
【AI論文解説】SmolLM2:17億パラメータ×11兆トークンで実現する高性能なSLM(小規模言語モデル)
最終更新日:2025年02月20日
記事監修者:吉井秀旭

LLM(大規模言語モデル)の飛躍的な性能向上に伴い、多くのタスクで高精度な結果を得られるようになりました。
しかし数十億から数千億パラメータ規模のモデルを本番環境で使おうとすると、膨大な計算資源や推論コストが現実的な導入のネックになります。
これに対して、パラメータ数を数億から数十億程度に抑えつつも、高性能を維持したSLM(小規模言語モデル)の研究が近年活発です。LLMのように幅広い知識や推論力を備えながら、制限されたメモリや計算資源でも動作可能なモデルが求められています。
本論文は、まさにそうした要求を背景に、小規模でありながらLLMに迫る性能を狙う新たな言語モデルSmolLM2を提案し、その開発過程や実験結果を詳細に報告しています。
- 論文名:SmolLM2: When Smol Goes Big — Data-Centric Training of a Small Language Model
- 論文著者:Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydlíček, Agustín Piqueres Lajarín, Vaibhav Srivastav, Joshua Lochner, Caleb Fahlgren, Xuan-Son Nguyen, Clémentine Fourrier, Ben Burtenshaw, Hugo Larcher, Haojun Zhao, Cyril Zakka, Mathieu Morlon, Colin Raffel, Leandro von Werra, Thomas Wolf|Hugging Face
- 論文提出日:2025年2月4日
- 論文URL:https://arxiv.org/abs/2502.02737
目次
本論文の概要
SmolLM2 は約 17 億パラメータという小型モデルでありながら、約 11 兆トークンの大規模データを多段階で学習し、同クラスの他モデルを上回る性能を達成しています。
本研究では英語 Web テキストだけでなく、数学やコードといった分野に特化した高品質データを段階的に追加し、特に後半には数学推論やプログラミング能力を大きく強化するような配分が採用されています。その結果、数学問題やコーディング課題において、Qwen2.5 や Llama3.2 など同程度パラメータ数のモデルよりも高いスコアを記録しています。
さらに、事前学習後には SFT(教師あり微調整)や DPO(嗜好学習)などの工程を加えることで、ユーザ指示への応答精度や回答品質を向上させています。こうした取り組みを通じて、小さなモデルでも多様なタスクに十分対応可能な汎用言語モデルを実現している点が特徴です。
ポイント
- 多段階のデータ混合と長期学習
- 独自作成の高品質データセット(FineMath、Stack-Edu、SmolTalk)
- 小規模モデルでも多様なタスクに対応可能な実験的検証と公開リソース
SmolLM2
本研究では、「小型モデルにもかかわらず、高い性能を実現する」ために以下のような手法を大きく三段階に分けて行っています。
- 多段階でのデータ混合による大規模事前学習
- コンテクスト長拡張
- SFT(Supervised Fine-Tuning)とDPO(Direct Preference Optimization)
以下では、それぞれの段階について詳しく解説していきます。
多段階でのデータ混合による大規模事前学習
約 11 兆トークンもの膨大なテキストを以下のステージに分けて段階的に学習させるアプローチを取っています。
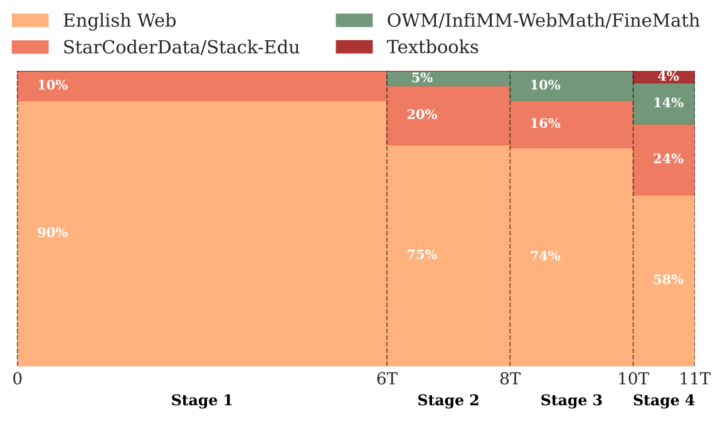
初期段階ではまず、英語Webテキストをベースに FineWeb-Edu(教育的価値が高いと判定された文書)と DCLM(多様な Q&A / カジュアルスタイル)を組み合わせ、さらに初歩的なコードデータ(StarCoderData)を 10% 程度混ぜ、学習させます。大量のトークンを使って言語理解や一般知識を広く吸収させ、ベース能力を底上げします。
ここではStarCoderDataを20%に増量し、コードデータ比率を高めます。加えて、既存の数学データ(OWM, OpenWebMath)をわずかに加え始めます。これらによってプログラミング関連の推論力を強化しつつ、数学分野にも対応可能な下地を作ります。
英語Webデータの配合をややDCLM寄りにしつつ、Stack-Edu(教材的に価値の高いコードを抜き出した新データ)を導入します。さらに、数学データもOWMやInfiMM-WebMathを合わせて10%程度に拡充します。これにより、学習後期での大幅な推論力向上を狙います。
学習率を直線的に下げつつ、最も質の高い数学データであるFineMath4+やInfiWebMath-3+を多めに取り入れます(全体の 14% 程度)。同時にコード(Stack-Edu)も大きく配合(24%)し、最後に Cosmopedia や書籍的コーパスを少し補完します。最終的に数学・プログラミング性能が飛躍的に向上し、高度な推論ができる土台が完成します。
このように、学習の進捗やベンチマーク結果に応じてデータの配合比率を調整しながら進めることで、「多彩な領域の知識」と「推論・計算力」を効率よく身につけさせる狙いがあります。特に後半のフェーズで数学とコードを重点投入することで、高レベルな推論タスクへの対応を可能にしています。
コンテクスト長拡張
SmolLM2 のベースモデルはまず「最大コンテクスト長 2k」で学習されましたが、最終段階でコンテクスト長を 8k に拡張しています。これは近年注目されている RoPE(Rotary Positional Embedding)パラメータの再設定などを行い、長文用の追加コーパスを一定割合で学習させる手法です。
この過程では、データに8kトークン以上の長文を組み込み、モデルがより長い文脈を扱えるように調整します。結果として、長文ドキュメントの要約・分割された質問応答・多段階の思考プロセスを要する問題など、より大きなスパンのテキスト処理が可能になっています。
SFT(Supervised Fine-Tuning)とDPO(Direct Preference Optimization)
ベースモデルが完成した後、SmolLM2 では実用に向けたいわゆる “Instruction Tuning” の工程として、SFT(Supervised Fine-Tuning) と DPO(Direct Preference Optimization) を実施します。
- SFT
「対話形式の指示」と「それに対する模範解答」のペアから成るデータセットを用い、教師ありの微調整を行います。論文中では独自に作成した SmolTalkや既存の MagPie 系列など、様々な指示応答データを組み合わせ、高品質な会話モデルへと仕上げています。 - DPO(Direct Preference Optimization)
別途用意した “人または AI による応答の好み” がラベルされた比較データ(ペアワイズ比較など)を使い、モデルの出力が好ましい方に寄るよう調整するアルゴリズムです。これにより、回答品質やユーザ満足度を高め、より自然で役立つ応答を返せるようになります。
DPO は Reinforcement Learning from Human Feedback (RLHF) の一種ですが、より直接的な手法として注目されています。こうしたステップを経て、SmolLM2 は「ただテキストを生成するだけでなく、ユーザ指示に沿って最適な応答を返す」能力をさらに獲得することになります。
以上のように、本研究では「多段階事前学習 → コンテクスト長拡張 → SFT・DPO による仕上げ」の三段階を踏むことで、小型モデルながらもさまざまな応用に耐えうる総合力の高い言語モデルを実現しています。
実験結果
本研究ではSmolLM2の性能比較として、1B〜2Bパラメータ規模の他モデル(Qwen2.5-1.5BやLlama3.2-1B)と各種ベンチマークを用いています。
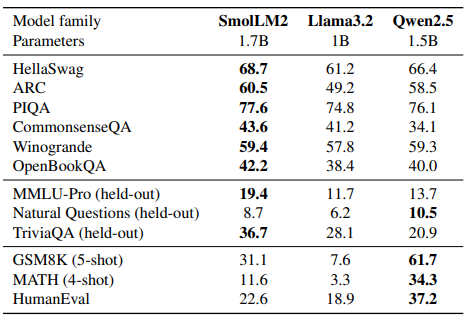
SmolLM2は一般的なベンチマーク(HellaSwag、ARCなど)で他モデルを上回る性能を示し、自然言語理解や知識系のベンチマーク(MMLU-Proなど)でも良好な結果を残しています。
一方、GSM8KやMATHなどの数学領域、およびHumanEvalなどのコード領域ではQwen2.5-1.5Bの方が一部上回るケースもありますが、本モデルも既存のLlama3.2-1B以上の水準を実現しています。さらに、論文では8kの長いコンテクストを必要とするタスク(HELMETやNeedle in the Haystack)に対しても十分な適応力があることを示しています。
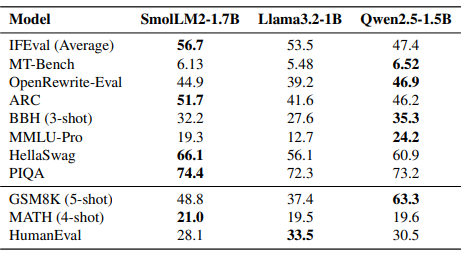
また、指示に従う能力や対話形式の応答性能を向上させるために、SmolTalkと呼ばれる新しい指示データセットを用いて追加のSFT(supervised fine-tuning)やDPO(Direct Preference Optimization)を実施した結果、自然な対話生成から数学的解法、コード生成までカバーする包括的な機能を持つ、SmolLM2-1.7B-Instructが完成しています。
考察と今後の課題
本モデルの成功要因としては、第一に大規模な英語Webデータだけでなく、数学やコードの専門データを適切にフィルタリングして多段階で組み合わせた点が大きいと述べられています。しかしながら、Qwen2.5-1.5Bなど一部の最新モデルに対してはまだ得意・不得意があり、特に高度な数学応答やコーディングタスクで今後の改良が期待されます。
さらには、小型モデルではパラメータ数が限られるため、データ選別やトレーニングスケジュールが性能を左右しやすいことが改めて示されました。データ品質をさらに高め、局所的な知識だけでなく推論プロセス自体を洗練する仕組みを入れることが、今後の主な方向性として提案されています。
また、より一貫した評価指標を確立し、モデルの特化領域を可視化する取り組みも課題として挙げられています。
SmolLM2についてよくある質問まとめ
- SmolLM2って何が特徴の言語モデル?
パラメータ数が17億程度と比較的小さいにもかかわらず、約11兆トークンという大規模なデータで学習させることで、多様なタスクで大規模モデルに近い性能をめざしたモデルです。
- LLMとの違いは?
パラメータ規模が小さい分、推論コストやメモリ消費を抑えられます。その一方で性能を維持するために、データの品質と最適な学習スケジュールが重要です。
まとめ
SmolLM2は、パラメータ数1.7Bという小規模な言語モデルを、約11兆トークンの丁寧にフィルタリングされた多様なデータで繰り返し学習することで、高い汎用性と性能を示しています。
具体的には、英語Webに加えて、数学とコードに特化した追加データセットを通じて推論力を底上げし、さらにマルチステージの学習計画により段階的にデータを学習することで、公開されている同規模のモデルの中でより優れた性能を達成しています。
本論文ではモデルの重みだけでなく、学習に用いたデータセットやコードも公開されており、将来の研究や応用の基盤となることが期待されます。
AI Marketでは、

東京大学工学部でAIについて学びながら研究を行った後、東京大学大学院に進学し研究を続けています。研究内容は、錯覚を伴う身体運動を、制御や最適化に基づくシミュレーションでモデル化することです。本アカウントでは、AI関連の最新論文などの解説を行っています!

