
Groqとは?高速処理が可能なLLMプラットフォームの特徴やアーキテクチャ、料金、活用例を徹底解説!
最終更新日:2026年03月12日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- Groqは、独自開発のLPU(Language Processing Unit)により、LLMの処理を非常に高速に行えるAIプラットフォーム
- APIを通じて複数のオープンソースLLMを利用でき、特にリアルタイム性が求められる応答速度や、処理の安定性に強みがあります。
- RAG(検索拡張生成)システム、カスタマーサポート、音声アシスタントなど、応答速度が重要となる様々な業務での活用が期待されています。
生成AIをビジネスに活用する際、応答の遅さやリアルタイム処理の難しさが課題となることがあります。
この記事では、そのような課題に対し、独自のLPU(Language Processing Unit)技術でLLMの高速処理を実現するAIプラットフォーム「Groq」をご紹介します。Groqがどのようにして驚異的な処理速度と安定性を両立し、API連携の容易さによって開発者の負担を軽減するのか、その仕組みから具体的な活用例、導入時のポイントまでを解説します。
生成AIに強いAI会社の選定・紹介を行います
今年度生成AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 生成AIに強い会社選定を依頼する
ご自分で生成AIの導入に強い開発会社を探したい方は併せてご覧ください。
目次
Groqとは?

Groqとは、LLM(大規模言語モデル)を驚異的な速度で処理できるAIプラットフォームです。従来のGPUベースの計算環境とは一線を画し、低遅延かつ高スループットな処理を実現しています。
単一プロバイダによる閉じたモデルとは異なり、複数のオープンソースLLMを搭載しているのが特徴です。ユーザーは目的に応じて最適なモデルを選択することが可能です。
開発者としては、API設計やレスポンス速度の合理化だけでなく、インフラレベルでのスケーラビリティの高さも魅力的です。特に、生成AIをリアルタイム処理基盤として活用したい企業にとって、Groqはこれまでにない速度と制御性を提供します。
企業としてのGroqの特徴
Groq社は、LLM(大規模言語モデル)の推論処理を高速化するために特化した独自のチップ「LPU(Language Processing Unit)」を開発・提供しています。従来のAI処理で主流であったGPU(Graphics Processing Unit)とは異なるアーキテクチャを採用することで、驚異的な処理速度と低遅延を実現しています。
Groq社は、自社開発のLPUの圧倒的な処理能力を、より多くの開発者や企業が容易に利用できるように、クラウドベースのAIプラットフォーム「GroqCloud」、通称「Groq」として提供しています。
Groqにより、ユーザーは高性能なハードウェアインフラを自前で構築・維持する手間はなくなります。APIを通じてGroqのLPUにアクセスし、LLMなどのAIモデルを驚異的なスピードで実行させることが可能になります。
ChatGPT、Geminiとの違い
GroqはChatGPTやGeminiと同じくLLMを活用した生成AIサービスですが、根本的なアーキテクチャと提供形態に明確な違いがあります。
ChatGPTやGeminiは、自社開発のモデルを中心に据えた統合型のプラットフォームであるのに対し、GroqはLLMを極限まで高速処理できるハードウェアと実行環境を中核に据えています。高性能なオープンソースモデルを搭載し、他社と比べて圧倒的な応答速度を実現しています。
つまり、GroqはAIモデルの開発企業ではなく、LLMを最大限に活用できる「実行基盤」を提供している点において他の主要生成AIとは本質的に異なります。
さらに、ChatGPTやGeminiは汎用的な会話生成を重視しているのに対し、Groqはリアルタイム推論処理や低遅延なAPIレスポンスを重視しています。そのため、処理速度が重要となるRAGや音声対話、IoT連携といった分野で高い有用性を発揮します。
参考:Groq
生成AIに強いAI会社の選定・紹介を行います
今年度生成AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 生成AIに強い会社選定を依頼する
Groqの特徴とメリット
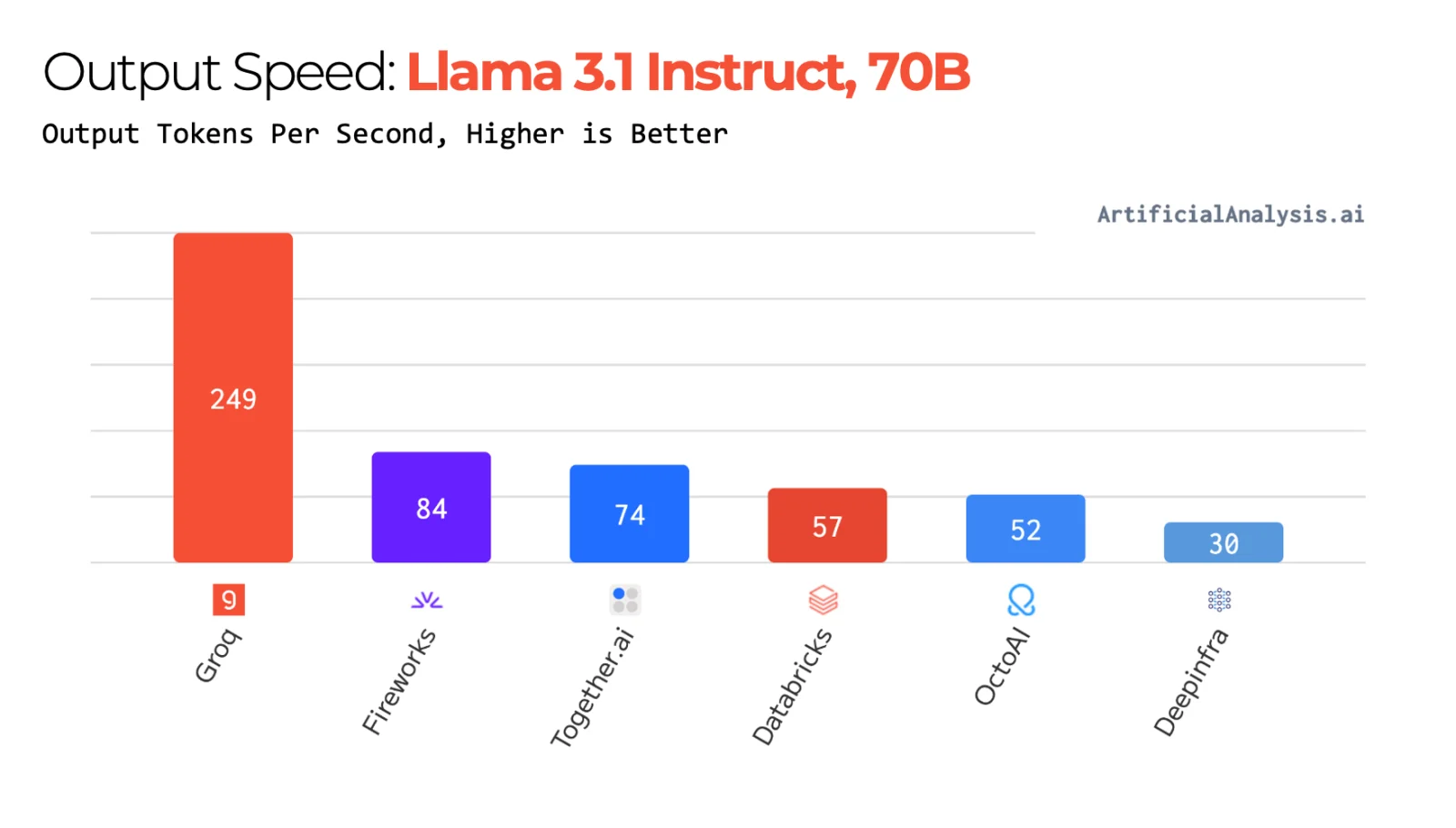
以下では、Groq独自の機能と特徴について見ていきましょう。
APIで簡単にアクセス
Groqは開発者の生産性を重視したAPI設計となっており、実装や運用を支援します。LLMの呼び出しやモデル選択、出力制御といった処理が直感的に実行できる設計が施されています。
こうしたAPI設計はバックエンドのAI実行基盤として、Groqを統合する際の初期導入コストを抑えつつ、既存のアプリケーションにスムーズに組み込むことが可能です。
また、ドキュメントやサンプルコードの整備にも適しており、少ない手順で高速推論の恩恵を受ける開発体験を提供しています。ユースケースごとの最適化やA/Bテストも実施できるため、実運用に耐えうる環境で活用できます。
LLMを高速で処理できる
Groqの最大の特徴は、LLMを圧倒的なスピードで処理できる点です。独自開発のLPUとTSPにより、トークンごとの処理時間が極めて短く、即時応答が可能です。
実際のパフォーマンスとして、Groqは数百トークンに及ぶ応答をわずか1秒以下で出力できるケースも多く、LLMの実用性を引き上げています。特に、モデルの複雑性に依存せず高速処理を維持できる点は、Groqの大きな優位性といえます。
これまで処理速度の制約から実用化が難しかったリアルタイムでの音声認識、画像解析、金融市場の異常検知といった高度なAIソリューションの実現が現実のものとなります。
また、高速な推論処理により、AIモデルのテストやイテレーションにかかる時間が大幅に短縮されます。
処理精度が安定している
Groqは高速処理だけでなく、処理精度の安定性にも優れています。演算の並列制御やデータフローを最適化することで、一貫した品質を維持しています。
これにより、同じプロンプトを複数回処理しても、再現性の高い出力を得ることが可能です。
主要なオープンソースLLMへの対応
Groqプラットフォームでは、LlamaやMixtralといった業界標準のオープンソース大規模言語モデルをサポートしています。これにより、特定のモデルにロックインされることなく、プロジェクトの要件や目的に最適なモデルを選択して利用できます。
いち早く次世代のAI処理基盤を活用することで、競合他社に先駆けてAIサービスを市場に投入し、競争優位性を確立することができます。
Groqで利用できるオープンソースLLM

Groqでは複数のオープンソースLLMを統合しており、それぞれのモデルをGroq独自の高速処理基盤で動作させています。搭載されているLLMについて以下で解説していきます。
Mistralシリーズ
Mistralシリーズは、フランスのMistral AIが開発したオープンソースの大規模言語モデル群です。こちらのLLMは、処理効率と多用途性を兼ね備えた設計が特徴です。
これらのモデルは、自然言語処理やコード生成、文書理解などのタスクに対応し、高い推論性能と応答速度を実現しています。また、Apache 2.0ライセンスの下で提供されており、商用利用やカスタマイズが容易です。
Llamaシリーズ
Llamaシリーズは、Meta AIが開発した大規模言語モデル群であり、オープンなアクセス性と高い性能を兼ね備えています。自然言語処理タスクにおいて優れた性能を発揮し、研究者や開発者に広く利用されています。
Llamaシリーズは、さまざまなパラメータサイズのモデルを提供しており、用途やリソースに応じた選択が可能です。Llama 3以降のモデルでは、マルチモーダル処理や長いコンテキストウィンドウへの対応が強化され、複雑なタスクへの適用が可能です。
2025年4月5日にはLlama 4が発表されました。Groqの高速推論基盤と組み合わせることで、Llamaシリーズの性能を最大限に引き出すことが期待されています。
DeepSeek
DeepSeekは、中国のAI企業High-Flyerが開発したオープンソースのLLMで、推論能力と計算効率に優れています。「DeepSeek R1」および「R1-Zero」は、Mixture-of-Experts(MoE)アーキテクチャを採用し、高精度な応答を実現します。
これにより、論理的推論や数学的問題解決などのタスクにおいて高精度な回答を提供します。また、これらのモデルはMITライセンスの下で公開されており、自由に利用・改変・商用利用できる点も強みです。
Qwen
Qwenは、Alibaba Cloudが開発したLLMシリーズで、自然言語処理や生成タスクにおいて高い性能を発揮するモデルです。
最大128,000トークンの長文コンテキスト処理に対応しており、複雑な文脈理解や長文生成が可能です。Qwenは約30言語に対応しており、多言語環境での利用にも適しています。
さらに、Qwen2.5-MathやQwen2.5-Coderなどの特化型モデルも提供されており、数学的推論やコード生成といった専門的な用途にも対応しています。
生成AIに強いAI会社の選定・紹介を行います
今年度生成AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 生成AIに強い会社選定を依頼する
Groqの高速処理を実現するアーキテクチャ

Groqが他のAI実行基盤と一線を画す理由は、その独自アーキテクチャにあります。以下では、Groqの高速処理を支える技術について解説します。
LPU(Language Processing Unit)
Groq独自開発のプロセッサであるLPU(Language Processing Unit)は、推論に特化したアーキテクチャです。従来のGPUやCPUは汎用計算向けであるのに対し、LPUはLLMの推論処理を目的に構築されています。
LPUは言語処理に不要な回路や機能を大胆にそぎ落としています。これにより、チップ上の限られたリソースを、言語処理に最も重要な演算ユニットやメモリ帯域の確保に集中投下できます。
そのため、パラメータ演算やトークン生成といった処理を極限まで高速化します。処理の並列性とスループットを最大化することで、応答遅延の大幅な削減を実現しています。
また、GroqのLPUは、ソフトウェアが命令を実行するのに必要な時間を事前に正確に把握できるように「決定論的実行」と呼ばれる思想のもとで設計されています。まるで精密に組まれたオーケストラの指揮者のように、どの処理(楽器)がいつ動き出し、いつ終わるのかが完璧にコントロールされています。
統一された命令セットと制御方式によって、予測可能な処理時間を保証し、生成結果の一貫性や処理の安定化も可能です。GroqはLPUを複数同時に稼働させるスケーラブルな構成も可能とし、大規模なエンタープライズ環境においても大きな優位性となります。
メモリ帯域幅の最適化
LLMの推論処理では、メモリ帯域の広さと効率的なアクセス構造が処理速度に直結しています。Groqではプロセッサとメモリの物理的な接続構造を最適化することで、極めて高い帯域幅を実現しました。
LPUと連携したアーキテクチャ全体でメモリアクセスを制御し、一定のスループットを維持する仕組みを構築しています。これにより、トークン単位での推論が短時間で完了し、LLMの処理全体が飛躍的に高速化されます。
また、推論中のボトルネックが生じにくく、処理時間のばらつきが少ないという安定性をもたらしています。こうした低レイテンシなメモリ構造がGroqの高速処理を実現しているのです。
ハードウェアとソフトウェアの協調設計
Groqの強みは、単に高性能なハードウェアを開発したことだけではありません。そのハードウェアの能力を最大限に引き出すためのソフトウェア、特にコンパイラの開発にも注力している点が非常に重要です。
コンパイラは、LLMのモデル定義を、LPUが実行できる機械語の命令セットに変換する役割を担います。Groqのコンパイラは、LPUの決定論的なアーキテクチャを熟知しており、計算タスクをLPU上で最も効率的に実行できるように、命令のスケジューリングやリソース割り当てを最適化します。
相乗効果:
ハードウェア設計の初期段階からソフトウェア(コンパイラ)のチームが密接に連携することで、互いの特性を最大限に活かした設計が可能になります。これにより、汎用的なハードウェアとソフトウェアを組み合わせる場合に比べて、より高いレベルでのパフォーマンスチューニングが実現されます。
Groqの使い方
Groqは、公式サイトにアクセスし、アカウントを登録するだけで使うことができます。
また、APIキーの取得と環境設定を行うことで、Pythonなどのプログラミング言語から利用可能です。開発経験のあるエンジニアであれば、容易に導入できるでしょう。
他のプロバイダーからGroqに移行するには、以下の手順が必要です。
- APIキーをGroq API キーに設定する
- ベースとなるURLを設定する
- 実行するモデルを選択する
いずれにしてもスムーズに使い始められるでしょう。
Groqの料金プラン
Groqの料金プランは、AIモデルによって違いがあります。まず、主なLLM(大規模言語モデル)の料金は以下の通りです。
| AIモデル | 1秒あたりのトークン数 | 100万トークン入力あたりの価格 | 100万トークン出力あたりの価格 |
|---|---|---|---|
| Llama 4 Scout (17Bx16E) | 460 | $0.11 | $0.34 |
| DeepSeek R1 Distill Llama 70B | 275 | $0.75 | $0.99 |
| Qwen QwQ 32B (Preview) 128k | 400 | $0.29 | $0.39 |
| Mistral Saba 24B | 330 | $0.79 | $0.79 |
| Llama 3.3 70B Versatile 128k | 275 | $0.59 | $0.79 |
| Llama 3 70B 8k | 330 | $0.59 | $0.79 |
| Llama 3 8B 8k | 1,250 | $0.05 | $0.08 |
| Gemma 2 9B 8k | 500 | $0.20 | $0.20 |
| Llama Guard 3 8B 8k | 765 | $0.20 | $0.20 |
次にテキスト読み上げ(TTS)モデルでは、以下を使えます。
| AIモデル | 1秒あたりの文字数 | 100万文字あたりの価格 |
|---|---|---|
| PlayAI Dialog v1.0 | 460 | $50 |
最後に自動音声認識(ASR)モデルでは、以下のように料金が設定されています。
| AIモデル | スピードファクター | 文字起こし1時間あたりの価格 |
|---|---|---|
| Whisper V3 Large | 189x | $0.111 |
| Whisper Large v3 Turbo | 216x | $0.04 |
| Distil-Whisper | 250x | $0.02 |
これらの数値は特に変動しやすいため、ご提示の数値が最新であるとは限りません。詳細については、Groqの公式サイトをチェックしてください。
生成AIに強いAI会社の選定・紹介を行います
今年度生成AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 生成AIに強い会社選定を依頼する
Groqの活用例

Groqの圧倒的な処理速度と安定性は、さまざまな業務領域で実用化が期待されています。
RAG(検索拡張生成)
GroqはRAG(検索拡張生成)との相性が良く、高精度な応答システムを構築する上で有効です。RAGにおける検索結果の取り込みと、応答生成でGroqのアーキテクチャが活用できます。
具体的には、LPUによるトークン処理の高速化・メモリ帯域の最適化により、検索されたドキュメントの取り込みから回答生成までをリアルタイムに近い形で実行可能です。Groqは複数モデルに対応しているため、最適なLLMを選択し、精度と速度のバランスを調整することもできます。
生成処理が高速化されることで、より多くの検索結果をLLMに渡し、多角的な視点からの回答を生成したり、複数の情報源を比較・統合してより深い洞察を得るような、高度なRAG処理を行う余裕が生まれます。これにより、回答の質そのものを向上させることが可能になります。
また、RAGシステムの開発や改善のステージにおいては、プロンプトエンジニアリングや検索結果のチューニングなど多くの試行錯誤が必要です。Groqによる高速なフィードバックループは、これらのイテレーションを加速させ、開発効率を大幅に向上させます。
カスタマーサポート
カスタマーサポートでは、リアルタイム性と応答の安定性を向上させるチャットボットプラットフォームとしてGroqを活用できます。Groqの高速処理能力により、問い合わせから応答までの遅延を最小限に抑えた自然な会話体験が可能となります。
Groqは処理の一貫性が高いため、問い合わせ内容に対して安定した出力を得ることができ、クレーム対応やトラブルシューティングといったミスの許されない場面でも信頼性を維持できます。また、FAQ応答や商品説明、手続き案内など、多様な問い合わせにも対応可能です。
Groqを導入したシステムでは、24時間対応の自動応答体制を構築しながら、ユーザー満足度を向上させることが期待できるでしょう。
音声アシスタント
音声対話では、ユーザーの問いかけに対する自然な応答が不可欠であり、わずかな処理の遅延でも対話の流れを阻害する要因となります。Groqではトークン単位での処理をリアルタイムに近い速度で実現しており、この要件を満たす性能を提供します。
また、LLMを切り替えて利用できるため、家庭用スマートスピーカーから企業向けの対話システム、医療や物流現場での音声ガイドに至るまで、幅広い導入ニーズに対応可能です。
IoT・エッジAI
IoTやエッジAIの環境では、センシングデータやユーザーインタラクションに即応するリアルタイム処理が求められます。Groqは専用ハードウェアによる高速推論を活かし、必要最小限の遅延で応答を返すことができます。
特にLPUは予測可能な処理時間を保証できるため、産業用ロボットやスマートホーム、車載システムなど、素早い意思決定が求められるユースケースで安定した稼働を実現します。
さらに、トークン処理効率が高いため、限られた電力や演算リソースでもLLMを活用することが可能です。リソース制約のあるエッジデバイスにとっては、大きなメリットと言えるでしょう。
Groqを使用する際の注意点
![]()
Groqの高速性・安定性は協力ですが、導入前に把握しておくべき注意点も存在します。
利用可能なモデルが限定されている
Groqで利用できるモデルは、あくまでオープンソースモデルに限定されています。ChatGPTやGeminiなどの商用クローズドモデルは利用できません。
そのため、自社で求める性能や言語対応が、搭載されているモデルで実現できるかを事前に検討する必要があります。
また、Groqは独自の実行環境でモデルを動作するため、一般的なHugging FaceのTransformersライブラリや、PyTorch形式で提供されるモデルをそのまま使用することはできません。あらかじめGroqが最適化・提供しているモデルに限られるため、柔軟性という点では制約があると言えます。
独自のハードウェア環境に依存している
Groqは、LPUを中核とした専用ハードウェア環境に依存しており、一般的なGPUやCPUベースの実行環境とは大きく異なります。
Groqの高速性や処理の一貫性は特化型アーキテクチャにより実現されていますが、同時にユーザーがGroqの提供するクラウド環境に依存せざるを得ないという制約も生じます。そのため、オンプレミスでの運用やカスタムインフラへの組み込みには限界があり、既存AIとの互換性や統合には注意が必要です。
また、LPUは一般的なハードウェアでは動作しないため、物理的にGroqの処理基盤を導入することは困難です。
導入を検討する際には、他の汎用的なプラットフォームと比較して、自社のシステム構成やセキュリティ要件に適合するかを検討しなければいけません。
日本語での回答精度は低い
Groqに搭載されているLLMは、主に英語圏を中心に開発されたオープンソースモデルが用いられています。そのため、日本語での入力に対する応答精度や自然さは劣る傾向があります。
特に、文脈の把握や敬語の使い分け、複雑な表現の理解といった日本語特有の処理においては、出力に違和感や曖昧さが生じるケースも少なくありません。これは、学習データにおける日本語コーパスの割合が少ないことやGroq自体が日本語圏の業務向けにチューニングされていないことに起因します。
日本語対応を強化したい場合には、別の日本語特化モデルや翻訳処理を組み合わせるといった工夫が必要です。
Groqについてよくある質問まとめ
- Groqとは何ですか?
Groqは、大規模言語モデル(LLM)の推論処理に特化したAIプラットフォームです。独自アーキテクチャで低レイテンシと高スループットを両立し、LLMの処理速度を飛躍的に向上させることが可能です。
- Groqで使えるAIモデルは?
Groqでは、以下のAIモデルを使用できます。どれを使うかは、ユーザーが選択できます。
- Mistralシリーズ: 処理効率と多用途性を兼ね備えたモデル群です。
- Llamaシリーズ: Meta AI開発の高性能モデル群で、様々なパラメータサイズを選べます。
- DeepSeek: 推論能力と計算効率に優れたモデルで、Mixture-of-Experts(MoE)アーキテクチャを採用しています。
- Qwen: Alibaba Cloud開発のモデルで、長文コンテキスト処理や多言語対応に強みがあります。
- Groqが高速で処理できるのはなぜですか?
- LPU(Language Processing Unit): LLMの推論処理に特化して設計された独自プロセッサで、「決定論的実行」により予測可能な高速処理を実現します。
- メモリ帯域幅の最適化: プロセッサとメモリの接続構造を最適化し、高いメモリ帯域幅と効率的なアクセスを実現することで、LLM処理全体の高速化に貢献しています。
- ハードウェアとソフトウェアの協調設計: LPUの能力を最大限に引き出す専用コンパイラを自社開発し、ハードウェアとソフトウェアの両面から最適化を行っています。
- Groqの主な特徴と、利用することでどのようなメリットがありますか?
- APIで簡単にアクセス可能: 開発者が直感的に利用できるAPI設計で、既存システムへの組み込みが容易です。
- LLMを高速で処理できる: 独自LPUによりトークン処理が極めて速く、即時応答が可能です。リアルタイムAIソリューションの実現や開発サイクルの短縮に貢献します。
- 処理精度が安定している: 最適化されたアーキテクチャにより、一貫した品質と再現性の高い出力を維持します。
- 主要なオープンソースLLMへの対応: LlamaやMistralなど、複数のオープンソースLLMからプロジェクトに適したモデルを選択できます。
- Groqはどのようにして使い始めることができますか?
- 公式サイトでアカウントを登録することで利用を開始できます。
- APIキーを取得し、Pythonなどのプログラミング言語から利用可能です。
- 他のプロバイダーからの移行も、APIキー設定、ベースURL設定、モデル選択といった手順で比較的容易に行えます。
- Groqは具体的にどのような業務で活用できますか?
- RAG(検索拡張生成): 検索結果の取り込みと応答生成を高速化し、高精度なリアルタイム応答システムを構築できます。
- カスタマーサポート: 応答遅延の少ない自然な会話体験が可能なチャットボットを構築し、顧客満足度向上に貢献します。
- 音声アシスタント: リアルタイムに近い応答速度で、自然な音声対話システムを実現します。
- IoT・エッジAI: 低遅延処理を活かし、産業用ロボットやスマートホームなど即応性が求められる分野で活用できます。
- Groqを利用する際に注意すべき点はありますか?
- 利用可能なモデルが限定されている: 主にオープンソースLLMが対象で、ChatGPTのような商用クローズドモデルは利用できません。また、Groqが最適化したモデルに限られます。
- 独自のハードウェア環境に依存している: Groqのクラウド環境に依存するため、オンプレミス運用やカスタムインフラへの組み込みには制約があります。
- 日本語での回答精度は低い場合がある: 搭載LLMは英語圏中心に開発されたものが多く、日本語の応答精度や自然さが劣る可能性があります。
まとめ
Groqは、LLMをこれまでにない速度で処理できる、革新的なプラットフォームとして注目を集めています。従来のGPU環境では実現が難しかった超低レイテンシな応答を可能にし、業務の高速化を実現すると期待されています。
今後AI活用を本格化させるにあたり、高速性と処理の安定性を重視するケースにおいては、Groqの導入が有力な選択肢となるでしょう。
ただし、Groqのような先端技術のポテンシャルを自社のビジネス価値へと最大限に転換するためには、利用するAIモデルの選定、既存システムとの連携、費用対効果の検証など、専門的な知見に基づいた計画と実行が不可欠です。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

