
ChatGPTとは?何ができる?最新機能・ビジネス活用事例・企業担当者向け導入方法・使い方徹底解説!
最終更新日:2026年03月23日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- ChatGPTは、OpenAI社が開発したLLM(大規模言語モデル)を基盤とする対話型AIであり、自然な文章生成、情報提供、多様なタスク実行が可能
- GPTモデルは継続的に進化し、マルチモーダル化が進んでいます。
- 無料プランから企業向けプランまで複数の料金プランが存在し、画像認識・生成、音声対話(Advanced Voice)、自作GPT、高度なデータ分析(Advanced Data Analysis)など、用途に応じた様々な機能が提供
- ビジネスにおいては、社内業務や顧客対応の自動化、コンテンツ作成、データ分析、プログラミング支援、アイデア創出など幅広い活用が期待
- 機密情報の取り扱いやハルシネーション(誤情報生成)、著作権などの注意点を理解し、適切な対策を講じることが重要
ChatGPTは、自然な対話を通じて文章作成、情報収集、データ分析などをこなす高性能な対話型AIです。ChatGPT以外にも多くの生成AIのサービスが公開されていますが、まだまだ生成AI業界トップを走り続けています。
この記事では、ChatGPTの基本的な仕組みから、GPTモデルの進化の歴史、無料・有料プランの違い、画像生成やデータ分析といった具体的な機能、そしてビジネスシーンでの多様な活用方法までを詳しく解説します。
さらに、企業が導入する際の注意点や、より効果的に活用するためのコツもご紹介しています。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
ChatGPTの導入支援を発注する会社を自力で探したい方はこちらもぜひ参考にしてください。
目次
- 1 ChatGPTとは?
- 2 歴代のGPTモデルとChatGPTの時系列解説
- 3 ChatGPTのプラン比較一覧表
- 4 他の対話型AIに差をつけるChatGPTの独自機能
- 4.1 画像生成(ChatGPT Images)
- 4.2 Adobeのクリエイティブアプリとの連携
- 4.3 グループチャット
- 4.4 社内知識機能(Company Knowledge)
- 4.5 ChatGPT Atlas
- 4.6 Apps SDK
- 4.7 学習モード(Study Mode)
- 4.8 ChatGPT agent
- 4.9 ChatGPT Pulse
- 4.10 Deep Research
- 4.11 Operator
- 4.12 Search(検索)
- 4.13 canvas
- 4.14 タスク機能
- 4.15 Advanced Voice
- 4.16 GPTs機能
- 4.17 マルチモーダルの対応
- 4.18 All Tools機能
- 4.19 カスタム指示機能の展開
- 4.20 Advanced Data Analysisでより高度なデータ集計・分析
- 4.21 Memory機能
- 5 ChatGPTの活用法は?何ができる?
- 5.1 社内業務の自動化
- 5.2 顧客対応の自動化
- 5.3 マニュアル・研修資料作成
- 5.4 広告クリエイティブ作成
- 5.5 コンテンツ・文章作成の効率化
- 5.6 SNS 投稿のアイデア創出・投稿文章の作成
- 5.7 文書の要約
- 5.8 リストや表の作成
- 5.9 システム開発でのコード生成
- 5.10 システム開発での要件定義、リファクタリング
- 5.11 レガシー言語のモダナイゼーション支援
- 5.12 調査と情報提供
- 5.13 文章の添削と校正
- 5.14 外国語学習支援
- 5.15 タスク管理
- 5.16 データ分析と予測
- 5.17 コミュニケーションの翻訳
- 5.18 アイデア生成
- 5.19 データドリブンな意思決定
- 5.20 商品・サービスの多言語対応の強化
- 5.21 マインドマップの作製補助
- 5.22 ペルソナ作成支援
- 5.23 動画制作支援
- 6 ChatGPTの使い方は?
- 7 ChatGPTと自社システムとの連携方法・進め方
- 8 ChatGPTを企業で活用する際の注意点
- 9 ChatGPTから最適化された情報を引き出すコツ
- 10 ChatGPTについてよくある質問まとめ
- 11 まとめ
ChatGPTとは?

ChatGPTとは、米国OpenAI社が2022年11月に公開したLLM(大規模言語モデル)を基盤モデルとして活用する対話型AI(チャットボット)です。人間のようにふるまい、自然な対話からユーザーが求める文章を生成することができます。
ChatGPTに搭載されているLLMはGPTシリーズです。膨大な量のテキストデータを学習し、人間のような自然な文章を生成できるChatGPTの基盤技術です。
ChatGPTはGPTの技術を活用して作られたユーザーとの対話用チャットインターフェースを持つサービスで、エンジンともいえるGPTの能力が向上するにつれて、ChatGPTの性能も進化していきます。
GPT初期バージョンが登場したのは2018年で、その後、相次いで新しいモデルが提供開始され、さらに各種APIの提供とその成長は止まることを知りません。
尚、2023年以降のChatGPTは、画像認識、画像生成も行えるようになっており、マルチモーダル化された対話型AIとなっています。
関連記事:「ChatGPTの画像認識の仕組み」
ChatGPTをはじめとする生成AIの台頭によって、シンギュラリティが始まったと評価する研究者も大勢います。自然なコミュニケーションを実現する対話機能を持ち、一般的な会話からビジネス的な会話まで、幅広い領域での対話が可能です。
一方で、ChatGPTを活用する上での情報漏洩や危険性への対策、著作権や商用利用に関する配慮なども必要です。
ChatGPTの仕組みはトランスフォーマーとファインチューニング
ChatGPTの根底にあるのは、トランスフォーマー(Transformer)というニューラルネットワークのアーキテクチャです。トランスフォーマーは、大量のテキストデータからパターンを学習し、その結果として自然言語処理の能力を獲得します。
ChatGPTに搭載されているLLMであるGPTは数百億の言葉を含むデータセットを使用して訓練され、結果として高度な文脈理解と文生成能力を持つようになりました。
そして、GPTにファインチューニングを行い、人間の指示・嗜好に合った応答をすることができるようにしたのがChatGPTです。ファインチューニングでは、RLHF(Reinforcement Learning from Human Feedback)と呼ばれる、人間のフィードバックに基づいた強化学習を行います。
そうすることで、あたかも人が書いたような自然な文章を生成できる仕組みです。
ChatGPTは、主に対話型アプリケーションなどの対話の応答生成に利用されています。これにより、企業や教育機関等でも活用できるようになり話題となっているのです。
ChatGPTの仕組みをこちらの記事で詳しく説明していますので併せてご覧ください。
従来のチャットボットとの違いとは?
ChatGPTは、あらかじめ用意された回答を返す従来のチャットボットと違う点は、実際の人間と会話しているようなリアルな会話文を生成できる点です。また、それまでの会話からどのような情報がほしいのか推測し返答することもでき、本当に人と話しているような自然なやり取りができるのが特徴です。
従来のチャットボットとChatGPTの決定的な違いをこちらの記事で詳しく説明していますので併せてご覧ください。
Gemini、Claudeとの違い
ChatGPT、Gemini、Claudeは、いずれも「Transformer(トランスフォーマー)」を基本としていますが、その上で各開発元が独自のアプローチや改良を加えています。
ChatGPTが大規模なテキストデータで事前学習された後、「RLHF 」を効果的に活用し、人間にとってより自然で役立つ対話ができるように調整されています。
これに対し、Google社のGeminiは、画像、音声、動画、コードなど複数の情報(モダリティ)を扱える「マルチモーダル」AIとして設計されている点が大きな特徴です。異なる種類の情報をネイティブに理解し、推論できるようにアーキテクチャレベルで最適化されています。
Anthropic社のClaudeは「Constitutional AI(憲法AI)」という独自のアプローチを重視しています。これは、AIが従うべき倫理的な原則群(憲法)を事前に設定し、AI自身がその原則に基づいて応答を自己修正する仕組みです。
これにより、より安全で、偏見が少なく、無害な応答を生成することを目指しています。
関連記事:「【モデル比較】ChatGPTとClaudeの性能・設計思想・使いやすさ・安全性・価格を徹底比較」
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
歴代のGPTモデルとChatGPTの時系列解説

GPT(Generative Pre-trained Transformer)は、2018年6月にパラメータ数1.17億個の初期モデルとして登場しました。Transformerアーキテクチャを実用的に採用したこのモデルは、その後の生成AIの歴史を決定づける一歩となりました。
OpenAIのモデル展開は現在、汎用性を追求する「メインモデル」、論理思考を極める「推論特化モデル」、そして特定用途に最適化された「派生モデル」の3つの軸で整理できます。
メインモデル
日常的な対話から高度なマルチモーダル処理まで、ChatGPTの核となるシリーズです。GPT-5以降は、それまで独立していた「推論特化モデル」のアルゴリズムが統合され、1つのモデル内でタスクに応じた思考の深さを自動調整する仕組みへと進化しています。
続いて、以下のようなモデルが発表されています。
| モデル | リリース日 | 特徴 |
|---|---|---|
| GPT-3.5 | 2022年3月 |
|
| GPT-4 | 2023年3月 |
|
| GPT-4 Turbo | 2023年11月 |
|
| GPT-4o mini | 2024年7月 |
|
| GPT-4o | 2024年5月 |
|
| GPT-4.1 | 2025年4月 |
|
| GPT-4.5 | 2025年2月 |
|
| GPT-5 | 2025年8月 |
|
| GPT-5.1 | 2025年11月 |
|
| GPT-5.2 | 2025年12月 |
|
推論特化モデル(oシリーズ)
複雑な論理パズル、高度な数学、プログラミングのデバッグなど、AIに「じっくり考えさせる」必要があるタスクのために開発されたシリーズです。内部で「思考の連鎖(Chain of Thought)」を繰り返すことで、従来のLLMが苦手とした論理的飛躍を克服しています。
o系(推論強化)モデルは以下のようにリリースされてきました。
| モデル | リリース日 | 特徴 |
|---|---|---|
| OpenAI o1-mini | 2024年9月 |
|
| OpenAI o1 | 2024年12月 |
|
| OpenAI o1 pro | 2024年12月 |
|
| OpenAI o3 mini | 2025年1月 |
|
| OpenAI o3 | 2025年4月 |
|
| OpenAI o4 mini | 2025年4月 |
|
| Codex-1 | 2025年5月 |
|
初期のo1リリース時は、汎用モデル(GPT-4o)と推論モデル(o1)を使い分ける必要がありましたが、GPT-5以降はこの境界が消失しています。
現在は一つのモデルに対し、ユーザーが「即答(Instant)」を求めるか「熟考(Thinking)」を求めるかを指定(あるいはAIが自動判断)する運用が主流となっています。
派生モデル
特定の目的や、AIの品質管理・安全性向上を目的としてOpenAI公式からリリースされた特殊モデルには以下があります。
| モデル | リリース日 | 特徴 |
|---|---|---|
| CriticGPT | 2024年6月 |
|
| SearchGPT | 2024年7月 |
|
| gpt-oss | 2025年 |
|
ChatGPTのプラン比較一覧表
ChatGPTには現在、以下のプランがあります。
- 無料プラン
- Plusプラン
- Proプラン
- Business(旧Team)プラン
- Enterpriseプラン
以下の表では無料プラン、Plusプラン、Proプラン、Business(旧Team)プランの4つを比較します。Enterpriseプランは大企業向けに設計されており、APIの利用を含む大規模な活用を目的とする場合に適していますので、ここでは割愛します。
| 特徴 | 無料 | Plusプラン | Proプラン | Business(旧Team)プラン |
|---|---|---|---|---|
| 対象ユーザー | 個人 | 個人 | 個人 | 小規模チーム |
| 月額料金 | 無料 | 20ドル | 200ドル | 年払い:25ドル/人 月払い:30ドル/人 |
| 自作GPT | なし |
|
| |
| アクセスの安定性 | 混んでいるときは遅くなることも | 安定している | ||
| 画像出力 | 限定アクセス | より緩い制限 | ||
| 画像入力 | 限定アクセス | 画像データを入力でき分析やグラフ化が可能(より緩い制限) | ||
| データ保護 | 標準 | 標準 | 標準 | 強化されたセキュリティ |
| 管理機能 | なし | なし | なし | 管理コンソール、チーム管理機能 |
| その他の特徴 | なし |
|
|
|
結論として、個人利用にはPlusプラン、企業やチームでの導入にはPlusまたはBusiness(旧Team)プランを推奨します。Plusプランでは高度なAIモデルの使用が可能になり、Business(旧Team)プランへのアップグレードによって、さらにセキュリティや管理面での利点が得られるからです。
さらに、高度なモデルやサービスを使いたい場合はProプランの使用を検討しましょう。最新の機能や詳細情報については、OpenAIの公式サイトを参照することもお勧めします。
関連記事:「ChatGPTの制限とは?プラン別の質問回数・文字数・機能の制約や対処法を徹底解説!」
他の対話型AIに差をつけるChatGPTの独自機能

ChatGPTは日進月歩どころか秒進分歩ともいえるスピードで成長しています。いくつかの重要な最新機能とその公開経過を説明します。
画像生成(ChatGPT Images)
ChatGPTの画像生成機能(ChatGPT Images)は、単なるテキストからの生成に留まらず、アップロードした画像の高度な編集や、要素の一貫性を維持した変換が可能です。特に新設された「Images」専用スペースでは豊富なプリセットスタイルを用いた直感的な操作が実現し、言語化しにくい視覚イメージの具体化を強力に支援します。
技術面では、生成速度が従来比で最大4倍に高速化され、API(gpt-image-1.5)利用時のコストも20%低減されました。
特筆すべきは、人物の外見や構図を保ったまま特定箇所のみを修正できる指示追従性の高さです。これにより、プロトタイプ作成や資料の図解化において、現場と経営層の認識齟齬を最小化し、ビジネスの意思決定を加速させる実戦的なインフラとして機能します。
Adobeのクリエイティブアプリとの連携
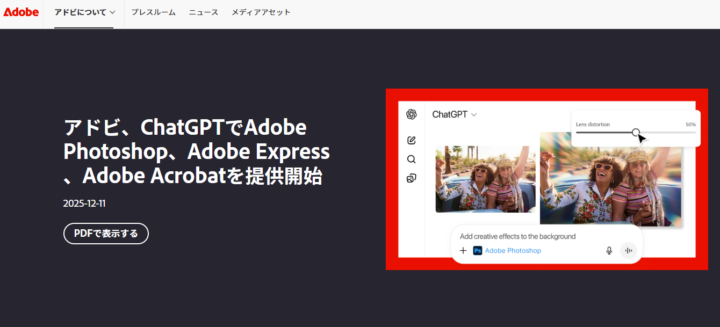
2025年12月、Adobeの主要3アプリ(Photoshop、Express、Acrobat)がChatGPTへ直接統合されました。ChatGPTの対話型インターフェース上で、画像編集、デザイン制作、PDF編集といった主要な作業を行えます。
Adobeのエージェント型AIとModel Context Protocol(MCP)を基盤とし、ユーザーが自分の言葉で制作作業を進められる点が特徴です。
Adobe Photoshopでは、自然言語での画像編集(背景ぼかし、色調補正等)に加え、チャット内に現れるスライダーで直感的な微調整が可能です。
Adobe Expressでは、数百万のプロ向けテンプレートを基に、SNSバナーやプレゼン資料のデザインを対話形式で即座に生成できます。
Adobe Acrobatでは、PDFの結合、OCR、ページ整理、さらには機密情報の墨消し(Redaction)までを自然言語で実行です。
グループチャット
ChatGPTの「グループチャット」は、従来の「人間対AI」のクローズドな関係を刷新し、複数人のユーザーと同じタイムライン上にAIが参加する招待制のコラボレーション機能です。
特筆すべき技術的進化は、最新モデル「GPT-5.1 Auto」による「ソーシャルな振る舞い」の実装です。AIは会話のフロー(文脈)を解析し、常に即答するのではなく、発言が求められるタイミングを推論して自律的に介入します。これにより、ブレインストーミングや意思決定の場において、AIが単なる検索ツールではなく、中立的なファシリテーターとして機能します。
なお、セキュリティ面では個人のメモリ機能(記憶)とは論理的に分離された設計となっており、私的な対話データがグループに漏洩するリスクを排除しつつ、セキュアな協働を実現しています。
社内知識機能(Company Knowledge)
多くの対話型AIが抱える課題は、汎用的な知識のみに基づき、企業特有の「最新かつ機密性の高い社内情報」に対応できない点です。
ChatGPTの法人プランで提供される社内知識機能(Company Knowledge)は、この点で他のAIに決定的な差をつけます。この機能は、RAG(検索拡張生成)技術を基盤とし、Slack、Google Drive、SharePoint、GitHubなどの業務アプリと直接接続するコネクタを提供します。
これにより、ChatGPTは既存のアクセス権限を尊重しながら、貴社の知識ベースをシームレスに参照し、ハルシネーション(AIの誤情報)を抑制した、根拠付きの正確な回答を生成します。
ChatGPT Atlas
ChatGPT Atlasは、OpenAIが開発したAIネイティブなWebブラウザです。従来のブラウザと異なり、ChatGPTが中核に深く統合されており、単なる情報検索ツールを超えた機能を提供します。
最大の特徴は、閲覧中のWebページの「コンテキスト(文脈)」をAIが常に理解している点です。これにより、ユーザーはタブを切り替えることなく、サイドバーでAIにページの要約や比較を指示したり、メール作成フォーム内で直接AIに文章のリライトをさせたりできます。
また、「ブラウザ・メモリ」機能により過去の閲覧履歴を記憶させ、パーソナライズされた支援を受けることも可能です。
さらに「エージェントモード」(プレビュー)では、AIがユーザーに代わり、フォーム入力や商品注文といったWeb上のタスクを自律的に実行します。これは、ブラウザがAIアシスタントの実行環境そのものになることを意味しています。
Apps SDK
OpenAI Apps SDKは、ChatGPTを単なるAIチャットから「アプリ実行プラットフォーム(OS)」へと進化させる、全く新しい公式開発キットです。従来のAPIがAIの「知能」を自社システムに組み込む(部品化する)ものだったのに対し、Apps SDKは、ChatGPTと上で直接動作する「ミニアプリ」を開発・提供するためのものです。
最大の特徴は、テキスト応答だけでなく、ボタン、カード、フォームといったリッチな「インタラクティブUI」をチャット内に直接埋め込める点です。これにより、ユーザーは会話の流れを止めずに、例えばホテルの予約や商品の購入といったアクションをChatGPT内で完結できます。
これは、8億人以上のユーザー市場に向けた「App Store」の登場に等しく、AIと自社サービスを連携させる戦略(API連携)とは全く異なる、新しいプラットフォーム戦略の幕開けを意味します。
学習モード(Study Mode)
OpenAIが2025年7月末に発表したChatGPTの新機能が「学習モード(Study Mode)」です。これは、単に質問に答えるだけのAIから脱却し、学習者の思考を促す教育ツールへと進化させたものです。
このモードの最大の特徴は、古代ギリシャの哲学者ソクラテスにちなんだ「ソクラテス式対話」を採用している点です。すぐに正解を提示するのではなく、「まず、どこから考えますか?」といった問いかけや段階的なヒントを通じて、利用者が自らの力で答えにたどり着くプロセスを支援します。
これにより、知識の丸暗記ではなく、深い理解と問題解決能力の育成を目指します。
また、利用者のスキルレベルや過去の対話履歴に応じて応答を最適化するため、一人ひとりに合わせた個別学習が可能です。個人の学習支援はもちろん、企業における新人研修や専門スキル向上など、人材育成の分野でもその活用が期待されており、教育のあり方を変える可能性を秘めた機能です。
ChatGPT agent
2025年7月17日にリリースされたChatGPT agentは、ChatGPTに統合された高度なAIエージェント機能です。
ユーザーの指示に基づいて、Webの閲覧や操作、データ分析、資料作成、外部アプリ連携などを自らの仮想コンピューター上で実行します。
従来の情報提供だけでなく、実際のアクションを伴う処理も行うため、複雑な業務や作業の自動化を数分で実現できるのが特徴です。
ChatGPT Pulse
2025年9月に発表されたChatGPT Pulseは、ユーザーの指示を待つ従来のAIとは異なり、利用者のニーズを先読みして能動的に情報を提案する新機能です。過去のチャット履歴やGoogleカレンダーなどの連携アプリから関心事や予定を学習し、毎朝パーソナライズされた情報をカード形式で自動的に届けます。
この「非同期リサーチ」機能により、ユーザーは自ら検索せずとも、その日の重要タスクや関連ニュースの要約を受け取ることが可能です。情報収集の手間を大幅に削減し、「質問に答えるAI」から「先回りして支援するパートナー」へと進化することで、日々の業務や生活の生産性を高めることを目指しています。
Deep Research
2025年2月2日にリリースされたDeep Researchは、ChatGPTに組み込まれた新しいAIエージェントです。ユーザーが質問や調査したいテーマを入力すると、Deep Researchはインターネット上の情報を自動的に検索・分析し、詳細なレポートを作成します。人間が数時間かけて行う調査であっても数分から数十分で完了します。
テキストだけでなく画像やPDFの情報も解釈・分析できるため、金融、科学、エンジニアリングなどの専門分野での深い調査や、家電や自動車の購入検討など、慎重なリサーチが求められる様々な場面で役立つことが期待されています。
Operator
Operatorは、OpenAIが開発したAIエージェントで、コンピューターの画面を理解し、マウスやキーボードを操作して作業を自動化する機能です。例えば、ウェブサイトをナビゲートしたり、フォームに入力したり、アプリの設定を変更したりを自動的に行うことが可能です。
なお、2025年2月時点では、米国のProプランのみで提供されています。
Search(検索)
ユーザーが質問すると、ChatGPTはインターネット上の最新情報を検索し、関連するウェブソースへのリンクとともに迅速かつタイムリーな回答を提供します。これにより、スポーツの最新結果、ニュース、株価情報などを自然な会話形式で得ることができます。
質問内容に応じてChatGPTが自動的にウェブ検索を行うこともありますが、ユーザーが手動で検索アイコンをクリックして検索を開始することも可能です。
canvas
2024年10月、OpenAIはChatGPTとの共同作業をより行いやすくする「canvas」機能をリリースしました。
文章作成やコード作成に適しており、出力した内容について、細かな指摘を出力内容に対して直接行うことが可能です。下記の画像のように、出力したコードのいち部分に対して、質問を行ったり、部分的に修正を指示ことができます。
タスク機能
2025年1月にOpenAIがChatGPTに導入したタスク機能は、ユーザーがリマインダーを設定したり、定期的なタスクを自動化することができる新しい機能です。この機能により、ChatGPTは指定された時間に自動的にタスクを実行し、結果を通知します。
例えば、「明日の14時に会議のリマインダーを設定して」と指示することで、指定の時間に通知を受け取ることができます。また、毎日や毎週など、定期的に繰り返すタスクを設定できます。例えば、「毎朝8時に今日の天気を教えて」と設定すれば、毎日同じ時間に天気情報を受け取ることができます。
Advanced Voice
ChatGPT Proで新たに搭載されたAdvanced Voice機能は、ユーザーがAIと音声で自然な対話を行える高度な音声モードです。その後、ChatGPT Plus、Business(旧Team)、Enterpriseユーザーも利用可能になっています。
利用には最新バージョンのモバイルアプリ(iOS/Android)、またはブラウザ版で使用可能です。ユーザーは音声入力を通じてChatGPTとリアルタイムで会話し、AIからも音声で応答を受け取ることができます。
GPT-4oなどのネイティブなマルチモーダルモデルを使用し、音声を直接「聞き」、生成します。また、音声の抑揚や感情表現を加えた読み上げも可能で、人間と話しているかのような感覚で会話ができます。
ビデオ、画面共有、画像アップロード機能も利用可能になりました。
GPTs機能
ユーザーが自身のニーズに合わせてカスタマイズ可能な「自作GPT機能」=GPTsの導入も重要な進展です。この機能により、企業や研究者は特定の分野や用途に特化したGPTモデルを作成できるようになります。
例えば、特定の業界用語や内部データを学習させることで、その分野に特化した高度な応答能力を持つChatGPTモデルを構築できます。これは、ビジネスの特定のニーズに合わせた応答、特定の研究テーマに対する深い洞察、社内データを取り込んでカスタマイズされたコンテンツ生成など、多岐にわたる応用が期待されています。
この自作GPT機能により、ChatGPTの利用範囲がさらに広がり、より個別化された応用が可能になります。
GPT Storeは、2024年1月に提供開始された、オリジナルで作成したGPTをオープンで公開、提供できるようにしたGPTアプリストアです。GPT Storeでは、学術論文検索に特化させたGPTや、デザイン作成に特化させたGPTなど様々なGPTが提供されています。
マルチモーダルの対応
ChatGPTは、マルチモーダルな対応能力も備えています。マルチモーダルとは、複数の異なるタイプの入力(テキスト、画像、音声など)を処理できる能力を指します。
マルチモーダルにより、ユーザーはChatGPTに対してテキストだけでなく、画像や音声を含む複合的なクエリを提供することができるようになります。また、音声認識や音声出力機能によって、ChatGPTはまるで自然な対話のように音声での入力に対して、音声で回答することもできます。
画像を入力として用いて、その内容に関する質問をすることや、テキストによる指示で画像を生成(Text to Image)も可能になっています。この進歩は、ChatGPTの応用範囲をさらに広げ、よりリッチなユーザー体験を提供しています。DALL・E 3が組み込まれたことで、画像の生成をシームレスに行えるようになりました。
ChatGPTとDALL・E 3を活用した画像生成機能についてはこちらの記事で解説しています。
All Tools機能
GPT-4 Turboから、「All Tools」という新機能のアップデートが含まれています。この機能は、ユーザーがChatGPTの様々な機能を一つの統合されたインターフェイスから利用できるようにするものです。
All Toolsにより、ユーザーは異なるコマンドや機能を切り替えるために複数のページやツールにアクセスする必要がなくなり、効率的かつ迅速に作業を進めることが可能になります。特にビジネスや研究の分野で、複雑なデータ分析や情報収集を行う際に、この一元化されたアプローチは大きな利点となります。
カスタム指示機能の展開
カスタム指示機能は、ChatGPTの応答をユーザーの特定のニーズや好みに合わせて調整できるようにするものです。この機能により、ユーザーはChatGPTに対して特定の指示やガイドラインを設定することができ、これによって生成される応答は、より具体的かつ目的に沿ったものになります。
例えば、特定のトーンやスタイルでの回答、特定の情報源の使用、または特定の形式でのデータの提示など、ユーザーの要求に応じて柔軟に対応することが可能です。このカスタマイズ機能により、ChatGPTはさらにユーザーフレンドリーなツールとなり、さまざまなビジネスや個人の要求に応じたカスタマイズが容易になります。
カスタム指示機能は自作GPT機能にも取り込めるようになっています。
Advanced Data Analysisでより高度なデータ集計・分析
ChatGPTでは話し言葉で指示することで、Pythonプログラムを生成・実行し、結果を出力できるAdvanced Data Analysis(旧Code Interpreter)という機能があります。従来のように、データの集計や分析でAIを活用するための専門的な知識やプログラムコードは必要となりません。
これは、ChatGPT Plusの追加機能となっていましたが、2024年9月現在は、無料版のGPT-4oなどでも設定不要で利用できるようになっています。
ChatGPTに送るプロンプトに以下のファイルを添付することができ、そのファイルの操作や読み込みを行うことができます。
ファイルを使用して、ChatGPTにどのような集計や分析を行うのかの指示を送れば、自動的にPythonのプラグラムコードを作成・実行することが可能です。この機能により、AIでデータ分析を行いたくても専門知識のハードルが高く躊躇している方でも、簡単にデータ分析を行うことができるでしょう。
関連記事:「ChatGPTのファイル読み込み機能とは?手順や活用法を徹底解説!」
Memory機能
ユーザーがチャットで入力した情報を記憶し、それを参照して回答に活かすことができる機能が搭載されました。情報の削除や変更もチャットを通じて可能です。
例えば、「私はベジタリアンだということを覚えておいて、レシピを提案するときはそれを考慮して」と指示すると、以降の会話でそれを考慮した回答が得られます。
Memory機能はデフォルトで有効になっており、ユーザーは直接ChatGPTに「これを覚えておいて」と指示することで、特定の情報を記憶させることができます。また、会話の中で重要な情報を自動的に記憶します。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
ChatGPTの活用法は?何ができる?

こちらでは、ChatGPTを活用した多岐にわたる活用法について説明します。
社内業務の自動化
ChatGPTを活用することで、社内の規則や規定等に関する質問への対応や、業務フローに関する質問への対応を自動化できます。ChatGPTに自社特有の情報を参照可能なChatGPT活用のチャットボットを構築することで、これまで特定の従業員が対応していた業務の自動化が可能です。
具体的には、以下のような方法で自動化を行います。
- 自社システムやウェブアプリケーションにAPI連携をしてChatGPTを利用する
- Azure OpenAI Serviceを使い、Azure上でChatGPTを利用する
- Azure ChatGPTを使い、自社内でChatGPTのクローンを作成して利用する
これらの方法では、ChatGPTが参照した自社特有の情報がOpenAI社に渡ることなく、セキュアな環境で社内対応を自動化できます。
尚、このようにChatGPTに対して自社の独自情報を参照させる仕組みはRAG(検索拡張生成:Retrieval-Augmented Generation)と呼ばれ、多くの日本企業がRAGを活用したチャットボットを構築しています。
顧客対応の自動化
ChatGPTを活用することで、以下のような顧客対応の自動化が可能です。
- パーソナライズされたDMの送信
- ヘルプデスクの対応
- 商品やサービスの注文に対する対応
- 顧客への提案内容作成
- 顧客アンケート結果の分析
- FAQの作成
高性能なチャットボットとしての顧客対応の自動化はもちろん、顧客への提案内容の作成や顧客アンケート結果の分析など幅広く利用することができます。顧客情報をChatGPTで取り扱う場合は、APIなどを使い情報が外部に出ないように徹底して対策を行う必要があります。
マニュアル・研修資料作成
ChatGPTの自然言語処理能力と大規模な知識ベースを活用することで、効率的かつ高品質なマニュアル作成が可能になっています。与えられた情報や指示に基づいて、人間が書いたかのような読みやすい文章を生成することができます。
また、ChatGPTは製品や業務プロセスに関する情報を理解し、それを分かりやすく説明する能力を持っています。複雑な概念を簡潔に解説したり、手順を明確に記述したりすることが得意です。
関連記事:「ChatGPTを用いたマニュアル作成の具体的な手順や活用法、プロンプト例」
広告クリエイティブ作成
ChatGPTは、広告クリエイティブ作成において強力なサポートツールとして活用されています。自然言語処理技術を活用し、ターゲット層に響くキャッチコピーや広告文を短時間で生成することが可能です。
さらに、ブランドトーンやメッセージ性を考慮した表現の調整も柔軟に対応できます。これにより、従来手間のかかっていたアイデア出しやコンセプト設計のプロセスが効率化され、クリエイティブ制作のスピードと質が向上します。
関連記事:「広告運用にChatGPTを使う事前リサーチ・改善の手法をプロンプト例付徹底解説!」
コンテンツ・文章作成の効率化
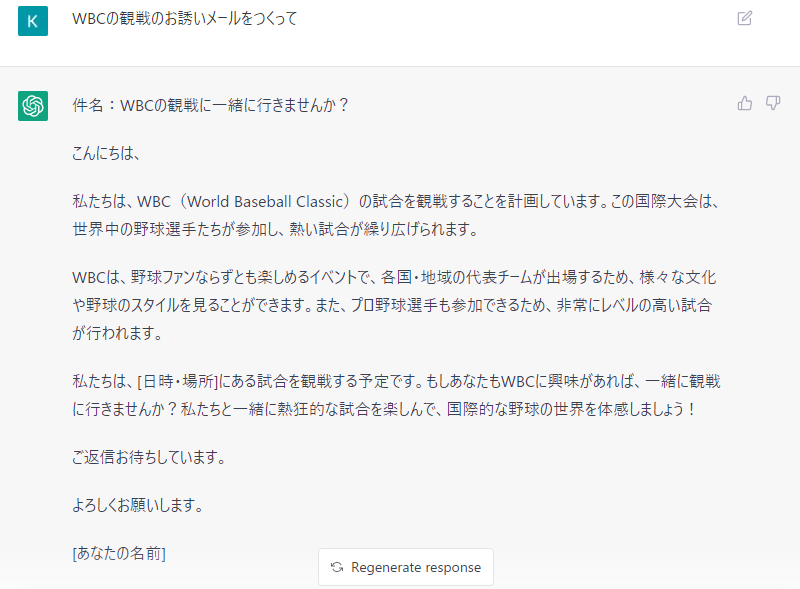
ChatGPTで以下のようなビジネス文章を作成することができます。ChatGPTは、情報発信サイトやSNS等のコンテンツや記事を作成し、配信・公開することにも有効に活用できます。
- 提案文
- 発注書、稟議書
- 申請書
- メールの下書き
- ウェブサイトのコンテンツ
例えば運営サイトのコンテンツを作成したい場合は、ChatGPT にキーワードやテーマを入力することで、記事の構成や文章を生成することができます。生成された文章をもとに、編集やブラッシュアップを行うことで、従来よりも効率的に記事を作成することが可能となります。
また、下書きとして文章を作成することなどもできるので、定型文などを書かずに書く手間が省けます。内容の手直しは必要ですが、明確に指示をすれば手直しの箇所も少なく、より正確な文章を作成することができます。ChatGPTをAPI経由で組み込むことで、この作業が格段に効率化される可能性が高まります。
関連記事:「資料作成のためのおすすめ生成AIサービス!自動化・高品質・低コストなど5つの導入メリットとは?」
SNS 投稿のアイデア創出・投稿文章の作成
ChatGPTに投稿の目的やターゲットを伝えることで、バリエーション豊かな投稿文章やハッシュタグを生成することができます。字数や表現方法などを指定すれば、各SNSに特化した投稿アイデアを作成できます。
2024年頃からは、実際にChatGPTを活用してX(旧Twitter)の投稿分を数多く作成しているインフルエンサーなども増えてきています。
また、画像を認識することもできるため、商品画像などに関する説明文やキャプションのアイデアも生成できます。Instagramを活用して集客を行いたい企業は、画像を元に投稿分をChatGPTに作ってもらうことで、これまでの投稿時間を大幅に削減することが可能になります。
文書の要約

ChatGPTは文章の要約ができます。長い文章を打ち込んだ後や説明文をコピペした後に、「文章を要約して」と送ると要約文を返してくれます。上記画像のように、論文やWebページを要約することも可能です。これも文体や出力言語などを指定することが可能です。
「実際の人間と会話している」ように自然にコミュニケーションが行えるのがChatGPTの特徴ですが、要約機能においても発揮されます。例えば、ChatGPTに「◯◯について教えて」と質問をしてその答えが返ってきた後に「要約して」と送ると「◯◯」について要約してわかりやすく教えてくれたりします。
関連記事:「ChatGPTによる要約とは?テキスト・動画・PDF向けのプロンプト・注意点を徹底解説!」
リストや表の作成

エクセル等で作成する事の多いリストや表をChatGPTで作成することもできます。
品目や性能、値段などの比較したい項目を指定することで比較表や候補リストを作成することができ、社内外での提案文の資料を簡単に作成することができます。自分で項目を並べて入力する必要がなく、ChatGPT内で調べた情報があればそのままリストや表にできるため作成する手間が大幅に省けます。
ChatGPTで作成したリストをエクセルで活用する方法をこちらの記事で詳しく説明していますので併せてご覧ください。
システム開発でのコード生成

ChatGPTは、プログラミングにおけるコーディングの補完として非常に有用です。ざっくり目標を伝えてコーディングを進めていくバイブコーディングにも活用されています。
また、システム開発のすべてのフェーズで生成AIを活用するAI駆動開発にも使われます。
ChatGPTをプログラミングに使う方法をこちらの記事で詳しく説明していますので併せてご覧ください。
システム開発での要件定義、リファクタリング
実は、この効果はプログラミングの前段階である「要件定義」から始まっています。要件定義のフェーズでChatGPTを活用し、ユーザーの曖昧な要望を明確な機能仕様に落とし込むことで、その後のコーディング指示がより的確になります。
精度の高い要件定義はChatGPTによるコード生成の品質を直接的に向上させ、開発プロセス全体の手戻りを削減するのです。
このように、開発の上流工程から関わることで、ChatGPTはプログラミングの多様な側面で貢献が期待でき、その効果はAPIや特定の開発環境と連携した場合に最も顕著です。
また、ChatGPTはコードレビューの自動化にも一役買うことができます。具体的には、コードのスタイルガイドに従っているか、または一般的なプログラミングのベストプラクティスに適合しているかを評価することができます。
以前は、2023年7月に公開されたChatGPTの機能である「Advanced Data Analysis(旧:Code Interpreter)(コード・インタープリタ)」機能を使うことでコードの生成、及び解析を行っていましたが、2024年9月時点では、このような機能を利用しなくても行うことが可能です。
レガシー言語のモダナイゼーション支援
ChatGPTは、ブラックボックス化したCOBOLなどのレガシーシステムを近代化(モダナイゼーション)する際の強力な支援ツールです。
その優れた言語能力により、難解なソースコードを解析して処理内容を日本語で分かりやすく要約したり、失われた仕様書をリバースエンジニアリングによって再作成したりすることが可能です。
また、古いコードをより保守性の高い構造に書き換えるリファクタリングの提案や、Javaなど現代的な言語への変換(マイグレーション)のたたき台を生成することで、開発工数を大幅に削減します。技術者不足が深刻なレガシーシステムの分野において、ChatGPTは属人化の解消とスムーズな技術継承を実現する切り札となります。
関連記事:「COBOL解析のChatGPT活用方法とは?メリット・注意点・他ツールとの比較も徹底解説!」
調査と情報提供
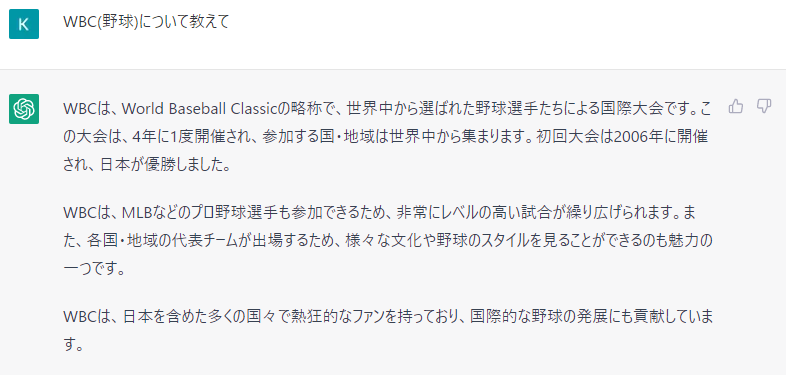
ChatGPTは、上記のような質問に対して人間のように自然に答えてくれます。気になることや調べてほしいことについて「◯◯について教えて」「◯◯とは何?」と質問すると、それに対して回答を送ってくれます。
インターネットで検索して情報を収集することが多いかと思いますが、ChatGPTに質問することで情報を収集できます。口調や文章表現方法を指定すれば、それに合わせた文章で返答することもできます。
このような情報は、新製品の開発方針を決定する際や、マーケティング戦略を考える上で非常に価値のあるデータとなります。さらに、この情報を活用することで、企業はデータドリブンな意思決定を行い、市場での競争力を一段と高めることができるでしょう。
マーケティング分野に限定してChatGPTの活用事例をこちらの記事で詳しく説明していますので併せてご覧ください。
文章の添削と校正

ChatGPTは、文章の添削と校正にも優れた能力を持っています。
例えば、企業で内部報告書やプレゼンテーション資料を作成する際、文法や表現の誤りはプロフェッショナリズムを損なう可能性があります。ChatGPTを活用することで、そのようなミスを事前に防ぐことができます。
ChatGPTは文章を入力すると、その内容に応じて最適な表現や文法に修正してくれます。さらに、ビジネス用語や専門用語にも対応しているため、専門的な文書でも安心して使用できます。
ChatGPTは、議事録の作成などで高品質な文書を短時間で作成できる点があります。これにより、企業は外部の校正サービスに依存することなく、内部で資料作成の効率を高めることができます。また、文書の品質が向上することで、企業全体のブランドイメージも高まるでしょう。
外国語学習支援
ChatGPTの音声入力・音声会話機能は、外国語学習支援において活用できます。例えば、スマートフォンアプリやPCの拡張機能を通じて、自然な発音でAIと対話しながら英会話やその他の言語を練習することが可能です。
ユーザーが話した内容をリアルタイムでテキストに変換し、文法や発音の誤りを指摘するフィードバックを受け取れます。そのため、独学でも効果的にスキルを向上させられます。
さらに、特定のトピックやシーン(例: レストランでの注文、旅行会話)を指定して実践的な対話をシミュレーションでき、ChatGPTが質問形式で応答することで会話が途切れず継続する点も魅力です。
関連記事:「ChatGPTの教育分野での活用例は?メリット・課題・実例を徹底解説!」
タスク管理

ChatGPTをAPIを用いて自社システムと連携させることで、自動的にタスクを分類したり、優先度を設定することが可能になります。
タスク管理は、企業運営において欠かせない要素です。しかし、多くの場合、タスク管理は手作業で行われ、その結果、効率が落ちることが少なくありません。さらに、ChatGPTの自然言語処理能力を活用して、メールやチャットから自動的にタスクを生成し、適切な部署や担当者に割り当てることもできます。
具体例を挙げると、ChatGPTに「今週の重要なタスクは何ですか?」と尋ねると、登録されたタスクリストから重要度や緊急度に基づいて、最適なタスクを提示してくれます。
このようにして、ChatGPTの活用により、タスク管理が一段と効率的になります。担当者は単純作業から解放され、より高度な分析や戦略的な業務に専念できるようになります。タスクの処理時間が大幅に短縮され、人的ミスも減少します。
データ分析と予測

データ分析と予測は、ビジネス戦略を練る上で欠かせない要素です。ChatGPTはこの領域でも非常に有用で、特にAPI連携を活用することで、その能力を最大限に引き出すことができます。
従来のデータ分析ツールとの違いは、ChatGPTが自然言語処理の能力を活用して、テキストデータや顧客のレビューも分析に取り込むことができる点です。
また、従来の販売データに加えて、ChatGPTを用いてSNSやオンラインレビューでの顧客の反応も分析します。
これにより、企業は自社商品のデザイン改善や、特定のアイテムに対するプロモーション戦略を練ることができます。単に数値データを解析するだけでなく、顧客の感情やニーズにも踏み込んだ感情分析が可能となります。
ChatGPTによるデータ分析で顧客満足度の向上が期待できます。満足度が高まれば、リピート購入や口コミによる新規顧客獲得が増え、結果として売上と利益が向上する可能性が高まります。
ChatGPTとエクセルを連携してデータ分析する方法をこちらの記事で詳しく説明していますので併せてご覧ください。
コミュニケーションの翻訳

多国籍企業や海外との取引が多い企業にとって、翻訳は避けて通れない課題です。ChatGPTは高度な自然言語処理能力を持つため、翻訳作業も得意とします。特にAPIと連携させることで、翻訳の自動化と高度化が可能です。
ChatGPTは多言語対応が可能なため、翻訳や多言語のコンテンツ作成にも活用できます。また、言語や文化の違いを理解し、地域特有のニュアンスを取り入れたコンテンツを生成することも可能です。
従業員が多言語でのコミュニケーションにストレスを感じることなく、より効率的な業務運営が可能になることは大きなメリットです。これにより、プロジェクトの進行速度が向上し、全体としての生産性が高まるでしょう。
AIを活用した翻訳サービスの事例をこちらの記事で詳しく説明していますので併せてご覧ください。自社サービスの多言語対応や、海外顧客へのアプローチが可能となり、グローバルな市場へのビジネス展開ができるようになります。
尚、OpenAIの提供するWhisperという音声認識モデルと組み合わせることで、上記のようなリアルタイム多言語翻訳が可能となります。
アイデア生成

ChatGPTは、自然言語処理(NLP)の高度な能力を持つため、アイデア生成にも非常に適しています。ChatGPTをアイデア生成の壁打ちに使うことで、アイデア生成のスピードと質の向上が期待可能です。
例えば、初期のアイデア生成はChatGPTに任せ、その後の詳細なブラッシュアップを人間が行うといった使い方が考えられます。
また、ChatGPTはアイデア生成のプロセスを多角的にサポートし、人力では考えにくいような新しい視点やアプローチを提供できるのです。
ChatGPTは多くの文献や記事、フォーラムなどから学習しています。そのため、一つの問題に対しても多角的な視点からアイデアを提供することができます。
また、人力でのアイデア生成には時間がかかる場合が多いですが、ChatGPTは瞬時に多くのアイデアを生成できます。これにより、ブレインストーミングの時間を大幅に短縮できます。
データドリブンな意思決定
データドリブンな意思決定は、現代ビジネスにおいて欠かせない要素です。ChatGPTをAPIとして既存のビジネスインテリジェンスツール(BIツール)に組み込むことで、このプロセスがさらに進化します。
ChatGPTは、市場のトレンド分析から、顧客の購買履歴やレビューまで、多角的にデータを解析することができます。
例えば、新製品の市場投入前に、競合他社の製品レビューを解析し、その情報を新製品の開発にフィードバックするといったケースが考えられます。このような手法を取ることで、市場での成功確率を高めることができるでしょう。
商品・サービスの多言語対応の強化
自社商品の商品やサービス情報の多言語対応は、グローバルなビジネス展開において必須の要素です。ChatGPTをAPIとしてCRMやCMSに組み込むことで、この多言語対応が一段と強化されます。
具体的には、ChatGPTは50以上の言語に対応しており、顧客サポートや製品説明文、マーケティング資料などを瞬時に多言語に翻訳することが可能です。
この機能の活用によるベネフィットは、海外市場でのビジネス展開がスムーズに行える点です。例えば、新規市場に参入する際に、既存のマーケティング資料をその国の言語に翻訳する作業が大幅に効率化されます。
関連記事:「ChatGPTを活用したコスト削減手法」
ChatGPTのさらに面白い活用方法をこちらの記事で詳しく説明していますので併せてご覧ください。企業のChatGPT導入事例はこちらの記事で詳しく説明していますので併せてご覧ください。
マインドマップの作製補助
マインドマップは中心テーマから情報を整理する手法で、ChatGPTとの相性が抜群です。ChatGPTは入力されたテーマから関連概念を自動抽出し、階層構造を瞬時に構築できます。自然言語での指示だけでアイデアを体系化し、専門スキルがなくても誰でも簡単に利用可能。
画像生成機能を使う方法もありますが、テキストベースの構造を生成し、PlantUMLやMermaidなどの外部ツールと連携することで、より高度な視覚化が可能です。従来はユーザー自身が階層を構築する必要がありましたが、ChatGPTが自動的に関連要素を整理できます。
作業時間を大幅に短縮し、質の高いアイデア構築や多角的な視点の提案に集中できます。
関連記事:「ChatGPTを活用してマインドマップを作成できる?作成方法・プロンプト設計のコツ・注意点を徹底解説!」
ペルソナ作成支援
ChatGPTはマーケティング分野でのペルソナ作成を効率化し、質を向上させる強力なツールです。具体的なターゲット像を多角的な視点から構築できるため、マーケティング戦略の精度向上に貢献します。
ChatGPTを活用したペルソナ作成の主なメリットは以下の通りです。
- 瞬時にペルソナを複数パターン作成できる
- 自社だけでは気づかない多様な視点を取り入れられる
- プロンプト設定により必要な条件を詳細に指定可能
実際の活用方法としては、サービスや商品の説明を入力し「このサービスに最適なペルソナを3人分作ってください」と依頼することで、名前、年齢、職業、趣味、課題など詳細なペルソナ情報を生成できます。これにより、「誰に」「どのように」訴求すべきかが明確になり、効果的なマーケティング施策の立案が可能になります。
関連記事:「ChatGPTでペルソナ設計ができるの?作成方法やプロンプト例を徹底解説!」
動画制作支援
ChatGPTを動画制作企画、アイデア出しの高速化に活用できます。動画のテーマやターゲットに応じた多様なアイデアを迅速に提案してくれます。
また、動画の構成に沿った具体的なセリフやナレーションを自動生成できます。専門的な内容も分かりやすく、ターゲットに合わせたトーンで作成可能です。
Soraのような動画生成AIへの指示(プロンプト)作成にも使えます。ChatGPTの活用により、動画制作にかかる時間とコストを削減し、より手軽に、かつ質の高い動画コンテンツを生み出すことが期待できます。
関連記事:「ChatGPTを活用した動画制作の方法は?生成・編集に使える実戦プロンプト・GPTsを徹底解説!」
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
ChatGPTの使い方は?

ChatGPTを活用する方法には以下があります
- ブラウザ
- スマホアプリ
- API
- ChatGPT Enterprise
- Microsoft Copilotを使う
以下に詳しい説明を記載します。ChatGPTのアカウントを削除する方法はこちらの記事で解説しています。
ブラウザから使う
PCでブラウザからChatGPTを登録して始める方法が最もスタンダードな使用方法です。オンラインで提供されているチャット対話システムを手軽で簡単に利用できます。
参考:ChatGPT公式サイト
自分でChatGPTを設定する必要がなく、手軽に利用できます。ただし、利用できる機能に制限がある場合があり、必要とする機能をすべてカバーしていない場合があります。
特に、企業が必要とする機能はカバーできていないことが多いでしょう。企業で安定運用するには、有料プランのChatGPT Plus、またはEnterpriseプランの導入は必須でしょう。
ログイン方法はこちらで説明しています。また、ChatGPTが使えない場合は、こちらをご参照ください。
関連記事:「ChatGPTの電話番号認証は必要?有料版・API利用での違い・エラー回避方法まで徹底解説!」
スマホアプリから使う
お使いのスマホからスマホアプリでChatGPTを使用できます。App Store(iPhoneの場合)またはGoogle Play Store(Androidの場合)を開いてダウンロードしましょう。正式なChatGPTアプリを見つけるためには、開発者名がOpenAIであることを確認してください。
APIを使う
APIを使用してChatGPTを利用する場合、自社のアプリケーションやサービスにチャット対話機能を統合できます。企業がChatGPTを活用する際には、APIを使用してChatGPTを統合することが一般的です。
API(Application Programming Interface)は、異なるシステム間で情報をやり取りするための仕組みであり、ChatGPTのAPIを利用することで、企業は独自のアプリケーションやサービスに対話的な機能を追加できます。ChatGPTの全ての機能を利用することができ、独自の対話システムを作成することができます。
APIはOpenAIの提供するAPIを活用する方法と、Microsoft Azure OpenAI Serviceを利用する方法が一般的です。
OpenAIのAPIを直接利用する場合、「Tier(ティア)」と呼ばれる利用制限の仕組みに注意が必要です。Tierは支払い実績やアカウントの運用期間に応じて段階的に昇格し、上位のTierほど1分間あたりのリクエスト数や処理トークン量の上限が緩和されます。
一方で、Azure OpenAI Serviceの場合は、Tier制ではなく申請ベースのクォータ(割当)管理や、予測可能なパフォーマンスを確保できる専用の「プロビジョニング」といった選択肢も用意されています。
APIを利用するには、専門的な知識が必要となります。また、APIを使用する場合は、適切なセキュリティ対策が必要です。
関連記事:「Azure OpenAI Serviceとは?On Your Data・Azure ChatGPTでChatGPTを社内でセキュア活用!」
ChatGPT Enterpriseを利用する
ChatGPT Enterpriseは2023年8月28日にOpenAIによって発表され、企業が安心して利用できるように高度なセキュリティとプライバシー保護が施されています。
このプランでは、企業が所有するデータや会話はOpenAIによって学習されることはありません。無料プラン、個人向けの有料プランではオプト設定を行わない限り学習データとして送信されます。
さらに、SOC 2に準拠しており、すべての会話は暗号化されています。
ChatGPT Enterpriseでは、通常のGPT-4よりも最大2倍高速に動作します。また、文章の長さも通常の4倍まで入力可能です。このプランでは、高度なデータ分析機能も無制限に利用でき、金融研究者やマーケター、データサイエンティストなどが短時間で情報を分析できます。
ChatGPT Enterpriseには、管理用のマスターアカウントなどセキュリティ面でも多くの機能が備わっています。これにより、企業は高度なセキュリティの下で、よりスペックの高いChatGPTを安心して利用できます。
ChatGPTを会社利用する方法、注意点をこちらで詳しく説明しています。
Microsoft Copilotを使う
厳密に言えばChatGPTを使うわけではありませんが、ChatGPTライクのUI、しかも最新のGPTをMicrosoft Copilotで利用できます。
お使いのブラウザからMicrosoft Copilotの公式ウェブページにアクセスします。Microsoft Copilotの最大の特徴は、最新モデルのGPTを無料で使用できることです。
無料プランのChatGPTでは最新のGPTの利用は制限されていることや利用不可であることが多いので、少し使用開始時期のタイムラグはありますが無料で最新のGPTを使えることは大きな魅力です。Microsoft社とOpenAI社の提携関係が続く限り、Microsoft CopilotにはOpenAIの最新GPTシリーズが搭載されていく可能性が高いでしょう。
Microsoft CopilotとChatGPTの違いはこちらで詳しく解説しています。
ChatGPTと自社システムとの連携方法・進め方

企業がChatGPTを効果的に活用するためには、いくつかの前提条件と導入ステップが必要です。特に、企業がChatGPTを自社システムと連携して使うためには、APIを活用して自社のシステムやサービスとGPTを連携することが必要になります。
生成AIの導入にあたってコンサルを依頼するメリット、コンサルの選び方はこちらで特集していますので併せてご覧ください。
API連携の前提条件
| 前提条件 | 概要 |
|---|---|
| テクニカルリソース | API連携に必要なテクニカルリソースが企業内に存在することが前提 |
| データの整備 | 高度な分析や企業独自のオリジナルな文章の生成を行うためには、整備されたデータが必要です。 |
| セキュリティポリシー | ChatGPTとの連携に当たっては、企業のセキュリティポリシーに準拠する必要があります。 どのようなデータを外部に出してはいけないのか、などを事前に整理しておきましょう。 |
| 予算 | API連携を考慮する場合、開発コストに加え、APIのトランザクションコストも考慮に入れる必要があります。 |
APIを自社システムと連携する上で、GPTの性能を最大限発揮するためには、データの整理が事前に行われていることが望ましいです。また、個人情報や機密情報の取り扱いに関するポリシーが明確であることも重要です。
ニーズ分析
まず、企業内でChatGPTを活用する目的とニーズを明確にします。これにより、どのような機能が必要か、どの程度の予算がかかるかが見える化されます。
開発会社ベンダーの選定
次に、ChatGPTを使ったシステムの開発会社を選定します。信頼性と実績のあるベンダーが望ましいです。
もちろん、社内に連携を行う開発実装が可能なエンジニアの方がいらっしゃれば、エンジニアの方におまかせしても良いかもしれませんが、開発会社は、類似の開発を多く行っており、どのような箇所に気をつけなければいけないのか、などのノウハウを保有しています。
そのため、内部開発にこだわる必要がなければ、ノウハウのある外部の開発会社への依頼を検討しましょう。
プロトタイピング・PoC
小規模なプロトタイプを作成します。これにより、実際にシステムが企業のニーズに適しているかを確認するPoCを実施します。
求めている回答が返ってくるのか、精度は十分か、を適切に判断できるように、開発の前段階から目標値を設定しておくと良いでしょう。
また、実際にサービスを利用するスタッフや顧客とのコミュニケーションを通して、本当に求めている精度なのかどうかを確認することも重要です。
特にChatGPTを活用したシステムの場合は、自動で回答を生成するというLLMの特性から、間違った回答を生成していないかの検証が重要です。
デプロイメント・実装
プロトタイピング・PoCが成功したら、実際にシステムに組み込むためのデプロイメント・実装を行います。
APIを通して連携した結果を、正しく自社システムに連携できているか、オペレーションに問題はないか、も含めて確認を行いながら実装を進めていきます。
運用と最適化
デプロイメント後は、定期的なメンテナンスと最適化が必要です。
特に、ChatGPTが生成するデータや文章の品質を維持するための監査が不可欠です。求めている回答が行われない場合は、追加のデータを取り込んだり、プロンプトを見直したりして、運用が行える状態を構築していく必要があります。
関連記事:「ChatGPTを既存のシステムに組み込める?何ができる?手順・メリット・注意点を徹底解説!」
ChatGPTを企業で活用する際の注意点

ChatGPTの活用には多くのメリットがありますが、その一方で注意すべき点も存在します。企業がChatGPTを会社利用する対応事例を詳しく説明していますので併せてご覧ください。
機密情報の取り扱い
ChatGPTはAPIを通じて企業のデータベースや他のアプリケーションと連携する場合が多いです。そのため、機密情報が漏洩しないように、APIのセキュリティ設定をしっかりと行う必要があります。
また、ChatGPTの機能と限界を理解した上で使用するために、ユーザーへの適切なトレーニングが必要です。または、学習済みデータとは別に社内独自データを検索できるRAGの使用も検討できるでしょう。
関連記事:「ChatGPTの履歴はどんな時に削除すべきか?方法や注意点を徹底解説!」
データの正確性
ChatGPTが生成する文章や分析結果は、入力されたデータに依存します。不正確なデータが入力されると、それに基づいて誤った結論や提案がされる可能性があります。
事前にChatGPTに入力するデータのクレンジングや正規化を行うことで、より正確な結果を得られます。
関連記事:「ChatGPTは質問の仕方で活用成果がここまで変わる!プロンプトのコツやテンプレートを徹底解説」
倫理的な側面
ChatGPTを用いて偏見や差別的な内容が生成されないように、設定やトレーニングデータの選定には注意が必要です。ChatGPTの動作を定期的に監査し、不正確な生成やセキュリティリスクがないかを確認することが重要です。
関連記事:「技術的に可能でもChatGPTでできないことは?規約の禁止事項・スペック制限・注意点を徹底解説!」
ハルシネーション
ChatGPTを始めとするLLM(大規模言語モデル)には、ハルシネーションという問題が付きまといます。ハルシネーションとは、AIがもっともらしく嘘をつく事象であり、実際には正しくない情報も、あたかも本当の情報のように対話の中で生成してしまいます。
そのため、ChatGPT等の回答においては、ハルシネーションという問題がある、ということを理解した上で、適切に活用することが重要です。
関連記事:「ChatGPTでハルシネーションを抑制する対策は?すぐ使えるプロンプト例・最新機能を活用した対策方法を徹底解説!」
学習していない内容は正確に回答できない
ChatGPTは、学習データに含まれない最新情報や、非常に専門的・ニッチな分野の知識については誤った情報を提供することがあります。また、ユーザーの指示が曖昧な場合も、意図しない回答につながりやすいです。
そのため、ChatGPTの回答を鵜呑みにせず、特に重要な情報については必ずご自身で事実確認(ファクトチェック)を行うようにしてください。ChatGPTはあくまで補助的なツールと捉え、最終的な判断は人間が行うことが賢明な使い方と言えるでしょう。
関連記事:「ChatGPTの回答精度を上げる方法は?RAGの活用方法・プロンプト設計のコツも徹底解説!」
アカウントの使いまわしは規約違反
ChatGPTの利用規約では、アカウントを複数のユーザーで共有することは禁止されています。これにより、アカウントが停止される可能性があります。
さらに、パスワードを共有すると、セキュリティ上のリスクが増大します。パスワードが漏洩した場合、個人情報やプロジェクト設定が危険にさらされる可能性があります。
関連記事:「ChatGPTアカウント共有は可能?使いまわしのリスクや適切な導入方法を徹底解説!」
Safety evaluations hub
OpenAIが2025年5月に公開した「Safety evaluations hub」は、GPT-4.1やGPT-4oなどのAIモデルの安全性評価結果を一般公開し、透明性を高めることを目的としています。
ヘイトスピーチ回避能力、ジェイルブレイク耐性、ハルシネーション頻度と回答の正確性、指示の優先順位遵守といった4種類の評価結果が公開されており、モデル選定の際に活用できます。
ChatGPTから最適化された情報を引き出すコツ

ChatGPTは、従来のようなWeb検索の方法では、無難で当たり障りのない回答しか得られません。ChatGPT特有の情報入力手法について説明します。
明確かつ具体的な質問や指示を与える
ChatGPTの応答を最適化するには、明確かつ具体的な質問や指示を与えることが重要です。これにより、ChatGPTはより関連性の高い応答を生成することができます。
追加の情報を提供する
ChatGPTが提供する応答のコンテキストや範囲に注意を払い、必要に応じて追加の情報を提供することで、より正確な応答を得ることができます。
プロンプトエンジニアリングを活用する
プロンプトエンジニアリングと呼ばれる、生成AIが最適な回答を導き出すことが可能な手法が実現されています。
具体的には、ChatGPTに質問を投げかける際に、「友だちのように回答してください」「100文字以内で」「箇条書きで」といった形でAIにプロンプト(指示や命令)を行うことで、より活用場面ごとに求めてる回答に近いものを導き出すことができるようになっています。
関連記事:「ChatGPTのプロンプトとは?作成のコツ・例文・人気のプロンプト作成システム徹底解説!」
モデルのカスタマイズ
応答の品質を高めるために、RAGやファインチューニングのようにユーザーの特定のニーズに合わせてモデルをカスタマイズすることも可能です。
このカスタマイズは、特定の業界や用途に特化した応答を生成したり、自社のデータを参照した回答を生成するのに役立ちます。
ChatGPTについてよくある質問まとめ
- ChatGPTとは?
ChatGPT(チャットジーピーティー)は、米国OpenAI社が公開した大規模言語モデルを活用する自然言語処理のためのニューラルネットワークモデルのチャットボットです。ChatGPTは人間のようにふるまい、自然な対話からユーザーが求める文章を生成することができます。詳しくはこちらにジャンプ。
- ChatGPTでできることは?
ChatGPTでできることは以下の通りです。
- 社内業務の自動化(質問対応、業務フローの説明)
- 顧客対応の自動化(パーソナライズされたDM送信、ヘルプデスク対応など)
- コンテンツ・文章作成の効率化(提案文、メール下書きなど)
- SNS投稿のアイデア創出
- 文書の要約
- リストや表の作成
- プログラミングでのコーディング生成・補完
- 調査と情報提供
- 文章の添削と校正
- タスク管理の効率化
- データ分析と予測
- 内部コミュニケーションの翻訳
- アイデア生成のサポート
ChatGPTは、自然言語処理の高度な能力を活かし、業務効率化やコスト削減、顧客満足度の向上など、様々な場面で企業の生産性向上に貢献できる可能性を秘めています。
- ChatGPTの使い方は?
ChatGPTを活用する方法には以下があります
- ブラウザから使う
- APIを使う
- ChatGPT Enterpriseを使う
- ChatGPTのプランにはどのような違いがありますか?
ChatGPTには主に以下のプランがあります。
- 無料プラン: 個人向け。基本的な機能を利用できるが、アクセス集中時の遅延や一部機能制限あり。
- Plusプラン: 個人向け(月額20ドル)。最新モデルへの優先アクセス、安定した応答速度、自作GPT作成・利用などが可能。
- Proプラン: 個人向け(月額200ドル)。Plusプランの全機能に加え、高度な機能への無制限アクセスなどが特徴。
- Teamプラン: 小規模チーム向け(月額25ドル/人〜)。Plusプランの機能に加え、チームでのGPT共有、管理コンソール、強化されたデータ保護などが特徴。
- Enterpriseプラン: 大企業向け。高度なセキュリティ、大規模導入向け管理機能、高速アクセス、API利用などが特徴。
- ChatGPTには他の対話型AIと比べてどのような独自機能がありますか?
ChatGPTには以下のような独自性の高い機能があります。
- GPTモデルの継続的な進化: GPT-4o、oシリーズなど、高性能な独自モデルを開発・提供。
- 自作GPT機能とGPT Store: 特定の目的に合わせてカスタマイズしたGPTを作成・共有・利用できるプラットフォーム。
- Advanced Data Analysis: 自然言語で指示するだけでデータ分析やグラフ作成が可能。
- マルチモーダル対応: テキスト、画像、音声を入力・出力として統合的に扱える。
- 多様な最新機能: Deep Research(自動調査レポート)、Operator(PC操作自動化)、canvas(共同編集)、タスク機能(リマインダー)、Advanced Voice(高度な音声対話)などを順次導入。
- CriticGPT: 出力(特にコード)の誤りを検出し改善する自己評価モデル。
- ChatGPTはどのような仕組みで動いていますか?
ChatGPTの基盤技術はTransformerというニューラルネットワークアーキテクチャです。このアーキテクチャを採用したLLM(大規模言語モデル)であるGPTが、膨大なテキストデータを学習することで、文脈理解能力や文章生成能力を獲得しています。
さらに、RLHF(人間のフィードバックによる強化学習)というファインチューニングを行うことで、より人間の意図や好みに沿った、自然で社会的に受け入れられやすい応答を生成できるように調整されています。
- ChatGPTは具体的にどのようなことに活用できますか?
ChatGPTは非常に多機能であり、以下のような様々な用途に活用できます。
- 業務効率化: 社内問い合わせ対応自動化、メール・資料作成補助、議事録作成、文章要約・校正。
- コンテンツ制作: ブログ記事作成、SNS投稿文作成、広告コピー生成、アイデア出し。
- 顧客対応: FAQ作成、チャットボットによる問い合わせ対応自動化、アンケート分析。
- 開発支援: プログラミングのコード生成・補完・レビュー。
- 情報収集・分析: 特定テーマに関する調査、データ分析・可視化、市場トレンド分析。
- 教育・学習: 外国語学習支援、専門知識の解説。
- その他: 翻訳、タスク管理、マインドマップ作成補助、ペルソナ作成支援。
- ChatGPTはどのように使えばよいですか?
ChatGPTを利用するには、主に以下の方法があります。
- ブラウザ: 公式サイトにアクセスし、アカウント登録(またはログイン)して利用する最も一般的な方法です。
- スマホアプリ: iOSおよびAndroid向けの公式アプリをダウンロードして利用できます。
- API: 自社のシステムやサービスにChatGPTの機能を組み込む場合に利用します。OpenAI APIまたはAzure OpenAI Service経由で利用可能です。
- ChatGPT Enterprise: 大企業向けの専用プランで、高度なセキュリティと管理機能が提供されます。
- Microsoft Copilot: Microsoftのサービス(Edgeブラウザ、Windows、Microsoft 365など)を通じて、最新のGPTモデルを利用できます(厳密にはChatGPTそのものではない)。
- ChatGPTを自社のシステムと連携させるにはどうすればよいですか?
ChatGPTを自社システムと連携させるには、主にAPIを利用します。以下のステップで進めるのが一般的です。
- 前提条件の確認: API連携に必要な技術リソース、整備されたデータ、セキュリティポリシー、予算などを確認します。
- ニーズ分析: ChatGPTを連携させて何を実現したいのか、目的と要件を明確にします。
- 開発会社/ベンダー選定: API連携やAIシステム開発の実績がある信頼できるパートナーを選定します(社内開発リソースがない場合)。
- プロトタイピング・PoC: 小規模な試作システムを構築し、目的の機能や精度が実現可能か検証します。
- デプロイメント・実装: PoCの結果に基づき、本番システムへの連携・実装を行います。
運用と最適化: 導入後も、生成される内容の品質監査やプロンプト調整、データ更新など、継続的な運用と改善が必要です。
- ChatGPTを企業で活用する際に注意すべき点は何ですか?
企業でChatGPTを活用する際には、以下の点に注意が必要です。
- 機密情報の取り扱い: 企業の機密情報や個人情報をChatGPT(特にWeb版)に入力しないように徹底し、API利用時も適切なセキュリティ対策を講じる必要があります。社内ルールの策定と従業員教育が重要です。
- データの正確性(ハルシネーション): ChatGPTは事実に基づかない情報(ハルシネーション)を生成することがあります。生成された情報を鵜呑みにせず、必ずファクトチェックを行う必要があります。
- 倫理的な側面・著作権: 生成されたコンテンツが偏見を含んだり、著作権を侵害したりする可能性がないか注意が必要です。特に商用利用する場合は、権利関係を確認する必要があります。
- アカウントの共有禁止: 利用規約でアカウントの共有は禁止されており、セキュリティリスクもあるため、複数人で利用する場合はTeamプランなどを検討すべきです。
- 情報漏洩リスク: API連携や独自データ活用(RAGなど)を行う際は、情報が外部に漏洩しないようなセキュアな環境構築が必要です。
- ChatGPTからより良い回答を引き出すコツはありますか?
ChatGPTから望む回答を得るためには、以下のようなコツがあります。
- 明確かつ具体的な指示(プロンプト): 目的、背景、出力形式、文字数、役割(例: 「あなたはプロの編集者です」)などを具体的に指示します。
- 追加情報の提供: 必要に応じて、文脈や制約条件などの追加情報を提供します。
- プロンプトエンジニアリングの活用: 回答の質を高めるための様々なプロンプト設計手法(例: Few-shotプロンプティング、Chain-of-Thought)を活用します。
- 段階的な指示: 複雑なタスクは一度に指示せず、ステップに分けて指示を与えます。
- モデルのカスタマイズ: 特定のタスクや分野に合わせて、ファインチューニングやRAG(Retrieval-Augmented Generation)を用いてモデルをカスタマイズします(専門知識が必要)。
- カスタム指示機能の活用: ユーザーの好みや特定の指示をあらかじめ設定しておくことで、応答スタイルを調整できます。
まとめ
ChatGPTは今後の仕事の在り方を大きく変えるものとして注目されています。自社システムにChatGPTに組み込むためのAPIの使用料金もリーズナブルであり、これからますます新しいサービスがリリースされていくでしょう。
ChatGPTは普段人と話すのと同じ感じで業務を自動化することができ、知識がなくても誰でも業務の効率化が進んでいくでしょう。特に、企業が保有する独自データベース(独自ノウハウ)等を活用し、APIと連携をさせることで、企業独自のChatGPTサービスの活用は今後も増えていくことが想定されます。
ChatGPTを活用したサービスは、まだ開発が始まったばかりです。どのようなサービスが開発され社会を変えていくのか、今後の展開が楽しみです。
ChatGPTの導入支援/活用支援や、自社ビジネス向けのカスタマイズ開発を行ってくれる会社をお探しの場合は、こちらのChatGPTの導入支援、カスタマイズ開発に強いおすすめ会社紹介記事もぜひご参考ください。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

