
Vision Transformer(ViT)とは?画像認識を変える仕組み・CNNとの違い・メリット・限界を徹底解説!
最終更新日:2026年01月31日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

画像認識の最前線で注目を集めるVision Transformer(ViT)。従来のCNNとは異なるアプローチで画像処理を行うこのモデルは、特に大規模データセットでの学習において優れた性能を示しています。
本記事では、ViTの基本的な仕組み、CNNとの違いから、実務での採用を検討する際に重要となるメリット・デメリットまで、実践的な観点から解説します。画像認識システムの構築や改善を検討されている方々に、技術選択の判断材料としてご活用いただける内容となっています。
関連記事:「AIによる画像認識とは?画像解析との違い・精度・仕組み」
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
画像認識、画像解析に強いAI開発会社をご自分で選びたい場合はこちらで特集していますので併せてご覧ください。
目次
Vision Transformer(ViT)とは?
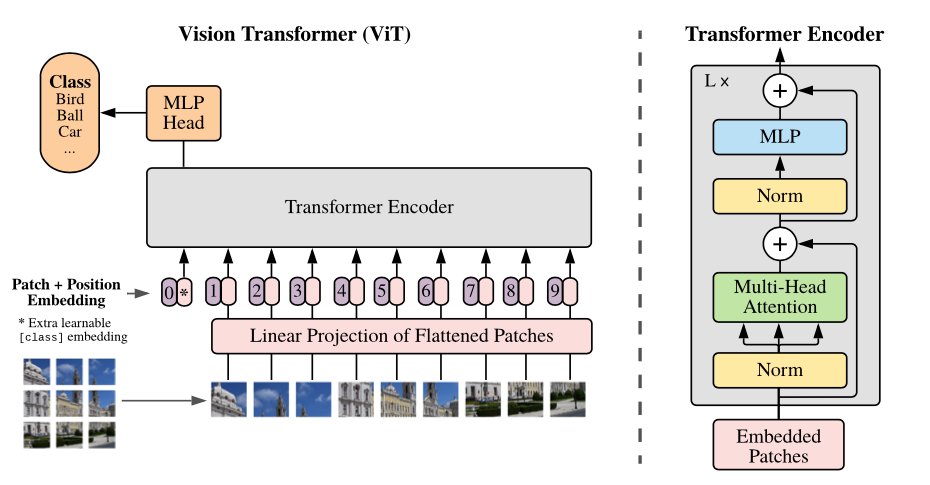
Vision Transformer(ViT)は、画像認識にTransformerを利用したモデルで2020年にGoogleから発表されました。自然言語処理で成功を収めたTransformerアーキテクチャを画像認識タスクに適用しています。
従来から画像認識分野で広く使われているCNN(畳み込みニューラルネットワーク)のような畳み込み層を一切使用せずに最先端の認識性能を達成しました。
画像をパッチに分割してトークンとして処理
Vision Transformerの核となる処理方式は、入力画像を固定サイズのパッチに分割することから始まります。画像を16×16ピクセルの小さな領域に分割し、各パッチを1次元のベクトルに変換します。
このプロセスにより、画像データを言語モデルで扱うトークンのような形式に変換することが可能となります。
変換されたパッチは線形射影によって低次元空間に埋め込まれ、パッチ埋め込みと呼ばれる特徴量として扱われます。さらに、クラス識別のための特別なトークン(Class Token)が追加され、位置情報を保持するための位置埋め込みも適用されます。
自己注意機構を活用した画像認識
Vision Transformerの処理フローは、パッチ埋め込みの生成後、Transformerエンコーダによる特徴抽出へと続きます。エンコーダ内では、Self-Attention機構(自己注意機構)により、画像内の異なるパッチ間の関係性が捉えられます。
このアプローチの特徴的な点は、CNNのような局所的な特徴抽出に依存しないことです。そのため、画像全体のグローバルな文脈を直接的に処理できます。
TransformerのAttention機構(注意機構)により、画像内の離れた位置にある要素間の関係性も効果的に捉えることが可能となり、これが従来のCNNベースモデルを超える性能の実現につながっています。
参考:GitHub|google-research/vision_transformer
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
CNNとVision Transformerの特性の違い

画像認識の分野において、CNNとVision Transformerは異なるアプローチで画像処理を行う二大アーキテクチャです。CNNが長年にわたって画像認識の主流であった中、Vision Transformerは新しいアプローチで優れた性能を示し、特に大規模データセットでの学習において注目を集めています。
アーキテクチャのコンセプトの違い
Vision Transformerは画像を固定サイズのパッチに分割し、それらをシーケンスデータとして扱うことで、画像全体のグローバルな関係性を直接的に捉えることができます。
CNNは畳み込み層を使用して局所的な特徴を段階的に抽出し、近接するピクセル間の関係性を前提とした設計になっています。
データセット規模による性能特性の違い
Vision Transformerは大規模なデータセット(例:JFT-300M)で事前学習を行うことで、ImageNetなどのベンチマークタスクでCNNベースのモデルを上回る性能を達成しました。大規模なデータセットで学習させた場合に真価を発揮し、1400万枚以上の画像データセットで学習させた場合にCNNを上回る性能を示すことができます。
ただし、Vision Transformerは大規模データセットで事前学習した後、小規模データセットに対して効果的に転移学習を行うことができます。
最新の研究では、データ拡張技術や蒸留技術を用いることで、Vision Transformerの小規模データセットでの性能を大幅に向上させることができることが示されています。
CNNは局所性や重み共有などの帰納的バイアスが組み込まれているため、比較的小規模なデータセットでも効果的に学習を行うことができます。
処理効率と計算リソースの特徴
Vision Transformerは自己注意機構を使用するため、一般的にCNNよりも計算コストが高くなります。しかし、Vision Transformerは画像全体のコンテキストを直接的に処理できるため、高解像度の画像を扱う際に特に効果的です。
最近は、Vision Transformerの計算効率を向上させるための様々な手法が提案されています。例えば、Swin Transformerは局所的な自己注意機構を導入することで、計算量を線形に抑えつつ高い性能を実現しています。
CNNは畳み込み演算を基本としているため、画像サイズの増加に対して比較的効率的にスケールすることができます。
適した用途と応用分野
Vision Transformerは画像分類、物体検出、セグメンテーションなど、幅広いコンピュータビジョンタスクで高い性能を発揮します。特にグローバルな文脈理解が重要なタスクや、大規模なデータセットを活用できる環境で威力を発揮します。
また、Vision Transformerは自然言語処理のTransformerと容易に統合できるため、画像とテキスト間のマルチモーダルタスクに特に適しています。
CNNは局所的なパターン認識が重要な場面や、リアルタイム処理が必要なアプリケーション、比較的小規模なデータセットでの学習に適しています。
画像認識技術は急速に進化しており、様々なモデルやサービスが登場しています。以下に、代表的な画像認識モデルとサービスを紹介します。
- U-Net:医用画像のセグメンテーションに特化したCNNアーキテクチャで、エンコーダ-デコーダ構造とスキップ接続が特徴的です。
- ResNet:深層ネットワークの学習を可能にしたモデルで、残差接続により勾配消失問題を解決しました。
- EfficientNet:モデルのスケーリングを最適化することで、少ないパラメータ数で高い精度を実現したCNNアーキテクチャです。
- CLIP:画像と自然言語を組み合わせて学習するマルチモーダルモデルで、柔軟な画像認識タスクに対応できます。
- Segment Anything Model (SAM):Meta AIが開発した汎用的なセグメンテーションモデル。画像エンコーダはVision Transformer (ViT) をベースとしたアーキテクチャを採用。
Vision Transformerの実用的なメリット

Vision Transformerは、従来のCNNベースのモデルと比較して、いくつかの実用的な利点を持っています。特に大規模なデータセットでの学習や、モデルのスケーリングにおいて優れた特性を示します。
高い計算効率とスケーラビリティ
Vision Transformerは、純粋にTransformerのアーキテクチャのみを利用することで、優れた計算効率とスケーラビリティを実現しています。モデルを大きくすると学習が進みにくくなる従来の深層学習モデルの課題に対して、Vision Transformerはモデルサイズを拡大しても性能向上が期待できるという特徴があります。
Vision Transformerの自己注意機構は本質的に並列処理に適しており、GPUなどの並列計算ハードウェアを効率的に活用できます。また、Swin TransformerやEfficient ViTなどの改良版アーキテクチャにより、メモリ使用量を抑えつつ高い性能を維持する手法が提案されています。
これにより、より大規模なモデルの構築が可能となり、画像認識タスクにおける性能向上の可能性が広がっています。
事前学習モデルの転移学習における優位性
Vision Transformerは転移学習において特に優れた性能を発揮します。大規模なデータセットで事前学習を行い、より小規模なタスクに適応させる際に高い精度を維持できます。
大規模な事前学習を行ったViTモデルは、少数のラベル付きデータでも高い性能を発揮することが示されています。
特に、ImageNet、CIFAR-100、VTABなどの様々な画像認識ベンチマークにおいて、最先端のCNNモデルと同等以上の性能を示しながら、学習に必要な計算コストを大幅に削減することに成功しています。
さらに、画像だけでなく、テキストや音声などの他のモダリティとの統合が容易であり、マルチモーダルタスクへの転移学習でも優れた性能を示しています。
自己教師あり学習への適用可能性
Vision Transformerは自己教師あり学習との相性が非常に良く、ラベル付けされていないデータからも効果的に特徴を学習することができます。特にDINOフレームワークを用いた場合、シーンのレイアウトやオブジェクトの境界情報を明示的に捉えることができ、k-近傍法による分類でもImageNetにおいて高精度を達成しています。
この特性により、ラベル付けされていない大量のデータを効果的に活用した学習が可能となり、モデルの汎用性と性能をさらに向上させることができます。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
Vision Transformerの課題とデメリット

Vision Transformerは新しいモデルとして注目を集めていますが、実用面においていくつかの重要な課題とデメリットが存在します。これらの制限を理解することは、モデルの適切な活用において重要です。
小規模データセットにおける汎化性能の低下
Vision Transformerの最も顕著な課題の一つは、小規模データセットでの性能低下です。CNNと異なり、Vision Transformerは画像の局所性や空間的な関係性に関する帰納的バイアスを持っていないため、約128万枚のImageNetのような中規模データセットでも十分な性能を発揮できません。
実際、CNNの性能を上回るためには、3億枚以上の膨大な画像データセットでの事前学習が必要とされています。
高周波成分や局所的なテクスチャの捕捉における制限
Vision Transformerは、高周波成分や局所的なテクスチャ情報の捕捉に苦心する傾向があります。
特に医療画像分析などの分野で重要な課題となっています。腫瘍や病変の検出において重要な局所的なテクスチャや微細な構造の認識に制限があることが指摘されています。
Swin Transformerなどのモデルでは、異なる解像度レベルで処理を行うことで、局所的な特徴と大域的な特徴の両方を捉える試みがなされています。
計算コストとメモリ使用量の課題
計算リソースに関する課題も無視できません。Self-Attentionの計算量は入力シーケンスの長さの二乗に比例するため、高解像度画像を処理する際には膨大な計算リソースとメモリが必要となります。
大規模なモデルを運用する場合、高性能なGPUやTPUを複数用意する必要があり、金銭的・時間的コストが大きな負担となります。
解釈可能性の問題
Vision Transformerの判断プロセスは、CNNと比較して解釈が困難です。モデルがどのような根拠で予測を行っているのかを理解することが難しく、特に重要な判断を必要とする医療診断や自動運転などの分野での応用において、この解釈可能性の低さは大きな課題となっています。
近年では、この問題に対処するための研究が進められていますが、依然として改善の余地が残されています。
関連記事:「XAIの概要からアプローチ手法、メリット、課題、活用分野を解説」
まとめ
Vision Transformerは、画像認識の新時代を切り開くAIモデルです。従来のCNNと比較して、大規模データでの高い認識精度、効率的な転移学習による導入コストの削減、そしてモデルの拡張性という明確な利点があります。
一方で、小規模データでの性能低下や高い計算コストなどの課題もあり、ビジネスへの導入には適切な判断が必要です。特に、大量の画像データを保有している企業や、高精度な画像認識を必要とする業務での活用が効果的でしょう。
自社の事業規模やデータ量、必要な認識精度を考慮したうえで、Vision Transformerの導入を検討することをお勧めします。まずは、既存の画像認識業務の課題を洗い出し、PoC(実証実験)を通じて効果検証を行うことから始めてみてはいかがでしょうか。
Vision Transformerについてよくある質問まとめ
- Vision Transformerは従来のCNNと比べてどのような点が優れているのですか?
Vision Transformerは、画像全体のグローバルな関係性を直接的に捉えることができ、大規模データセットでの学習時にCNNを上回る性能を発揮します。また、モデルの拡張性に優れており、単純にモデルサイズを大きくしても性能向上が期待できます。
使用できるデータセットの規模や計算リソース、求められる処理速度によって判断が分かれます。大規模なデータセットが利用可能で、グローバルな文脈理解が重要な場合はViTが適していますが、小規模データセットでの学習や、リアルタイム処理が必要な場合はCNNが適している可能性が高いでしょう。
- Vision Transformerのメリットは何ですか?
主なメリットは以下の3点です。
- モデルサイズを拡大しても性能向上が期待できる優れたスケーラビリティ
- 転移学習における高い性能
- 自己教師あり学習との高い相性
特に大規模データセットでの学習において、従来のCNNモデルと同等以上の性能を示しながら、学習に必要な計算コストを大幅に削減できます。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

