
【AI論文解説】Long-CLIP: Unlocking the Long-Text Capability of CLIP
最終更新日:2025年01月30日
記事監修者:石川 裕地

こんにちは、現役機械学習エンジニアの石川です。
本記事では、
画像と言語のマルチモーダル基盤モデルであるCLIP[1]は、非常に汎用的なモデルで、zero-shotでの画像分類などを簡単に行うことができたり、画像生成などにも活用されています。私もCLIPを用いて自分で集めた画像の分類などを行うことがあるのですが、一般的な物体はかなり高い性能で認識することが可能です。
一方で、色や形状などの特定の特徴を持った物体を認識させようとするとなかなかうまくいかなかったり、テキストを入力とした画像生成においては、テキストで指定した要素が画像に反映されない、ということが何度かありました。
この理由について、いろいろ調査していたところ、この論文を見つけましたので、この記事で解説したいと思います。
目次
論文サマリ
- 画像とテキストのマルチモーダルモデルであるCLIPの、詳細な説明文を扱うことができない、という問題点を解決するために、Long-CLIPという手法を提案
- このLong-CLIPは、学習済みのCLIPから簡単に拡張することが可能で、100万の画像とテキストのペアで追加学習するだけで、性能向上を実現
- Long-CLIPと元のCLIPの間では、潜在空間の整合性が取れているため、他のCLIPを用いた下流タスクでもLong-CLIPに置き換えることが可能
- CLIPと比較して、長いテキストを用いた画像検索タスクで約20%の性能向上を実現
本研究の背景
画像とテキストのマルチモーダル基盤モデルであるCLIPは、画像分類だけでなく、画像生成や画像検索など、幅広い領域で活用されています。
しかしながら、CLIPにはいくつか欠点があります。本研究では、その中でも「有効なテキストトークン数の短さ」と「物体と属性の誤認識」の二つに焦点を当てています。
有効なテキストトークン数の短さ
一つ目の欠点として、テキストトークンの長さが不十分であるという点が挙げられます。
例えば、下図に示されている詳細な文を用いたCLIPの画像検索では、文中のオレンジの文字で示されている”white columns and lamp posts leading down a sidewalk”などが、検索結果の画像に現れていないことがわかります。

また、CLIPを活用したテキストからの画像生成においても、入力のテキストで指定されている “antique street lamp”や”old-fashioned bicycle”といった一部の条件が反映されていないことがわかります (下図)。

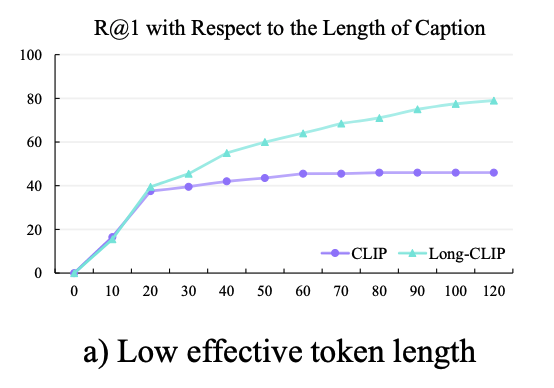
定量的な実験として、画像検索タスクにおいて、テキストの長さと検索性能の関係性を定量的に調査したところ、テキストトークン数が20を超えたあたりから、CLIPを用いた画像検索の性能が向上しないことがわかります(下図)。
このことからもCLIPは長い文を上手に扱えないということがわかります。
物体と属性の誤認識
別の欠点として、CLIPでは、物体とその属性を表す言葉が一致していなくても、高い類似度を出してしまうことがあります。

上図では、「レモンと茄子」の画像と、A~Dの4つのテキストの類似度を比較したの結果を示しています。Dの文では、「右にあるレモンが紫色で、左の茄子が黄色」と全く画像を表したものになっていないのにも関わらず、CLIPによる出力では最も高い類似度を出しています。
このように、CLIPは物体の属性を表す言葉の対応関係を誤って認識してしまうことがあります。
提案手法
本研究では、テキストにおける「有効なトークン数の短さ」と「物体と属性の誤認識」の問題を解決するために、Long-CLIPという枠組みを提案しています。
Long-CLIPには、以下の二つの手法が含まれています。
- Knowledge-preserved Stretching: テキストエンコーダーにおけるPositional embeddingの有効トークン数を増やすための手法
- Primary Component Matching: 長いテキストと短いテキストの両方に対応させるための手法
これらの手法は、既存のCLIPへの拡張が容易です。また、CLIPを一から大量のデータで学習する必要がなく、100万の画像と長いテキストのペアを用いて追加学習するだけで、長い文への対応が可能になります。
この追加学習は、8GPUを用いて、12時間で実行することが可能です。Long-CLIPは、元のCLIPの潜在空間と整合性が取れているため、他の下流のタスクにおいてCLIPとそのまま差し替えることが可能です。
ここからは各手法について、詳細に説明していきます。
Knowledge-preserved Stretching
研究背景でも触れましたが、従来のCLIPでは、テキストエンコーダーにおける有効なトークン数が20程度であることが実験的にわかっています。
このことは、positional embeddingの学習が、トークンの位置が20までのものしかうまくいっていない、ということを表しています。
位置が20以降のpositional embeddingを有効なものにするために、Long-CLIPでは、Knowledge-preserved Stretchingという手法を提案しています。
Knowledge-preserved Stretchingでは、以下のようにpositional embeddingを扱います。
- 位置が20までのpositional embeddingは、学習した値をそのまま採用する
- 位置が20以降のpositional embeddingは線型補完する
このように、位置20までのpositional embeddingを変更せずに、それ以降のpositional embeddingを線型補完することで、より長いテキストに対応できると主張されています。
Primary Component Matching
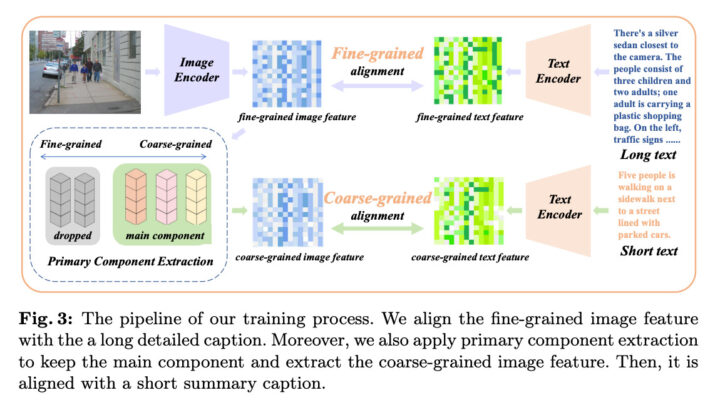
Long-CLIPでは、Knowledge-preserved Stretchingに加えて、長いテキストに対応させるために、長いテキストと画像のペアを用いて追加学習を実施します。
しかし、単に長いテキストだけで追加学習を行うと、短いテキストを用いた時の性能が落ちてしまうという問題が起きてしまいます。
この問題が起こる原因は、モデルが画像中のすべての属性を捉えようとするものの、それらの相対的な関係性や重要性の違いなどを区別しない状態になってしまうからであると論文では述べられています。つまり、長いテキストだけで学習を行うと、モデルが画像内の全ての属性を含めようとし過ぎてしまい、個々の情報の区別できなくなってしまうのです。
そこで、Long-CLIPでは、Primary Component Matchingという手法を提案しています。Primary Component Matchingでは、以下の二つの学習を行います。
- 長いテキストと、画像の対応関係の学習
- 短いテキストと、画像から抽出された主要な特徴量との対応関係の学習
このように、長いテキストと短いテキストの両方を用いて学習を行うことで、モデルが画像の詳細な情報と重要な情報の両方を捉えられるようになります。
実験
Long-CLIPの有効性を示すために、ゼロショット画像分類、画像検索、画像生成のタスクで性能を評価しています。
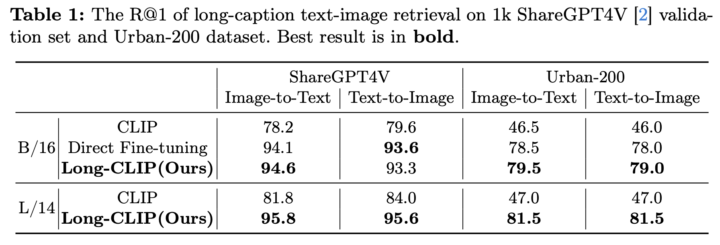
まず、長いテキストを用いたときの画像検索の性能を比較します。提案法は、CLIPと比較して大幅な性能向上を実現していることがわかります。
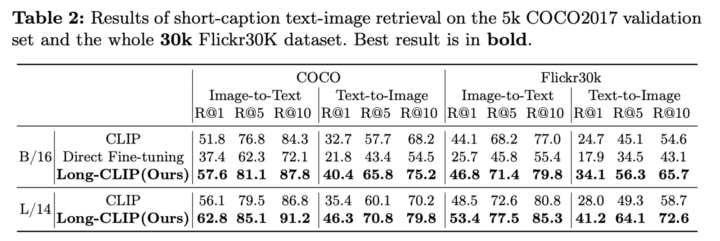
次に、短いテキストを用いたときの画像検索の性能比較です。Long-CLIPは、長いテキストを用いた画像検索だけでなく、短いテキストを用いた画像検索においても性能が向上していることがわかります。
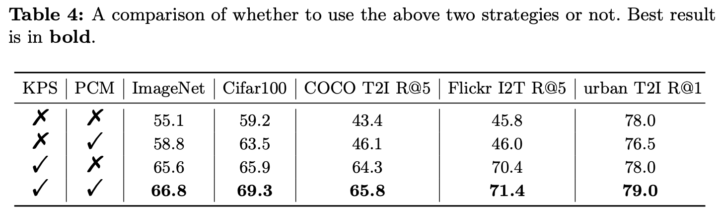
また、Long-CLIPに使用されているKnowledge-preserved Stretchingと、Primary Component Matchingの二つの手法の影響を調べた結果が下記の表です。いずれも性能向上に寄与していますが、特にKnowledge-preserved Stretchingが大きく性能向上に影響を与えていることがわかります
以下の図では、CLIPとLong-CLIPを用いたときの、画像生成の結果を比較しています。Long-CLIPの方が、入力テキストをより忠実に反映していることがわかります。

これらの結果から、Long-CLIPが従来のCLIPと比べて、より詳細なテキストに対応できるようになったことがわかります。
また、画像生成タスクにおいても、Long-CLIPは優れた性能を示しています。提案された手法を用いることで、詳細なテキストを反映した画像を生成することができることが確認されました。
以上のように、Long-CLIPは画像検索と画像生成の両方のタスクにおいて優れた性能を示しており、従来のCLIPの欠点を解消することに成功したと言えます。今後は、Long-CLIPを様々な応用先に適用することで、さらなる発展が期待されます。
今後の課題や応用について
Long-CLIPは、CLIPよりも長いテキストを扱えるようになりました。これにより、これまでの単語や文レベルの画像検索に加えて、より詳細な文章レベルでの画像検索が可能になります。
また画像生成の文脈では、反映させたい要素を繰り返し記述するなどのプロンプトの工夫をせずとも、意図した画像を生成しやすくなると考えられます。
Long-CLIPについてよくある質問まとめ
- Long-CLIPはどのようにCLIPの長文処理能力を向上させていますか?
Long-CLIPがCLIPの長文処理能力を向上させる方法は以下の通りです。
- Knowledge-preserved Stretching: テキストエンコーダーのPositional embeddingを拡張
- Primary Component Matching: 長文と短文の両方を用いた学習
- 100万の画像と長いテキストのペアを用いた追加学習
- 元のCLIPの知識を保持しながら、長文への対応を実現
- Long-CLIPの主な利点と、従来のCLIPと比較した性能向上はどの程度ですか?
Long-CLIPの主な利点と性能向上は以下の通りです。
- 長いテキストを用いた画像検索タスクで約20%の性能向上
- 短いテキストを用いた画像検索タスクでも性能が向上
- 画像生成タスクでより詳細なテキスト指示を反映可能
- CLIPの潜在空間との整合性を保持し、既存のCLIPベースのタスクに容易に適用可能
- 100万ペアのデータで12時間の追加学習のみで実現可能
- Long-CLIPが解決する従来のCLIPの主な問題点は何ですか?
Long-CLIPが解決するCLIPの主な問題点は以下の通りです。
- 有効なテキストトークン数の短さ(20トークン程度)
- 長い説明文を用いた画像検索や生成での性能低下
- 物体と属性の誤った対応付け(例:レモンが紫色、茄子が黄色という誤認識)
- 詳細な指示や条件を含む長文テキストの処理能力不足
引用
Zhang, B., Zhang, P., Dong, X., Zang, Y. and Wang, J., 2024. Long-clip: Unlocking the long-text capability of clip. arXiv preprint arXiv:2403.15378. (arXiv, GitHub)
[1] Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International conference on machine learning. PMLR, 2021.
AI Marketでは、
関連記事:「Clipとは?OpenAIのマルチモーダル基盤モデルの仕組み・活用事例・課題を徹底解説!」

慶應義塾大学大学院でAI研究を行いつつ、SoftBank社でAI研究開発に従事した後、現在は日本最大級のSNS企業にて、機械学習エンジニアをしています。画像・動画認識中心に研究開発を行い、国際学会での論文投稿実績も多数。本アカウントでは、AI関連の最新論文などの解説を行っています!
Xアカウントもぜひフォローお願いします!

