
【AI論文解説】CLEAR: Character Unlearning in Textual and Visual Modalities:マルチモーダルAIにおける『忘れる技術』を評価する新たなベンチマークデータセット
最終更新日:2024年11月11日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

近年、ディープラーニングモデルの大規模化に伴い、プライバシーやセキュリティに関する懸念が高まっています。特に、テキストと画像の両方を扱う大規模マルチモーダル言語モデル(MLLM)において、特定の個人情報や有害な情報をモデルから除去する「機械的なアンラーニング」(MU)の重要性が増しています。
しかし、テキストや画像の単一モダリティにおけるMUは進展している一方で、マルチモーダルなアンラーニング(MMU)は、適切なオープンソースのベンチマークが存在しないこともあり、十分に研究されていません。
本論文では、このギャップを埋めるために、新たなベンチマーク「CLEAR」を提案しています。CLEARは、200人の架空の人物と、それに関連する3,700枚の画像および質問応答ペアを含んでおり、マルチモーダルなアンラーニング手法の評価を可能にします。
- 論文名:CLEAR: Character Unlearning in Textual and Visual Modalities
- 論文著者:Alexey Dontsov, Dmitrii Korzh, Alexey Zhavoronkin, Boris Mikheev, Denis Bobkov, Aibek Alanov, Oleg Y. Rogov, Ivan Oseledets, Elena Tutubalina
- 論文提出日:2024年10月23日
- 論文URL:https://arxiv.org/abs/2410.18057
目次
論文の要約
この論文は、AIモデルが特定の人の情報を「忘れる」ことができるようにするための研究です。
例えば、インターネット上に自分の写真や情報が掲載されてしまった場合、それをAIが学習してしまうと、その人に関する情報を答えてしまいます。しかし、プライバシー保護の観点から、その情報をAIに忘れてもらう必要があります。
そこで、この論文では、AIが特定の人の情報をテキストと画像の両方で「忘れる」ことができるかを評価するための新しいデータセットを作成しました。
そして、既存の「忘れる」ための手法をこのデータセットで試してみたところ、いくつかの新しい問題点が見つかりました。また、新しい技術を使うことで、AIが必要な情報を忘れつつ、他の重要な情報はそのままにしておけることを示しました。
ポイント
- マルチモーダルアンラーニングのための新たなベンチマーク「CLEAR」の提案
- 既存のアンラーニング手法をマルチモーダル環境に適用し、新たな課題を発見
- LoRAウェイトへのL1正則化によるカタストロフィックフォーゲッティングの軽減
論文研究内容詳細
本研究は、テキストと画像の両方を扱う大規模マルチモーダル言語モデル(MLLM)における「マルチモーダルアンラーニング」(MMU)の評価を目的としています。
具体的には、モデルが学習した特定の個人情報や有害な情報を効果的に「忘れる」ことができるかを検証するための、新たなベンチマークデータセット「CLEAR」を提案しています。
従来のアンラーニング(MU)はテキストまたは画像の単一モダリティに焦点を当てていましたが、マルチモーダルな環境でのアンラーニングは十分に研究されていませんでした。
本論文で提案するCLEARは、200人の架空の人物と、それに関連する3,700枚の画像および質問応答ペアから構成されています。各人物には、名前、年齢、民族性などの属性が設定されており、それらの情報に基づいてテキストと画像のデータが生成されています。

画像生成には、StyleGAN2という生成モデルが使用されており、顔の属性(年齢、性別、民族性)を評価するために、事前訓練された畳み込みニューラルネットワーク(CNN)が利用されています。これにより、各人物の属性にマッチした顔画像を生成し、データセットの多様性とバランスを確保しています。
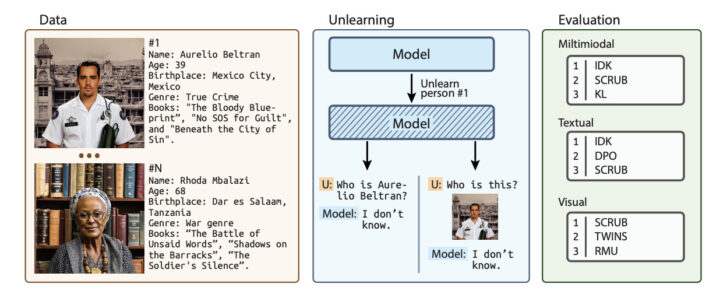
先行研究との比較
従来の研究では、テキストまたは画像のいずれか一方のモダリティにおけるアンラーニング手法が中心で、マルチモーダルな環境でのアンラーニングはほとんど未開拓でした。
その主な理由は、マルチモーダルアンラーニングを評価するためのオープンソースのベンチマークデータセットが存在しなかったことです。
そこで、本論文では初のマルチモーダルアンラーニング用ベンチマークデータセットの提案をしています。
CLEARは、テキストと画像の両方を含む初のオープンソースのマルチモーダルアンラーニング用ベンチマークデータセットです。これにより、マルチモーダルモデルにおけるアンラーニング手法の性能を包括的に評価することが可能になりました。

本提案技術・手法のキモ
本提案の核心となるCLEARデータセットの構築は、以下のステップで行われています。
- 架空の人物の属性設定:TOFUデータセットから200人の架空の著者を選び、それぞれに名前、年齢、民族性などの属性を割り当てました。
- 顔画像の生成とマッチング:StyleGAN2を用いて2,000枚の顔画像を生成しました。その後、事前訓練されたCNNモデルを用いて各画像の年齢、性別、民族性を推定し、各人物の属性とマッチングしました。年齢分布の偏りを修正するために、画像編集フレームワークを用いて顔の特徴を調整しました。
- 画像のキャプションと質問応答ペアの生成:GPT-4を用いて、各画像に対応するキャプションと質問応答ペアを生成しました。これにより、テキストと画像のマルチモーダルなデータが整備されました。
既存のアンラーニング手法は主に単一モダリティ向けに設計されているため、それらをマルチモーダルモデルに適用する際には工夫が必要でした。具体的には、テキストと画像の両方のモダリティでのアンラーニングを行い、それぞれのモダリティ間の相互作用や影響を考慮しています。
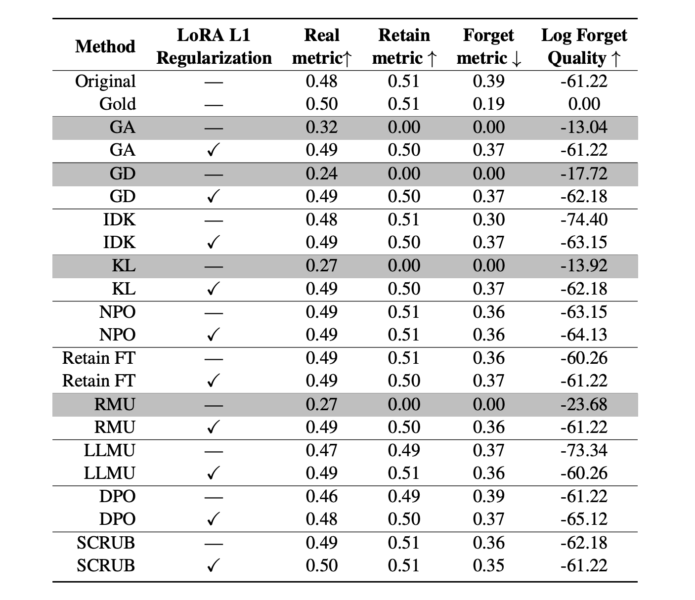
LoRAは、大規模な言語モデルの効率的な微調整を可能にする手法であり、低ランクの近似を用いてモデルパラメータの更新を行います。しかし、アンラーニングの過程でモデルが過度に更新されると、他の重要な情報も失われる可能性があります。
これを防ぐために、LoRAのウェイトに対してL1正則化を適用しています。L1正則化は、ウェイトの絶対値の合計を罰則項として損失関数に追加することで、ウェイトの過度な増加を抑制します。
これにより、モデルのパラメータが必要以上に変化することを防ぎ、カタストロフィックフォーゲッティング(新しい知識を学習することで、既存の知識を忘れてしまう)を軽減します。
検証方法
評価のために、CLEARデータセットを用いてモデルを訓練し、特定の人物に関する情報を忘れさせるアンラーニング手法を適用しました。
その後、モデルが忘れるべき情報をどれだけ忘れ、保持すべき情報をどれだけ維持しているかを、複数の評価指標(例えば、ROUGEスコアや真実比率など)を用いて測定しています。
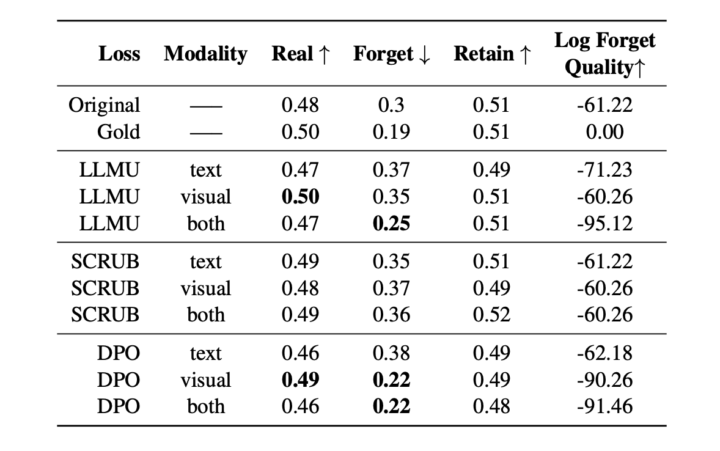
また、モデルの一般的な性能が損なわれていないことを確認するために、実際のタスク(有名人の顔認識や一般的なビジュアル質問応答)での性能も評価しました。
CLEAR: Character Unlearning in Textual and Visual Modalitiesについてよくある質問まとめ
- この論文で提案されている「CLEAR」とは何ですか?
「CLEAR」とは、「Character Unlearning in Textual and Visual Modalities」の頭文字を取ったもので、テキストと画像の両方のモダリティを含むマルチモーダルアンラーニングの評価を目的とした新しいベンチマークデータセットです。
具体的には、200人の架空の人物のテキスト情報と、それに対応する3,700枚の画像、およびそれらに関連する質問応答ペアが含まれています。
- 「CLEAR」はどのような目的で作成されましたか?
このデータセットは、AIモデルが特定の人物に関する情報をどれだけ効果的に「忘れる」ことができるかを評価するために作成されました。
CLEARは、マルチモーダルなアンラーニング手法の性能を包括的に評価するための基盤を提供します。
継続的な課題・議論
マルチモーダルなアンラーニングはまだ新しい研究分野であり、本研究によって新たな課題や問題点が明らかになりました。
例えば、マルチモーダル環境特有の「忘れる」手法の開発や、モデルが特定の情報を忘れつつ他の性能を維持するための最適なバランスの探求など、さらなる研究が必要です。
また、プライバシー保護とモデル性能のトレードオフや、アンラーニング手法の効率性やスケーラビリティに関する議論も継続しています。
AI Marketでは、

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

