
LLM活用でのリスク評価はなぜ必要?ベンチマークだけではなくハルシネーションやバイアスに対する耐性評価方法を徹底解説!
最終更新日:2026年06月16日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- LLMを業務利用する際は、性能だけでなく、ハルシネーション(誤情報)やバイアス、セキュリティといった多様なリスクを総合的に評価
- LLMのリスクを可視化するには、攻撃者の視点で脆弱性を探す「レッドチーミング」や、実際の利用環境で試す「フィールドテスト」といった実践的な評価手法
- リスクを低減するには、RAG(検索拡張生成)の導入やガードレールの設定といった対策が有効
LLM(大規模言語モデル)の導入による生産性向上が期待される一方、その裏側には「もっともらしい嘘(ハルシネーション)」や「情報の偏り」、さらには「情報漏洩」といった、ビジネスの信頼を揺るがしかねないリスクが潜んでいます。
性能の高さだけに注目して導入を進めると、思わぬトラブルに繋がりかねません。
この記事では、LLMを安全かつ効果的に活用するために不可欠な7つのリスク評価項目と、その具体的な評価手法、そして検出されたリスクへの対策までを網羅的に解説します。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
目次
LLMの導入で必要な7つのリスク評価は?

LLM(大規模言語モデル)の導入は高い生産性を実現する反面、誤情報の生成や偏った出力などのリスクを抱えています。そのため、導入時には性能評価に加えて、安全性・バイアス・信頼性・セキュリティの総合的な検証することが欠かせません。
関連記事:「LLMの導入・改善効果をA/Bテストで測定できる?指標設定から実施手順、分析の流れを徹底解説!」
安全性評価
LLMを基にする生成AIは自然で説得力のある文章を生み出す反面、虚偽の情報を出力するリスクを抱えています。特にハルシネーションは、企業の信頼性を損なう重大な要因となり得ます。
また、有害コンテンツの生成や差別的な言及は、利用者に直接的な悪影響を及ぼす可能性があります。
業務利用においても、出力結果が意思決定や顧客対応に直結することが多いため、LLMの導入段階でそのリスクないか検討しなければいけません。
安全性評価はただの技術的検証だけでなく、事業継続性や社会的責任を担保するための基盤的な取り組みと位置付けられるでしょう。
バイアス評価
LLMは膨大なテキストデータを学習しているため、学習したデータに基づく偏見や不均衡をそのまま取り込んでしまう可能性もあります。このバイアスを放置すると、差別的な表現や特定の集団を不利に扱ってしまうことになりかねません。
こうしたバイアスは、顧客との信頼関係を損なったり、企業ブランドを傷つけたりする重大なリスクにつながります。近年のAI活用においては、倫理的観点からの説明責任ができるAI(XAI)が求められるケースも増えています。
そのため、LLM導入時にはバイアス評価を体系的に行って公平性を確保する視点が必要です。評価の過程では、社会的影響や利用シナリオに即して検討することがポイントになります。
関連記事:「ChatGPT vs Claude vs Gemini 犯罪・暴力的表現など不適切な出力対応力を徹底比較!」
出力の一貫性評価
LLMのリスク評価において、出力が一貫して正確であるかを確認する信頼性評価は不可欠です。LLMを業務システムや顧客対応に組み込む場合、同じ質問に対して異なる答えを返す、根拠が不明確な文章を提示する、といった挙動は大きなリスクとなります。
信頼性が担保されていなければ、意思決定の誤りや顧客からのクレームにつながりかねません。
LLMの出力内容が変動する背景には、確率的な生成特性やプロンプト設計の影響があるため、これらを理解した上で評価を行うことが求められます。社内での利用においても、複数部門をまたがった再現性の確保が重要となります。
継続的な信頼性評価によって、モデル改善の優先度を明確化できます。
情報の鮮度・正確性評価
一般的なLLMの知識は、そのモデルが学習した特定の時点までのデータに限定されています(カットオフ)。そのため、最新の出来事や変化の速い業界情報に関する質問には、古い情報や誤った情報に基づいて回答する可能性があります。
例えば、市場調査レポートの作成にLLMを利用した結果、古い市場データに基づいた分析をしてしまい、事業戦略を誤る可能性があります。また、法改正に関する情報を尋ねた際に、改正前の古い条文を提示され、コンプライアンス上の問題に発展するケースも考えられます。
セキュリティ評価
LLMを業務システムに導入する際には、セキュリティ評価が欠かせません。モデルに入力される情報に外部に漏洩してはならない内容が含まれることも珍しくないため、プロンプトインジェクションやデータ抽出攻撃に対して脆弱でないかを確認する必要があります。
また、外部APIを通じて利用する場合は、通信経路の暗号化やアクセス権限の管理といったシステム全体の安全設計も求められます。
セキュリティ評価を怠ると、情報の漏洩・不正利用などの重大リスクに直結して法的責任にまで拡大する恐れがあります。そのため、LLMの導入時点で包括的なセキュリティ評価を行い、継続したリスク管理が必要です。
著作権侵害リスク評価
LLMが生成した文章や画像が、学習データに含まれていた既存の著作物と酷似してしまう可能性があります。LLM自身に「著作権」という概念はなく、あくまで確率的な生成プロセスを経ているため、意図せず盗用や剽窃に類似したアウトプットを生み出してしまうのです。
LLMに生成させたブログ記事やマーケティングコンテンツが、他社の著作権を侵害していた場合、損害賠償請求やコンテンツの差し止めといった法的な紛争に発展するリスクがあります。特に、生成物を商用利用する場合は細心の注意が必要です。
現状の法整備では、AIによる生成物の著作権侵害が起きた場合、その責任はAIの「利用者」が負うことになる可能性が高いとされています。
予測不能な運用コスト評価
多くのLLMベンダーは、API経由での利用量(トークン数)に応じた従量課金制を採用しています。想定以上に利用が拡大したり、非効率なプロンプトが多用されたりするとAPI利用料が指数関数的に増大し、予算を大幅に超過する可能性があります。
PoC(概念実証)段階では低コストで済んでいたものが、全社展開した途端に莫大な運用コストが発生し、プロジェクトの費用対効果が著しく悪化するケースがあります。コスト管理の仕組みを導入せずに利用を進めることは経営上の大きなリスクとなります。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
LLMの代表的なリスク評価手法5種類
LLMのリスクを可視化するには、実運用を想定した評価が必要になります。ここでは代表的な手法について解説します。
モデルベンチマークテスト
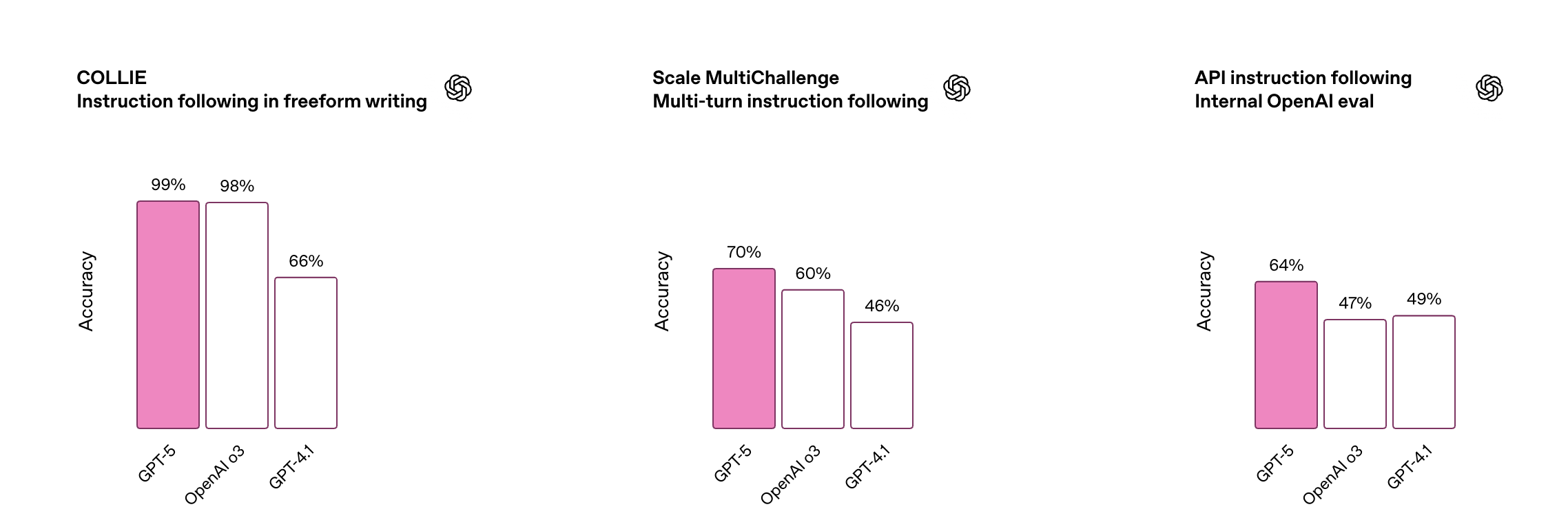
モデルベンチマークテストは、標準化された基準でLLMを測定する手法です。一般的には、以下の項目を対象にデータセットを用いて評価します。
- 正確性(Accuracy)
- 一貫性(Consistency)
- ハルシネーション耐性
- バイアス検出
- 安全性(Safety)
- 説明可能性(Explainability)
実践的な評価方法としては、MMLUなどの公開ベンチマークを利用して定量的に把握するほか、業務ドメインに即した独自データを組み合わせるのが効果的です。これにより、モデルの汎用性能だけでなく、実際の利用環境での信頼性も確認できます。
一方で、ベンチマーク結果が高くても、必ずしも安全性や公平性が担保されるわけではありません。ベンチマーク結果をそのまま信用してしまうと、バイアスや有害出力といったリスクを見逃す可能性があります。
そのため、ベンチマークテストは基盤的な指標として活用しつつ、他の評価手法と併用することが推奨されます。
敵対的プロンプト(Adversarial Prompting)
敵対的プロンプトとは、意図的に不正確な質問を与えて脆弱性やリスクを明らかにする評価手法です。システムの制約を回避させるような指示や機密情報を引き出す質問を投げかけることで、出力の安全性を確認できます。
敵対的プロンプトでは、まずセキュリティ制約やコンテンツ制御の突破を目指しましょう。モデルが意図しない応答を返さないかを確認します。
また、有害コンテンツの生成誘発を試す方法もあります。差別的な発言や不正確な医療情報など、通常は避けるべき出力を引き出せるかどうかが検証可能です。
さらに、プロンプトを分割・迂回させる手法も有効です。直接禁止されている表現を避け、段階的に質問を組み立てながら最終的に不適切な情報を誘導できるかを試します。
フィールドテスト
フィールドテストは、実際の利用環境に近い状況でLLMを運用して挙動を評価する手法です。限定的なユーザーグループやサンドボックス環境を設定することで、以下の項目を確認できます。
- ハルシネーションの発生頻度
- バイアスや不適切な出力
- ユーザー体験(UX)の一貫性
- 業務フローとの適合性
- 安全性とセキュリティ上の挙動
フィールドテストの実施によって、理論上の性能評価と現場での使用感を比較できます。そして、リスク低減の改善点を抽出できることが可能です。
ただし、フィールドテストは本番運用に近い形で行われるため、誤出力による業務影響を最小限に抑える管理体制や有害コンテンツを遮断が可能であることが前提となります。
レッドチーミング
レッドチーミングは、専門チームが攻撃者の立場となり、LLMを徹底的に検証し、脆弱性や潜在的なリスクを洗い出す評価手法です。
具体的には、悪意あるユーザーが試みるであろう内容を意図的に仕掛け、モデルの安全性を検証します。
- セキュリティ制約の突破可能性
- 有害コンテンツ生成の誘発
- ハルシネーションの誘発
- バイアスの顕在化
- ガードレールやフィルタリングの回避
- 説明可能性の欠如
レッドチーミングによって、通常のテストでは発見できないリスクを事前に特定することが可能です。ガードレールや監視機能を、運用前に強化して強固な基盤を築けます。
ただし、レッドチーミングは人的・時間的コストが大きいため、チームの確保から検証まで十分に実施できるようになってからスタートさせる必要があります。
説明可能性(Explainability)の評価
LLMの説明可能性は、モデルの出力がどのような根拠やプロセスに基づいて生成されたのかを明らかにするために欠かせない評価です。ブラックボックス的な性質を持つLLMは、なぜその出力になったのか原因が不明確になりやすいため、説明可能性を確保することが求められます。
評価方法としては、以下の手法があります。
| 評価手法 | 詳細 |
|---|---|
| 根拠データのトレーサビリティ | 出力がどの情報源に基づいて生成されたのかを特定し、再現可能性を検証 |
| 理由付け出力(Rationale Generation)の分析 | 回答に至るまでの推論プロセスを明示させ、その論理展開が妥当かどうかを確認する |
| SHAP・LIMEの応用 | 入力要素が出力に与える影響度を数値化し、モデルがどの要因を重視したかを評価 |
| 人手評価 | アノテーターや専門家によるレビューを通じ、モデルが示した説明が人間の判断に照らして妥当かを確認する |
評価のポイントは以下です。
- ユーザーや監査担当者が理解可能な形で根拠を提示できているか
- 説明が一貫性を持っているか
説明可能性の評価を行うことで、リスクが顕在化した際に原因を追跡しやすくなり、透明性を確保できます。
LLMのハルシネーションやバイアスを低減するのに有効な対策

LLMでのハルシネーションやバイアスが検出された場合には対策が必要です。具体的な低減対策について解説していきます。
LLMガードレールの活用
ガードレールとは、LLMを安全で責任ある形で利用するために、出力の範囲や内容を制御する仕組みを指します。ガードレールを設けることで、ハルシネーションを起こして虚偽情報を生成したり、有害コンテンツを出力したりするリスクを軽減できます。
具体的には、禁止ワードや特定トピックを検知して遮断するルールベースの仕組みや追加のモデルを用いたフィルタリングなどがあります。
また、企業ごとの倫理規範や法規制を反映させることで、コンプライアンス強化にも対応可能です。特に、顧客対応や教育、医療、金融といった社会的影響の大きい分野に有効です。
さらに、ガードレールは導入時だけでなく、継続的に改善と検証を行うことで効果を維持できます。責任あるAI(Responsible AI)を実現する上で、LLMガードレールの活用は不可欠です。
RAGの導入
RAG(検索拡張生成)を導入することで、LLMが持つ知識の限界や学習データの古さを補い、ハルシネーションの発生を抑制できます。企業内のナレッジベースや公開情報を検索対象として整備し、検索エンジンとモデルを統合するシステムを構築します。
その上で、出力結果に参照元を明示する設計を取り入れることで説明可能性の向上にもつながります。
セキュアなプラットフォームの選定
例えば、Azure OpenAI Serviceのように、入力されたデータがモデルの学習に利用されず、閉域網での接続が可能なエンタープライズ向けのサービスを選定することでデータ漏洩のリスクを大幅に低減できます。
temperature調整
temperatureとは、LLMが出力する回答の多様性や創造性を制御するパラメータです。値が変わることで、以下のように性質を変化させます。
| 数値 | 性質 | 適している業務 |
|---|---|---|
| 0.2〜0.4 | 出力のばらつきを抑え、再現性や一貫性を重視する | 社内ナレッジ検索やFAQ対応 |
| 0.5〜0.7 | 一定の多様性を保ちながら、精度とのバランスを取る | 顧客向けのチャット対応 |
| 0.8以上 | 創造的な文章生成やアイデア発想 | アイデアの発案 |
temperature値は高くなると、クリエイティブな性質を強めますが、ハルシネーションが増加する傾向が高まります。そのため、利用範囲は限定すべきです。
このようにtemperatureの調整は、業務要件や利用目的に即した戦略的な運用が求められます。
Chain-of-Thoughtプロンプティング
Chain-of-Thoughtプロンプティングは、モデルに思考過程を明示させることで、複雑な問題解決や推論をより正確に行わせる手法です。人間が問題を解く際に段階を踏んで考えるように、モデルに思考の連鎖を文章化させることで論理的で一貫性のある出力を得られます。
特に以下のタスクを得意としており、通常のプロンプトでは誤答が多くなる場合に有効です。
- 数値計算
- 論理推論
- 因果関係の分析
- 複雑な意思決定
モデルに思考過程を逐次的に表現させることで、精度や一貫性を高めることが可能です。これにより、回答の透明性が高まり、説明可能性の向上に直結します。
Deliberative Alignment
Deliberative Alignmentは、LLMが安全ポリシーやコンテンツポリシーを参照しながら応答の可否や内容を判断するためのアライメント手法です。OpenAIの論文「Deliberative Alignment: Reasoning Enables Safer Language Models」で提案されており、モデルの推論能力を安全性の判断に活用する点が特徴です。
従来のSFT(教師ありファインチューニング)やRLHFでは、人間が付けたラベルから望ましい応答を間接的に学習することが一般的でした。一方、Deliberative Alignmentでは、あらかじめ定義したセーフティ仕様やスタイルガイドラインをモデルに学習させ、その内容を推論プロセスで参照しながら回答を生成できるようにします。
違法行為や自傷行為の助長など、本来拒否すべきリクエストへの対応を強化しつつ、無害な質問まで拒否してしまう過剰な拒否を減らす効果が期待できます。また、jailbreakと呼ばれる回避攻撃への耐性向上にもつながる手法として注目されています。
有害コンテンツのフィルタリング
有害コンテンツのフィルタリングは、LLMが生成する出力から有害なコンテンツを排除し、安全性を確保するための対策です。モデルの応答前後にフィルタリングレイヤーを設置して、不適切な表現が含まれる場合はブロックされます。
具体的な手法は、以下の通りです。
| フィルタリング手法 | 詳細 |
|---|---|
| プロンプト設計 | モデルに対し「差別的表現を避けること」や「有害な出力は禁止」と明示する |
| ブラックリスト・ホワイトリストでの検知 | 不適切語彙や禁止トピックをリスト化し、自動検出・ブロックに適用させる |
| 分類モデルによるモデレーション | 専用の有害コンテンツ検出モデルを用いて、LLM出力をリアルタイムにスクリーニングする |
| 多段階でのフィルタリング | 生成直後に一次判定を行い、利用者に提示する前に二次判定を実施することで、回答の漏れを最小化する |
ただし、過度にフィルタリングを行うと正当な情報まで削除されるリスクがあるため、業務用途やユーザー層に応じて調整することが重要です。
反事実的データの拡張
反事実的データの拡張(Counterfactual Data Augmentation)とは、既存の学習データに対して、もし別の条件だったらという視点でデータを生成・追加する手法です。LLMの偏りを緩和する効果があります。
例えば、性別や人種などの属性を入れ替えた文章を追加することで、モデルがバイアスにとらわれずに公平に応答できるように学習させます。これにより、特定の集団に対するバイアスを低減し、公平性と信頼性を高めることが可能です。
自動生成ツールやアノテーションを活用すれば、既存データを体系的に変換して拡張できます。また、人による検証も有効で、アノテーターがレビューすれば精度が担保されます。
ただし、データ拡張も過剰に実施すると分布のバランスが崩れ、かえって性能が低下する可能性があるため注意が必要です。
複数モデルでの判定
複数モデルでの判定では、異なるモデルの出力を比較・照合することによるリスク低減を目指します。主要モデルを一次判定、別のモデルを検証役として設定し、ハルシネーションやバイアスを検出します。
同じ入力に対して複数のモデルから得た回答を比較することで、妥当性を補強し、誤情報が利用されるリスクを抑えられます。
LLM-as-a-Judge
LLM-as-a-Judgeは、生成された出力を別のLLMが評価・判定する技術です。メインのモデルであるLLM生成した回答を、異なるLLMモデルが精査します。
LLM-as-a-Judgeでの評価によって作業の効率化や継続的な品質監視が可能になり、人手リソースを削減できます。また、多くの場合において人間による評価よりも客観的な評価ができるようになり、ハルシネーションやバイアスを正確に検知可能です。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
LLMのリスク評価についてよくある質問まとめ
- LLM導入時に行うべきリスク評価は?
LLMを導入する際は、主に以下の7つのリスクを総合的に評価する必要があります。
- 安全性: ハルシネーション(虚偽情報)や有害コンテンツを生成しないか。
- バイアス: 出力に差別的な表現や偏見が含まれていないか。
- 出力の一貫性: 同じ質問に対して、安定して信頼できる回答を返すか。
- 情報の鮮度・正確性: 最新かつ正確な情報に基づいているか。
- セキュリティ: プロンプトインジェクション攻撃や情報漏洩に対する脆弱性はないか。
- 著作権侵害: 生成物が既存の著作物を盗用していないか。
- 運用コスト: API利用料などが予測不能なレベルまで増大しないか。
- LLMのリスクを評価するには、どのような手法がありますか?
代表的なリスク評価手法として、以下の5つが挙げられます。
- モデルベンチマークテスト: 標準化されたデータセットでモデルの基礎性能を測定する。
- 敵対的プロンプト: 意図的に悪意のある質問を投げかけ、脆弱性を明らかにする。
- フィールドテスト: 実際の利用環境に近い状況でテスト運用し、問題を洗い出す。
- レッドチーミング: 専門チームが攻撃者の視点でシステムを徹底的に検証する。
- 説明可能性(Explainability)の評価: なぜその回答に至ったのか、根拠やプロセスを検証する。
- バイアスはどのように検出・測定すればよいですか?
バイアスの検出には、属性や条件を変えた反事実的データを用いたテストが有効です。
- 性別や人種などの属性を入れ替え、回答の差異を比較する
- 複数の質問パターンを設計し、モデルの出力傾向を分析する
- 専門家やアノテーターによる人手評価を組み合わせ、定性的観点から確認する
まとめ
LLMを業務に導入する際は、モデル性能の高さだけでなく、安全性や信頼性を確保するためのリスク評価が欠かせません。ハルシネーションやバイアスといった問題は運用する限り付きまとうため、ガードレールやフィルタリングなどの多層的な対策を講じる必要があります。
ここで重要なのは、LLMを導入して終わりではなく、継続的に評価と改善を繰り返し、Responsible AIの実現につなげることです。そのプロセスによって、LLMは組織競争力を支える基盤へと育てられます。
もし、自社でのリスク評価手法の確立や、専門的な知見を要する対策の導入に課題を感じる場合は、知見を持つ専門家のサポートを得ながら、より堅牢なAI活用体制を構築することをおすすめします。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

