
【AI論文解説】Deliberative Alignment:LLMが自ら『安全』を推論する
最終更新日:2025年02月10日
記事監修者:吉井秀旭

LLM(大規模言語モデル)の性能向上によって、さまざまなタスクで優れた成果が得られる一方、モデルが悪用されてしまうリスクや、意図しない有害な応答を生成してしまう問題が深刻化しています。
特に、違法行為の手助けや自傷行為の誘導など、人命や社会的影響につながる領域では、モデルに明確な安全基準を守らせることが急務となっています。
本論文は、このような要請に応えるため、事前に定義したセーフティ仕様(コンテンツポリシーやスタイルガイドライン)をモデルに習得・想起させたうえで回答を導く新たな手法を提案しています。以下では、その手法の狙いと実験的な効果を解説し、今後の課題や展望を概観します。
- 論文名:Deliberative Alignment: Reasoning Enables Safer Language Models
- 論文著者:Melody Y. Guan, Manas Joglekar, Eric Wallace, Saachi Jain, Boaz Barak, Alec Helyar, Rachel Dias, Andrea Vallone, Hongyu Ren, Jason Wei, Hyung Won Chung, Sam Toyer, Johannes Heidecke, Alex Beutel, Amelia Glaese|OpenAI
- 論文提出日:2024年12月20日
- 論文URL:https://arxiv.org/abs/2412.16339
目次
本論文の概要
本論文は、Chain-of-Thoughtを用いてモデルに安全性に関わる仕様を直接学習させる「Deliberative Alignment」という手法を提案しています。
通常、LLMの安全性向上には、モデル出力を人間が評価してラベルをつける「SFT(教師ありファインチューニング)」や「RLHF(人間のフィードバックによる強化学習)」などが用いられます。
しかし、これらの従来手法は、大量の人手によるラベリングが必要であったり、ポリシーの内容をモデルが明示的に学ぶわけではなく、“ラベルから間接的に学習する”ことにとどまりがちです。
これに対して著者らは、モデル自身に安全ポリシーの文章を一度明示的に与えたうえで、そのポリシー内容を参照するかたちでステップごとの思考過程を生成させ、それを学習データとしてさらにモデルを訓練する手順を導入します。
これにより、モデルが安全ポリシーを内部的に思い出し、理由づけをしながら最終的な応答を行えるようになる、というのが本手法の狙いです。
ポイント
- ポリシー文書を明示的に参照しつつChain-of-Thoughtを学習させることで、高精度な拒否判断と柔軟な応答を両立
- 従来のRLHFに比べ、ポリシーを直接モデル内部に埋め込むため、汎用的なjailbreak攻撃への耐性が向上
- 大量の人力アノテーションを必要とせず、モデル生成データを活用してスケーラブルに安全性を高める手法として有望
Deliberative Alignment
本論文は、LLMが持つ推論能力を活用して、モデル内部に安全ポリシーを「直接」学習させ、その内容を推論プロセスで参照しながら回答を得る「Deliberative Alignment」という手法を提案しています。
具体的には、以下の二段階(SFTとRL)を軸にモデルを再訓練することで、詳細なコンテンツポリシーやスタイルガイドラインを忠実に守った出力を可能にしています。
まず、各ステップの前段階として学習用データの準備(生成およびフィルタリング)を行い、最後にSFT→RLの順でモデルを訓練していきます。
学習用データ準備
コンテンツポリシーの用意
本研究で扱う安全ポリシーには、「違法行為」「自傷行為」「扇動的・暴力的内容」「規制対象の助言」など、モデルが扱うべきコンテンツカテゴリーごとのルールが細かく定義されています。
各カテゴリーで「許可される内容」「拒否すべき内容」「セーフコンテンツ回答が必要な内容」などをテキストとしてまとめ、それに加えて「ハード拒否のスタイル」「セーフコンテンツ回答のスタイル」など、応答の書き方や形式を定めるガイドラインが作成されています。
データの生成
もともとのLLM(ベースモデル)に対して、ユーザープロンプトと、そのプロンプトに関連するコンテンツポリシー情報をセットで提示します。すると、モデルは「ポリシーを参照しながら出力したChain-of-Thoughtと最終回答」を生成します。ここで得られた「Chain-of-Thought付き回答」こそが学習データの元となります。
なお、学習時の実運用では、各ユーザープロンプトに「これはどのカテゴリーに該当するか」というラベルを付与しておき、対応するカテゴリー別のポリシーをベースモデルに提示します。こうしてモデルに「必要な安全ルールだけ」を参照させたうえで回答を作らせるわけです。
フィルタリング
得られたデータのうち、ポリシーを正しく引用していない、またはポリシーに違反するような不適切回答を含むものを排除する必要があります。
そこで、もうひとつ用意したポリシーを参照できる「報酬モデル(GRM)」を使い、上記Chain-of-Thought付き回答がポリシー順守になっているか、自動的にスコアリングします。一定の閾値を下回る回答は破棄し、学習に使うのは高品質な応答のみに絞ります。
この段階の重要な工夫は「モデル自身が出力したデータを、別の報酬モデルでふるいにかける」という点です。こうすることで、大量の人手アノテーションを使わずに済み、スケーラブルな形で十分な学習用サンプルを収集できます。
SFT(教師ありファインチューニング)ステージ
フィルタリング後の(「プロンプト」「Chain-of-Thought」「最終回答」)からなるデータを用いて、「ベースモデル」を学習(ファインチューニング)します。
学習後のモデルは推論時にポリシーをコンテキストとして直接与えなくても、内部に埋め込まれた知識を思い起こしてChain-of-Thoughtを進められるようになります。「この質問は危険だから拒否」「これは翻訳だけ求められているので応答してよい」などを、自律的に判断しやすくなるのがポイントです。
RL(強化学習)ステージ
SFTの後、もう一度「安全関連のプロンプト」と「報酬モデル(GRM)」を使い、強化学習による微調整を行います。具体的な流れは以下のようになります。
- SFTで学習したモデルがユーザープロンプトに対して回答を生成(ただし、この段階ではChain-of-Thoughtは隠す場合がある)。
- 報酬モデル(GRM)が回答を採点し、そのスコアを報酬として与える。
- モデルが報酬を高める方向にパラメータを更新する。
このRL段階では、SFTで学んだ「ポリシー参照付きの思考様式」がより洗練され、例えば複数のセーフティカテゴリーが入り混じるような複雑な状況でも、より的確に違反応答を回避できるようになると報告されています。
実験結果
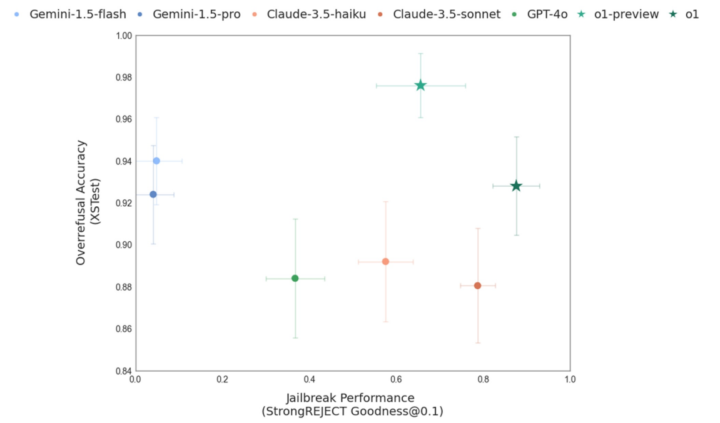
本論文では、提案手法「Deliberative Alignment」が適用されているoシリーズのモデル群(o1 や o3-mini など)をOpenAIの既存モデル(GPT-4相当のものを含む)や他社のLLM(Gemini、Claudeなど)と比較しながら、以下のような指標を計測しています。
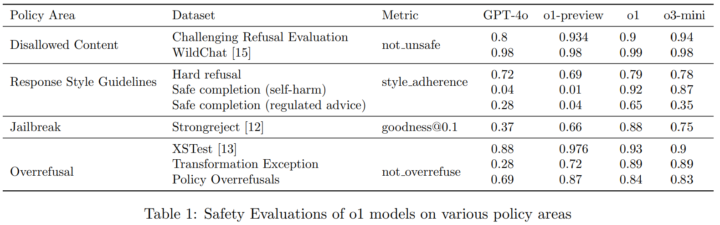
まず、禁止されるべきコンテンツへの応答率(Disallowed Content)を大幅に下げられることを確認しています。具体的には「違法行為の助長」「自傷の詳細手段リクエスト」などを正確に検知して拒否する率が向上しています。
また、拒否すべきでない質問への誤った拒否(Overrefusal)も改善されており、特にユーザーが自身で用意したテキストを翻訳・変換する「Transformation Exception」をモデルが正しく理解して拒否を回避できるようになっている例も報告されています。
さらに、外部の研究で提案された「jailbreak」攻撃、すなわちモデルをだまして本来拒否すべき応答を引き出すテクニックに対しても、Deliberative Alignment手法を施したモデルは高い耐性を示しています。
その一方で、モデルの回答スタイル(拒否応答文の定型など)についても、ハード拒否かセーフコンテンツ回答なのかを区別して整合性をとりやすくなっていることがわかります。
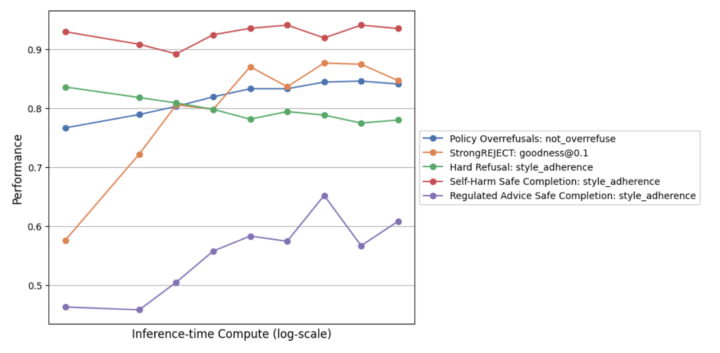
加えて、モデルが推論時に費やすステップ数を増やしてやると、さらに安全性が向上することが示されています。これは複雑な問い合わせほど長いChain-of-Thoughtを使うことで、より安全ポリシーを正確にたどれるからだというのが著者らの考察です。
考察と今後の課題
著者らは、提案手法が「ポリシーを記憶しながら、推論中にそれを思い出し、合致するかを自律的に検討する」流れを学習できることを示しています。これによって、従来の安全対策より強固な拒否ロジックや適切なセーフコンテンツの提供が可能となり、とくに複雑な“jailbreak”攻撃への耐性が高まる点を強調しています。
一方で、本研究でも完全な安全保証が得られるわけではなく、モデルの性能や規模がさらに高まるにつれて、より洗練された安全ポリシーを回避しようとするプロンプトが登場する懸念も示唆されています。
また、モデルが内部にポリシーを獲得しているため、その一部を誤って学習する危険や、内部でのChain-of-Thoughtが隠蔽的になりうるリスクも考えられます。モデルがポリシーを“何の疑いもなく絶対視”し続ける設計が、本当に望ましいかという倫理的・社会的議論も残されています。
Deliberative Alignmentについてよくある質問まとめ
- Deliberative Alignmentとはどんな手法?
モデルにあらかじめ定義した安全ポリシーの文書を学習させ、そのポリシーを推論時に思い出しながら回答を作る手法です。
従来は人間が大量のラベルを付ける方法が多かったところを、ポリシー内容をチェーン・オブ・ソートで参照させる点が大きな特徴です。
- 実際にどんな効果がある?
違法行為のリクエストや自傷行為の手引きなど、本来拒否すべき質問への対応が強化される一方、無害な質問を不用意に拒否してしまう“過剰な拒否”が減少します。
また、“jailbreak”と呼ばれる回避攻撃にも、チェーン・オブ・ソートで「ポリシー違反を狙った質問」だと見抜きやすくなります。
まとめ
Deliberative Alignmentは、「モデル自身が安全ポリシーを引用して考え、それに基づいて回答を生成する」手法を二段階の学習(SFTとRL)で行い、拒否が必要な内容を的確に判断しながら無害なリクエストにはより柔軟に対応できるモデルを実現しました。
実験結果では、既存の安全強化手法を上回る高い拒否精度と攻撃耐性を示すだけでなく、過度な拒否(overrefusal)の軽減にも寄与していることが確認されています。この成果は、高リスク領域におけるLLMの運用に大きく役立つ可能性を示唆し、今後さらに高度化するモデルの安全面を支える重要なフレームワークとなると期待されます。
AI Marketでは、

東京大学工学部でAIについて学びながら研究を行った後、東京大学大学院に進学し研究を続けています。研究内容は、錯覚を伴う身体運動を、制御や最適化に基づくシミュレーションでモデル化することです。本アカウントでは、AI関連の最新論文などの解説を行っています!

