
サポートベクターマシンをわかりやすく説明!SVMの仕組みとは?メリット・デメリット、活用例を徹底解説
最終更新日:2026年01月26日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

サポートベクターマシンは教師あり学習アルゴリズムの1つで、分類や回帰といった重要なデータ分析分野に適用されます。ディープラーニング以前から使われていたモデルですが、今でも幅広い分野で活用されています。
この記事では、サポートベクターマシンの基本原理から、メリット・デメリット、実際のビジネスでの活用事例まで解説していきます。本記事を読むことで、サポートベクターマシンの基礎知識が身につき、自社のビジネスへの応用可能性を見出すことができるでしょう。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
AI開発会社をご自分で選びたい場合はこちらで特集していますので併せてご覧ください。
目次
サポートベクターマシンとは?

サポートベクターマシン(SVM)とは、機械学習での教師あり学習アルゴリズムの1つです。スパムメールのフィルタリング、画像認識などの分類問題や回帰分析に主に適用されます。
ただし、画像認識においては、CNNなどの手法がより主流となっています。
サポートベクターマシンは、データ分類する際に、異なるクラスのデータ点間の距離(マージン)を最大化する決定境界(超平面)を求めるのが基本的な考え方です。マージンを最大にすることで、汎化性能が向上し、新たなデータに対する予測精度を高められます。
りんごとオレンジを分類するタスクを例にとると、サポートベクターマシンではりんごとオレンジの間に見えない仕切り線(決定境界)を引きます。仕切り線は、できるだけ両方の果物から離れた場所に引くことも目標にします。
なぜなら、仕切り線がりんごとオレンジから離れているほど、新しく入荷したりんご、またはオレンジも正しく分類できる可能性が高くなるからです。
サポートベクターマシンは、その最大の特徴である高い分類精度で多くの機械学習タスクで使用されてきました。ディープラーニングが普及する以前から活用されており、現在でもデータ分析に多く使われるアルゴリズムです。
関連記事:「AIによるデータ分析の基本的なことから活用するメリット、失敗しないためのポイント」
サポートベクターとは
サポートベクターは、決定境界を定める上で重要な役割を果たす点です。決定境界と最も近いデータ点との距離を最大化する際に、決定境界の位置は特定のデータ点を基に決定されます。これらのデータ点のことを、サポートベクターと呼びます。
サポートベクターは学習結果に直接影響を与えるため、SVMにおいて重要な要素となります。学習データの中で、サポートベクター以外のデータ点は直接的な影響を持たないため、SVMは比較的少数のデータ点を用いた効率的な学習が可能です。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
サポートベクターマシンの仕組み

サポートベクターマシンの核心となるのが、マージン最大化とカーネル法です。以下では、サポートベクターマシンの仕組みを構成する概念・手法を紹介します。
マージン最大化
マージンとは、決定境界(超平面)とそれに最も近いデータ点(サポートベクター)との距離を指します。SVMはマージンを最大化することで、データの分類精度を高め、汎化性能を向上させることが可能です。
マージンを大きく取ることで、学習データに過剰に適合する過学習を防ぎ、新しいデータに対する予測精度を確保できます。また、高次元データやノイズを含むデータにも対応可能です。
しかし、すべてのデータが完全に線形分離できるとは限りません。この場合はソフトマージンと呼ばれる手法を用い、一部のデータ点の誤分類を許容しながら最適な決定境界を求めます。
カーネル法
カーネル法は、低次元の特徴空間では分離困難なデータを高次元空間へと写像し、線形分離可能な形に変換する手法です。カーネル法を使えば必要な計算を効率的に実行できるため、非線形な境界を持つデータセットにもサポートベクターマシンを適用できます。
カーネル法では明示的に高次元空間に変換することがありません。そのため、データを高次元空間に射影しながら、計算量を抑えることが可能です。
サポートベクターマシンの精度や計算効率に影響を与えるため、適切なカーネル関数を選択することが重要です。データの分布や問題の性質に応じて選ぶことで、サポートベクターマシンの性能を最大限に引き出すことができます。
サポートベクターマシンのメリット

データ分析に適したアルゴリズムであるサポートベクターマシンには、さまざまなメリットがあります。以下では、サポートベクターマシンを活用するメリットを解説していきます。
過学習の抑制
過学習とは、AIモデルが学習データに過度に適合しすぎることで、新しいデータに対する汎化性能が低下する現象を指します。サポートベクターマシンはマージン最大化の原理に基づき、決定境界の汎化性能を重視します。そのため、不要なデータの影響を受けにくいという特性を持ちます。
サポートベクターを分類の基準としているため、ノイズの影響を最小限に抑えつつ、データ全体の構造を捉えることができます。データ学習で陥りやすい過学習を抑えつつ、高い汎化性能を維持する機械学習アルゴリズムとして、サポートベクターマシンは広く活用されています。
高い識別精度を実現
マージン最大化による分類境界の最適化によって、サポートベクターマシンは高い識別精度を実現します。未知のデータに対する分類性能を向上させ、ノイズの影響を抑えることが可能です。
さらに、サポートベクターマシンは少量の学習データでも高精度で分類します。データセットが小規模でも、適切なカーネル関数やハイパーパラメータの調整を行うことで、高い識別精度を維持できます。
非線形データにも対応
サポートベクターマシンでは、線形分離が難しいデータに対しても適用可能です。カーネル法を利用することで、データが直線や平面で明確に区別できない場合でも非線形データを扱うことができます。
データの特性に応じた適切なカーネルを選ぶことで、非線形データに対する分類精度をさらに向上させることができます。サポートベクターマシンは非線形データを扱う際にも高い識別性能を維持できるため、複雑なデータ構造を持つ問題にも対応可能です。
回帰分析にも対応可能
主に分類問題に用いられるサポートベクターマシンですが、回帰分析にも応用できます。これを「サポートベクター回帰(Support Vector Regression, SVR)」と呼び、SVMの基本原理を活用しながら、連続値の予測を行う手法です。
通常の回帰分析では、予測値と実測値の誤差の最小化を目指しますが、サポートベクターマシンでは特定の許容範囲を設定し、その範囲内での誤差を無視します。このアプローチにより、ノイズの影響を受けにくく、汎化性能の高い回帰モデルを構築することが可能です。
SVRの特徴として、非線形回帰にも容易に対応できる点が挙げられます。これは、カーネル法を用いることで、高次元の特徴空間に写像し、その空間内で線形回帰を行うことができるためです。
また、SVRは重回帰分析と比較して、以下のような利点があります。
- 多重共線性の問題が生じにくい
- 説明変数の数がデータ数を上回る場合でも解析可能
- 変数間の交絡効果を自動的に考慮できる
これらの特徴により、SVRは複雑な関係性を持つデータや、多数の説明変数を扱う場合に特に有効です。ただし、モデルの解釈性については、重回帰分析の方が優れている場合があるため、分析の目的に応じて適切な手法を選択することが重要です。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
サポートベクターマシンのデメリット
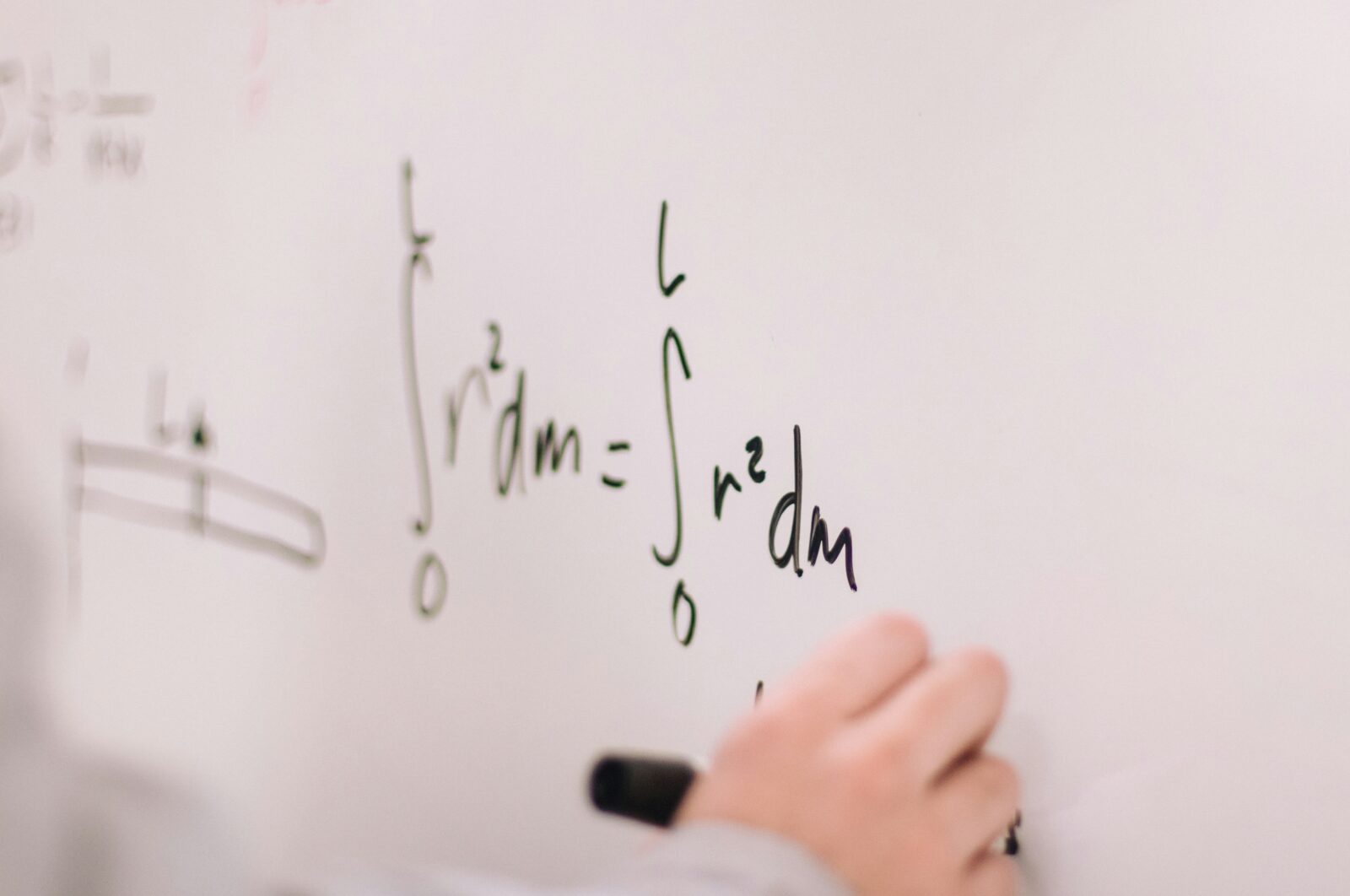
サポートベクターマシンは高い識別精度と汎化性能を持つ一方で、デメリットもあります。具体的なデメリットについて解説していきます。
計算コストが高い
サポートベクターマシンは高い識別精度を誇る一方で、計算コストが高くなるという課題があります。大量のデータを扱う場合や次元数が増えると、計算量が急激に増大し、学習や推論の処理時間が長くなります。
また、カーネル法を適用した場合は、高次元空間へのマッピングによる計算負荷が追加されます。これによって計算の複雑さが増し、大規模データの処理が一層困難になるでしょう。
こうしたデメリットに対しては、データのサンプリングや特徴選択による次元削減、または線形SVMなどの計算負荷の低い手法を用いるのが効果的です。
大規模なデータの分析は不得意
サポートベクターマシンの学習プロセスは計算負荷の大きい最適化問題を含むため、データ量が増えると処理時間やメモリ消費が急増します。そのため、大規模なデータの分析は不得意です。
データが増えるほどサポートベクターの数も増加し、学習時間が長くなります。数百万件以上のデータを扱う場合、学習が時間内に完了しない可能性もあります。
複雑なパターンを持つ大規模データ(画像、音声、自然言語など)には、ディープニューラルネットワーク(DNN)を使う場合もあります。DNNの中間層を特徴抽出器として使い、その出力をSVMに入力する方法や、DNNの最終層をSVMに置き換えることで、DNNの特徴学習能力とSVMの分類性能を組み合わせる方法もあります。
データの特性によっては性能が低下する
クラス分布が大きく偏っているデータセットでは、サポートベクターマシンは多数クラスに偏った予測を行う傾向があります。サポートベクターマシンがクラス分布を考慮せずにマージンの最大化に焦点を当てるのが原因です。
サポートベクターマシンはデータがクリーンで、クラスが明確に分離されていることを前提としています。ノイズの多いデータセットでは、サポートベクターマシンの性能が大幅に低下する可能性があります。
学習結果の解釈が困難
サポートベクターマシンの分類はサポートベクターと決定境界を基に行われるため、単純な重みの比較で特徴の重要度を判断することができません。線形回帰や決定木、ランダムフォレストのように、直感的な判断がしにくいデメリットがあります。
カーネル法を適用した場合は、高次元空間でのデータの変換がブラックボックス化しやすく、決定境界の形状や分類基準が直感的に理解しにくくなります。これにより、サポートベクターマシンを用いたモデルの意思決定プロセスを説明するのが困難となり、医療や金融と言った根拠の明確性が重視される分野では導入しにくくなるでしょう。
関連記事:「XAI(説明可能なAI)とは?」
サポートベクターマシンを適切に活用するポイント

サポートベクターマシンの高い識別性能を維持し、適切に運用していくには、以下のようなことが必要です。
- スケーリングを実施する
- ハイパーパラメータを適切に調整する
- 適切なカーネルを選択する
それぞれの手法について解説していきます。
スケーリングを実施する
サポートベクターマシンを効果的に活用するには、データのスケーリングが不可欠です。サポートベクターマシンではスケールの異なる特徴量が存在すると、一部の特徴が支配的になり、他の重要な特徴の影響が無視されてしまい分類精度が低下する可能性があるためです。
データのスケールが揃っていないと、決定境界の形状が適切に形成されず、学習がうまく進められません。そのため、特徴量ごとの値の範囲を統一して精度を向上させ、安定した学習を実現することが必要です。
ハイパーパラメータを適切に調整する
サポートベクターマシンの性能を最大限に引き出すには、ハイパーパラメータの調整が必要です。サポートベクターマシンでは、以下のようなハイパーパラメータの設定がモデルの識別性能や汎化能力に影響を与えます。
- 正則化パラメータ(C)
- カーネルパラメータ(γなど)
正則化パラメータCは、誤分類をどの程度許容するかを制御する役割を持ちます。C値が大きくすると学習データへの適合度は高まりますが、過学習のリスクは増加します。一方、C値を小さくすると、多少の誤分類を許容しながら汎化性能を向上させることができます。
カーネルパラメータγ(ガンマ)のγ値が大きいと、決定境界が局所的になり、過学習のリスクが高まります。一方でγが小さすぎると、データの構造を十分に捉えられず、識別精度が低下する可能性があります。
適切なカーネルを選択する
カーネル関数は、低次元空間で線形分離が難しいデータを高次元空間へ対応させ、分類や回帰を可能にする役割を持ちます。カーネルによってモデルの表現力や計算効率が変わるため、適切な関数を用いることで最適な分類境界を構築できます。
代表的なカーネル関数としては、以下のようなものがあります。
- 線形カーネル:最もシンプル
- 多項式カーネル:画像処理分野で人気
- RBFカーネル:最も一般的に使用される
- シグモイドカーネル:ニューラルネットワークと類似した特性
サポートベクターマシンを適用する際には、データの特性や分類タスクの要件に応じて最適なカーネルを選択することが不可欠です。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
サポートベクターマシンの活用例
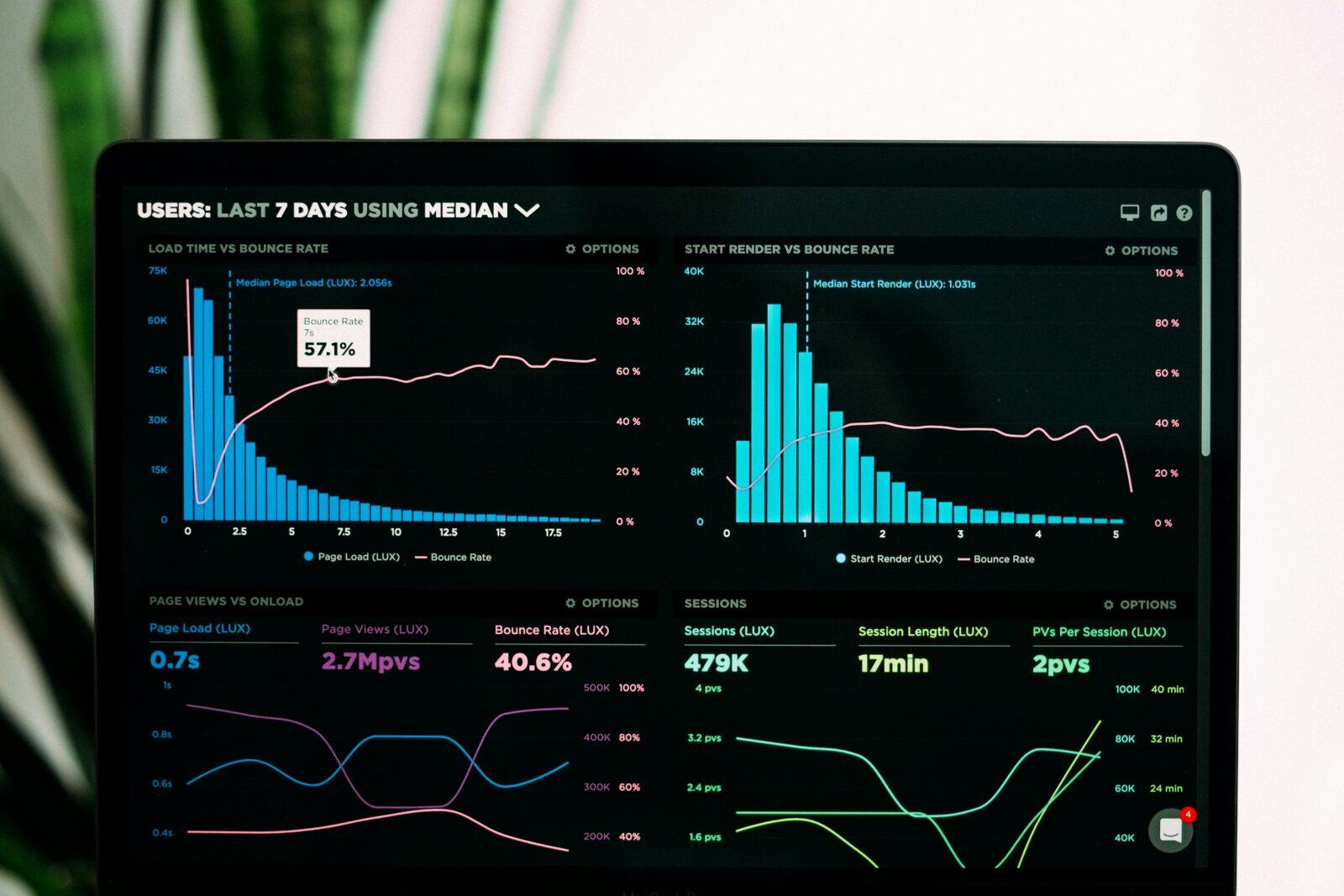
サポートベクターマシンが持つ高い分類精度と汎化性能は、さまざまな分野で活躍することが期待されています。以下では、サポートベクターマシンの活用例を5つ紹介します。
株価予測
株価の変動は、多くの要因に影響を受けるため、単純な統計手法では精度の高い予測が困難です。しかし、サポートベクターマシンは高次元データの扱いや非線形パターンの学習にも優れているため、将来の価格変動を予測するのに適しています。
株価予測では、サポートベクターマシンを回帰分析に応用した「サポートベクター回帰」が用いられています。株価の時系列データを学習し、適切な決定境界を求めることで、過去のデータから将来の価格を推定することが可能です。
また、テクニカル指標やマクロ経済データ、ニュース記事のセンチメント分析など、多様なデータを組み合わせた予測モデルの構築にも利用されます。サポートベクターマシンによる分類や回帰分析を行うことで、より高精度な株価予測が可能です。
関連記事:「証券会社でいまAIが求められている背景や実際の活用事例」
災害予測
サポートベクターマシン(SVM)は、気象データや地震データの分析にも応用されており、災害予測の分野で有効な手法とされています。気象パターンの変動や地殻変動の傾向を分析し、異常な兆候を検出することが可能です。
例えば豪雨・台風の予測では、気温・気圧・湿度・風速などの気象データを学習し、異常気象の発生を分類するモデルとして活用されます。過去の気象データと最新の観測データを組み合わせることで、異常気象の発生確率を推定することができます。
また、斜面の傾斜角度、地質、降水量などのデータから、土砂崩れの危険性を判定可能です。
サポートベクターマシンを活用した災害予測は、リアルタイムデータと組み合わせることで、早期警戒システムの精度を向上させることが可能です。適切なデータ前処理やパラメータ調整を行うことで、実際の災害リスクの予測精度を高めることも期待できるでしょう。
関連記事:「AI防災とは何なのか、活用するメリットや活用方法・具体的な事例」
腫瘍診断
サポートベクターマシンは医療分野においても活用可能で、腫瘍の診断を支援します。画像診断や遺伝子データの解析において、遺伝子やタンパク質の分類に使用され、良性腫瘍と悪性腫瘍を識別するための手法として有効です。
腫瘍診断では、医用画像データを解析し、腫瘍の特徴を抽出することで、悪性か良性かを分類する必要があります。サポートベクターマシンは特徴空間内で分類境界を見つけるのに優れており、限られたデータでも高い精度で腫瘍の識別が可能です。
また、遺伝子発現データやバイオマーカー情報の分類にも活用されており、腫瘍の種類や進行度を特定するための補助的な診断ツールとして使用されます。
関連記事:「ゲノム解析の概要やゲノム解析の事業活用が期待できる分野を紹介」
異常検知
異常検知とは、通常のパターンから逸脱したデータを検出することであり、製造業の品質管理やサイバーセキュリティ、金融の不正取引検出など、多くの領域で重要な役割を果たします。
例えば製造業では、センサーから取得した機械の動作データを分析し、異常な振動や温度変化を早期に検出することで、設備の故障を未然に防ぐ予知保全に活用されています。サポートベクターマシンは限られたデータから最適な境界を学習できるため、異常を高精度で検出することが可能です。
関連記事:「異常検知とは?メリットや学習方法、手法」
顔検出
サポートベクターマシンは画像中の顔と非顔の部分を分類し、顔の周りに境界を作成します。これにより、セキュリティシステムやカメラのフォーカス機能などに応用されています。
顔検出では、画像の局所的な明暗パターンを使用します。これらの特徴は、顔の構造(目、鼻、口など)を効率的に表現します。
ただし、ディープラーニングの発展により、近年では畳み込みニューラルネットワーク(CNN)を用いた手法が顔検出でも主流になりつつあります。しかし、サポートベクターマシンは依然として計算リソースが限られた環境や、学習データが少ない場合などで有効な選択肢となっています。
関連記事:「顔認証システムとは?どんな仕組み?導入手順・注意点」
サポートベクターマシンについてよくある質問まとめ
- サポートベクターマシンとは?
サポートベクターマシン(SVM)は、教師あり学習の一種で、分類や回帰に用いられるアルゴリズムです。高い分類精度と理論的な裏付けを持ち、ディープラーニングが普及する前から広く活用され、現在もデータ分析に用いられています。
- サポートベクターマシンのデメリットは?
サポートベクターマシンを活用するにあたって、以下のようなデメリットが存在します。
- 計算コストが高い
- 大規模なデータの分析は不得意
- 次元の呪いが発生する可能性がある
- 学習結果の解釈が困難
- サポートベクターマシン(SVM)は、どのようなデータ分析に向いていますか?
SVMは、特に分類問題に強みを発揮します。例えば、顧客のセグメンテーション、スパムメールのフィルタリング、画像認識など、明確なクラス分けが必要なタスクに適しています。また、回帰分析にも応用可能で、株価予測や需要予測など、連続値の予測にも利用できます。
まとめ
サポートベクターマシンは、高い分類精度と汎化性能を持つ機械学習アルゴリズムです。マージン最大化による過学習の抑制や、カーネル法での非線形データ対応を実現し、小規模データに対しても高精度な予測が可能です。
しかし、その性能を最大限に引き出すには、データの特性を理解し、適切なパラメータ調整やカーネル関数の選択を行う必要があります。大規模データの分析や、学習結果の解釈に課題が残る場合も考えられます。より高度な分析や、複雑な課題への対応には、専門家の知識やサポートが必要となるケースもあるでしょう。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

