
OpenAIが次世代音声モデルをAPI経由で提供開始
最終更新日:2025年03月21日

OpenAIは2025年3月20日(現地時間)、新たな音声処理モデル群をAPI経由で世界中の開発者に提供開始した。
これまでのテキストベースのエージェント技術への投資に加え、より直感的で自然な音声インタラクションを実現する高精度な音声認識(Speech-to-Text)モデルと、指示により話し方を調整できる音声合成(Text-to-Speech)モデルを導入することで、より強力でカスタマイズ可能なインテリジェントな音声エージェントの構築を可能にしている。
- 最新のGPT-4oアーキテクチャを基盤とした高精度音声認識モデルが既存のWhisperモデルより優れたWER(単語エラー率)を実現し、アクセントやノイズ環境でも正確に認識
- テキスト音声変換モデルに「共感的なカスタマーサービスエージェントのように話す」などの指示による調整機能を初めて搭載し、用途に合わせた表現力豊かな音声を実現
- 本格的な音声ユーザーインターフェース構築に必要な技術を提供し、コールセンター、会議記録、ストーリーテリングなど幅広い応用分野でのボイスエージェント開発を促進
OpenAIが新たに発表した音声認識モデル「gpt-4o-transcribe」と「gpt-4o-mini-transcribe」は、既存のWhisperモデルと比較して単語エラー率(WER)を大幅に改善している。これらのモデルは強化学習技術と高品質な音声データセットの中間学習を通じて開発され、特にアクセント、騒音環境、異なる話速などの困難なシナリオにおける音声の細かなニュアンスをより正確に捉え、誤認識を減少させる能力を持つ。
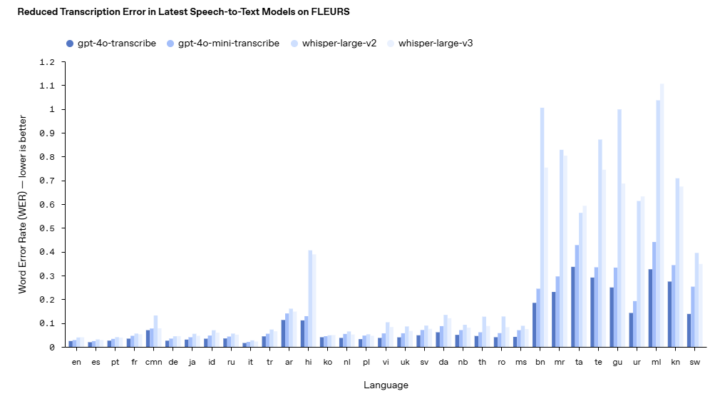
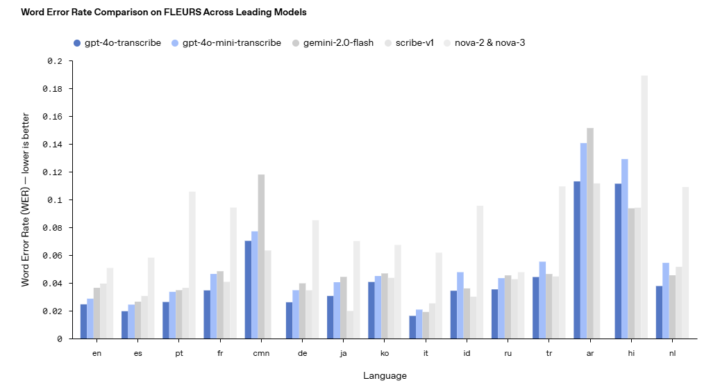
FLEURS(Few-shot Learning Evaluation of Universal Representations of Speech)などの確立されたベンチマークにおいて、これらの新モデルはWhisper v2やWhisper v3を含む既存のモデルを一貫して上回る性能を示しており、Gemini-2.0-flashやscribe-v1、nova-2 & nova-3などの他の主要なモデルと比較しても、ほとんどの主要言語でより低いWERを達成している。これにより、カスタマーコールセンターや会議ノートの文字起こしなどのユースケースに特に適したより信頼性の高い文字起こしが可能となっている。
また、新しいテキスト音声変換モデル「gpt-4o-mini-tts」も発表された。このモデルの最も注目すべき点は、開発者が初めて「何を言うか」だけでなく「どのように言うか」についても指示できる新機能だ。
例えば「共感的なカスタマーサービスエージェントのように話す」といった指示を与えることで、カスタマーサービスからクリエイティブなストーリーテリングまで、さまざまなユースケースに合わせたよりカスタマイズされた体験を提供することが可能になった。
OpenAIはこれらの技術的進歩の背後にある革新として、本物の音声データセットによる事前学習、先進的な蒸留手法、そして強化学習パラダイムを挙げている。GPT-4oとGPT-4o-miniのアーキテクチャを基盤とし、音声中心の専用データセットで広範囲に事前学習することで、音声のニュアンスへの深い洞察と音声関連タスクでの優れたパフォーマンスを実現している。
新しい音声モデルは現在、すべての開発者がAPIを通じて利用可能だ。既にテキストベースのモデルを使って会話体験を構築している開発者にとって、これらの音声認識および音声合成モデルを追加することは、ボイスエージェントを構築する最もシンプルな方法となる。OpenAIはこの開発プロセスを簡素化するためにAgents SDKとの統合も発表している。
また、低遅延の音声対音声体験を構築したい開発者には、Realtime APIの音声対音声モデルを利用することを推奨している。OpenAIは今後、音声モデルのインテリジェンスと精度の向上に継続的に投資し、安全基準に沿った方法で開発者が独自のカスタム音声を持ち込んでさらにパーソナライズされた体験を構築できる方法を模索する計画だ。
また、合成音声がもたらす課題と機会についての政策立案者、研究者、開発者、クリエイターとの対話も継続している。さらに、開発者がマルチモーダルなエージェント体験を構築できるよう、ビデオを含む他のモダリティにも投資していく方針だ。
AI Market の見解
OpenAIの次世代音声モデルのリリースは、音声インターフェース市場に重要な進展をもたらす技術だ。特に注目すべきは、GPT-4oアーキテクチャをベースにした音声特化モデルの開発アプローチで、音声認識精度の向上と音声合成の柔軟な調整機能の両立を実現している点にある。
技術的には、強化学習を重視したパラダイムと高品質データセットの活用が単語エラー率の低減につながり、特に多言語対応の強化は国際的なアプリケーション開発に大きな価値をもたらすと想定される。
ビジネス面では、コールセンターや医療文書化など、正確な音声理解が求められる産業でのAI活用を加速させる効果があり、表現力のあるテキスト音声変換モデルはパーソナライズされたユーザー体験の創出に貢献すると考えられる。
これらのAPIの提供は、開発者のボイスエージェント構築の敷居を下げ、より自然で直感的なAIインタラクションが多くのサービスに組み込まれる流れを強化すると想定される。
参照元:OpenAI
次世代音声モデルに関するよくある質問まとめ
- OpenAIの新しい音声認識モデルは既存のWhisperモデルと比べてどのような改善がありますか?
新しい「gpt-4o-transcribe」と「gpt-4o-mini-transcribe」モデルは、単語エラー率(WER)が大幅に改善されています。特にアクセント、騒音環境、異なる話速などの困難な状況での認識精度が向上しました。FLEURSなどの確立されたベンチマークでは、Whisper v2やWhisper v3を一貫して上回る性能を示しており、多言語対応も強化されています。これらの改善は、強化学習技術と高品質な音声データセットの中間学習によって実現されており、カスタマーコールセンターや会議記録などの実用的なシナリオでより信頼性の高い文字起こしが可能となっています。
- 新しいテキスト音声変換モデルの「指示による調整機能」とは具体的にどのようなものですか?新しいテキスト音声変換モデルの「指示による調整機能」とは具体的にどのようなものですか?
新しい「gpt-4o-mini-tts」モデルでは、開発者が「何を言うか」だけでなく「どのように言うか」についても指示できる機能が初めて導入されました。例えば「共感的なカスタマーサービスエージェントのように話す」といった指示を与えることで、音声の話し方や感情表現をカスタマイズできます。これにより、より親しみやすいカスタマーサービス音声や、物語のナレーション向けの表現力豊かな音声など、用途に特化したボイスエージェントの構築が可能になります。ただし、現在のモデルは人工的なプリセット音声に限定されており、OpenAIはこれらが常に合成的なプリセットと一致するよう監視しています。

AI Market ニュース配信チームでは、AI Market がピックアップするAIや生成AIに関する業務提携、新技術発表など、編集部厳選のニュースコンテンツを配信しています。AIに関する最新の情報を収集したい方は、ぜひ𝕏(旧:Twitter)やYoutubeなど、他SNSアカウントもフォローしてください!
𝕏:@AIMarket_jp
Youtube:@aimarket_channel
TikTok:@aimarket_jp
過去のニュース一覧:ニュース一覧
ニュース記事について:ニュース記事制作方針
運営会社:BizTech株式会社
ニュース掲載に関するご意見・ご相談はこちら:ai-market-press@biz-t.jp

