
SLM(小規模言語モデル)とは?LLMとの違いは?小規模の理由・企業へのメリット・デメリットを徹底解説!
最終更新日:2025年08月21日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

SLM(小規模言語モデル)という軽量型のAI言語モデルが2024年頃から登場しています。2022年のChatGPTの登場以降、LLM(大規模言語モデル)は、多くのビッグテック企業が競うように開発を進め、2023年、2024年にかけて多くのLLMが開発・提供されました。
但し、LLMはその名の通り大規模が学習を行ったモデルであるため、開発コスト、運用コストも膨大です。反面、SLMは小規模な設計となっていることから、運用の柔軟性に優れ、2024年以降、多くの企業がSLMの開発・提供を進めています。
そこで、この記事では
LLMの開発に興味がある方や、自社にLLMのような自然言語AIを導入したいと考えている方は、ぜひ最後までご覧ください。
また、LLMとは何か?基本的な仕組みとその重要性についてはこちらで詳しく解説していますので併せてご覧ください。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
ChatGPT/LLM導入・カスタマイズに強いAI開発会社を自力で選びたい方はこちらで特集していますので併せてご覧ください。
目次
SLMとLLMの違いとは?

SLM(小規模言語モデル)とは、特定タスクの処理を得意とする軽量型の言語モデルであり、LLMの対比言語モデルです。
SLM(Small Language Model/小規模言語モデル)とLLM(Large Language Model/大規模言語モデル)は、ともに自然言語処理における言語モデルですが、SmallとLargeという言葉の違いの通り、規模に大きな違いがあります。
LLMの代表例であるGPT-4は約1.76兆ものパラメータを持つと言われている一方で、明確な定義はないものの、一般的なSLMのパラメータ数は数十億程度(例えば、Microsoft社の提供するPhi-3-miniは38億パラメータ)とされています。
つまり、SLMはLLMの数百〜数千分の1のパラメータサイズということになります。
このように、言語モデルの規模を表す指標の一つが「パラメータ数」であり、パラメータとは、モデルが学習する際に調整される変数のことを指します。パラメータ数が多いほど、モデルが表現できる言語の複雑さが増し、より自然な文章を生成できるようになります。
と言ってもSLMとLLMで厳密な境界値が定義されているわけではありません。
この規模の違いは、学習に用いるデータの範囲と量に起因しています。VLMの技術は、従来のテキスト中心のモデルに加え、画像情報を含む解析が可能なため、用途に応じたモデル選択の幅をさらに広げる要素として注目されています。
LLMはインターネット上の膨大な情報を学習・トレーニングに用いるため、ユーザーのあらゆる問いかけや命令に汎用的に対応することができます。しかし、その分モデルのサイズが大規模になってしまうのです。
SLMは軽量型で分野特化向き
一方、SLMは特定の目的や領域のデータを主に学習・トレーニングします。例えば、医療分野に特化したSLMであれば、医学論文や診療記録などを中心に学習を行います。
LLMに比べると汎用性に欠ける部分はありますが、その分モデルのサイズを小規模に抑えることができ、学習・トレーニングした特定の領域や分野に関しては、LLM以上の性能を発揮することができるという違いがあります。
今後は、以下のように各企業や組織の目的に応じて、LLMとSLMを使い分けていくことが重要になってくると考えられます。
関連記事:「LLM・SLM・VLM・MLLM・LVM・LMMなどの用語、意味が分かる!」
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
SLMの活用分野
企業でSLMを導入して効果を上げている分野を紹介します。
金融機関における融資審査の自動化
金融機関では、融資申請書や財務諸表など、大量の文書を処理する必要があります。これらの文書には、金融特有の専門用語や定型表現が多く含まれています。SLMを用いることで、これらの文書を自動的に分析し、融資の可否判断を支援することができます。
SLMを用いることで、審査基準の統一化も図れるため、融資判断の公平性や透明性の向上にもつながります。
法律事務所での契約書のレビューの効率化
法律事務所では、契約書のレビューに多くの時間と労力を費やしています。契約書には法律特有の専門用語や複雑な文章構造が多く含まれているため、レビューには高度な専門知識が必要とされます。SLMを活用することで、契約書のレビューを半自動化し、作業効率を大幅に向上させることができます。
弁護士はより重要な部分に集中してレビューを行うことができ、作業時間が大幅に短縮されました。また、レビューの質の向上にもつながっています。
LLMが汎用性に優れている一方、SLMは特定分野での高い性能と、導入・運用コストの低さが強みと言えるでしょう。今後は、各企業や組織の目的に応じて、LLMとSLMを使い分けていくことが重要になってくると考えられます。
なぜLLMではなくSLMが必要?

今やLLMはAIの主流となってきていますが、いくつか課題もあります。
必要な性能に対して開発コストが大きすぎる
LLMには、開発コストが大きいという課題があります。時に、必要な性能に見合わない開発コストになることもあります。
LLM はモデルのサイズが数千億〜数兆ものパラメータになります。ですから、学習やプロンプトの実行に必要な計算能力とエネルギー消費が莫大なものとなり、これによりコストが大きくなってしまいます。実際、GPT-4のトレーニングにかかるコストは少なくとも1億米ドル以上であると言われています。
このような高コストになると、LLMの研究や開発、LLMを活用したサービス開発などについては資金力のあるジャイアント企業にしかできないというのが現状です。
LLMはGPT-4をはじめとして高性能なモデルが数多くあり、日々性能を高めるための研究・開発が行われていますが、LLMのモデル高性能であればあるほど、パラメータ数が増加し、それに比例してコストが大きくなっていく課題があります。
学習・トレーニングに時間がかかる
数千億〜数兆ものパラメータを学習・トレーニングするには、膨大な量のデータが必要です。そして、それをすべて学習しトレーニングするのにも時間がかかってしまうというのが、LLMの課題の一つです。
高性能なLLM の学習作業には、膨大なデータ量や、複雑なツール・テクニックが必要となります。また、ユーザーのプロンプトに対して正確に回答することや、悪意のある回答などをしないためのトレーニング・ファインチューニングを数多く行わなければなりません。
LLMは、パラメータが多いことでユーザーからの様々なタスクをこなすことできますが、高い精度や悪意なく安全にタスクをこなすためには、膨大な学習とトレーニングが必要となってしまうという課題があるのです。
ハルシネーション(幻覚)が発生しやすい
LLM の重大な問題としてあげられるのが、ハルシネーション(幻覚)が発生しやすいということです。
LLMは学習にインターネット上のあらゆるサイトを用いています。膨大なインターネット上の情報を学習し、言葉と言葉のつながりや文脈を理解することで、あたかも人が話すような自然な言葉で、ユーザーが求める回答をすることができるようになっています。
しかし、学習した情報をもとにもっともらしく回答しますが、実際には事実でもない回答を生成してしまうことや、無関係な情報を組み合わせて回答を生成してしまうことがしばしば起こります。
LLMは、学習するパラメータが多いことで、多くの知識をもとに回答ができますが、ハルシネーションが発生しやすくなるという課題があります。
生成AIでのハルシネーションについてこちらの記事で詳しく説明していますので併せてご覧ください。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
SLMが企業にもたらす4つのメリット

SLMにはどのようなメリットがあるのでしょうか。紹介していきます。
開発コストを抑えることができる
SLMの大きなメリットは、開発コストを抑えることができるということです。SLMはLLMに比べてモデルのサイズが小さいことから、計算に必要なGPUの性能やエネルギー消費が少ないのが特徴です。
これにより、SLMの開発は設備コストや人件費、消費エネルギーのコストなどをLLMの開発に比べて小さくすることができます。
学習・トレーニングの時間を短縮できる
SLMはLLMに比べて学習時間を大幅に短縮することができます。SLMは特定の目的や領域・分野に絞ったデータを学習・トレーニングします。ですから、LLMの何兆というパラメータにくらべ、SLMは数億〜数百億というパラメータで数で済みます。
LLMに比べてパラメータ数が少ないことで、学習・トレーニングに必要な時間を短縮することができます。LLMが数十日〜数ケ月かかるのに対して、SLMは数日で学習・トレーニングを完了させることができます。
スマホやエッジAI・オフラインで使用しやすい
SLMは、スマートフォンやAIをネットワークの端末機器に直接搭載するようなエッジAI、さらにオフラインのパソコン(CPUベース)でも使えるローカルLLMやで使用しやすいのが特徴です。SLMをモバイルデバイスでも展開しやすいメリットがあります。
SLMは、スマートフォンやIoT機器でエッジLLMとしても動作するため、これまでは不可能だった方法でAIを活用できるようになります。
例えば、ネットワークがつながっていない外出先でも画像認識などを備えたSLMをスマートフォンで動かすことで、カメラで撮影した画像を認識することなどが可能となります。また、デジタルサイネージ等に搭載すれば、インターネット環境に接続されてないサイネージ上でも対話を実現することなども可能です。
ハルシネーションが発生しにくい
LLMは膨大な量の学習した情報をつなぎ合わせて、事実でない回答をすることがあります。しかし、SLMではハルシネーションが発生しにくくなります。
SLMは、特定範囲やタスクに絞って使用する事を想定しており、用途に合わせたデータのみを学習・トレーニングさせるためLLMに比べてもデータ数が少なく済みます。データ数を減らすことで、正しく回答するためのファイチューニングが行いやすくなります。SLMは、こうした要因で、LLMに比べてハルシネーションが発生しにくいというメリットが生まれます。
SLMのデメリット

SLMには以下のようなデメリットがあります。
- 汎用的でない
- データ収集の難しさ
- 専門知識が必要
SLMは、特定分野に特化しているという特徴があり、LLMに比べると汎用性で劣ってしまいます。LLMのような汎用的なタスクの処理が難しい場合もあります。
また、分野が限定的であるため、学習のためのデータ収集が難しい場合や、学習・トレーニングのための専門知識が必要となる場合があります。特に、法律分野や医療分野など、気密性や専門性が非常に高い場合は、データの収集や学習、トレーニングに高度な知識が必要となるでしょう。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
SLMの代表モデル
LLMとSLMの境界値が正式に定義されているわけではありませんが、一般にSLMとみなされており、開発側もSLMとしての利点を前面に出している代表的なモデルを紹介します。
gpt-oss
gpt-ossは、OpenAIが2025年8月に発表したオープンウェイトの言語モデルファミリーです。特にgpt-oss-20bは210億パラメータを持つ比較的小規模なモデルで、一般的なGPUでも動作するよう設計されているためSLM(小規模言語モデル)に分類してもいいでしょう。
高性能な120bモデルと共に、ツール利用や高度な推論能力に優れているのが特徴です。Apache 2.0ライセンスで公開され、誰でも自由にダウンロード、改変、商用利用が可能です。
これにより、企業や開発者は自社環境でセキュアかつ柔軟にAIを開発・運用でき、AI技術の民主化を大きく前進させるものとして注目されています。
GPT-4o mini
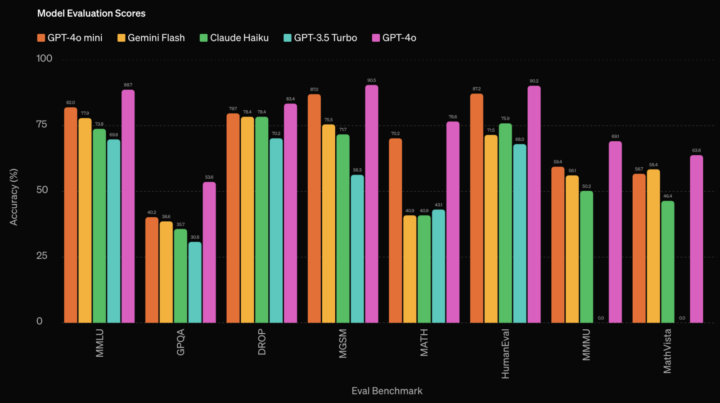
GPT-4o miniは、OpenAIが2024年7月18日に発表した軽量な自然言語処理モデルです。ChatGPTにも使われるGPT-4oの優れた機能を継承しつつ、よりコンパクトで効率的な設計が特徴です。
GPT-4よりも安価となっており、例えばGPT-4oでは100万入力トークン当たり5ドルであるのに対し、GPT-4o miniでは100万入力トークン当たり0.15ドルと約30分の1程のコストに抑えられています。(2024年9月時点)
また、軽量化されたことで回答スピードも向上しています。GPT-4oに比較すると、やや処理性能は劣るものの、GPT-3.5Turboよりも高性能であるとしています。
関連記事:「GPT-4o miniとは?OpenAIのSLMの使い方・メリット・注意点を徹底解説!」
Phiシリーズ
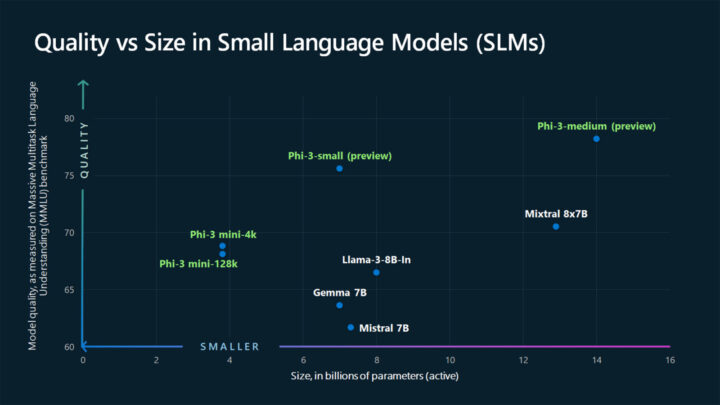
Phiシリーズは、Microsoft社が開発した高性能でコスト効率の高いSLM(小規模言語モデル)ファミリーです。このシリーズは、言語処理、コーディング、数学的推論など幅広い能力を評価するベンチマークにおいて、同サイズや時にはより大規模なモデルを上回る性能を示しています。
Phiシリーズの主な特徴は以下の通りです。
- 多様なモデルサイズ:Phi-1(13億パラメータ)からPhi-4(140億パラメータ)まで様々な用途に対応
- 特化型トレーニング:高品質な合成データセットと厳選された公開データを使用し、効率的な学習を実現。
- マルチモーダル対応:Phi-3シリーズでは画像処理能力を持つMLLM(マルチモーダルLLM)であるvisionモデルも登場。
- 広範な利用可能性:Azure AI、Hugging Face、Ollamaなど多様なプラットフォームで利用可能。
- 継続的な改善:各世代で性能と機能が向上しPhi-4では数学的推論で特に高い性能を示す。
Phiシリーズの進化は以下の通りです。
- Phi-1:Pythonコーディングに特化
- Phi-2:言語理解と推論能力の向上
- Phi-3:多様なモデルサイズと機能(mini、small、medium、vision)
- Phi-4:数学的推論に優れ、より大規模なモデルと競合する性能
Phiシリーズはエッジデバイスでの展開やリアルタイム処理が必要なアプリケーションに適しています。
Orca 2
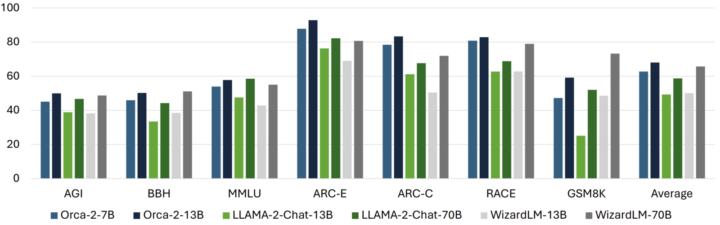
Orca 2は、Microsoft社が開発したSLMです。Orca 2は、meta社が開発した「Llama 2」というLLMをベースに、推論能力を向上させることを目的としてファインチューニングされたモデルで、推論や論理的な問題解決に焦点を当てたSLMとなっています。
Orca 2は、複雑な推論プロセスを模倣するように設計されています。LLMが直接的な回答をするようなことに対しても、Orca 2では「記憶・推論・生成、抽出・生成、直接回答」といったさまざまな解決戦略を模索した上で最適な回答を生成します。
説明のトレースやステップバイステップの思考プロセスなど、豊富なシグナルから学習し推論や論理的な問題解決に特化したOrca 2は、パラメータ数が130億ながら、推論や論理的な問題解決の分野ではLLMよりも洗練された回答ができるSLMとなっています。
Stable LM 2 1.6B

画像生成の人気モデルであるStable Diffusionで知られるStability AIが開発したStable LM 2 1.6B は、多言語で学習されたSLMです。学習している言語は次の通りです。
- 英語
- スペイン語
- ドイツ語
- イタリア語
- フランス語
- ポルトガル語
オランダ語Stable LM 2 1.6Bのパラメータ数は16億となっています。言語モデリングにおける最新のアルゴリズムを活用することで、16億という非常に小さいサイズながら、スピードと性能の好バランスを実現したモデルとなっています。
また、Stable LM 2 1.6Bのコンパクトなサイズとスピードは、ハードウェアリソースのハードルを下げ、従来のLLMよりも多くの企業や開発者が生成AIの開発を可能にします。Stable LM 2 1.6Bには、日本語で学習したSLMである「Japanese Stable LM 2 1.6B(JSLM2 1.6B)」もあります。
TinyLlama

meta社のLlamaと同じアーキテクチャを持つTinyLlamaも注目を集めているSLMの一つです。TinyLlamaのパラメータ数は、たったの11億と他のLLMだけでなく、他のSLMのサイズと比べても小規模なモデルと言えます。
しかし、そのパフォーマンスは優秀で、様々な言語処理のタスクにおいて優れた結果が出ています。TinyLlamaの学習するパラメータ数は小さいですが、トレーニングには、1兆語のデータセットが使用されており、人間の言語だけでなくプログラミング言語でもトレーニングされています。
これにより、自然言語だけでなく、PythonやJavaのようなコーディング言語でも優れた処理を行うことができるという特徴のSLMです。TinyLlamaはそのサイズが非常に小さいため、リソースの小さい様々なデバイスでも組み込むことができるモデルとなっています。
Gemma 7B

Gemma 7Bは、Google DeepMind社および他のGoogleチームによって開発された最新の軽量オープン言語モデルです。2024年2月21日にリリースされました。このモデルは、Geminiモデルの研究と技術に基づいて構築されています。
関連ニュース記事:「Google、「Gemini」と同じ技術を用いた軽量/高性能な生成AIオープンモデル「Gemma」を公開」
Gemma 7Bは、7億のパラメータを持つ大規模な言語モデルです。トレーニングには、多様なWebドキュメント、プログラミングコード、数学的テキストなど、合計6兆のトークンが使用されました。
このデータセットは、幅広い言語スタイルやトピックに対応できるよう設計されています 。Low Rank Adaptation(LoRA)技術を使用して特定のタスク向けにカスタマイズが可能であり、柔軟な適応性を持っています 。
2024年6月27日にはGemma 2がリリースされました。大規模な事前学習済みモデルを引き継ぐ「知識蒸留」の採用により、第1世代よりも高性能な推論が可能になったうえに、クラウド環境からローカル環境まで幅広いハードウェアに対応できるようになりました。
さらに、より信頼性の高い学習データの選別や人間のフィードバックを強化学習へ取り入れることで、回答の安全性を高めています。
関連記事:「Gemma 2とは?特徴・メリット・デメリット・活用分野を徹底紹介!」
Mistral 7B
Mistral 7Bは、Mistral AIチームによって開発され、2023年9月27日にリリースされました。このモデルは、Apache 2.0ライセンスの下で提供され、商用利用も含めて制限なく使用できます 。
トレーニングデータには、インターネットスケールのデータが使用され、7億のパラメータを持つモデルです。Grouped Query Attention (GQA)やSliding Window Attention (SWA)などの技術が組み込まれています。これにより、計算効率とキャッシュサイズの低減が図られています。
Mistral 7Bは、Llama 2 13Bと比較してもほとんど全てのベンチマークで優れた性能を示しています。特に、数学、コード生成、推論の分野で優れた結果を達成しています
Mistral 7Bは、クラウドやローカル環境でのデプロイが容易であり、複数のプラットフォーム(Google Cloud、AWS、Azure)での実行がサポートされています。また、Instruction-tunedモデルも提供されており、特定のタスクに最適化するためのファインチューニングが容易に行えます。
BitNet b1.58
BitNet b1.58は、Microsoft Research AsiaとChinese Academy of Sciencesの共同研究チームによって開発されたSLMです。2024年2月27日に論文『The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits』で発表されました。
BitNet b1.58は、各パラメータを-1、0、+1の3値で表現する1.58ビット量子化技術を採用しています。これにより、従来の32ビットや16ビットモデルと比較して大幅な軽量化を実現しています。
この技術により、LLM(大規模言語モデル)のモバイルデバイスやIoT機器への実装、クラウドインフラの効率化が期待されています。ただし、学習時には依然として高精度計算が必要であり、効率的な学習手法の開発が今後の課題となっています。
関連記事:「1ビットLLMの衝撃!BitNet b1.58の概要と活用方法について徹底解説!」
OpenELM
OpenELM(Open-source Efficient Language Model)は、Appleが2024年4月に発表したオンデバイス処理に特化したオープンソースLLMです。Transformerアーキテクチャを基盤とし、270M/450M/1.1B/3Bパラメータの4サイズを提供する点が特徴です。
最大の強みは層別パラメータ最適化技術にあり、従来モデルが全層均等にパラメータを配置していたのに対し、下位層は少なく上位層は多く配置する設計を採用しています。これにより、1.1BパラメータモデルでAllen InstituteのOLMo(1.2B)を2.36%精度で上回りながら、学習データ量を半減させることに成功しています。
関連記事:「OpenELMとは?Appleの狙い・商用利用・始め方・メリット・注意点を徹底紹介!」
SLMについてよくある質問まとめ
- SLMとLLMの違いは何ですか?
SLMはSmall Language Model(小規模言語モデル)、LLMはLarge Language Model(大規模言語モデル)の略称です。SLMはLLMに比べてモデルのサイズ(パラメータ数)が小さいのが特徴で、LLMが数千億から数兆のパラメータを持つのに対し、SLMは数億から数百億程度です。SLMは特定の分野やタスクに特化しており、その分野では高い性能を発揮します。
- SLMのメリットにはどのようなものがありますか?
SLMの主なメリットは、(1)開発コストを抑えられること、(2)学習・トレーニングの時間を短縮できること、(3)スマホやエッジAI、オフラインでも使用しやすいこと、(4)ハルシネーション(幻覚)が発生しにくいことです。SLMはLLMに比べてモデルのサイズが小さいため、計算に必要なリソースやエネルギー消費が少なく、コスト面でのメリットがあります。
まとめ
自然言語処理AI・生成AIは、学習するパラメータ数に比例して能力が高くなるというのが一般的でした。実際に、後発のLLMほど、そのパラメータ数は大きくなっています。しかし、SLMは、数兆のパラメータを持つLLMに比べて、非常にモデルサイズが小さくなっていますが、特定の分野やタスクにおいてはLLMと同等かそれ以上の能力を発揮するものも多くあります。
SLMはサイズが小さいことにより、LLMに比べても開発・運用コストを小さくすることができます。また、高性能なリソースが必要ないためにスマホやエッジAI、ローカル環境でも動作させることが可能となっています。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、お客様の課題ヒアリングや企業のご紹介を実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

