています。
今後はマルチモーダル対応も視野に入れ、さらなる機能拡張が期待されます。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

