
自己教師あり学習とは?教師なし学習・教師あり学習との違い・仕組み・LLMにおける活用方法を初心者向けに解説!
最終更新日:2026年01月31日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- 自己教師あり学習は人間による正解ラベル(アノテーション)付与を必要とせず、データ自身から学習用の正解を自動生成する
- 特定のタスクを解く前に、世界の構造や文脈を理解する「基盤モデル」を構築する手法
- 少量のデータで専門的なタスクに適応(ファインチューニング)させることが可能
- LLM(大規模言語モデル)の次トークン予測や、製造業での異常検知、マルチモーダルAIなどのAIモデルが「自律的に賢くなる」ためのエンジン
生成AIやLLMの性能が飛躍的に向上しつつある背景には、AI開発における学習手法そのものの変化があります。その中核を担っているのが自己教師あり学習で、自然言語処理や画像認識、マルチモーダルAIの分野で採用されるようになり、AI(人工知能)モデルの開発におけるの前提条件にもなりつつあります。
本記事では、自己教師あり学習の概要から、教師あり学習・教師なし学習との違い、仕組み、代表的なアプローチについて解説します。また、自己教師あり学習がなぜLLM(大規模言語モデル)や最新の画像解析において中核を担っているのか、その仕組みをエンジニアリングとビジネスの両側面から解き明かします。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
AI開発会社をご自分で選びたい方はこちらで特集していますので併せてご覧ください。
自己教師あり学習とは?
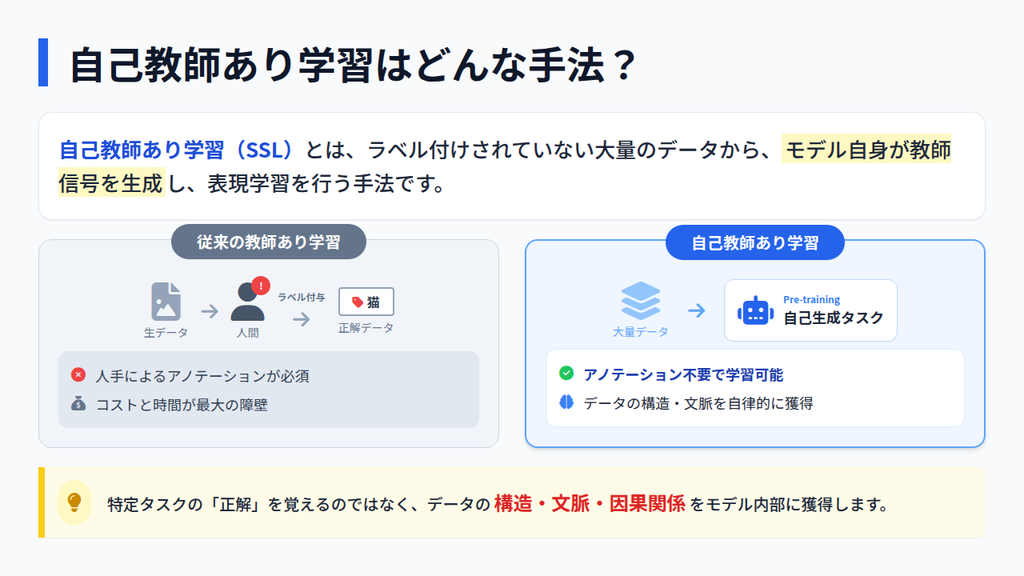
自己教師あり学習(SSL:Self-Supervised Learning)とは、ラベル付けされていない大量のデータから、AIモデル自身が教師信号を生成し、表現学習を行う手法です。自然言語処理や画像認識の分野において重要な手法となっています。
特にChatGPTなどに使われるLLM(大規模言語モデル)やマルチモーダルAIの基盤技術として中核を担います。
従来の「教師あり学習」では、人間が大量のデータに対して「これは猫」「これは売上データ」といった正解ラベルを付与(アノテーション)する必要がありました。これがAI導入における最大のコスト障壁でした。
自己教師あり学習では、人手によるアノテーションに依存せずに学習を進められます。
このアプローチは、特定のタスクを直接解くことではなく、データの構造・文脈・潜在的な因果関係をモデル内部に獲得させます。その結果、自己教師あり学習で事前学習されたモデルは、下流タスク(分類、生成、予測)に転用した際に高い汎化性能を発揮します。
教師なし学習・教師あり学習・半教師あり学習との違い
| 学習手法 | ラベル(正解)の有無 | 学習の仕組み | メリット | 主な課題 |
|---|---|---|---|---|
| 教師あり学習 | 必須 (人間が付与) | 入力と正解のペアを覚え、未知のデータに対して正解を予測する | 精度が安定しやすく、評価(正解率)が明確 高精度な予測が求められる場面で広く利用 | 大量のアノテーションコストと時間が必要 |
| 教師なし学習 | 不要 | データ自体の構造や分布を分析し、グループ化(クラスタリング)する | データの傾向把握や異常検知の初期段階に有効 | 「何をもって正解とするか」の解釈が人間に委ねられる |
| 半教師あり学習 | 一部のみ有 | 少量のラベル付きデータと、大量のラベルなしデータを組み合わせて学習 | ラベル作成コストを抑えつつ、教師ありに近い精度を狙える | ラベルなしデータの質が悪いと、全体の精度が引っ張られる |
| 自己教師あり学習 | 不要 (データから自動生成) | データ自身から正解を作り出し学習する。 | 膨大な未整理データを活用でき、高度な汎用性が育つ | 莫大な計算リソース(GPU)が必要 評価がテクニカル |
教師あり学習は、入力データと正解ラベルの組(教師データ)を用いて学習する手法です。画像分類や需要予測など、高精度な予測が求められる場面で広く利用されています。
一方で、大量のラベル付きデータを用意する必要があり、コスト・時間・スケーラビリティが課題となります。
次に教師なし学習は、ラベルを使用せず、データの分布や構造そのものを捉えることを目的とします。しかし、学習結果がタスクに結びつきにくく、何を学習したのかが分かりづらいという側面が残ります。
半教師あり学習は、少量のラベル付きデータと大量の未ラベルデータを組み合わせて学習する手法です。教師あり学習の精度と、教師なし学習のデータ効率を両立させますが、設計が複雑になってしまいます。
一方、自己教師あり学習は、ラベルが存在しないという点では教師なし学習に近いものの、学習タスクそのものは教師あり形式で設計されています。大量の未ラベルデータを活用しつつ、下流タスクに直結する表現学習が可能です。
自己教師あり学習で、地頭の良いジェネラリストとしてのAIモデルを育て、その後、少量の教師ありデータで専門家としてのAIに仕立て上げる(ファインチューニング)二段構えの手法がよく使われます。
自己教師あり学習の活用領域
自己教師あり学習は特定分野に限らず、生成AIや予測AIの基盤技術として幅広い領域で実運用されています。以下では、代表的な活用領域を整理しています。
| 活用領域 | 活用例 |
|---|---|
| 自然言語処理(NLP) |
|
| 画像分析・動画解析 | |
| 音声・音響認識 |
|
| 時系列・センサーデータ | |
| マルチモーダルAI |
自然言語処理の分野では、自己教師あり学習は標準的な事前学習手法として定着しています。次トークン予測やマスク予測を通じて文脈理解能力を獲得したモデルは、翻訳・要約・検索・生成といった多様なタスクに転用可能です。
画像・動画解析では、ラベル付けが困難な映像データを活かせる点がメリットです。特に製造業や医療分野では、正常データを中心に自己教師あり学習を行い、異常検知へ応用されます。
音声・音響、時系列データにおいても同様に、連続性や時間的構造そのものを学習対象にすることが可能です。
また、複数のモダリティを統合するマルチモーダルAIや世界モデルにおいても、現実世界の構造や因果関係をラベルなしで獲得する必要があるため、自己教師あり学習が不可欠な要素となっています。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
自己教師あり学習の仕組みは?
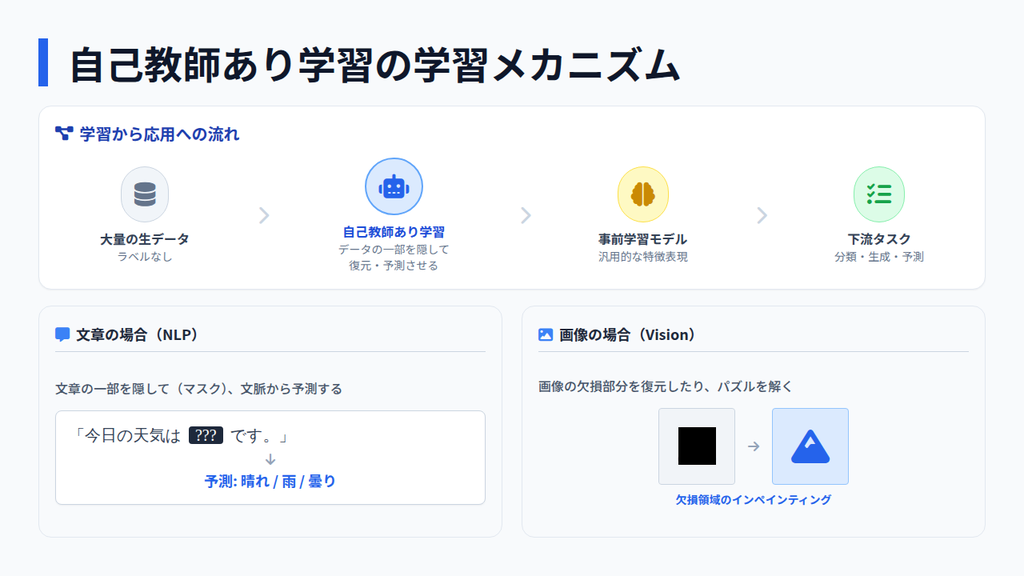
自己教師あり学習において重要なのは、あらかじめ人が正解を与えるのではなく、データの一部を変換・欠損・分割することで予測対象を人工的に作り出す点と言えます。以下では、自己教師あり学習の仕組みを解説します。
データから教師信号を自動生成する
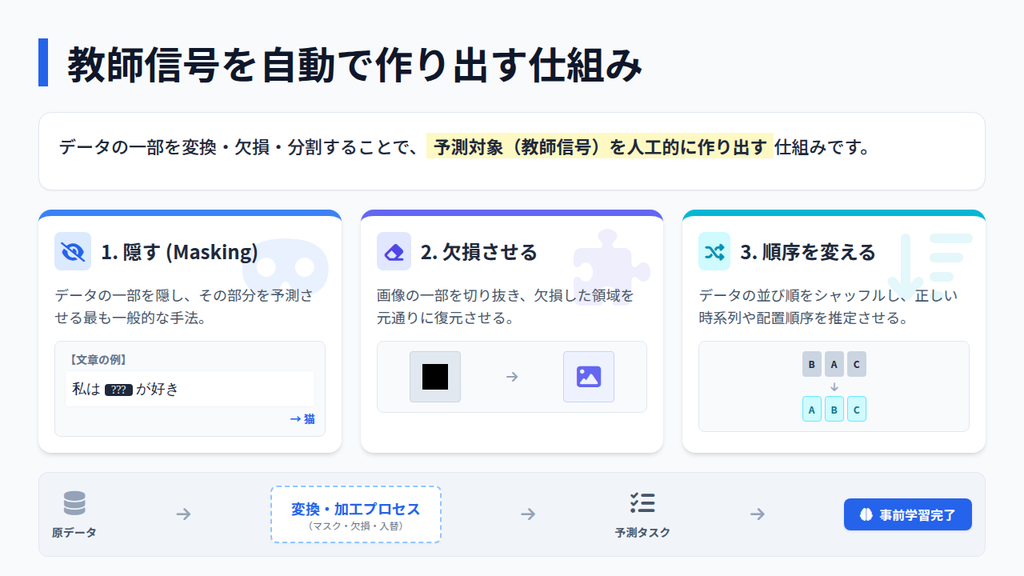
自己教師あり学習は、人手で付与されたラベルを使わず、元データから学習用の教師信号を自動的に作り出す設計です。ここでいう教師信号とはモデルが予測すべき正解を指します。
しかし、その正解は外部から与えられるものではなく、データの一部を加工・変換することでAIが内部的に生成します。
具体的には、データの一部を意図的に隠す・欠損させる・順序を変えるといった操作を行い、その元の状態を予測させます。
- 文章中の単語をマスクして予測させる
- 画像の一部を隠して復元させる
- 時系列データの次の値を推定させる
これにより、入力と正解が同一データから同時に生成されます。モデルは単純な表層パターンではなく、文脈・構造・時間的整合性・因果関係といった情報を捉えるように学習できます。
また、教師信号を自動生成することで、データの種類や量に対する制約が緩和されます。企業内に蓄積されたログ、文書、画像、センサーデータなども、そのまま学習資源として活用可能です。
そのため、データ活用のスケールと実用性を両立させることが可能です。
代表的なアプローチ手法
自己教師あり学習には複数の系統があり、データ種別(テキスト・画像・音声・時系列)や目的(表現学習・生成・予測)に応じて使い分けられます。
| アプローチ | 概要 | 学習方法のイメージ例 | 適用領域 |
|---|---|---|---|
| JEPA(Joint-Embedding Predictive Architecture) | 観測の一部から別部分の表現を予測し、意味的構造に集中 | 「ペンが机から落ちる動画」の続きを予測する際、「ペンは床に落ちて、少し滑って止まる」という結果(概念)だけに焦点を当てて予測 |
|
| マスク予測(Masked Modeling) | 入力の一部を隠し、欠損部分を当てることで文脈表現を獲得 | 「本日は[ ? ]に恵まれ、絶好の行楽日和です。」 → [ 晴天 ]を予測 写真の真ん中を黒塗りにし、周りの風景から真ん中に何があるかを推論させる |
|
| 自己回帰予測(Autoregressive) | 過去の情報から次の要素を逐次予測し、系列構造を学習 | 「むかしむかし、あるところに……」 → 次に来るのは「おじいさんと」である確率が高いと予測 |
|
| 対照学習(Contrastive Learning) | 正例(近い/同一)と負例(異なる)を引き離し、識別可能な表現を学習 | 同じ犬の写真を「角度を変えたもの」と「色を変えたもの」を用意し、これらは「同じもの」であると教えます |
|
| 非対照・自己蒸留(Non-contrastive / Distillation) | 負例を使わず、異なる変換ビュー間で表現を一致させる | 「学生AI」が、少しだけ先に学習が進んでいる「先生AI(実は自分自身のコピー)」の出力を予測・模倣 |
|
| 復元・ノイズ除去(Denoising / Reconstruction) | ノイズ付与や欠損を加え、元に戻す過程で学習する | 砂嵐が混じった古い録音音声から、ノイズを取り除いて元の声を復元 |
|
| 予測符号化(Predictive Coding) | コンテキストから将来の潜在表現を予測し、情報量の高い特徴を獲得 | 歩いている時、「次に足が着く感覚」を予測しているが、もし段差がある場合、予想外の衝撃(予測エラー)を感じます。この「予測と現実の差」から学習 |
|
特にJEPAは、自己教師あり学習の中でも重要です。復元型の学習がピクセルや波形などの細部に引きずられやすいのに対し、JEPAは入力の一部から別部分の埋め込みを予測することで意味的・構造的な情報の獲得を狙います。
自己教師あり学習は、教師信号の作り方と予測対象の置き方によってアプローチが分岐します。
事前学習
自己教師あり学習では、事前学習(Pre-training)と下流タスク(Downstream Task)を分離できる2段階構成となっており、汎用性と実用性を両立したモデル開発が可能になります。
事前学習では、ラベルを必要としない自己教師ありタスクを通じて、モデルにデータ全体の文脈や構造を学習させます。この段階では、後続タスクで再利用可能な表現を獲得することが目的です。
そのため、大規模かつ多様な未ラベルデータを用いるほど、モデルの汎化性能は高まります。
下流タスクへの転用
下流タスクへの転用では、事前学習済みモデルをベースとして、分類・生成・予測・異常検知などの業務タスクに適応させます。この際、少量のラベル付きデータでチューニングする、あるいはモデルを固定して利用することが可能です。
これにより、ゼロからモデルを学習する場合と比べて、必要なデータ量や開発工数を大幅に削減できます。
特に企業利用においては、まず自己教師あり学習で自社データに適応した基盤モデルを作り、用途ごとに下流タスクを追加するアプローチをとることが多いです。そうすることで、ドメイン固有の知識を内包したモデル資産を蓄積できます。
自己教師あり学習の4つのメリット
自己教師あり学習は、データ活用・開発効率・適合性の観点でメリットを持ちます。特に企業におけるAI活用では、どのようにデータを集め、どこまでコストをかけられるかが成否を分けるでしょう。
既存の未ラベルデータをそのまま活用できる
自己教師あり学習のメリットとして挙げられるのが、既存の未ラベルデータを追加で加工することなく活用できる点にあります。企業には業務ログ・文書・画像・音声・センサーデータなどの情報が蓄積されていますが、それらの大半はラベル付けされておらず、十分に活用できない状態です。
従来の教師あり学習では、これらのデータを使うために、正解ラベルの設計と付与(アノテーション)が必要でした。しかし、この工程では専門の知識と人的コストを要し、データ量が増えるほど現実的でなくなってしまいます。
一方で自己教師あり学習は、データそのものから教師信号を自動生成します。そのため、過去に蓄積されたデータや、日常業務の中で自然に発生するデータを、そのまま学習に投入できます。
導入視点で見ると、「ラベル貼りが必要だから無理」と諦めていた領域に、自己教師あり学習が風穴を開けます。
自社ドメイン特化の基盤モデルを作れる
自己教師あり学習では、自社ドメインに最適化された基盤モデルを構築することが可能です。公開されている汎用モデルは幅広いデータで学習されていますが、特定の業界や業務固有の文脈・専門用語までは十分に反映されていません。
社内文書から業務ログ、運用データを学習に利用することで、固有の表現や暗黙知を内部表現として獲得し、汎用モデルでは捉えきれない精度を実現します。
自社データで事前学習されたモデルは外部データへの依存度が低いため、セキュリティやガバナンスにおいても扱いやすくなります。
少量のデータでも高精度なモデルを構築できる
自己教師あり学習は、下流タスクにおいて必要となるラベル付きデータ量を大幅に削減できます。事前学習の段階でデータ構造や文脈を学習しているため、モデルがすでに良い初期状態を持っているからこそ実現されます。
従来の教師あり学習では、タスクごとに一定量のラベル付きデータを用意しなければ、安定した精度を得ることが困難でした。
一方、自己教師あり学習で事前学習されたモデルは、少量のデータによるファインチューニングや、場合によっては学習なしの転用でも実用レベルの性能を発揮します。
導入視点で見ると、データの量が足りない、偏っているという課題を解消する手段といえます。
特に製造業の検品や金融の不正検知など、不正解データ(=異常値)が極めて少ないケースでは、教師あり学習は機能しにくいのが実情です。自己教師あり学習で「正常な状態」を学習させることで、そこから外れる違和感も敏感に察知する、より高度な検知モデルが構築可能です。
データ作成・開発にかかるコストと時間が削減される
自己教師あり学習は、AI開発におけるコストや時間の削減にも貢献します。人手によるアノテーション作業を前提としないため、データ準備に要する時間と人件費を大幅に削減できます。
特に、専門知識が必要な分野や判断基準が属人的になりやすいアノテーション業務では、この効果が顕著に表れるでしょう。結果として、開発の初期段階におけるボトルネックが解消され、検証サイクルを高速に回せるようになります。
また、事前学習済みのモデルを基盤として再利用できるため、タスクごとにゼロからモデルを構築する必要がありません。基盤モデルを前提とした開発にシフトすることで、プロジェクトのPOC(概念実証)期間を大幅に短縮し、市場投入までのスピードを上げることが可能です。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
なぜ自己教師あり学習はLLMで不可欠?

LLM(大規模言語モデル)は、その性能の大部分を自己教師あり学習による事前学習に依存しています。人手で設計されたタスクを直接解かせるのではなく、大量のテキストデータから言語構造や文脈を獲得することが汎用性の高いモデルを成立させています。
以下では、LLMにおいて自己教師あり学習がどのような形で組み込まれているのかを、学習アプローチごとに解説します。
次トークン予測による事前学習がLLMのキモ
LLMにおける自己教師あり学習の中核となっているのが、次トークン予測による事前学習です。与えられた文脈に基づいて、次に出現する単語(トークン)を予測するタスクを繰り返すことで言語の構造や意味的関係を学習させます。
テキストデータそのものが、入力(これまでのトークン列)と正解(次のトークン)を同時に提供するため、自己教師あり学習として自然に成立します。次トークン予測こそが、「AIは既存文章の続きに出てくる単語を確率的に予測しているだけ」とよく言われるゆえんです。
次トークン予測は文章生成との親和性が高く、自然な文章を連続的に生成する能力を高めやすいのが特徴です。一方で単語単位の正解を当てるタスクであるため、文全体の意味理解や双方向文脈の把握には、次に説明するマスク予測型などのさらなる工夫が必要になります。
それでも、次トークン予測はスケーラビリティと汎用性に優れており、現在のLLMの多くがこの形式を採用しています。
マスク予測型アプローチによる文脈理解
マスク予測型アプローチは、文脈理解に特化した手法として位置づけられます。文章中の一部のトークンを意図的にマスクし、その欠損部分を周囲の文脈から推定させることで学習を行います。
このアプローチで特徴なのは、予測対象となるトークンの前後の情報を同時に参照できる点です。これにより、モデルは単語の出現確率だけでなく、文全体の意味的整合性や依存関係を考慮した表現を内部に構築できるようになります。
マスク予測型アプローチは、単文の理解や情報抽出、分類といったタスクで高い性能を発揮します。
また、マスク予測型は生成を主目的としないため、推論時の安定性や再現性を重視する用途にも適しています。検索・要約・RAGの文書理解など、正確に理解することが重要な場面で機能します。
テキスト・画像・音声・動画を同時に扱うマルチモーダルSSL
自己教師あり学習はテキスト単体にとどまらず、複数のデータ形式を同時に扱うマルチモーダルAIや世界モデルへと拡張されています。ここで重要な役割を果たしているのが、マルチモーダル自己教師あり学習(Multimodal SSL)です。
マルチモーダルSSLでは、テキスト・画像・音声・動画といったモダリティ間の対応関係をラベルなしで学習します。例えば、画像とそれを説明するテキストが意味的に対応しているかを予測させることでモダリティを横断した共通表現を獲得します。
これにより、テキストだけでは不十分だった視覚的・空間的理解が補完され、より現実世界に近い認識が可能です。
世界モデル
さらに発展した概念が、環境の状態遷移や因果関係を内部表現として学習する世界モデルです。自己教師あり学習を用いて、次の状態・観測されない部分・将来の変化を予測することで、AIモデルは世界の構造そのものを内在化します。
LLMと世界モデルが結びつくことで、言語理解・視覚認識・行動予測を統合した高度な推論が可能になります。
このように、マルチモーダルSSLや世界モデルは、自己教師あり学習を世界理解へと進化させるものであり、次世代型LLMの基盤技術にもなり得るでしょう。
強化学習との役割分担
LLMの開発において、自己教師あり学習と強化学習は競合する手法ではなく、役割が分かれた補完関係にあります。それぞれが担う役割を理解することで、モデル設計の全体像が見えやすくなります。
自己教師あり学習は、主に世界や言語の構造を理解するための基盤づくりを担います。この段階では、特定の目的や報酬を直接最適化することはありません。
一方で強化学習は、望ましい振る舞いや出力を評価基準に基づいて調整する役割を担います。人間のフィードバックやルールベースの報酬を用いて、安全性・有用性・指示遵守といった観点で出力を最適化します。
LLM開発では、自己教師あり学習による事前学習によって広範な知識と表現力を獲得し、その後に強化学習で振る舞いを調整します。
この役割分担を踏まえると、自己教師あり学習はLLMの能力そのものを規定し、強化学習はその能力をどのように使わせるかを制御する仕組みといえます。
自己教師あり学習についてよくある質問まとめ
- 自己教師あり学習とは何ですか?
自己教師あり学習とは、ラベル付けされていないデータから、モデル自身が学習用の教師信号を生成し、表現学習を行う機械学習手法です。人手による正解ラベルを必要とせず、文章の一部を予測させる、画像の欠損部分を復元させるなど、データ内部の構造を利用して学習タスクを構成します。
- 自己教師あり学習は、他の学習手法と何が違うのですか?
最大の違いは「正解ラベル(教師信号)の作り方」にあります。
- 教師あり学習: 人間が手動で正解ラベルを付与します。
- 教師なし学習: 正解を定義せず、データの構造やグループ化のみを行います。
- 自己教師あり学習: データの一部を隠したり変換したりすることで、データ自身から自動的に正解を作り出し、教師あり学習の形式で学習を進めます。
- 自己教師あり学習はLLMでどのように活用されますか?
LLMでは、自己教師あり学習が事前学習フェーズの中核を担っています。代表的な例が次トークン予測やマスク予測による学習で、これらのタスクにより、モデルは言語の文法構造や意味関係、長距離文脈を獲得します。
その後、必要に応じて強化学習やファインチューニングを行い、指示遵守や安全性といった振る舞いを調整します。
- 自社に大量のデータ(ログや画像)はありますが、どの手法が最適かどのように判断できますか?
データの特性(時系列、テキスト、画像など)や、解決したい課題(予測、分類、生成)によって最適なアプローチは異なります。AI Marketでは、貴社の保有データの内容をヒアリングし、自己教師あり学習を含む最適な手法を提案できる経験豊富な開発パートナーを選定・紹介することが可能です。
- 自己教師あり学習は計算リソース(GPU)の負荷が高いと聞きますが、コストが見合いますか?
ゼロからの学習はコストがかかりますが、既存の基盤モデルを自社データで「自己教師あり」的に追加学習させる手法なら、コストを抑えつつ高い効果を得られるケースが多いです。AI Marketのコンシェルジュにご相談いただければ、予算感に合わせた現実的な開発計画を持つ企業を無料でマッチングいたします。
まとめ
自己教師あり学習は、生成AIやLLMを実運用レベルへ引き上げるための前提条件となり得る設計思想です。ラベルの作成に依存せず、未整理データをそのまま価値ある知識へ変換できるため、研究用途にとどまらず、企業におけるAI活用を現実的なものにするでしょう。
LLMの文脈では、自己教師あり学習が知識獲得と理解の役割を担い、強化学習が振る舞いを制御するという役割が成立しています。
自己教師あり学習を実ビジネスに落とし込むには、計算リソースの確保や、JEPAや対照学習といった複雑なアルゴリズムから自社課題に最適なものを選定する高度な専門性が求められます。
自社データのポテンシャルを最大限に引き出し、競争優位性を築くための具体的な導入戦略については専門的な知見を持つパートナーの伴走が不可欠です。次世代のAI活用へ一歩踏み出すために、まずは専門家への相談を検討してみてはいかがでしょうか。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

お電話で無料相談
WEBから無料相談(60秒で完了)
今年度問い合わせ急増中
Warning: foreach() argument must be of type array|object, false given in /home/aimarket/ai-market.jp/public_html/wp-content/themes/aimarket/functions.php on line 1594
Warning: foreach() argument must be of type array|object, false given in /home/aimarket/ai-market.jp/public_html/wp-content/themes/aimarket/functions.php on line 1594
