
AIによる画像認識とは?【2026年最新版】仕組みや画像解析との違い、種類・活用方法・注意点を徹底解説!AI Marketでの導入相談事例付き
最終更新日:2026年06月18日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

画像認識は、製造業で画像判定による品質管理の自動化、小売業での在庫最適化、セキュリティ強化など、その応用範囲が拡大していますが、特にAIを活用した画像認識のビジネス活用が急速に広がっています。
しかし、「導入コストが高そう」「自社に本当に必要なのか」「どれくらいの精度が出るの?」といった懸念をお持ちの経営者も多いのではないでしょうか。実は、AI画像認識の導入は想像以上に身近なものになっています。
この記事では、AIで画像認識を行う方法、画像解析との相違点、AIモデルの種類、活用されている分野、注意点、導入方法をわかりやすく解説します。
精度についてのよくある誤解や最新技術動向、さらには、AI Marketで実際に開発企業の紹介を行った事例についても説明していますので、画像認識AIを導入検討している方、精度を上げれずに悩んでいる方は最後までご覧ください。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
画像認識・画像解析に強いAI開発会社をご自分で選びたい場合はこちらで特集していますので併せてご覧ください。
目次
AIによる画像認識とは?

「画像認識」とは、形や色などの特徴を用いて、コンピュータが2次元(2D)または3次元(3D)画像に写るものが何であるかを認識する技術です。人間が「犬」「猫」「車」などの物体を識別する際に、特徴を学習し判断するプロセスを参考に、コンピュータが同様の認識能力を獲得することを目指しています。
そしてこの画像認識にAI技術を加えて、より高精度な画像認識を実現するのが画像認識AIです。広い概念としては、画像認識技術はコンピュータビジョン技術の一種とも言えます。
尚、動画解析においても、基本的には画像認識の技術がベースとなっています。
AIが画像を認識する仕組み
画像認識をAIで行うとは、画像から「特徴量(見た目の手がかり)」を取り出し、それを手掛かりに正解ラベルへ結びつく規則を学習させることです。
従来の画像認識は「この色なら赤」「この形なら丸」のように、人が固定ルールを作って判定していました。しかし現実の画像は、光・角度・背景・個体差で見え方が毎回変わるため、ルールがすぐ破綻します。
AI画像認識では逆に、大量の画像と正解(教師データ)を与え、ブレがあっても共通する“らしさ”が残るように、内部のパラメータを調整していきます。これが学習で、調整の仕方を決めるのがアルゴリズムです。
人間で言えば、子どもが犬を何度も見て「耳・毛・動き」などの手がかりを組み合わせて“犬っぽさ”(猫との違い、人間との違い)を覚えるのに近いです。こうして得た特徴量と規則を使って、分類(これは何か)・検出(どこにあるか)・異常(いつもと違うか)などを一貫して判断できるようになります。
VLMによる進展
近年は、分類・検出・セグメンテーションと言った従来型の画像認識に対し、VLM(Vision-Language Model)の進歩により、「画像の意味を文章で説明する」「曖昧な指示で探す(例:赤っぽい汚れ、欠け気味の角)」など、“言語で使える画像認識” が可能になっています。
そのため、現場では 従来の画像認識を検査の自動化に、VLMを一次判定・検索・要約においての人の判断を速くする住み分けが増えています。
画像解析との違いは?
実務で混乱しやすいのが「画像認識」と「画像解析」の言葉の揺れです。結論から言うと、現在は両者を厳密に分けるよりも、“目的(何を自動化したいか)”で整理する方が失敗しません。
- 画像認識(Recognition):画像から対象を見つけてラベル化する(分類・検出・セグメンテーションなど)
- 画像解析(Analysis):認識結果を使って判断・予測・最適化に繋げる(異常原因推定、歩留まり分析、需要予測、リスク検知など)
つまり、現場では 「認識=目」/「解析=脳」 の関係になりやすく、プロジェクトも「撮像→認識→解析→業務アクション」までを一気通貫で設計することが増えています。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
実際にAI Marketにいただいた画像認識のAI活用相談事例
AI Marketには、画像認識を活用した業務効率化・品質向上を目的としたAI活用相談を多くの企業からいただいております。
お客様から寄せられたご相談は以下のようなもので、AI Marketでは、コンサルタントがお客様の課題感をヒアリングし、適した技術・ソリューションを保有する企業をご紹介致しました。
- 図面・仕様書から自動見積積算を行うAIシステムの構築
- 食品工場の入場前作業(コロコロ・毛髪除去)の行動遵守チェックAI
- 配電盤のネジ締め・コネクタ接続不良のスマホ画像検知アプリ
- 液体残量の変化を画像から測定するスマートフォン解析アプリ
- 製品本体画像・型番シールからSKUを特定する画像検索・OCRシステム
※実際のお客様からのご相談内容のため、企業特定に繋がる情報は伏せています。
① 図面・仕様書から自動見積積算を行うAIシステムの構築
ご相談企業様属性
- エリア:関東
- 従業員数:1,001人〜
図面・仕様書・数量表のマルチドキュメント解析による積算自動化と3Dデータ連携|AI Marketによる要件・技術整理内容
電気通信設備の見積積算業務において、仕様書・数量表・図面・特記事項など複数のドキュメントをもとに手作業で積算を行っており、見積作成に時間がかかる点が課題となっていました。特に既存の積算パッケージでは対応できない独自記号や線情報、図面の読み取りが必要なケースが多く、自動化が進んでいない状況です。
そのため、PDF図面やCAD図面、仕様書などの非構造データを統合的に解析し、機器構成や数量を抽出した上で見積を自動生成する仕組みを希望されていました。また、3Dスキャンデータから図面を生成し、その情報を積算に連携するフローも将来的に検討されています。
カスタマイズ前提で図面意味理解まで含めた長期的な開発を視野に入れた相談となっていました。
② 食品工場の入場前作業(コロコロ・毛髪除去)の行動遵守チェックAI
ご相談企業様属性
- エリア:関東
- 従業員数:1,001人〜
人物動作認識による作業工程遵守チェックと逸脱行動検知の映像解析|AI Marketによる要件・技術整理内容
食品工場の入場時に実施するコロコロクリーナーや毛髪除去などの衛生工程について、作業が確実に実施されているかをAIカメラで確認したいという相談です。現在は監視カメラ映像を人が確認しており、確認作業に工数がかかる点や見逃しが発生する点が課題となっていました。
求められているのは、特定の作業を行っていない人物の検知や、作業時間の不足、工程逸脱などを自動で検出する仕組みです。リアルタイム解析だけでなく、録画映像の後解析にも対応し、将来的には複数工程に横展開できる行動定義の登録機能も希望されています。
また、防護服やマスク着用状態での人物識別、複数人同時入場時の動作判定など、実環境に合わせた行動認識精度が求められていました。
③ 配電盤のネジ締め・コネクタ接続不良のスマホ画像検知アプリ
ご相談企業様属性
- エリア:関東
- 従業員数:1,001人〜
スマートフォン撮影によるネジ状態判定とコネクタ接続不良の外観検査AI|AI Marketによる要件・技術整理内容
受配電キャビネット内部のネジ締め不良やコネクタ接続不良を検知するため、スマートフォンで撮影しながら点検を支援するアプリの検討相談です。配電盤内には数百点の確認箇所があり、目視点検では見落としが発生する可能性があるため、品質向上のための補助ツールとしての導入を希望されています。
固定カメラではなく作業者がスマートフォンを持って撮影し、画面上で即時判定される仕組みを想定しています。スプリングワッシャーの潰れ具合やネジの緩み、配線の抜けなど微細な状態を画像から判定し、異常箇所を提示する機能が求められています。
また図面や3Dモデル情報と連携し、点検対象箇所の抜け漏れを防止する仕組みも将来的な要望として挙げられていました。
④ 液体残量の変化を画像から測定するスマートフォン解析アプリ
ご相談企業様属性
- エリア:関東
- 従業員数:1,001人〜
容器形状変化の画像計測による液体残量推定と減少速度予測アルゴリズム|AI Marketによる要件・技術整理内容
ビニール袋状や筒状容器に入った液体の残量を、スマートフォンで定期撮影した画像から測定し、残量ゼロまでの時間を算出するアプリの開発相談です。容器は減少に伴い形状が変化するため、単純な液面検出ではなく、形状変化量から体積を推定する必要があります。
袋型容器では変形量の解析、筒状容器ではメモリ位置やピストン位置の認識など、容器タイプごとの計測ロジックが必要とされています。複数容器を同時管理し、残量低下時のアラート通知や将来的なシステム連携も視野に入れた要件です。
また正面・側面の複数画像やマーカー付与など、精度向上のための撮影条件も検討されています。
⑤ 製品本体画像・型番シールからSKUを特定する画像検索・OCRシステム
ご相談企業様属性
- エリア:関東
- 従業員数:101〜500人
類似外観識別と型番文字認識を組み合わせたSKU特定画像検索システム|AI Marketによる要件・技術整理内容
多数の製品SKUの中から、スマートフォンで撮影した本体画像や型番シール画像をもとに該当品番を特定し、部品検索システムに連携する仕組みを検討されていました。色違いやサイズ違いなど外観差異が小さい製品が多く、誤案内を避けるため高精度な特定が必要とされています。
本体画像からの類似検索だけでなく、底面シールの文字情報を読み取りSKUを特定する方法も並行して検討されています。コンシューマ向けWebサービスへのAPI連携を前提とし、撮影ガイドUIや画像トリミングなどユーザー操作を簡略化する設計も求められています。
過去製品を含む数千SKU規模での検索精度と、部品検索サイトへの自動連携が要件として挙げられていました。
AI Marketでは、上記のように、様々な企業・教育機関からのAI活用相談を受け付けています。
生成AIツールを用いて、AI企業の選定をAIに相談するケースも増えています。しかし、実際のAI導入では、機密情報の取り扱い、実装可能性の判断、企業選定など、人が介在しないと判断が難しい要素も多く存在すると考えています。
だからこそAI Marketでは、実際の人間である専門のAIコンサルタントが直接お客様と対話し、ヒアリングから企業選定までを支援し、実現性の高いAI導入をサポートしています。
貴社でもAI活用をご検討中の際は、ぜひご相談ください。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
画像認識にAIを導入するメリットは?

画像認識AIは、単なる技術トレンドではありません。貴社のビジネスを根幹から変えて、新たな成長軌道に乗せる可能性を秘めた戦略的ツールです。
主なメリットとして、以下の点が挙げられます。
- 劇的な業務効率化とコスト削減
- 製品・サービス品質の向上と安定化
- 顧客満足度(CS)の向上
これらのメリットをさらに詳しく掘り下げていきます。
業務効率化とコスト削減
多くの企業にとって、画像認識AI導入の最も直接的で分かりやすいメリットは、業務プロセスにおける圧倒的な効率化と、それに伴うコスト削減効果でしょう。
人間が行ってきた「目で見て判断する」作業は集中力や体力を要し、時間的制約も伴います。画像認識AIは、これらの定型的な視覚タスクを24時間365日、疲れ知らずで、しかも人間をはるかに超えるスピードと精度で実行できます。
これにより、以下のような効果が期待できます。
- 人件費の削減
- 生産性の向上
- ヒューマンエラーの撲滅
- 人材の最適配置
例えば、検査工程の時間が半減すれば、生産ライン全体のスピードアップに繋がります。また、不良品の流出や手戻り作業に伴う損失(時間・コスト)を大幅に削減します。
さらに、ルーティンワークから解放された従業員を、企画、開発、顧客対応といった、より高度な判断や創造性が求められるコア業務へと再配置することが可能になります。
関連記事:「画像認識AIの導入・運用費用内訳を徹底解説!ROIの考え方と向上させる方法は?」
品質向上と顧客満足度の改善
画像認識AIは、コスト削減や効率化といった「守り」の側面だけでなく、企業の生命線ともいえる「品質」の向上においても絶大な効果を発揮します。そして、その品質向上は、顧客満足度(CS)の向上という形で、明確なビジネス成果へと直結します。
例えば、製造業では人間の目では検出が困難なμm(マイクロメートル)単位の微細なキズや異物混入、色むらなどをAIが高精度で検知します。これにより、不良品率が劇的に低下し、製品品質の安定化・均質化が実現します。
結果として、クレーム削減、ブランドイメージ向上、顧客からの信頼獲得に繋がります。
新サービス創出と競争優位の獲得
画像認識AIの導入効果は、既存業務の改善だけに留まりません。むしろ、その真価は、これまでにない新しいサービスやビジネスモデルを創出し、競合他社に対する明確な優位性を確立する「攻め」の戦略において発揮されると言っても過言ではありません。
既存製品に画像認識AIを組み込むことで、その機能性や利便性を飛躍的に高め、競合製品との差別化を図ります。
例えば、店舗内のカメラ映像から顧客の動線、滞在時間、手に取った商品などを分析し、これまで把握できなかった顧客インサイトから、全く新しい商品開発やサービス事業の着想を得ることも可能です。
これらの取り組みは、単なる業務効率化とは異なり、企業の新たな収益源を生み出し、市場における独自のポジション(競争優位性)を築くための強力な武器となります。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
AIによる画像認識の種類は?

AI画像認識の種類には、以下のようなものがあります。
- 画像分類
- 物体検出
- セグメンテーション(領域検出)
- 異常検知
- 姿勢推定・動作認識
- 画像キャプション生成・視覚的質問応答
- 顔認証
- 文字認識(OCR)
- 画像検索
- 画像変化検出
それぞれの特徴について、詳しく解説します。
画像分類(シーン理解)

画像分類は、画像に写るものをカテゴリ(ラベル)として判定する技術です。さらに「シーン理解」は、個々の物体を単独で認識するだけでなく、その全体的な「環境」や「状況」をまとめて理解することを目指します。
例えば、ある画像に「多くの計器」「左右に座る制服姿の男女」「空の背景」などが写っているとします。これらの要素の組み合わせから、画像が一般的に「飛行機の操縦室」であると推定できます。
このように、画像分類・シーン理解は“画像全体の意味”を掴む入口として、多くの画像AIの土台になります。
活用されている分野
- 視覚支援(視覚障害者向け:今いる場所・状況の説明)
- ロボット工学(周辺環境の把握→行動選択)
- 自動運転・ADAS(道路状況の認識:市街地/高速/工事区間など)
- 製造業(工程状態の分類:正常/要注意、設備稼働状態の識別)
- 医療(画像所見の分類:疾患候補の一次スクリーニング)
- クマ、シカ、カラスなどの害獣検知
最新トレンド
- 自己教師あり学習(ラベルなし事前学習)の普及:大量画像から汎用特徴を学び、少量データでも強い分類性能を出しやすい(例:DINOv2)
- 画像×テキストの統合理解:テキストと画像を同じベクトル空間で扱い、分類ラベルを「文章」で柔軟に定義できる(例:CLIP)
- 軽量・高速化:エッジ端末(スマホ/工場PC/車載)で動く最適化(量子化・蒸留)が標準戦略に
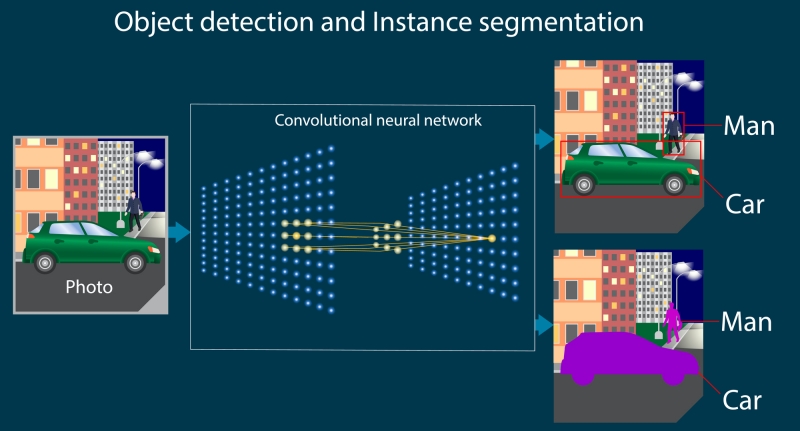
物体検出

物体検出は、「何があるか」だけでなく「どこにあるか」まで特定する技術です。主に、物体の位置を矩形(バウンディングボックス)で表します。
近年、この技術は画像検査AIによる個数カウントでも大きく進展しています。単なる検出にとどまらず、追跡(トラッキング)まで含めて“数える・追う・異常を拾う”運用が一般化しました。
またセキュリティカメラ映像では、人物検出→追跡→異常行動検出や人数カウント(人流解析)に活用されます。店舗のAIカメラでは、棚の商品やレジ通過品など、個々の物体識別にも応用されます。
現場ではYOLOのような高速なアルゴリズムが重宝される一方、より複雑なシーンでは、画像全体の関係性を捉えるVision Transformer(ViT)系の採用も増えています。
活用されている分野
- 製造業(外観検査の前段:欠陥候補の位置特定、部品カウント)
- 小売(棚割・在庫監視、レジレス、万引き抑止の補助)
- 交通(自動運転・ADAS:車両/歩行者/標識の検出)
- 建設(重機・作業員の検出、安全帯未着用の検出補助)
- セキュリティ(侵入検知、人物追跡、群衆検知)
最新トレンド
- 未知物体・オープンボキャブラリ検出:学習していない対象でも、テキスト指示で“それっぽいもの”を探す。
- 高速化×高精度の両立:リアルタイム推論と精度要求が同時に上がり、モデル選定が「FPS・精度・コスト」の三角形最適化へ
- イベントカメラ×検出:低遅延・高速移動に強いセンシングで、従来カメラの弱点を補完
Meta社のSegment Anything Model 3 (SAM 3):LLM(大規模言語モデル)を融合することで、事前の追加学習なしにテキスト指示だけで未知の物体や概念を特定できます。
セグメンテーション(領域検出)

セグメンテーションは、画像中の各ピクセルが「どの物体/背景に属するか」を分類する技術です。物体検出よりも境界が正確に取れるため、形状・面積・輪郭が重要な業務で効果を発揮します。
例えば、道路や壁面のひび割れの位置・形状の抽出、医療画像で病変部位の正確な範囲推定などに使われます。自動運転でも、道路/歩道/車線などを分離し、運転環境をより正確に理解するために用いられます。
セグメンテーションには主に以下の種類があります。
- セマンティックセグメンテーション:同種の物体を同じグループとして識別(例:車は全部「車」)
- インスタンスセグメンテーション:同種の物体でも個体ごとに分離(例:車A/車B)
活用されている分野
- 製造業(塗りムラ・欠け・傷の範囲抽出、寸法推定の補助)
- 医療(腫瘍・臓器領域の抽出、手術支援の前処理)
- 建設・インフラ(ひび割れ・腐食の範囲抽出、補修量の見積支援)
- 自動運転(道路領域・走行可能領域の推定)
- 農業(病斑領域の抽出、収穫対象の範囲推定)
最新トレンド
- プロンプトで切り抜けるFoundation Model:学習なしでも、指示やクリックで対象を切り抜く(Segment Anything系) :contentReference[oaicite:3]{index=3}
- 画像だけでなく動画セグメンテーション:連続フレームで“追い続ける”切り抜きが実務導入されやすく
- 少量データ・弱教師あり:完全アノテーションを作れない現場向けに、ラベルコスト削減が主戦場
近年では、Segment Anything Model(SAM)のように、事前学習なしにセグメンテーションを実現するモデルが登場し、非常に注目されています。
異常検知

画像認識の中でも特に活用が進んでいるのが異常検知です。これは「正常のパターン」を学習し、そこからの逸脱を検出する考え方で欠陥検出に強いアプローチです。さらに、色検査も重要な応用分野として注目されています。
製造ラインの外観検査では、従来目視で判定していた傷・汚れ・欠けなどを、画像から高精度に判別します。
また2D画像だけでなく、Lidarや3Dカメラを用いて、立体形状の異常(歪み・欠け・凹み)まで検査するケースも増えています。医療分野ではCT/MRIから異常組織の検出などにも活用されます。
活用されている分野
- 製造業(外観検査:傷・欠け・異物・汚れ・印字不良)
- 食品(異物混入、焼き色ムラ、形状不良)
- インフラ(設備点検:腐食・漏れ・ひび割れ)
- 医療(画像所見の異常候補検出)
- 物流(仕分けミス・ラベル不備・梱包不良の検知補助)
最新トレンド
- 自己教師あり異常検知:不良画像が少ない現場で、「正常だけ学習」で立ち上げやすい
- 3D/マルチモーダル検査:RGB+深度+反射などを統合して、見逃しを減らす
- 合成データ(シミュレーション)活用:不良の再現が難しい場合に、人工的に欠陥を生成して学習補助
姿勢推定・動作認識
姿勢推定は、主に人物画像から骨格・関節の位置(キーポイント)を特定し、人物がどのような姿勢・動きをしているかを推定する技術です。代表的なライブラリとして以下があります。
- OpenPose:定番ライブラリで、関節を「点」で結ぶ
- Meta SAM 3D Body:人体全体を3Dメッシュとして復元し、ひねりや隠れ部位の推論が強い
プロスポーツ選手のフォーム解析、工場スタッフの動線・作業姿勢の改善など「人の動き」を数値化したい領域で強力です。
活用されている分野
- スポーツ(フォーム解析、怪我予防、戦術分析)
- 製造・物流(作業姿勢の改善、安全動作の監視)
- 自動車(居眠り・脇見・急病兆候などの検知補助)
- 介護・医療(転倒検知、リハビリ動作評価)
- エンタメ(モーションキャプチャ、AR/VR)
最新トレンド
- 2D→3D姿勢推定:単眼カメラからでも立体姿勢を推定し、実務精度が上がっている
- 全身+手指+顔の統合推定:接客・作業分析など“細かい動き”が重要な領域に拡張
- プライバシー配慮:顔を特定せず「骨格だけ」で解析する要件が増加
画像キャプション生成・視覚的質問応答

画像キャプション生成は、画像を説明する文章を自動生成する技術です。画像に写る物体だけでなく、状態・行動・関係性まで文章化できます。
また、画像に関する質問に答えるVisual Question Answering(VQA)も同系統で、画像×言語の相互理解を深めます。
視覚障害者支援アプリでは、写真を撮るだけで内容を音声で説明できます。SNSやECでは、自動生成キャプションを検索・整理に活用できます。
この領域では、VLM(Vision-Language Model)が中核技術として急速に普及しています。
活用されている分野
- アクセシビリティ(画像内容の読み上げ・説明)
- EC/メディア(画像の自動タグ付け・検索性向上)
- カスタマーサポート(写真付き問い合わせの内容理解)
- 製造・点検(現場写真の要約、異常候補の言語化)
- 教育(教材画像の説明・QA)
最新トレンド
- マルチモーダルLLMの実務利用:画像→要約→指示生成までを一気通貫で処理できる
- 「見る」だけでなく「根拠を示す」:どの領域を見て答えたかを可視化し、誤答リスクを抑える動き
- 社内ナレッジ連携:画像理解結果をRAGで補強し、業務ルールや部品DBと結合して回答精度を上げる
こちらではAIによる画像生成技術の基礎知識・活用方法を詳しく説明しています。
顔認証
顔認証は、顔の特徴を数値化し、個人を特定・照合する技術です。セキュリティゲートやスマートフォンのロック解除など、本人確認のUXを大きく変えました。
活用されている分野
- 入退室管理(オフィス・工場・研究施設)
- 本人認証(スマホ・決済・会員サービス)
- 監視・防犯(要注意人物の検知補助)
- 空港・施設(搭乗・入場のスムーズ化)
最新トレンド
- なりすまし対策(Liveness):写真・動画・マスクによる突破を防ぐ判定が重要に
- オンデバイス化:クラウド送信せず端末内処理で完結し、プライバシー要件に対応
- 規制・社会受容性への配慮:導入前に目的・範囲・保存期間の設計が必須
文字認識(AI-OCR)
文字認識は、印刷文字や手書き文字を識別し、画像内の文字をテキストに変換する技術です。従来OCRにAIが加わり、AI-OCRとして精度が大きく改善しました。
AI-OCRは、データ入力自動化、郵便物仕分け、チェック(マーク)読み取り、図面読み取りなどで活躍します。
近年は生成AI連携により、読み取った文字列を「日付」「金額」などの項目として理解・整形する運用が現実的になっています。
活用されている分野
- 経理・会計(領収書/請求書の入力自動化)
- 金融(本人確認書類、申込書のデータ化)
- 物流(伝票、ラベル読み取り、仕分け)
- 製造(検査成績書、帳票、図面のデジタル化)
- 医療(紹介状・問診票のデータ化)
最新トレンド
- ドキュメント理解(レイアウト解析):文字だけでなく「表」「見出し」「項目構造」まで捉える
- 生成AIで後処理:OCR結果の揺れを正規化し、項目抽出・名寄せ・チェックまで自動化
- 手書き対応の高度化:現場帳票・医療書類など“崩れた文字”に適用範囲が広がる
画像検索
画像検索(Image Retrieval)は、大量の画像データベースから類似画像を検索・取得する技術です。テキスト検索だけでは説明しづらい「見た目が近い」を直接探せる点が強みです。
一般的には、画像から色・形状・テクスチャなどの特徴を抽出し、CNNやTransformerで高次元ベクトルに変換します。ベクトル検索により類似度を計算し、関連性の高い画像をランキング表示します。
活用されている分野
- EC(画像から類似商品検索、コーデ提案)
- 製造(類似不良の検索、過去事例参照)
- メディア(写真整理、重複検出、素材管理)
- 医療(類似症例検索、参考画像検索)
- セキュリティ(特定人物・車両に類似する映像の探索)
最新トレンド
- テキストでも画像でも検索できる:CLIP系の埋め込みで「文章→画像検索」が実用に :contentReference[oaicite:5]{index=5}
- ベクトルDBが標準インフラ化:画像特徴をDBに保存し、検索を業務機能として組み込みやすい
- RAG(検索拡張生成)との連携:検索で拾った画像を根拠に、説明文・レポート生成まで自動化
画像変化検出
画像変化検出は、同一の場所や対象を異なる時点で撮影した画像を比較し、変化を検出する技術です。単発画像の理解ではなく、時間変化という文脈まで扱うのが特徴です。
例えば建設現場の定点カメラでは、建物形状の変化や資材移動などを検出し、進捗管理・安全管理の精度を上げられます。
活用されている分野
- 建設(進捗管理、資材移動検知、安全管理)
- インフラ(橋梁・道路の経時劣化監視)
- 防災(浸水・土砂崩れ・倒壊の把握)
- 農業(生育差・病害の早期検知)
- 製造(工程前後の差分検査、組付けミス検知)
最新トレンド
- 動画・連続画像の解析:1回の差分ではなく、時系列として「傾向の変化」を捉える
- 衛星・ドローン画像との統合:広域監視+現場の定点監視を組み合わせ、運用価値が上がる
- 異常検知との融合:変化=異常とは限らないため、業務ルール(正常変化)を取り込む設計が増える
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
画像認識に使われるAIモデル・アーキテクチャは?
ディープラーニング(深層学習)の活用が、画像認識分野でのAI活用を一気に推し進めたと言っても過言ではありません。特に以下技術が現在の画像認識AIで重要なモデルです。
- CNN系(畳み込みニューラルネットワーク)
- YOLO
- GAN
- EfficientNet
- Vision Transformer(ViT)
- マルチモーダルモデル
CNN系(畳み込みニューラルネットワーク):ディープラーニングの画像認識特化モデル
ディープラーニングのなかでも、特にCNN(畳み込みニューラルネットワーク)は、画像のピクセルデータをそのまま利用し、人間が手動で特徴を選択することなく、自動的に画像の特徴を学習します。
代表的なCNNアーキテクチャには以下があります。
ResNet
ResNetは2015年に提案された深層CNNアーキテクチャで、スキップ接続を導入することで非常に深いネットワークの学習を可能にしました。
2020年に提案されたResNeStでは、分割注意メカニズムを導入したアーキテクチャで、より高い精度を達成しています。さらに2021年にGoogleが発表した改良版ResNet-RSでは、より効率的なトレーニングと推論を実現しています。
VGG
VGGは2014年に提案されたシンプルで均一なアーキテクチャです。VGG-19 with Batch Normalizationではバッチ正規化を導入し、学習の安定性と速度を向上させました。
さらに、VGG-16 with Squeeze-and-Excitationでは、チャネル間の相互依存関係をモデル化し、性能を向上させています。
Faster R-CNN
Faster R-CNNは2015年に提案された高精度な物体検出モデルです。Faster R-CNNの中核はCNNによる特徴抽出です。バックボーンネットワークとして、ResNetやVGGなどの事前学習済みCNNを使用します。
R-CNN、Fast R-CNN、Faster R-CNNと進化する中で、CNNの特性を活かしながら効率化と精度向上を実現しています。
U-Net
U-Netは、U字型のエンコーダ・デコーダ構造を用いることで、少量のデータでも高精度かつリアルタイムに処理が可能です。医療画像診断や自動運転、製造業の品質管理など幅広い分野で活用されています。
UNet++やTransformerを組み合わせたTransUNetなどのモデルも提案され、効率化と精度向上が進んでいます。
YOLO
YOLO (You Only Look Once)は物体検出に特化したモデルで、リアルタイム処理に適しています。YOLOは物体検出の実務で特に採用が多いシリーズで、現場の要件(速度・精度・推論コスト)に合わせて世代更新が早いのが特徴です。
近年もUltralyticsから YOLOv10(2024)、YOLO11(2024) など改良版が継続的に登場しており、「YOLO=高速検出の定番」という位置付けは変わりません。
一方で、2023年以降、CLIPやGeminiのようなマルチモーダル化したLLM(大規模言語モデル)を活用してこれまでよりもより簡単に画像認識を行う、ということもできるようになってきています。
要件によってはViT系やマルチモーダル系が優位になることもあるため、“何を検出し、どの速度で、誤検知/見逃しのどちらを許容するか” で選定するのが失敗しないコツです。
GAN
GANは2014年に提案された生成モデルです。生成器と識別器の2つのネットワークを競争させることで学習を行います。
高品質な画像生成が可能ですが、学習の不安定性が課題として残っています。
GAN関連記事:「敵対的生成ネットワーク(GAN)とは?Diffusionとの違いは?画像生成の仕組みや特徴を徹底解説!」
EfficientNet
EfficientNetは2019年にGoogleの研究者によって提案された、画像分類のためのCNNアーキテクチャです。複合スケーリング手法を用いてネットワークの幅、深さ、解像度を同時に最適化します。
少ないパラメータ数で高い精度を達成しており、モバイルデバイスへの導入に適しています。
関連記事:「EfficientNetとは?画像分類モデルとしての特徴・活用法を徹底解説!」
Vision Transformer(ViT)
最近では、CNNに加えて、2020年にGoogleから発表されたVision Transformer(ViT)が注目されています。ViTは、自然言語処理で広く用いられているTransformerモデルを基に、画像認識タスクに応用したものです。
ViTでは、画像を小さなパッチに分割し、それぞれのパッチをTransformerの入力として扱います。この方法により、画像内の異なる部分間の関係をより深く理解することができ、特に大規模な画像データセットを用いたタスクにおいて高い性能を発揮します。
関連記事:「Vision Transformer(ViT)とは?仕組み・CNNとの違い・メリット・限界を徹底解説!」
マルチモーダルモデル
マルチモーダルモデルは、画像、テキスト、音声など複数の形式のデータを統合的に扱うAIモデルです。複数のデータ形式を同時に処理し、相互の関係性を学習します。
以下のようなモデルが発表されています。
AI画像認識の業界別活用方法は?
AIを用いた画像認識の活用方法を業種ごとに説明します。こちらでAI画像認識の活用事例をさらに詳しく説明しています。
製造業
| 活用方法 | 活用方法の説明 |
|---|---|
| 不良品の検知(外観検査) | 製造ラインにおいて、製品の外観を分析し、傷や変形などの不良を自動的に検出 ディープラーニング(深層学習)やコンピュータビジョンなどの画像認識AIを活用して、製品や部品の外観を自動的に検査 微細加工の検査 |
| 設備劣化の判定(予知保全) | 工場内の機械設備や生産ラインの状態を監視し、劣化や異常を早期に検出 |
| 図面の読み取りと管理 | 図面データベースから必要とする図面を迅速かつ高精度で検索する |
| 設計作業の支援 | CADにAIを統合することで、設計プロセスを自動化できるほか、データの解析やパターン認識を通じて設計提案 |
| 作業分析 | 作業手順を分析し、無駄な動作をなくして生産性を向上 |
| 部品の識別や検索業務 | 類似画像検索システムを導入することで、外観が類似した部品を瞬時に特定でき、在庫管理や調達業務の負担を軽減 |
| 倉庫でのピッキング | ビンピッキング:部品や製品などが無造作に入れられた容器(ビン)から、必要な対象物をロボットが取り出す工程の自動化 |
関連記事:「製造業での画像認識AI導入事例は?効果や活用事例を徹底解説!」
自動車・交通
| 活用方法 | 活用方法の説明 |
|---|---|
| 自動運転支援 | 車載カメラからの映像をリアルタイムで分析し、道路状況、他の車両、歩行者などを認識 ※オプティカルフロー技術やセンサーフュージョン技術も活用 |
| 横断歩道の検出 | 地図データとを組み合わせて横断歩道を正確に検出し、歩行者の安全確保に貢献 |
| 設計作業の支援 | CADにAIを統合することで、設計プロセスを自動化できるほか、データの解析やパターン認識を通じて設計提案 |
Eコマース・小売
| 活用方法 | 活用方法の説明 |
|---|---|
| 顧客の視線解析(アイトラッキング) | 顧客が商品棚のどこを見ているか、どのように見ているか等を分析 |
| 購買行動分析 | 顧客行動分析やパーソナライズされた商品レコメンデーション、ビジュアル検索機能の提供 |
| ビジュアル検索機能 | 参考画像をアップロードするだけで視覚的に近い商品を類似画像検索 |
| 真贋判定 | 対象となる製品や情報が本物であるか、それとも偽物・模造品であるかを見極める |
関連記事:「小売業・スーパーのAI活用事例12選!メリット・需要予測・マーケティング・流通の課題を解決」
関連記事:「EC業界でのAI活用方法は?メリットや注意点、活用事例を徹底解説!」
流通・物流
| 活用方法 | 活用方法の説明 |
|---|---|
| 在庫管理 | 店舗の棚やバックヤードの画像を分析し、商品の在庫状況をリアルタイムで把握 |
| 荷崩れ防止 | トラックなどに積載された荷物の荷姿を画像認識して輸送中の荷崩れを防止する |
| 通関書類処理 | 多様なフォーマットや言語で記載された品名、数量、金額、契約条件などを高精度に読み取り、システムへ自動入力 |
関連記事:「物流業界向けAI導入・活用事例!メリットや課題、倉庫・配送・検品管理向けサービス」
IT・ソフトウェア
| 活用方法 | 活用方法の説明 |
|---|---|
| バーチャルヒューマン | 生成AI(ジェネレーティブAI)を組み合わせて、リアルな外見と動きを持つバーチャルヒューマンを作成 |
セキュリティ
| 活用方法 | 活用方法の説明 |
|---|---|
| 生体認証 | 顔認識や虹彩認識などの生体情報を分析し、個人を特定 |
| 防犯カメラ | 危険エリアや進入禁止エリアなどへの侵入検知や不審行動検知 |
建設・インフラ・公共事業
| 活用方法 | 活用方法の説明 |
|---|---|
| インフラ点検 | ドローンで撮影した橋梁や建築物の画像を分析し、ひび割れや腐食を検出 |
| 安全管理 |
|
| 非破壊検査 | 水道管やガス管の内部を撮影した画像を分析し、腐食や亀裂などの異常を検出 |
| 図面の読み取りと管理 | 図面データベースから必要とする図面を迅速かつ高精度で検索する |
| 設計作業の支援 | CADにAIを統合することで、設計プロセスを自動化できるほか、データの解析やパターン認識を通じて設計提案 |
| 排水処理 | 排水処理の遠隔化 |
| 水質検査 | 水中に含まれる化学物質や微生物の濃度などを測定し、水の安全性・衛生状態を評価する |
| 防災 | 治水監視 |
関連記事:「建設業におけるAIの活用と導入について、最新の開発状況と具体的な用途」
環境保護
| 活用方法 | 活用方法の説明 |
|---|---|
| 生態系モニタリング |
スポーツ
| 活用方法 | 活用方法の説明 |
|---|---|
| パフォーマンス分析 | 選手の動作を高精度カメラで撮影し、姿勢、スピード、角度などを詳細に分析。フォームの改善点や怪我のリスクを特定し、トレーニング計画の最適化に活用。 |
| 戦術分析 | 試合映像から選手の動きのパターン、ポジショニング、チーム全体の戦術的傾向を自動で分析。対戦相手の特徴や弱点を把握し、効果的な戦術立案に活用。 |
| 審判の判定支援 | 高速カメラと組み合わせて、人間の目では判断が難しい接近したプレーや瞬間的な事象を正確に判定 |
関連記事:「スポーツとAIの融合で可能になる未来と事例、メリット・デメリットを紹介」
文化財保護・芸術
| 活用方法 | 活用方法の説明 |
|---|---|
| 文化財管理 | 美術品の真贋判定や文化財の劣化状態モニタリング |
教育
| 活用方法 | 活用方法の説明 |
|---|---|
| 学習支援 | 学習者の表情・姿勢分析による集中度の測定や手書き文字の認識による採点支援 |
関連記事:「教育業界に強いプロ厳選AI開発会社」
農業
| 活用方法 | 活用方法の説明 |
|---|---|
| 作物管理 | ドローンや衛星画像を用いた作物の生育状況モニタリング、病害虫の早期発見 |
関連記事:「農業にAIを導入することに対するメリット/デメリットや、具体的な活用事例」
医療・介護
| 活用方法 | 活用方法の説明 |
|---|---|
| 画像診断支援 | X線やMRI画像の分析による腫瘍や異常の検出、皮膚がんの早期発見 |
| 患者モニタリングシステム | 患者のバイタルサインや身体活動などの情報をリアルタイムで把握し、異常の早期発見や治療判断を支援 |
| 転倒検知 | 画像認識AIの活用により、利用者にデバイスを装着させることなく転倒を自動検知 |
関連記事:「医療・製薬業界に強いプロ厳選おすすめAI開発会社」
エンターテインメント・メディア
| 活用方法 | 活用方法の説明 |
|---|---|
| コンテンツの自動タグ付けと分類 | 動画や画像コンテンツ内の人物、物体、シーン、感情表現などを自動で認識し、適切なタグを付与 |
| 著作権侵害コンテンツの検出 | 画像・動画の特徴を分析し、著作権で保護されたコンテンツの無断使用や改変を自動的に検出 |
| 視聴者の感情分析 | 視聴者の表情や反応をリアルタイムで分析し、感情の変化を追跡 |
| バーチャルキャラクターの生成 | 生成AIを組み合わせて、リアルタイムでの表情変化や自然な動きを持つバーチャルキャラクターを作成 |
関連記事:「テレビ・ラジオ業界のAI活用方法は?メディアでの活用事例・導入事例」
企業でAIによる画像認識を導入する手順は?

画像認識モデル導入の基本的なステップは以下です。最近主流になっているディープラーニングを活用した画像認識で説明しています。
それぞれのステップは、目的とする認識タスクによって細部は異なる可能性がありますが、基本的な流れは共通しています。この一連の流れを理解し、適切に実行することで、高性能な画像認識モデルの導入が可能となります。
それぞれのステップについて説明します。
関連記事:「AI開発の手順は?AIシステム構築の流れを徹底解説!失敗しない為の注意点もわかる完全ガイド」
導入する目的と必要な精度を明確にする
画像認識モデルの導入を計画する最初のステップは、その目的と必要な認識精度を明確にすることです。
自動運転や医療画像診断など人命に関わる目的であれば、高い精度が求められます。逆に、一部の書類の文字認識などに用いる場合は、ある程度の精度が担保されていれば、コストを抑える方向性もあります。
精度に関しては、社内でも以下のような誤解が広まらないように正しいスタンスを周知することが重要です。
| 精度に関するよくある誤解 | 正しい見解 |
|---|---|
| 画像認識AIは常に100%正確である | 画像認識AIの精度は様々な要因によって変動します。最新の画像認識アルゴリズムでも、条件によっては誤認識が発生する可能性があります。 例えば、近年顔認識ソフトウェアの精度は大幅に向上しました。それでも失敗率は0.2%であり、完璧な精度を達成することは現実的ではありません。 |
| 画像認識AIは人間よりも常に劣っている | 特定のタスクにおいては、AIが人間の能力を上回ることがあります。 |
| 画像認識の精度は単一の数値で表すことができる | 画像認識の精度は、使用例や設定された閾値によって大きく変わります。例えば、法執行機関の使用では高い精度閾値が設定されますが、エンターテイメント目的では低い閾値でも十分な場合があります。 |
導入目的によって必要な精度は変動するため、この段階で具体的な目標を設定することが重要です。
画像認識ソリューションの選び方
画像認識技術の導入方法としては、クラウドサービス、オープンソース、カスタム開発など複数のアプローチが存在します。
自社の目的やリソース、必要な柔軟性に応じて最適なソリューションを選ぶために、以下の表を参考にしてください。
| ソリューション | 手法 | メリット | ポイント |
|---|---|---|---|
| クラウドサービス | 既存の画像認識API(例:Google Cloud Vision、AWS Rekognition、Azure AI Vision等)を利用 | 短期間で導入可能、初期投資が少なく済む | 迅速に導入したい場合。最新の技術更新が自動的に反映される点も魅力だが、カスタマイズ性が低い場合も多い。精度向上が難しい。 |
| オープンソース | Tensorflow、PyTorch、OpenCVなど、無料で利用できるライブラリの活用 | 柔軟性が高く、コミュニティでのサポートが豊富 | 自社で技術開発が可能な場合や、カスタマイズ性を重視する企業。ライセンスや保守、セキュリティ面の検討が必要。 |
| カスタム開発 | 自社または専門開発会社と協力して、ゼロから開発 | 業務ニーズに最適化された専用ソリューションが構築できる | 特定の業務要件や高い精度・独自機能が必要な場合。初期投資や開発期間が長くなるが、長期的には競争優位性を確立できる可能性が高い。 |
データ収集
画像認識モデルの学習を行うには、大量の画像データの収集が必須となります。このデータはモデルが世界を理解するための基盤となります。
データの収集方法は主に以下の2つに分かれます。
- 公開データセットの利用:CIFAR-10、ImageNet、COCO等の既存のデータセットを活用
- 独自データの収集:自社製品や特定の対象物の画像を収集
ただし、ただ多くのデータを集めるだけではなく、「質」も重要です。集めた画像データが偏りがあったり、目的とするタスクに適していないと、学習したモデルの性能が低下します。
関連記事:「AI学習用のデータ収集代行会社プロ厳選おすすめ」
データの加工
画像データの前処理は、モデルの学習効率と精度向上に重要です。以下のような処理を行います:
- リサイズ:すべての画像を同じサイズにリサイズ
- 正規化:ピクセル値を0-1の範囲に正規化
- データ拡張:回転、反転、ズーム等の変換を適用
ディープラーニングモデルの定義
データ収集と加工が終わったら、次にディープラーニングモデルの定義を行います。使用するフレームワーク(例えば、TensorflowやKerasなど)により、畳み込みニューラルネットワーク(CNN)などのモデルを設計し、学習データを利用してモデルの学習と評価を行います。
Pythonを使用したAI画像認識
AIによる画像認識の導入でよく用いられるプログラミング言語としてPythonがあります。Pythonの特徴としては、簡潔なコードでプログラムを書けることや、豊富なライブラリが存在することが挙げられます。
これにより、Pythonは多くの開発者にとって書きやすく、また読みやすいプログラミング言語となっています。
画像認識のために必要なデータの前処理、特徴抽出、モデルの訓練と評価などの一連の流れを、Pythonの各種ライブラリを活用して比較的簡単に実現できます。例えば、OpenCVやPillowで画像の読み込みや前処理を行い、scikit-learnやTensorFlow、Kerasを用いて画像認識のためのモデルを構築・訓練可能です。
Pythonには、CNNやGANといった高度な画像認識手法をサポートするライブラリも含まれており、これによりディープラーニングを用いた画像認識が容易になります。
関連記事:「PythonがAI開発で使われるのはなぜ?理由・メリット・デメリット・活用例を徹底解説!」
PoC(概念実証)の実施
十分なデータの用意が整ったら、小規模なPoC(Proof of Concept:概念実証)を行います。これは本格導入前にAIが自社課題を解決できるかを試す実験段階です。
限られた範囲でプロトタイプの画像認識モデルを構築し、例えば「工場ラインの一工程だけで不良検知AIを試す」「店舗の一部商品カテゴリで欠品検知を試行する」といった具合に実施します。
PoCの目的は技術的実現性の確認だけでなく、得られる効果の測定と課題の洗い出しです。結果をもとに精度が目標に達しているか、処理速度や現場との相性に問題はないかを評価します。
もし結果が思わしくなければ、この段階でモデルの改善(追加データ学習やパラメータ調整)やアプローチの見直しを行います。経営層に対しては、PoCフェーズで早期にリスクを検知・対応することで、無駄な投資を抑えつつ成功率を上げるステップであることを説明します。
成功したPoCは社内のAI導入機運を高める材料にもなるため、小さく成功体験を積むことの重要性も強調します。
実装・検証
モデルの学習が完了したら、実際にそれを使用して画像認識を試みます。画像データを学習用とテスト用に分け、テスト用データを用いてモデルの性能を検証します。
その結果を基に、モデルの改善点を明らかにし、必要に応じて調整を行います。
- テストデータでの評価:精度、適合率、再現率等の指標を確認
- 過学習の確認:訓練データと検証データでの性能比較
- ハイパーパラメータの調整:学習率、バッチサイズ、層の数等を最適化
- モデルのファインチューニング:転移学習を適用し、特定のタスクに適応
継続改善
モデルの評価と調整を行った後は、再度学習を行い、その結果を元にモデルを改善していきます。このプロセスを繰り返すことで、徐々にモデルの性能を向上させていくことが可能になります。
AI画像認識を活用する際の注意点

AI画像認識を活用する際の注意点は以下です。
| 注意点 | 概要説明 |
|---|---|
| データの量とクオリティ | 高精度な認識には大量の画像データ(数十万〜数百万点)が必要 データのクレンジングも重要だが、時間とコストがかかる。 |
| コンセプトドリフト | 照明・カメラ・製品仕様・背景が変わると精度が落ちる 監視指標(不良率/再検査率)と再学習ルールを最初から決める |
| 撮影環境の整備 | カメラの質や設置位置が重要。適切な撮影環境を整えないと、精度が低下する可能性がある。 |
| 情報セキュリティとプライバシー | 個人情報保護や肖像権に配慮が必要 適切なセキュリティ対策が求められる。 |
| 機能の適切な選択 | 自社ビジネスに必要な機能を把握し、適切なAI画像認識を選択することが重要。 |
| 学習期間の確保 | 1,000〜10,000枚以上の画像で初期学習を行い、継続的な学習とアップデートが必要。 |
| 誤認識の可能性 | 完全に誤認識を排除することは難しく、対策が必要。 |
| ブラックボックス問題 | AIの判断根拠が不明確な場合、結果の信頼性が問われる 説明可能AIの開発が進んでいる。 |
| 再学習時の品質管理 | 新たなデータ学習時に以前の学習内容を忘れる現象 |
| バイアスの問題 | 学習データや設計者のバイアスにより、AIの判断に偏見や差別が含まれる可能性がある。 |
| 説明可能性の確保 | AIの判断プロセスを人間が理解・説明できるようにする必要がある。 |
| プライバシー侵害のリスク | 個人情報の目的外利用や漏洩のリスクがあり、適切な管理が必要。エッジAIの活用も検討される。 |
注意点を踏まえて、画像認識においてAIが得意とすること、不得意とすること、現状の課題に対する解決策をこちらの記事で解説しています。
画像認識AIの導入で押さえるべき法令・ガバナンス
画像認識は、対象によっては個人情報・生体情報・監視に該当し、技術より先に運用ルールが必要になります。
日本(個人情報保護法/APPI)では、顔などの身体的特徴をデータ化したものは「個人識別符号」に該当し得ます。つまり「映っている」だけでなく、照合可能な形で扱う時点で管理水準が上がると考えるのが安全です。
EU AI Actでは、用途によっては「禁止」または「高リスク」に分類され、透明性・リスク管理・記録・人の監督などが強く求められます。特に生体認証や公共空間の監視は要注意領域です。
企業としては、法令対応を“現場で回る形”にするために、最低限次を決めておくと導入がスムーズです。
- 目的:何のために撮り、何を判定し、誰が使うか
- 保管:保存期間、アクセス権、匿名化/マスキング
- 監督:誤判定時の人手レビュー手順
- ログ:いつ、何を、どう判定したか(監査可能性)
さらに、AIガバナンスを社内制度として整えるなら ISO/IEC 42001(AIマネジメントシステム) を参照すると、属人的な運用から抜けやすくなります。
画像認識の歴史:ディープラーニングから生成AIへ
パターン照合の時代
画像認識の原理は、初期にはバーコードやテンプレートマッチングといったシンプルな手法に基づいていました。これらの技術は、限られた条件下でのパターン照合により、画像中の特定の情報を抽出するもので、複雑なシーンや多様な物体を正確に識別することは困難でした。
その後、コンピュータの処理能力向上と共に、機械学習や統計的手法が取り入れられるようになり、画像認識の精度は徐々に改善されました。
AI、そしてディープラーニングの時代
そして、いわゆる「AI」であるディープラーニング、特に畳み込みニューラルネットワーク(CNN)の登場により、画像認識技術は飛躍的に進化しました。結果、2012年頃から画像認識コンテスト(ImageNetなど)でAIの性能が飛躍し、人間の認識精度を上回るケースも現れました。
例えば、かつては困難だった写真中の複数物体の同時検出や、手書き文字の高精度認識が可能になり、様々な産業で実用化の動きが加速しました。
生成AIが画像認識にも変革を起こしている
近年の画像認識は「ディープラーニング」からさらに進み、“視覚の基盤モデル(Vision Foundation Model)” が実務に入り始めています。
生成AIの発展により、画像認識AIは新たな局面を迎えています。代表例は、ラベル付き教師データを大量に用意しなくても汎用表現を獲得できる 自己教師あり学習(Self-supervised Learning) や、画像×言語を同時に理解できるVLM(Vision-Language Model)の台頭です。
ChatGPTに代表されるLLM(大規模言語モデル)と画像認識モデルを組み合わせることで、画像の内容をより深く理解し、自然言語で説明することが可能になっています。例えば、OpenAIのCLIPやMetaのImageBindなどのモデルはテキストと画像の埋め込みを組み合わせた転移学習を行っています。
ChatGPT上での画像認識も可能になっており、単に「犬/猫を当てる」から、“何が起きているかを言語で説明し、次アクションまで提案する” 方向へ拡張しました。
さらに、Metaが発表した Segment Anything(SAM)の後継であるSAM 3など は、画像だけでなく動画も含めた“汎用セグメンテーション”を強化しており、現場のアノテーション負荷を減らす方向でも注目されています。
マルチモーダルでますます拡張
マルチモーダルAIの発展により、画像認識AIは、画像だけでなく異なるデータとの統合による高度な理解が可能になります。画像、テキスト、音声など様々なモダリティを組み合わせることで、人間に近い知覚・認知能力を持つAIの実現が期待されます。
画像認識に特化したモデルよりも精度高く認識することはまだできませんが、マーケティング分野などでは今後活用されることが想定されます。
また、画像認識と音声処理を融合することで、以下に挙げる技術への応用が可能になります。
- 音声と口の動きから発話を認識するAudio-Visual Speech Recognition(AVSR)
- 画像と音声から音源位置を特定するSound Source Localization(SSL)
- 音声から話者の顔の動きを生成するTalking Face Generation
今後、画像認識技術はさらに他のAI分野と融合し、新たな応用分野を切り開いていくでしょう。
関連記事:「AIによる音声認識の仕組みとは?何ができる?技術や企業の活用事例を徹底解説!」
最新の画像認識技術動向

画像認識の精度と適用範囲を大きく広げる可能性を秘めている技術を紹介します。また、自然言語処理など他のAI分野との融合により、マルチモーダルな理解も可能になってきています。
一方で、実世界への応用には、データの収集やアノテーション、モデルの解釈性など、まだ多くの課題が残されています。今後のさらなる研究と発展が期待されます。
画像認識とロボティクスの融合
画像認識技術は、ロボティクスの分野でも欠かせない要素です。画像認識は以下分野でロボットの知覚・認知能力の向上に大きく貢献します。
- 物体認識を用いたロボットマニピュレーション
- 環境理解に基づくロボットナビゲーション
- 人とロボットのインタラクションにおける視覚情報の活用
特に、Metaのスマートグラス「Aria Gen 2」などを活用し、人間が見ている世界や手の動きを一人称視点でデータ化することで、ロボットが人間の行動を模倣したり、意図を汲み取ったりする研究が加速しています。
Few-shot Learning
Few-shot Learning は、少量のデータから効果的に学習するための手法です。従来の機械学習では大量のデータを必要としましたが、Few-shot Learning ではメタ学習の考え方を取り入れ、わずかな例から新しいクラスを認識できるようにします。
この手法を用いることで、データが少ない場合でも高精度な画像認識が可能になります。
関連記事:「Few Shot Learning入門:ファインチューニングとの違いは?どんな分野で使う?失敗しない注意点を解説」
Zero-shot Learning
Zero-shot Learning は、学習時に一度も見たことがないクラスを認識する手法です。属性情報や言語情報を利用して、未知のクラスに対する認識能力を獲得します。
例えば、「黄色くて長い」という属性情報から「バナナ」を認識するような場合に用いられます。Zero-shot Learning により、画像認識の適用範囲が大きく広がることが期待されます。
Zero-shot Learningの仕組み、活用事例をこちらの記事で詳しく説明していますので併せてご覧ください。
自己教師あり学習(Self-supervised Learning)の進化
自己教師あり学習(SSL:Self-supervised Learning)は、教師なし学習の1つで特徴表現を学習する手法です。画像の一部を隠して復元させたり、画像の変換に対して不変な特徴を学習させたりすることで、ラベルのない大量の画像データから汎用的な特徴表現を獲得します。
事前学習モデルを用いることで、少量のデータでも高精度な画像認識が可能になります。
エッジデバイスでの展開
転移学習を活用することで、計算リソースの限られたエッジデバイスでも高度な画像認識が可能になっています。軽量化されたモデルを事前学習し、エッジデバイス上で特定のタスクにファインチューニングすることで、リアルタイムの画像認識を実現しています。
例えば、医療画像分析において、一般的な画像データセットで事前学習したモデルを転用する手法が注目されています。ImageNetなどの大規模データセットで学習した特徴抽出器を、X線画像やMRI画像の分析タスクに転用することで、限られた医療画像データでもリアルタイムで高精度な診断支援が可能になっています。
画像認識におけるデータセットについては、こちらで詳しく解説しています。
画像認識についてよくある質問まとめ
- 画像認識とは?画像解析との違いは?
「画像認識」は、形や色などの特徴を用いて、コンピュータが画像に写るものが何であるかを認識する技術です。スマートフォンの顔認証システムで顔を特定すること、自動車の自動運転システムで道路上の物体を検知すること、製造ラインでの異常検知システムによる不良品の発見など、幅広い産業でその効果を発揮しています。
一方、画像解析とは、コンピューターを使って画像データから有用な情報を抽出し、分析・判断する技術です。近年はAIの活用により画像の認識から解析を一連で行うようになり、両者の垣根は低くなっています。
- AI画像認識を導入することで、どのように競合他社と差別化を図れますか?
AI画像認識の戦略的導入により、以下のような差別化が可能です:
- 業務効率の飛躍的向上 • リアルタイムの品質管理による製品品質の向上 • 需要予測精度の向上による在庫最適化
- カスタマーエクスペリエンスの革新 • パーソナライズされた商品レコメンデーション • VR/ARを活用した新しい購買体験の提供
- 新規ビジネスモデルの創出 • 画像データを活用した新サービスの開発 • 予測保守サービスの提供による収益源の多様化
- コンプライアンスと安全性の強化 • 高精度な不正検知システムの構築 • 作業現場の安全性向上
- AI画像認識の導入プロセスはどのようなものですか?社内にAI専門家がいない場合でも導入は可能でしょうか?
AI画像認識の一般的な導入プロセスは以下の通りです:
- ビジネス課題の特定と目標設定
- データの収集と前処理
- AI モデルの選択または開発
- システム統合とテスト
- 社内トレーニングと運用開始
- 継続的な監視と改善
社内にAI専門家がいなくても、以下のアプローチで導入が可能です:
- クラウドAIサービス(AWS Rekognition, Google Cloud Vision等)の活用
- AIベンダーやコンサルティング企業とのパートナーシップ
- 段階的な導入とスキル育成の並行実施
- AI Marketでは、画像認識に関するどのような相談ができますか?
はい、記事でご紹介した研究機関の事例のように、具体的な課題をお持ちの企業様から多くのご相談をいただいています。
ご相談例(研究機関様):
課題: 途上国での青果物(トマト)の品質劣化状況を目視でしか把握できず、ロス率を定量的に測定することが難しかった。
ご要望: 画像AIでトマトの品質を判定し、廃棄対象となる個体の割合を推定・可視化したい。
AI Marketの支援: お客様の課題を丁寧にヒアリングし、「物体検出」「画像分類」などの技術を持つ最適なAI開発会社をご紹介しました。
このように、お客様の現状の課題や将来的な構想をお伺いした上で、最適なAIソリューションや開発パートナーのご紹介を無料で行っておりますので、お気軽にご相談ください。
AI画像認識を導入する際は専門会社へ
画像認識AIは、技術の進化とともに私たちの生活をより豊かで便利なものに変えていく可能性があります。
Amazon RekognitionやAzure AI Visionのように、手軽に画像認識AIを実装することが可能なサービスも増えています。
私たちは、この革新的な技術の恩恵を最大限に活かしつつ、責任あるAIの原則に基づいた開発と利用を心がけていくことが重要です。画像認識AIの未来は、技術者だけでなく、私たち一人一人の関わり方によって形作られていくのです。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

