
Cohere Command A Visionとは?特徴や主な画像解析機能、性能、実画面での使い方、注意点まで徹底解説!
最終更新日:2025年08月21日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- Command A VisionはCohereが2025年7月に公開した視覚特化型AIで、スライド・図表・PDF・写真などから構造化データを自動抽出。
- ChartQA・DocVQA・OCRBenchなど9種の視覚ベンチマークでGPT-4.1やLlama 4を上回る性能。
- 無料トライアル・研究利用・企業向け契約の3形態で提供され、画像アップロードはCohere PlaygroundやHugging Faceから可能。
2025年7月、Cohere社はテキストと画像を同時に理解し、分析するマルチモーダルLLM「Command A Vision」を発表しました。スライド・図表・PDF・写真など、企業が日常的に扱う多様な視覚資料をAIが理解・解析し、構造化データの抽出や業務自動化を支援するAIモデルです。
本記事では、Command A Visionの特徴、主な機能、性能、料金プラン、使い方、導入時の注意点まで徹底的に解説します。文書・画像を横断して業務効率化を進めたい企業担当者や技術者の方にとって、実践的な内容となっています。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
LLMに強いAI開発会社をご自分で選びたい場合はこちらで特集していますので併せてご覧ください。
目次
Command A Visionとは?

Command A Visionは、Cohereが2025年7月に発表した視覚情報に特化したマルチモーダルLLM(MLLM)です。マルチモーダルAIとは、テキスト、画像、音声など、複数の異なる種類の情報(モダリティ)を同時に処理できるAIのことを指します。
スライド、図表、写真、PDF、スキャン文書など、企業内で日常的に扱われる多種多様な画像・文書データを解析し、業務の効率化や作業自動化を支援することを目的としています。
このモデルは、従来のCommand Aが持つ高精度なテキスト処理能力をベースに構築されており、そこに画像や視覚情報を理解・活用するための機能が統合されています。
つまり、文章だけでなく、文書のレイアウト構造、図やグラフの意味、写真の背景や空間関係までをAIが理解し、実務に役立つ形でデータ化することが可能です。
Command A Visionの料金プラン
トライアルではCommand A Visionを無料で研究用で試すことができます。エンタープライズ用途では、オンプレミスやカスタムモデルもサポートされており、個別契約によって導入が可能です。
| プラン種別 | 料金 | 概要 |
|---|---|---|
| Cohere Playground | 無料(制限あり) | 試用・評価用途向け。商用不可。 |
| 研究利用 | 無料 | Hugging Face経由で利用可能。非商用の研究目的に限る。 |
| エンタープライズ契約 | 個別見積もり | オンプレミス導入やカスタムモデル対応。個別契約。 |
随時変更の可能性がありますので、最新の情報は公式サイトをご参照ください。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
Command A Visionの特徴、主な機能
Command A Visionの特徴、主な機能は以下の通りです。
- 図表・チャート・図面の高度な理解
- 文書構造の理解と情報抽出
- 企業向け視覚資料の処理に最適化
- 画像からの状況把握・リスク分析
- 導入しやすい軽量なシステム設計
- Command Aシリーズのストロングポイントを引き継ぐ
図表・チャート・図面の高度な理解
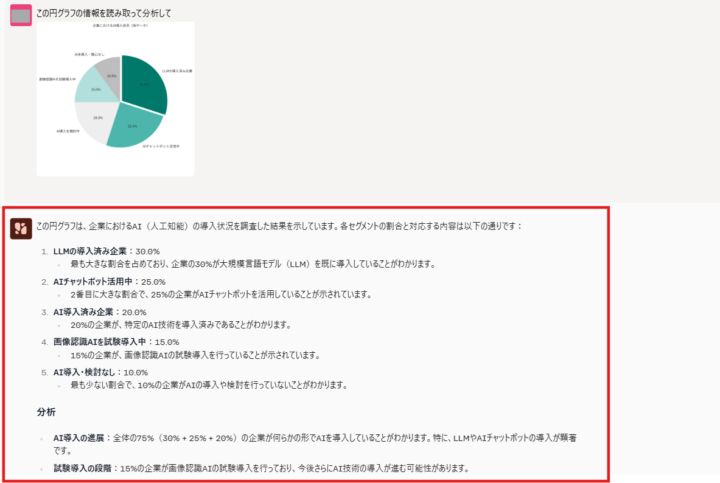
Command A Visionは、プレゼン資料に使われるスライド画像から図表・見出し・本文などを正確に解析し、意味のある構造として情報を抽出することができます。上記の画像は、Command A Visionが円グラフを読み取り、各項目の内容と割合を正確に抽出・整理した結果を示しています。
Command A Visionは、チャートやグラフ、表、構造図など、複雑な視覚資料に含まれる情報を正確に読み取ります。
数値や構成データの抽出にとどまらず、業界特有の文脈を踏まえた分析も可能で、財務資料や設計図、技術文書といった専門的な資料にも対応しています。
タイトル・箇条書き・凡例・グラフ軸ラベルなど、視覚的な区切りやレイアウト構造を理解したうえで処理を行うため、内容をそのままテキストやJSON形式に整形することが可能です。
ビジネス文書の読解とデータ抽出(OCR)において、GPTGPT-4.1やLlama 4 Maverickといった競合モデルを上回るベンチマークスコアを記録しています。単に文字を読み取るだけでなく、表の構造やレイアウトを理解し、意味のある情報として抽出できるのが強みです。
こうした視覚情報を実務で使える形式に変換することで、資料作成や意思決定の質を高めることができます。
文書構造の理解と情報抽出
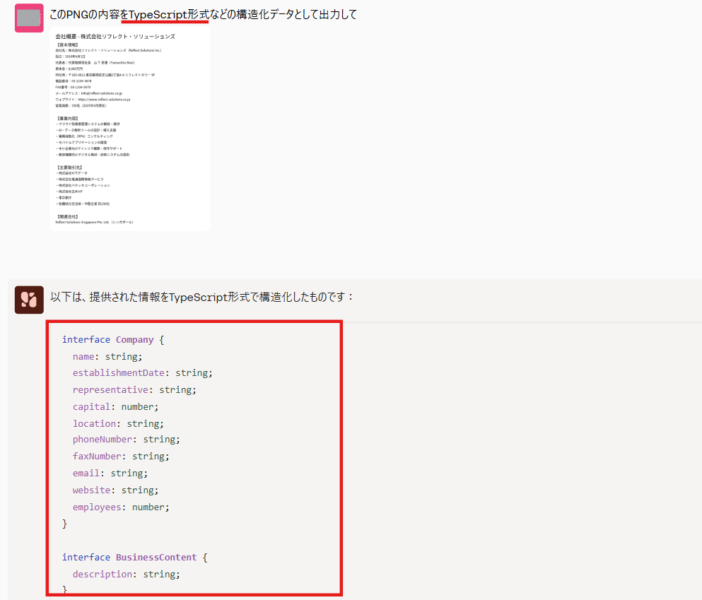
上記は、サンプル企業の概要についてPNG画像をCommand A Visionが解析し、TypeScript形式の構造化データとして出力できたことを示した画像です。社名や所在地、事業内容などを正しく読み取り、プログラムで扱いやすい形式に変換する処理を自動で行っています。
契約書や請求書、各種フォームに対しては、文字情報だけでなく文書のレイアウトや構造全体を理解した上で、必要な情報を正確に抽出します。
日付や金額、担当者名、住所などのフィールドを自動で検出し、TypeScript形式などの構造化データとして出力することが可能です。
これにより、帳票作成や請求書処理といった定型業務の効率化が図れ、業務システムとの連携もスムーズに行えます。
画像からの状況把握・リスク分析

上記は、トンネル工事中の現場写真をCommand A Visionが解析し、リスク検知や進捗状況の把握に関する情報を自動で抽出・整理した様子を示した画像です。構造物の安全性や作業員の装備、工事の進行具合などを判断し、文章として出力しています。
現場写真や監視画像をもとに、設備や人物の配置、異常な状態、危険兆候などを認識します。建設・小売・物流などの現場オペレーションにおいて、目視確認の自動化や安全管理の高度化を実現します。
多言語能力
英語、スペイン語、フランス語、ドイツ語、イタリア語、日本語など、世界中の主要な言語に対応しています。英語や日本語を含むマルチリンガルのスライドや、装飾の多い複雑なレイアウトにも対応しており、従来のOCRや単純な画像解析では難しかったタスクにも柔軟に対応できます。
これにより、海外拠点とのやり取りや、多言語でのドキュメント処理もスムーズに行えます。
導入しやすい軽量なシステム設計
Command A Visionは、エンタープライズ環境での活用を前提に、GPU2基以下(例:A100×2台またはH100×1台)でも運用できる軽量設計です。1120億という巨大なパラメータ数を持ちながら、4-bit量子化により比較的低リソースでの動作が可能です。
A100を2枚、またはH100を1枚用いた構成で運用可能です。そのため、セキュリティ要件が厳しい環境でも、自社のサーバー(オンプレミス)やプライベートクラウドへの導入ハードルが大幅に下がります。
機密性の高い情報を外部に出すことなく安全にAIを活用したいという企業のニーズに応えます。
Command Aシリーズのストロングポイントを引き継ぐ
Command A Visionには、Command Aシリーズ共通のRAG(検索拡張生成)や多言語対応機能が統合されており、日本語を含む主要言語での自然な応答生成が可能です。
ベースとなっている「Command A」モデルは、RAG技術に最適化されています。これは、回答を生成する際に、企業の社内データベースやマニュアルといった信頼できる情報源を参照する技術です。
これにより、AIがもっともらしい嘘をつくハルシネーションを抑制し、事実に基づいた正確な回答を生成します。
Command A Visionは、グラフや図表の読み取りだけでなく、文書構造の把握や写真の状況分析まで対応し、視覚とテキストの両面から業務情報を一元的に処理できる統合型AIとして機能します。
Command A Visionの並外れたビジョン性能
Command A Visionは、企業向けの視覚情報処理タスクにおいて、現時点(2025年8月)で最先端の性能を誇るAIモデルです。
ビジョン系タスク平均正解率
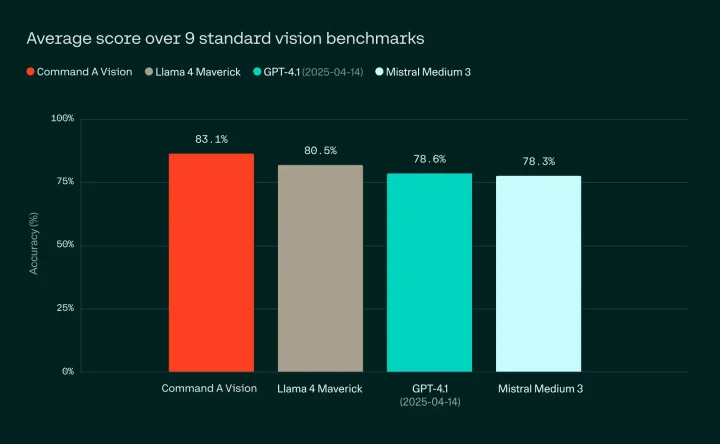
ベンチマーク比較では、ChartQAやDocVQA、OCRBenchなど、上記で示す9種類の標準的なビジョンタスクにおける平均正解率で83.1%を記録しており、Llama 4 Maverick(80.5%)、GPT-4.1(78.6%)、Mistral Medium 3(78.3%)などの主要モデルを上回る結果を残しています。
個別ビジョンタスク比較
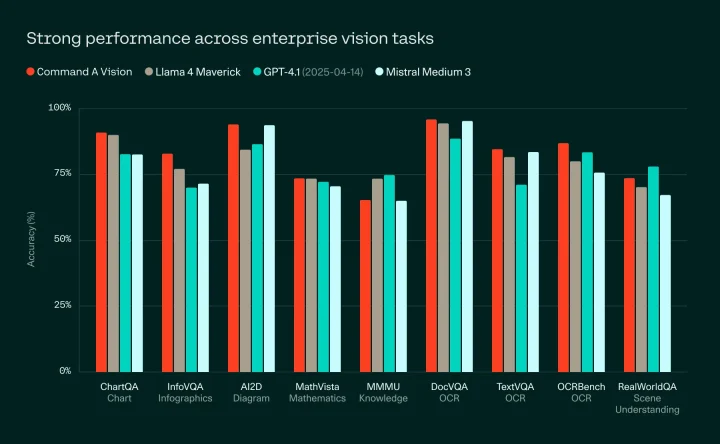
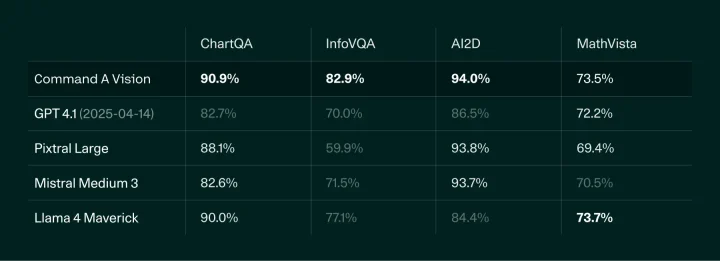
高いスコアは単なる平均値にとどまらず、上記画像のように個別のタスクでも裏付けられています。
以下は、ChartQA(グラフ内容の読解)、InfoVQA(図表の理解)、AI2D(図式推論)、MathVista(数理図式問題)といった視覚推論タスクにおけるモデルの正答率を比較した画像です。
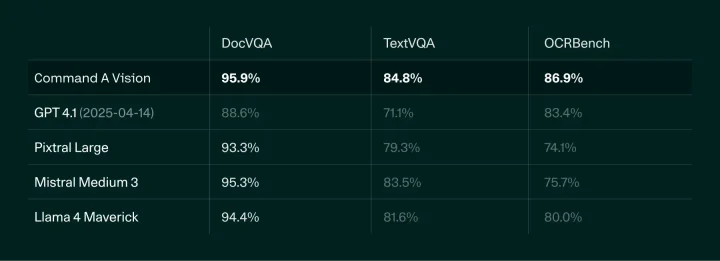
以下のDocVQA(文書内の情報抽出)、TextVQA(画像内テキストの理解)、OCRBench(文字認識精度)に関する比較でも最も高い正答率を記録しており、業務書類やOCR処理における精度の高さが証明されています。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
Command A Visionを使う方法
Command A Visionを研究目的で利用するには以下の方法があります。
- Cohere プラットフォーム(Cohere Playground)から試す方法
- Hugging Faceから試す方法
Cohere プラットフォーム(Cohere Playground)から試す方法
最も簡単に始められる方法としては、Cohere自身がホストしているプラットフォーム(Cohere Playground)で、サインアップしてAPIキーを取得する方法です。
- Cohere プラットフォームにアクセスし、アカウント登録を行います。
- 登録後、「Go to Playground」をクリックし、チャット画面へ遷移します。
- チャット画面(Cohere Playground)で右側の「Model」を選択することで、Command A Visionを試すことができます。
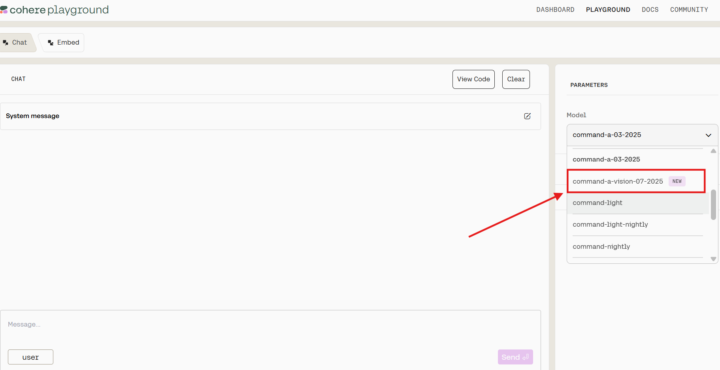
- Command A Visionでは、Cohere Playground上でPNGまたはJPG形式の画像ファイルをアップロードして解析できます。
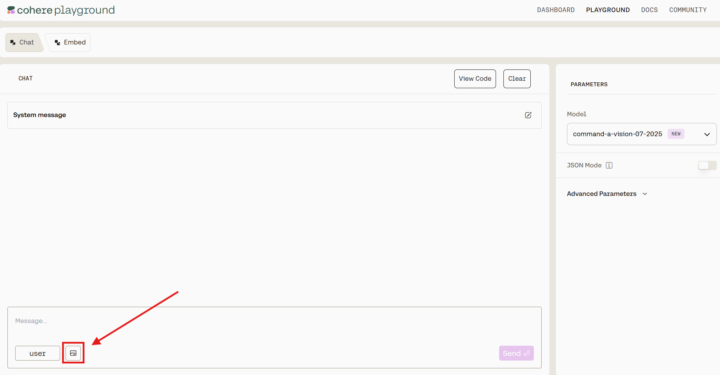
なお、今回使用したCohere Playgroundでは、アップロード可能なファイル形式がPNGおよびJPGに限定されており、PDFファイルのアップロードには対応していませんでした。
Hugging Faceから試す方法
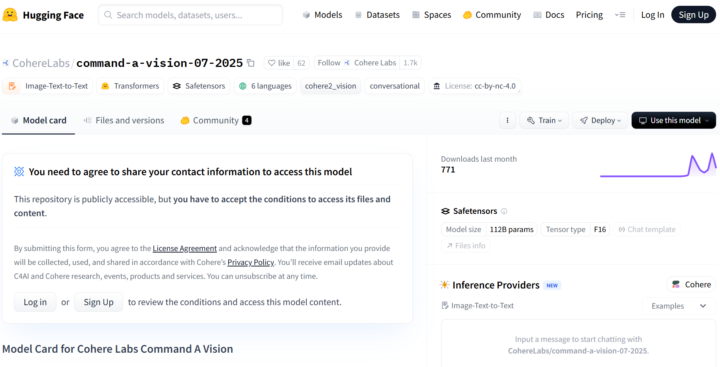
Command A Visionは、Hugging Face経由でも試すことが可能です。
- Hugging FaceのCommand A Visionページにアクセスします。
- 利用規約(非商用ライセンス)が表示されるので、内容を確認して同意します。
- デモ画面(PlaygroundまたはSpace)で、画像をアップロードし、テキストを入力してAIとの対話を始められます。
Command A Visionに関するよくある質問まとめ
- Command A VisionとはどんなAIですか?
Cohereが開発した、視覚情報に特化したマルチモーダルAIです。主な特徴は以下の通りです。
- 対象: スライド、図表、PDF、写真など、企業が扱う多様な画像・文書データ。
- 能力: テキスト情報だけでなく、レイアウト構造やグラフの意味、写真の状況までを理解・解析。
- 基盤: 高精度なテキスト処理能力を持つ「Command A」モデルがベース。
- 目的: 業務の効率化と自動化を支援する。
- Command A Visionの主な特徴や機能は何ですか?
Command A Visionは、ビジネス文書の処理に特化した多彩な機能を備えています。
- 図表・チャートの高度な理解: プレゼン資料の円グラフなどを正確に解析し、構造化データとして抽出。
- 文書構造の理解: 契約書や請求書のレイアウトを認識し、必要な情報をTypeScript形式などで出力。
- 画像からの状況把握: 建設現場の写真などからリスクや進捗状況を自動で分析。
- 軽量なシステム設計: GPU2基以下で動作可能で、オンプレミス導入のハードルが低い。
- 高機能の継承: Command Aシリーズの強みであるRAG(検索拡張生成)や多言語対応機能も搭載。
- Command A Visionの性能はどのくらいですか?
企業向けの視覚情報処理タスクにおいて、最先端の性能を誇ります。
- 総合性能: 9種類の標準的なビジョンタスクの平均正解率で83.1%を記録し、Llama 4 Maverick(80.5%)やGPT-4.1(78.6%)を上回ります。
- 個別タスク: グラフ読解(ChartQA)、文書情報抽出(DocVQA)、文字認識精度(OCRBench)など、個別の専門タスクでも主要モデルより高い正答率を記録しています。
- Command A Visionはどうやって使えますか?
目的に応じて、主に2つの方法で利用を開始できます。
Cohere Playground:
- Cohere公式サイトでアカウントを登録。
- Playground画面で「Model」からCommand A Visionを選択。
- PNGまたはJPG形式の画像をアップロードして解析を試す。
Hugging Face:
- Hugging FaceのCommand A Visionページにアクセス。
- 非商用の利用規約に同意。
- デモ画面で画像をアップロードし、対話形式で試す。
まとめ
Command A Visionは、画像やPDF、スライド、図表などの視覚情報を高精度で解析できるAIモデルです。
DocVQA・TextVQA・OCRBenchといった主要ベンチマークで高い正答率を示し、構造化データ出力や多言語対応、オンプレミス運用など、実務での柔軟な活用を可能にします。
導入前にはセキュリティ管理や認識精度の確認、ライセンス条件の把握が重要ですが、適切に運用すれば業務の効率化と自動化に大きく貢献します。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

