
Llama 3.3とは?特徴・GPTやGeminiとの性能比較・活用シーンを徹底解説!
最終更新日:2026年02月06日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

LLM(大規模言語モデル)の進化は目覚ましいですが、その多くは高度な計算リソースを必要とし、導入には高いハードルがありました。しかし、Metaが開発したLlama 3.3はその常識を覆しています。
Llama 3.3は、わずかなリソースでGPT-4やGemini 1.5 Proと互角の高い性能を発揮し、複雑なテキスト処理タスクを効率的に実行できます。
本記事では、Llama 3.3の特徴と主要AIモデルとの詳細な性能比較、Llama 3.3がどのようにして企業における様々な課題を解決し、業務効率を向上させるのか、具体的な活用事例を交えながら徹底解説します。
読み進めることで、貴社におけるLlama 3.3の活用可能性が見えてくるでしょう。
関連記事:「LLMとは?ChatGPTとの違い・企業活用事例・種類・導入方法」
AI Marketでは、
ChatGPTの導入支援ができるAI開発会社について知りたい方はこちらで特集していますので併せてご覧ください。
目次
Llama 3.3とは?

Meta社が2024年12月に発表したLlama 3.3は、オープンソースで多くの企業に活用されているLlamaシリーズで、テキスト処理に特化したLLMです。Githubでオープンソースが公開されていまる他、Meta社の公式サイトからもダウンロード可能です。
Llama 3.3は、従来のLlama 3.1 405Bモデルと同等の性能を、より小さなモデルサイズで安価な使用料で実現することを目指して設計されており、テキストのみを扱うことで、処理効率を大幅に向上させています。
Llamaのバージョンヒストリー
Llamaシリーズは、パラメータ数の増加、コンテキスト長の拡大、多言語サポートの強化など、継続的な改善を重ねてきました。また、オープンソースモデルとして、研究コミュニティや企業に広く利用されています。
特にLlama 3以降のモデルは、大幅な性能向上と機能拡張が特徴となっています。
| バージョン | 発表日 | 特徴 |
|---|---|---|
| Llama 1 | 2023年2月24日 | パラメータサイズ: 7B、13B、33B、65B コンテキスト長: 2048トークン 学習データ: 1〜1.4兆トークン 非商用ライセンスで研究者向けにリリース |
| Llama 2 | 2023年7月18日 | パラメータサイズ:7B、13B、70B コンテキスト長: 4096トークン 学習データ: 2兆トークン Grouped-Query Attention (GQA)を導入 商用利用可能なライセンスで公開 |
| Llama 3 | 2024年4月18日 | パラメータサイズ: 8B、70B コンテキスト長: 8192トークン 学習データ: 15兆トークン以上 小規模モデルにもGQAを拡張 新しいトークナイザー(TikToken)を採用 |
| Llama 3.1 | 2024年7月23日 | パラメータサイズ: 8B、70B、405B コンテキスト長: 128,000トークン 8つの追加言語をサポート |
| Llama 3.2 | 2024年9月25日 | テキストのみのモデル(1B、3B)と視覚対応モデル(11B、90B) マルチモーダル機能(テキストと画像)を導入 エッジデバイスや携帯端末向けに最適化 |
参考:Llama 3.3
▼累計1,000件以上の相談実績!お客様満足度96.8%!▼
Llama 3.3の特化型機能

Llama 3.3は、LLMの新しい方向性を示しています。従来のモデルが機能の拡張や規模の拡大を目指す中、Llama 3.3はテキスト処理に特化することで、効率性と実用性を追求しました。
テキスト処理に特化した最適化設計
Llama 3.3は、テキスト入力とテキスト出力に特化することで処理効率を大幅に向上させています。近年注目を浴びるMLLM(マルチモーダルLLM)としての機能を意図的に省くことで、テキスト処理に特化した最適化が可能となり、より少ないパラメータ数で高い性能を実現しています。
特にGrouped-Query Attention (GQA)という最適化された注意機構を採用することで、計算リソースを効率的に活用しています。これにより、一般的な開発者のワークステーションでも実用的な推論処理が可能となりました。
さらに、8ビットや4ビット精度での量子化技術をサポートし、メモリ使用量を最適化できます。
Llama 3の基本モデルは、128Kトークンのコンテキストウィンドウを採用しています。一般的な用途だけでなく、長文処理や複雑なタスクにも対応できる十分な長さです。
強化された多言語処理機能
Llama 3.3は、英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語の8言語に対応しています。多言語数学的常識問題(MGSM)というベンチマークテストでは91.1%という高精度を達成しており、非英語コンテンツでも安定した性能を発揮します。
学習データの一定部分が非英語コンテンツで構成されており、これにより多言語での自然な対話が可能となっています。特に多文化的なビジネスや研究環境での応用において、この多言語対応は重要な利点となっています。
70Bパラメータによる効率的な処理能力
Llama 3.3の最大の特徴は、70Bという比較的小規模なパラメータ数でありながら、Llama 3.1の405Bモデルに匹敵する性能を実現している点です。
Llama 3.3は、Grouped-Query Attention (GQA)という最適化された注意機構を採用することで、計算リソースの効率的な活用を可能にしています。この設計により、一般的な開発者のワークステーションでも実用的な推論処理が可能となりました。
15兆トークンの学習データによる精度向上
Llama 3.3は約15兆トークンという大規模なデータセットで学習されて、2023年12月までの知識をカバーしています。います。この学習データには、ウェブ上の公開コンテンツに加えて、2500万件以上の合成データが含まれています。
データの品質管理においては、NSFWフィルターやセマンティック重複排除など、複数の品質管理パイプラインを経て精選されています。
▼累計1,000件以上の相談実績!お客様満足度96.8%!▼
Llama 3.3と主要AIモデルとの性能比較
Llama 3.3は、テキスト処理に特化することで、より大規模なモデルと同等の性能を実現しています。この最適化アプローチにより、実用的な性能と効率性のバランスを達成しています。
Vocify社の提供するLLMリーダーボードでは、Google Gemini 1.5 Pro・GPT-4など主要モデルとの比較検証結果が掲載されています。
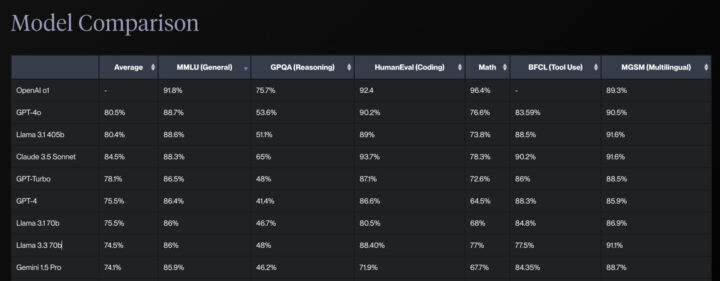
推論と理解力
推論と理解力の面では、一般知識を評価するMMULベンチマークでLlama 3.3はGemini 1.5 Proを上回り、GPT-4とほぼ同等の性能を示しています。
- GPT-4: 86.4%
- Llama 3.3: 86%
- Gemini 1.5 Pro: 85.9%
Llama 3.3は、Grouped-Query Attention (GQA)を採用することで、推論処理の効率を大幅に向上させています。NVIDIAのTensorRT-LLMとの組み合わせにより、最大で3倍の推論スループット向上を達成しています。
コード生成
コード生成能力において、Llama 3.3はHumanEvalベンチマークにおいて、Gemini 1.5 ProとGPT-4の両方を上回る優れた性能を示しています。
- Llama 3.3: 88.4%
- GPT-4: 86.6%
- Gemini 1.5 Pro: 71.9%
HumanEvalベンチマークで88.4%を記録し、GPT-4の86.6%とほぼ互角で、Gemini 1.5 Proの71.9%を大きく超える性能を発揮しています。
数学的推論
数学的推論においては、Llama 3.3はMATHベンチマークにおいて、Gemini 1.5 ProとGPT-4の両方を大きく上回る結果を示しています。
- Llama 3.3: 77%
- Gemini 1.5 Pro: 67.7%
- GPT-4: 64.5%
コンテキストウィンドウ
コンテキストウィンドウについては、Llama 3.3のコンテキストウィンドウは、Gemini 1.5 Proには及ばないものの、GPT-4を上回る長さをサポートしています。
- Gemini 1.5 Pro: 2Mトークン
- Llama 3.3: 128Kトークン
- GPT-4: 32Kトークン
Llama 3.3は128Kトークンをサポートしており、Gemini 1.5 Proの2Mトークンには及びませんが、実用的な長さの文書処理に十分な容量を確保しています。
Llama 3.3の実践的活用事例

Llama 3.3は、効率的な設計と高い処理能力を活かして、様々な実務シーンで活用されています。特に、テキスト処理に特化した最適化により、従来よりも少ないリソースで高度なタスクを実行できます。
マルチリンガル顧客サポート
Llama 3.3は、英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語の8言語に対応しており、グローバルな顧客サポートを効率的に実現します。
多言語チャットボットの構築によって、顧客の問い合わせに対して、リアルタイムで適切な言語での応答が可能です。また、異なる言語圏の顧客に対して、商品情報の提供や注文プロセスのサポートを行えます。
一般的な開発者向けワークステーションでも実用的な性能を発揮するため、中小規模の企業でも多言語対応のカスタマーサービスを展開できます。
コード生成・開発支援
HumanEvalベンチマークで88.4%のスコアを達成し、GPT-4の86.0%を上回る性能を示しています。開発者は自身のワークステーションで直接モデルを実行でき、コードの生成、デバッグ、ユニットテストの作成などを効率的に行えます。
テキストベースのデータ分析
テキストデータの分析において、Llama 3.3は効率的な処理能力を発揮します。128Kトークンのコンテキストウィンドウにより、長文のドキュメントや複雑な会話の分析が可能です。
ビジネスレポート、研究論文、法的文書などの分析や、ユーザーフィードバック、レビュー、アンケート回答の感情分析を行えます。また、大量の論文や研究データを分析し、新たな研究トレンドや重要な発見を特定します。
また、非構造化テキストデータからのパターンや傾向の特定も可能で、データドリブンな意思決定をサポートします。
ドキュメント処理・要約
128Kトークンのコンテキストウィンドウを活用し、長文ドキュメントの処理や要約を効率的に実行できます。技術文書の翻訳、マーケティング資料のローカライズ、多言語ブログの作成など、幅広いコンテンツ管理タスクに対応します。
特に、品質管理パイプラインを経て精選されたデータセットにより、高品質な出力を維持しています。
まとめ
Metaが開発したLlama 3.3は、70Bという比較的小規模なパラメータ数ながら、GPT-4やGemini 1.5 Proと同等以上の性能を実現するLLMです。テキスト処理に特化した設計により、多くの企業が抱える課題を解決する可能性を秘めています。
この記事で紹介した活用事例は、その可能性のほんの一部です。より詳細な知識や、貴社の具体的な状況に合わせた導入方法については、専門家のサポートが必要となる場合もあります。もしご興味をお持ちでしたら、ぜひお気軽にご相談ください。
AI Marketでは、
Llama 3.3についてよくある質問まとめ
- Llama 3.3は具体的にどのようなタスクに活用できますか?
マルチリンガル顧客サポート、コード生成・開発支援、テキストベースのデータ分析、ドキュメント処理・要約など、テキストに関わる幅広いタスクに活用できます。
- Llama 3.3は他のLLMと比較してどのような強みがありますか?
Llama 3.3は、テキスト処理に特化しているため、少ないリソースで高い性能を発揮します。特に、コスト効率が高く、様々な規模の企業で導入しやすい点が大きな強みです。
- Llama 3.3を利用するために必要な環境は?
Llama 3.3は、一般的な開発者向けワークステーションでも実用的な性能を発揮するように設計されています。NVIDIAのTensorRT-LLMと組み合わせることで、さらに高速な推論処理が可能です。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

