
【AI論文解説】Differential Transformer:重要な情報だけを引き出す新型Transformer「Diff Transformer」
最終更新日:2024年11月08日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

Diff Transformerは、Transformerの注意メカニズムが不要な文脈に過度に集中し、重要な情報を見逃しがちな問題に対処するために開発されました。
Diff Transformerは、異なる2つの注意スコアの差分を計算することで「ノイズ」を打ち消し、重要な情報に注意を集中させることが可能です。
これにより、情報抽出の精度や長い文脈の処理が改善され、多くの下流タスクにおいてTransformerを上回る性能を示しています。
- 論文名:Differential Transformer
- 論文著者:Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, Furu Wei| Microsoft Research, Tsinghua University
- 論文提出日:2024年10月7日
- 論文URL:https://arxiv.org/abs/2410.05258
目次
論文の要約
Diff Transformerは、Transformerの弱点である「不要な文脈への過剰な注意」に対処するために開発された新しいモデルです。
Transformerは文脈内の重要な情報を見つけるのが苦手で、余分な注意が割かれてしまいます。これに対してDiff Transformerでは、2つの注意スコアの差分を計算してノイズを打ち消し、必要な情報に注意を集中させる仕組みを導入しています。
これにより、文章の要約や質問応答のようなタスクで高い精度を発揮し、特に長い文章の処理においても優れた結果を示しました。
ポイント
- 異なる2つの注意マップの差分をとることで、ノイズを打ち消し、重要な情報に焦点を当てる「差分注意メカニズム」を導入
- 従来のTransformerに比べて、文脈の長さに応じた学習や情報抽出において高い精度を実現
- 長文処理や質問応答などの実用的なタスクにおいて、Transformerを上回る結果を示し、応用可能性が高い
論文研究内容詳細
この研究は、Transformerモデルが長いシーケンスや複雑な文脈において、不要な情報にまで注意を向けてしまう問題を解決するため、新しいアーキテクチャ「Differential Transformer(Diff Transformer)」を提案しています。
Transformerの注意機構は、ソフトマックス関数を用いてシーケンス内のトークン間の関連性を計算しますが、このプロセスで重要でない情報にも注意が割かれ、結果的にモデルの性能が低下することがあります。
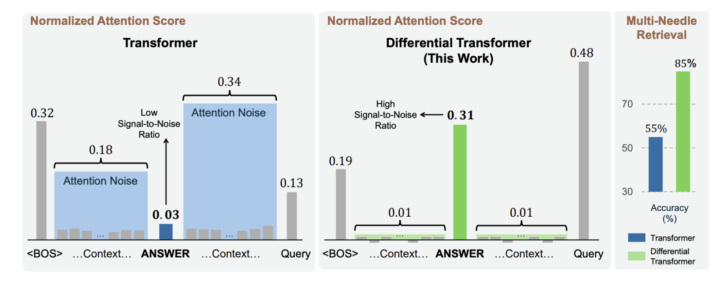
Diff Transformerは、この課題に対処するために「差分的注意機構(Differential Attention Mechanism)」を導入しています。
具体的には、クエリとキーのベクトルを2つのグループに分割し、それぞれでソフトマックス注意マップを計算します。その後、これら2つの注意マップの差を計算し、この差分を最終的な注意スコアとして使用します。この差分計算により、共通のノイズ成分がキャンセルされ、重要な情報への注意が強調されます。
この手法は、電気工学におけるノイズキャンセリングヘッドフォンや差動増幅器と類似しています。ノイズキャンセリングヘッドフォンは、環境ノイズと逆位相の音を生成してノイズを打ち消します。同様に、Diff Transformerは不要な注意(ノイズ)を打ち消し、重要な情報に焦点を当てることができます。
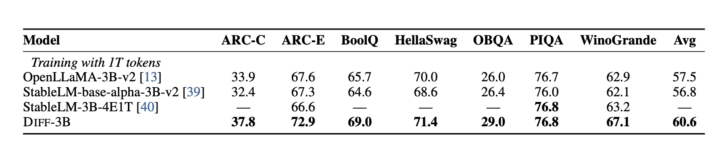
また、Diff Transformerはモデルサイズや学習トークン数のスケーリングにおいても優れており、より小さなモデルサイズや少ない学習データで同等以上の性能を達成できることが実験で示されています。
先行研究との比較
従来のTransformerモデルは、多くの自然言語処理タスクで高い性能を発揮していますが、長い文脈や大量の情報を処理する際に、重要でない部分にも過剰に注意を向けてしまう傾向があります。
これにより、モデルが重要な情報を正確に抽出できず、特に長いシーケンスにおいて性能が低下する問題がありました。また、ハルシネーションと呼ばれる、入力にない情報を生成してしまう現象も報告されています。
Diff Transformerは、この問題を解決するために差分的注意機構を導入し、2つの注意マップの差分を計算することで不要な情報を効果的に除去します。これにより、モデルが重要な情報にのみ注意を向けることができ、不要なノイズによる影響を最小限に抑えることができます。
本提案技術・手法のキモ
技術の核心は「差分的注意機構」の導入にあります。この機構では、通常のクエリ(Q)とキー(K)のベクトルを2つのグループに分割し、それぞれでソフトマックス関数を適用して注意マップを計算します。その後、これら2つの注意マップの差を計算し、この差分を用いてバリュー(V)を重み付けします。
擬似コードとして示されている下記図では、この差分的注意機構の具体的な計算手順が示されています。まず、入力Xからクエリとキーを二つに分割します(Q1、Q2、K1、K2)。
次に、それぞれの組み合わせで注意スコアA1とA2を計算します。これらのスコアはソフトマックス関数を適用した後、スカラーλを用いて差分を計算します(A1 – λ * A2)。最後に、この差分スコアをバリューVと掛け合わせて最終的な出力を得ます。
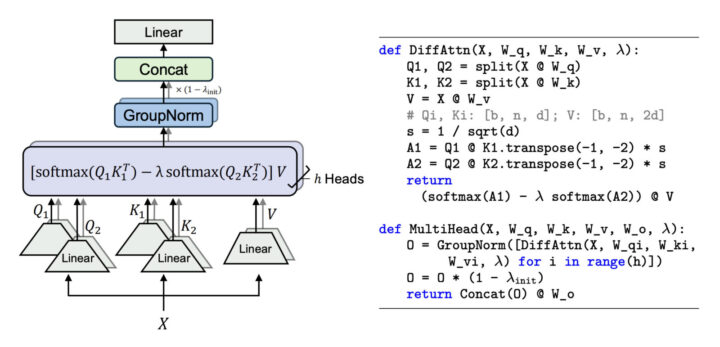
この差分計算により、共通のノイズ成分がキャンセルされ、重要な情報に対する注意が強化されます。また、λは学習可能なパラメータであり、初期値λ_initを適切に設定することで、モデルの学習を安定化させています。
さらに、Diff Transformerではマルチヘッド注意機構も差分的に拡張されています。各ヘッドは異なるパラメータを持ち、それぞれで差分的注意を計算します。ヘッド間の統計的なばらつきを抑えるために、各ヘッドに対してグループ正規化(GroupNorm)が適用されています。
これにより、ヘッドごとの出力が均一化され、学習の安定性が向上します。
これらの工夫により、Diff Transformerは従来のTransformerと同等の計算コストでありながら、不要な情報を効果的に除去し、重要な情報に集中する能力を高めています。
検証方法
Diff Transformerの有効性は、さまざまな実験を通じて総合的に検証されています。
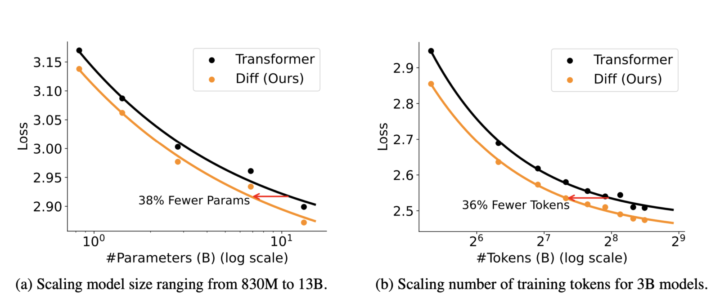
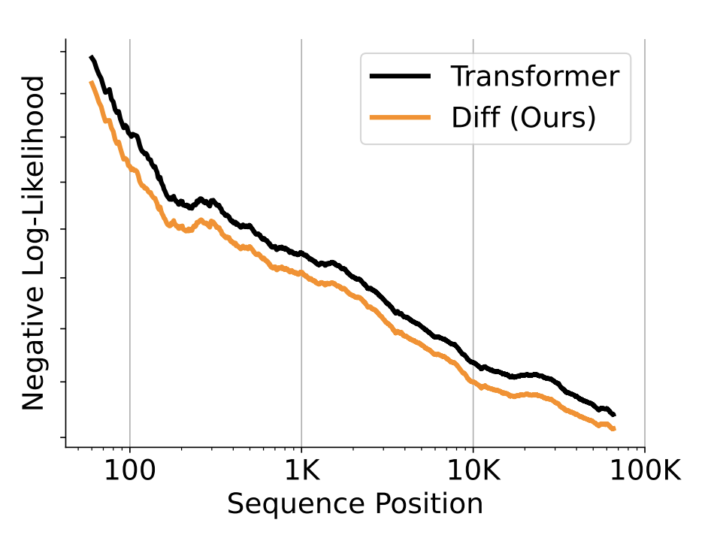
まず、言語モデリングの評価では、Diff Transformerが従来のTransformerよりも優れた性能を示しています。下記図では、モデルサイズや学習トークン数を増加させた際の検証セットにおける損失が示されており、Diff Transformerがより効率的に学習できることが分かります。
次に、長い文脈における性能評価として、最大64Kトークンの長さでの言語モデルの評価が行われています。
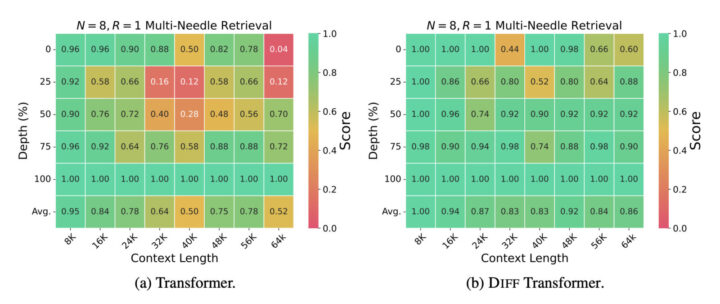
また、重要な情報の抽出能力を評価するために、「ニードル・イン・ア・ヘイスタック(Needle-in-a-Haystack)」テストが実施されています。これは、長い文脈の中から特定の情報(針)を正確に見つけ出す能力を測定するものです。
下記図では、Diff TransformerがTransformerよりも高い精度で情報を抽出できることが示されています。特に、複数の針がある場合や、針が文脈の初期部分に配置されている場合でも、高い精度を維持しています。
さらに、文脈内学習(In-Context Learning)の評価では、Diff Transformerが多数の例を提示した際にも安定した性能を発揮することや、ハルシネーションの抑制効果も評価されています。
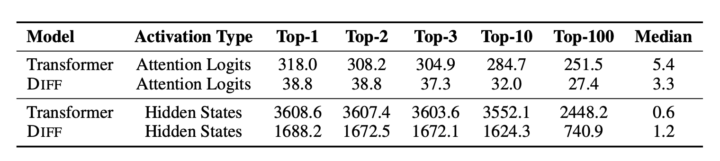
最後に、アクティベーションの異常値(アウトライヤー)の減少効果も検証されており、下記の通りDiff TransformerがTransformerよりもアウトライヤーの値が小さいことが分かります。これにより、モデルの量子化(特に低ビット幅での量子化)が容易になる可能性があります。
これらの多角的な実験結果から、Diff Transformerがさまざまなタスクや条件において有効であることが総合的に示されています。
Differential Transformerについてよくある質問まとめ
- Diff Transformerとは何ですか?
Diff Transformerは、Transformerモデルの注意機構を改良し、不要な情報(ノイズ)を減らして重要な情報にだけ集中することができる新しいアーキテクチャです。
これにより、長文内の情報抽出やハルシネーションの抑制において高い精度が発揮され、より実用的なAIモデルが構築できます。
- Diff Transformerの差分的注意機構の効果は何ですか?
差分的注意機構は、2つの異なる注意マップの差分を利用してノイズを除去し、重要な情報に焦点を当てます。
この技術により、Transformerよりも効率的に長文内の重要な情報を抽出でき、文脈内学習における安定性も向上しています。
継続的な課題・議論
Diff Transformerの提案により、Transformerの持ついくつかの課題が改善されましたが、まだいくつかの継続的な議論や研究課題が存在します。
まず、差分的注意機構が除去するノイズの具体的な性質や、その効果についてのさらなる理解が必要です。
また、差分的注意機構の計算コストや効率性についても議論があります。2つのソフトマックス注意マップを計算するため、計算量が増加する可能性があります。
さらに、低ビット幅での量子化に関する可能性も今後の研究課題です。Diff Transformerはアクティベーションのアウトライヤーを減少させる効果があり、これによりモデルの量子化が容易になると期待されています。しかし、実際にどの程度のビット幅まで量子化が可能であり、モデルの性能がどのように影響を受けるかについての詳細な研究が必要です。
最後に、Diff Transformerの適用範囲や他のタスクへの一般化についても議論が続いています。自然言語処理以外の領域、例えば画像認識や音声処理などで同様のアプローチが有効かどうか、また、他のモデルアーキテクチャとの組み合わせによる性能向上の可能性についても今後の研究が期待されます。
AI Marketでは、

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

