

AI開発の手順は?AIシステム構築の流れを徹底解説!生成AI/LLM時代の注意点もわかる完全ガイド
課題のどこをAIで解くのかを明確化したうえで、従来型(学習中心)/生成AI・LLM型(接続中心)/AIエージェント型(実行中心)のどれでいくかを早期に分岐させる...
生成AI、画像認識、AI開発企業等のAI会社マッチング支援サービス
課題のどこをAIで解くのかを明確化したうえで、従来型(学習中心)/生成AI・LLM型(接続中心)/AIエージェント型(実行中心)のどれでいくかを早期に分岐させる...

データ分析の価値は「データを集めること」ではなく、目的定義・前処理・手法選択・施策への翻訳という5ステップを継続運用できる仕組みとして設計することにある AIを...

多くの企業でAI導入のハードルとして、大量の学習データを収集するコストと将来の環境変化への懸念という課題を挙げられるケースが多いようです。メタ学習は、これらの課...

自社でAI開発を行うためには、オンプレミス、クラウド環境問わず適切な環境を構築しなければいけません。ハードウェアやソフトウェアを含め開発環境を整備することで、効...

AI開発や導入にかかるコスト圧縮に有効なのが、国や自治体が提供する補助金や助成金です。 近年では、AIを含むIT関連に多くの補助金を活用できるようになっており、...

製造現場の人手不足、医療現場の負担増大、高齢化社会における介護ニーズの増加…さまざまな課題に直面する現代社会において、自律型ロボットは課題解決の新たな一手として...

サポートベクターマシンは教師あり学習アルゴリズムの1つで、分類や回帰といった重要なデータ分析分野に適用されます。ディープラーニング以前から使われていたモデルです...
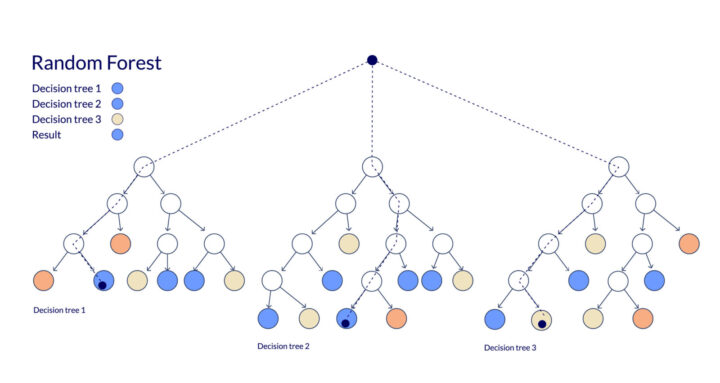
ランダムフォレストは、ビジネスの現場で日々直面する複雑なデータ分析の課題を解決する強力なツールです。 多数の決定木を組み合わせることで、従来の分析手法では見過ご...

大規模なAIモデルの導入は、高精度な業務自動化を可能にする一方で、運用コストやリソースの制約が課題となることがあります。知識蒸留(Knowledge Disti...

LLM(大規模言語モデル)が急速な進歩を遂げる中で、LLMを活用したシステムの導入に取り組む企業も増えています。しかし、LLMの真価を発揮させるには、開発から運...
