
日本語特化LLMおすすめ9選徹底解説!ChatGPT以外にもある?現状と今後の期待
最終更新日:2025年09月03日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

近年、人工知能(AI)技術の中でも、特に自然言語処理(NLP)の領域は目覚ましい進化を遂げています。特に、ChatGPTの登場により、非IT企業でもテキスト生成AIを全く使わない企業の方が少なくなっています。これらの進歩の中心にあるのが、LLM(大規模言語モデル)です。
LLMについてはこちらの記事で、ChatGPTとはなにか、機能や使い方事例をこちらで詳しく説明していますので併せてご覧ください。
LLM技術は、翻訳、要約、質問応答、コンテンツ生成など、さまざまな応用が可能で、ビジネスからエンターテイメント、教育まで幅広い分野での活用が期待されています。
しかし現状は英語中心のLLM開発が進んでおり、英語以外の言語でのLLMの開発とその応用はまだ多くはありません。そんな中、日本語に特化し、日本語に強いLLMの研究と開発が注目を浴びており、有力なLLMも台頭してきています。
本記事では、
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
LLM・RAG開発が得意なAI開発会社について知りたい方はこちらで特集していますので、併せてご覧ください。
なぜ日本語LLMが必要?
現在市場で主流となっているほとんどのLLMは英語データ(Webでの英語記事など)を多く学習し作成されています。それでも、ほとんどのLLMは出力を多言語に翻訳する能力に優れていることもあり、通常の使用では日本語でスムーズにやり取りを行えるかもしれません。
ChatGPTでも日本語での質問に対し、時に英語でいきなり回答してくることはありますが、「日本語で答えて」と指示すると日本語で答え直してくれます。
それでも、特にビジネスでは日本語ネイティブなLLMが必要と言えるのはなぜでしょうか?
日本特有の知識や情報を回答する
英語などの主要言語に比べ、日本語で利用可能な高品質な学習データセットは限られています。大規模なデータセットの構築と維持は高コストであり、これが日本語LLMの発展を妨げる一因になっています。
しかし、最近では、オープンソースの取り組みや公的機関によるデータセットの提供が増えてきています。日本語の大規模なデータを学習することで、日本特有の知識や情報を取り入れることができます。これにより、日本のユーザーのニーズにより的確に応えることが可能となります。
関連記事:「オープンソースLLMを徹底比較!特徴・活用メリット・代表モデルの比較ポイントも解説」
日本語は文脈に大きく依存する
日本語は、文脈に大きく依存する言語であり、単語の意味が文脈によって大きく変わることがあります。このため、英語のLLMをそのまま日本語に適用すると、不自然な言葉遣いや文脈の誤りが生じる可能性があります。
日本語LLMは、より高度な文脈理解能力を必要とします。さらに、敬語の使用や多様な表現形式も、モデルの学習における重要な課題となっています。
日本独自の文化や慣習の理解が必要
日本には独自の文化、慣習、ビジネスマナーがあります。日本語のLLMは、これらの背景知識を学習することで、日本のユーザーに合わせたコミュニケーションが可能になります。
日本語LLMを活用することで、日本市場に特化したサービスやソリューションを提供できます。これにより、グローバル市場での競争力だけでなく、国内市場でのプレゼンスも高めることができます。
関連記事:「LLMを評価するLLM-as-a-Judgeとは?概要・メリット・活用シーン・注意点を徹底紹介!」
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
日本語特化で日本語に強い有力LLM9選
様々な課題に直面している日本語特化のLLMですが、日本語の学習データを元にオープンソースのLLMをファインチューニングした日本語対応のLLMや、日本語のデータセットをベースに学習を行ったLLMが多く公開され始めています。ここでは、有力な日本語に最適化されたLLMを紹介します。
ChatGPTのOpenAIが手掛けるGPT-4日本語カスタムモデル

ChatGPTを提供するOpenAIは、2024年4月に、日本語に最適化されたGPT-4カスタムモデルの提供開始を発表しました。日本語の性能に優れており、翻訳、要約のパフォーマンスが向上した他、トークン数などのコスト効率も向上しており、GPT-4 Turbo対比で最大3倍高速に動くことが特徴です。
2024年4月の発表では、今後数ヶ月以内にAPIが公開される予定とされていましたが、2024年11月時点でAPIは公開されていません。
軽量で高性能なNTTのtsuzumi
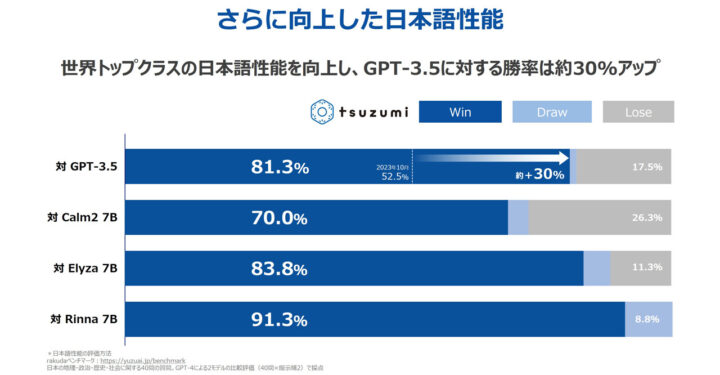
NTTが開発した「tsuzumi」は、日本語と英語の処理に特化したLLMで、軽量でありながら高い日本語処理能力を持つことが特徴です。パラメータサイズが6億から70億と比較的小さく、GPUやCPUでの推論動作が可能です。
これにより、学習やチューニングにかかるコストが大幅に低減されます。さらに、特定の業界や企業組織に特化したチューニングが可能で、マルチモーダル機能の追加により新しい価値の創出が期待されています。
NEC日本語特化型LLM「cotomi」
NECは、日本語に特化したLLM「cotomi」を開発し、それに関連したサービスをトータルで提供すると発表しました。このLLMは、130億パラメーターを持ち、世界最大級の日本語に特化したモデルとされています。
このLLMの最大の特長は、性能で海外製のLLMを凌駕しつつ、非常にコンパクトで超軽量化されている点です。パラメータサイズは海外製と比較して13分の1(GPT-3が1750億パラメータ)に抑えられており、標準的なサーバーでも動作可能な設計になっています。これにより、アプリのスムーズな動作や電力消費、サーバーコストの削減が可能になります。
東大松尾研発のELYZA(KDDI子会社)

東京大学の松尾研究室発のAIカンパニーである株式会社ELYZAが日本語のLLMを発表しました。700億パラメータを持つ「ELYZA-japanese-Llama-2-70b」という日本語特化型のLLMです。Meta社のオープンソース基盤モデル「Llama 2 70B」をベースとして開発されました。
ローカルLLMのベースとされて使われることも多いLLMです。
このモデルは国内外のモデルと比較しても高い性能を示しており、特に日本語の処理において最高水準の性能を実現しています。ELYZAはこの技術を基に、さらに多様な業界や企業向けに特化したLLMの開発も進めており、その技術力と応用範囲の拡大が期待されます。
楽天が提供するRakuten AI 7B

楽天グループも、日本語に最適化されたLLMを公開しています。基盤モデルである「Rakuten AI 7B」、およびインストラクションチューニングを施した「Rakuten AI 7B Instruct」と、さらにファインチューニングされたチャットモデル「Rakuten AI 7B Chat」を含みます。フランスのAIスタートアップであるMistral AI社の「Mistral-7B-v0.1」を基に日本語・英語データを学習させて開発されました。
これらのモデルは、オープンソースとして提供され、Apache 2.0ライセンスの下で利用可能です。楽天のLLMは、特に日本語のテキスト生成タスクにおいて高い性能を発揮することが期待されています。
IBMのGranite日本語版

IBMはGranite(グラナイト)の日本語版モデルを2024年2月に提供開始しました。このモデルは、80億パラメータを持ち、インターネット、学術、コード、法務、財務の領域から得たビジネス関連データで学習しています。
IBMは、企業向けAIとデータのプラットフォームであるIBM watsonxに、Granite基盤モデル群を継続的に追加しています。Granite日本語版は、日本語のテキスト処理に特化し、長い日本語の文章の効率的な処理と高速な推論を実現することが目標です。これにより、日本のクライアントは自社に適したAIモデルを選択し、生成AI(ジェネレーティブAI)の活用を加速できるようになります。
国内最高水準のベンチマーク評価のao-Karasu
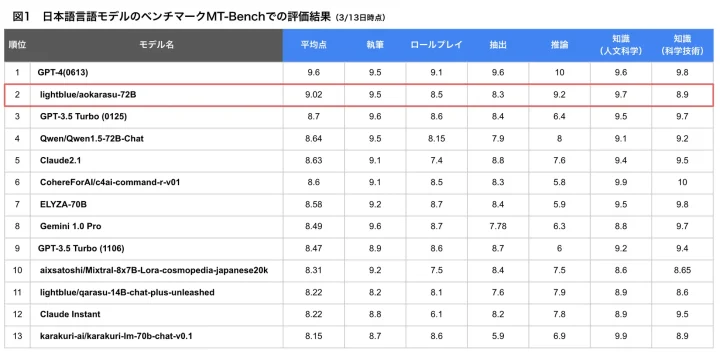
東京大学発、最先端アルゴリズムの現場実装に取り組むAIスタートアップの株式会社Lightblueは、720億パラメータを擁する日本語特化のLLM「ao-Karasu」を2024年3月に公開しました。このモデルは、Stability AIが提供する日本語性能のベンチマーク、Japanese MT-Benchの自動評価で国内最高水準の評価を得ています。
Lightblueはこのモデルを基に、DXコンサルティングや受託開発で培ったノウハウを活かし、業務理解を基にしたカスタマイズサービスを提供しています。
継続事前学習を行うrinnaのYouri 7B
AIキャラクタービジネスを手がけるrinna株式会社は、2023年10月にMeta社のオープンソース基盤モデル「Llama 2」をベースに日本語学習を行なった「Youri 7B」シリーズを発表しました。
Youri 7Bシリーズは、Llamaの70億パラメータモデルへさらに日本語・英語を400億トークンさらに学習させたモデルです。Youri 7Bは日本語の学習量が少ないLlamaの弱点を補ったモデルでベンチマークスコアも高水準ですが、ファイルサイズが大きいため動かすコンピュータのスペックが要求される側面もあります。
サイバーエージェントが開発したCyberAgentLM
サイバーエージェントは、70億パラメータと32,000トークン対応の日本語LLM「CyberAgentLM」を開発しました。このモデルは、AWSの機械学習サービス「Amazon SageMaker」で扱えるようになり、これが世界的なクラウドサービスで同社のLLMが公開される初の事例となります。
このLLMは、企業がAWSサービスを通じて簡単に自社環境にデプロイ可能で、日本語の自然言語処理技術の発展に貢献することを目指しています。
日本語のLLMに対する今後の期待

日本語特化のLLMは今後も大きな進化が期待されています。以下は、予想される今後の展望です。
高度な理解と生成能力の向上
日本語LLMの今後の発展では、日本語の複雑な文法や微妙なニュアンスを深く理解し、それをもとに自然で流暢な文章を生成する能力のさらなる向上が期待されています。これには、俗語や方言の理解、感情や意図を正確に捉える推論能力の強化が含まれます。
このような高度な理解と生成能力は、ユーザーの意図をより正確に捉え、多様なコミュニケーションやクリエイティブな内容生成に対応できることを意味します。
個々のニーズや業界に合わせたカスタマイズ
将来の日本語LLMは、エンドユーザーの特定のニーズに合わせたカスタマイズの可能性を広げることが期待されます。これは、個人の趣味や関心、職業的要求、または特定の業界固有の用語とプロセスに適応するモデルの開発を意味します。
ユーザーが直面する具体的な課題に対応し、その解決を助けるようなカスタマイズされたLLMは、使用体験を大きく向上させ、LLMの実用性をさらに拡大することができるでしょう。
国内外からの注目
日本語LLMの開発は国内外から注目を集めています。国際的なAI研究コミュニティでは、日本語などの非英語言語への対応が、多言語LLMの発展に不可欠であると認識されています。
また、日本国内では、政府や大企業、スタートアップがこの分野への投資を加速しており、国際競争力の強化という観点からも、日本語LLMの研究開発が推進されています。
モデルの軽量化
LLMの開発や運用コストを削減するために、LLMの軽量化、特にSLM(小規模言語モデル)への移行が注目されています。これにより、GPUリソースが削減でき、用途やケースに合わせてのチューニングがしやすくなります。今後、特定のビジネスプロセスや専門分野に特化した、小規模ながらも高性能なモデルが増えていくでしょう。その中には、当然日本語特化型LLMも含まれます。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
日本語特化のLLMについてよくある質問まとめ
- 日本語特化のLLMがなぜ必要?
- 日本語の特性に対応:日本語は英語とは文法構造や表現方法が大きく異なります。英語のLLMをそのまま日本語に適用すると、不自然な言葉遣いや文脈の誤りが生じる可能性があります。日本語のLLMは、日本語の特性を理解し、自然で適切な言葉遣いを実現します。
- 日本独自の文化や慣習の理解:日本には独自の文化、慣習、ビジネスマナーがあります。日本語のLLMは、これらの背景知識を学習することで、日本のユーザーに合わせたコミュニケーションが可能になります。
- 日本市場での競争力強化:日本語LLMを活用することで、日本市場に特化したサービスやソリューションを提供できます。これにより、グローバル市場での競争力だけでなく、国内市場でのプレゼンスも高めることができます。
- 日本語データの活用:日本語のLLMは、日本語の大規模なデータを学習することで、日本特有の知識や情報を取り入れることができます。これにより、日本のユーザーのニーズにより的確に応えることが可能となります。
- 日本語特化のLLMにどんな期待ができる?
- 高度な理解と生成能力の向上
- 個々のニーズや業界に合わせたカスタマイズ
- 軽量化
まとめ
この記事では、日本語特化のLLMの現状や課題、そして有力なLLMの紹介をしました。英語が中心のLLMだけでなく、日本語に特化したLLMにおいても凄まじい進化を見せており、今後あらゆるビジネスシーンや業務での導入が進んでいくでしょう。
企業や個人は、用途に最適な言語モデルを理解し、タスクに適応させた活用を進めていくことが今後のポイントになります。
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
ChatGPT/LLM導入・カスタマイズに強いAI開発会社を自力で選びたい方はこちらで特集していますので併せてご覧ください。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

