
Inception Labs社、世界初の商用拡散大規模言語モデル(dLLM)「Mercury Coder」を発表。従来のLLMより最大10倍高速な処理を実現
最終更新日:2026年02月19日
記事監修者:AI Market ニュース配信チーム
Inception Labs社は2025年2月27日、従来の自己回帰型LLMとは異なるアプローチで開発された拡散大規模言語モデル(dLLM)であるMercury Coderを発表した。
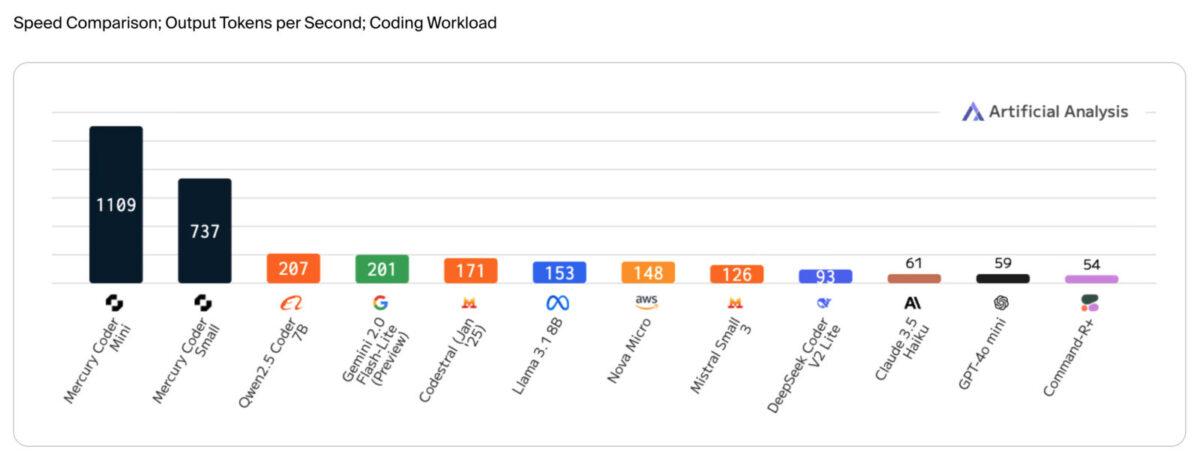
同社のdLLMは従来のLLM比で最大10倍の高速化と低コスト化を実現し、NVIDIA H100上で1000トークン/秒以上の処理速度を達成するという。
- 従来の自己回帰型LLMと異なる「粗から細へ」のアプローチで並列処理を実現し、最大10倍の高速化を達成した拡散言語モデル
- コード生成に特化したモデル「Mercury Coder」は1000トークン/秒以上の処理速度を実現しながら、GPT-4o MiniやClaude 3.5 Haikuを上回る性能
- API提供とオンプレミス導入に対応し、既存のハードウェア、データセット、監視付き微調整(SFT)、アライメント(RLHF)パイプラインと完全互換
従来のLLM(大規模言語モデル)は自己回帰型であり、テキストを左から右へ一度に1トークンずつ生成するため、本質的に逐次処理となる。
これに対し、Inception Labs社が開発したディフュージョンモデルは「粗から細へ」の生成プロセスを採用しており、出力を純粋なノイズから数回の「ノイズ除去」ステップで洗練していく。このアプローチにより、従来モデルの制約を超えた推論能力と応答構造化、そして誤りや幻覚の修正が可能になった。
Inception Labs社が最初に公開するdLLMである「Mercury Coder」はコード生成に特化したモデルだ。標準的なコーディングベンチマークでの評価では、GPT-4o MiniやClaude 3.5 Haikuなどの速度最適化された自己回帰型モデルのパフォーマンスを上回りながら、最大10倍の高速化を実現している。
特筆すべきは処理速度で、速度最適化された自己回帰型モデルが最大でも200トークン/秒程度の処理速度である一方、Mercury Coderは一般的なNVIDIA H100上で1000トークン/秒以上の処理速度を達成している。これは一部のフロンティアモデルと比較すると20倍以上の高速化だ。
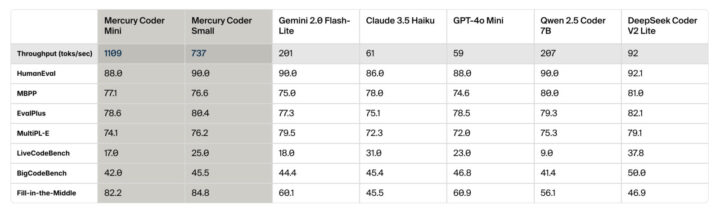
また、Mercury Coderは開発者の評価も高い。Copilot Arenaでのベンチマークでは、Mercury Coder MiniはGPT-4o MiniやGemini-1.5-Flash、さらには大型モデルのGPT-4oをも上回り、第2位タイを獲得している。
同時に、GPT-4o Miniの約4倍の速度を持つ最速のモデルでもある。Inception Labs社のdLLMは既存の自己回帰型ベースモデルの代替として利用可能で、RAG、ツール使用、エージェントワークフローなどすべてのユースケースをサポートする。
同社は、APIとオンプレミス導入を通じてモデルへのアクセスを提供しており、既存のハードウェア、データセット、監視付き微調整(SFT)およびアライメント(RLHF)パイプラインと完全に互換性がある。
AI Marketの見解
Inception Labs社のディフュージョン型LLMの登場は、生成AIの処理速度と効率性における重要な技術的転換点となる可能性が高い。
従来、ディフュージョンモデルは画像・動画・音声生成で主流だったが、テキストや特にコードへの応用は難しいとされてきた。
この障壁を突破したInception Labs社の技術は、特に低レイテンシーが求められる実用的なAIアプリケーション、例えばリアルタイムの顧客サポートやコード補完において大きな価値をもたらすだろう。
既存モデルとの互換性を維持しながら処理速度を大幅に向上させる手法は、専用ハードウェアへの依存度を下げ、AIの民主化を促進すると共に、より高度な推論能力とエラー修正機能を持つAIシステムの実現に寄与するだろう。
参照元:inceptionlabs
Mercury Coderについてよくある質問まとめ
- 拡散大規模言語モデル(dLLM)と従来のLLM違いは?
従来のLLMはテキストを左から右へ1トークンずつ順番に生成するのに対し、拡散大規模言語モデル(dLLM)は「粗から細へ」のアプローチで複数トークンを並列処理します。
この方式により、Inception Labs社のdLLMは最大10倍の高速化(1000トークン/秒以上)を実現し、出力全体を継続的に洗練できるため誤りや幻覚の修正能力も高まります。
また、従来ディフュージョンモデルは画像・動画・音声生成で主流でしたが、Inception Labs社によってテキスト・コード生成への応用が初めて実用化されました。
- Mercury Coderはどのような用途で特に効果を発揮しますか?
Mercury Coderは高速な処理速度と高品質な出力により、リアルタイムコード補完、大規模コードベースの分析・生成、レイテンシーに敏感なアプリケーション開発で特に効果を発揮します。
従来は処理速度の制約から小型の低性能モデルしか使えなかった環境でも高性能モデルを導入できるようになり、同じハードウェアでより多くのリクエストを処理できるため運用コストも削減できます。
標準的なコーディングベンチマークでは、GPT-4o MiniやClaude 3.5 Haikuを上回る性能を示しています。

AI Market ニュース配信チームでは、AI Market がピックアップするAIや生成AIに関する業務提携、新技術発表など、編集部厳選のニュースコンテンツを配信しています。AIに関する最新の情報を収集したい方は、ぜひ𝕏(旧:Twitter)やYoutubeなど、他SNSアカウントもフォローしてください!
𝕏:@AIMarket_jp
Youtube:@aimarket_channel
TikTok:@aimarket_jp
過去のニュース一覧:ニュース一覧
ニュース記事について:ニュース記事制作方針
運営会社:BizTech株式会社
ニュース掲載に関するご意見・ご相談はこちら:ai-market-press@biz-t.jp

