
世界モデルを実装するには?3つのコンポーネント・代表的手法・成功のポイントを徹底解説!
最終更新日:2026年01月18日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- 世界モデルは「視覚」「記憶・予測」「意思決定」の3層で構成され、これらを疎結合に設計する
- アルゴリズムの選定以上に、意思決定に直結する状態空間の定義と、物理法則を学習するための時系列の連続性を担保したデータ収集が重要
- 最初から高解像度・長時間の予測を目指さず、GPUリソースや学習時間を逆算した現実的な構成から着手
AIが世界の法則を自律的に学習し、シミュレーションを通じて最適な行動を導き出す「世界モデル」は、物理的な試行錯誤のコストが極めて高い製造、ロボティクス、自動運転といった分野のあり方を大きく変える可能性を秘めています。
しかし、世界モデルを実装したいが、どこから手を付けるべきかわからないと感じている方は少なくありません。
本記事では、世界モデルを実装するために押さえるべき3つのコンポーネントを軸に、DreamerV3やJEPAといった主要アルゴリズムの特性、さらには実装時に突き当たるGPUリソースやSim2Realの壁をどう乗り越えるかまで、実務に即した知見を解説します。
世界モデルの活用に強いAI開発会社の選定・紹介を行います 今年度世界モデルに関する相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 世界モデルの活用に強いAI開発会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
AI開発会社をご自分で選びたい方はこちらで特集していますので併せてご覧ください。
目次
世界モデルを構成する3つの主要コンポーネント
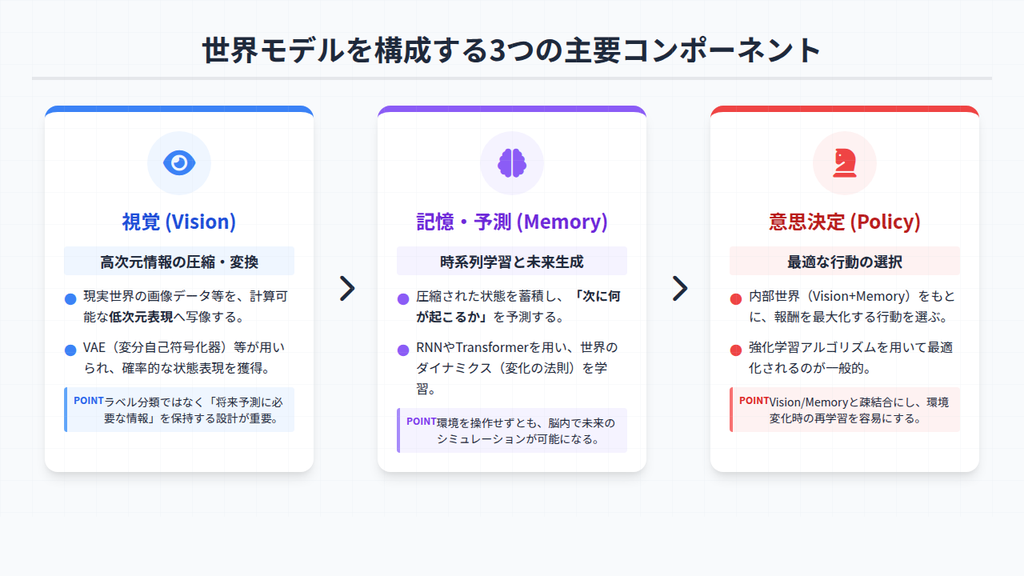
世界モデルの実装は、単一のモデルやアルゴリズムを導入すれば完結するものではありません。どう観測し、どう記憶・予測し、どのように行動へ結びつけるかという役割を分担するために、複数のコンポーネントを組み合わせて設計する必要があります。
コンポーネントは、大きく分けて3つです。
- 視覚(Vision)
- 記憶・予測(Memory)
- 意思決定(Policy)
それぞれの役割について解説します。
視覚(Vision)
視覚(Vision)は、現実世界から得られる高次元な情報を、学習・推論に適した低次元表現へ変換する役割を担います。
カメラで取得した画像やセンサーデータをそのまま扱うと、計算コストが膨大になり、後段の予測や意思決定の精度が不安定になります。そのため、視覚情報をいかに圧縮しつつ、クリアな状態を保持するかが実装上のポイントです。
例えば、工場のカメラ映像から「アームの位置」や「製品の距離」といった重要な情報だけを抽出する役割です。
実務・研究の双方で広く用いられているのが、VAE(変分自己符号化器)を中心とした表現学習手法です。VAEは、入力画像を潜在空間(latent space)へ写像し、そこから再構成する過程を通じて、世界の状態を確率的な表現として獲得します。
世界モデルの実装において重要なのは、Visionを認識モデルとして独立させる設計です。画像分類や物体検出のようにラベルに依存した視覚処理ではなく、将来を予測するために十分な情報を含んだ状態表現を学習する必要があります。
この違いを理解せずに既存の画像モデルを流用すると、世界モデル全体の性能が頭打ちになるケースも少なくありません。
記憶・予測(Memory)
世界モデル実装における記憶・予測(Memory)は、視覚の段階で圧縮された世界状態を時系列として蓄積し、状態遷移を予測するコンポーネントです。過去の情報を保存するのではなく、次に何が起こり得るのかを内部モデルとして学習します。
過去の情報を基に、「次に何が起こるか」を予測します。現在の状態と行動(Action)を入力すると、次の瞬間の世界の状態を脳内で生成します。
多くの世界モデルでは、RNN(LSTM・GRU)やTransformerを用いた潜在状態空間でのダイナミクス学習が採用されます。この仕組みにより、実際に環境を操作しなくても、頭の中で未来をシミュレーションすることが可能です。
RNN系とTransformer系の選択は、データ量・時間依存性・計算コストに直結します。比較的短い時間スケールでの予測ではRNNが扱いやすい一方で、長期的な依存関係や履歴を考慮する場合にはTransformerが有効です。
記憶・予測は、精度が高いだけでは不十分です。どの程度先の未来まで、どの解像度で予測するのかを明確にしなければ、計算コストが膨張し、実運用に耐えないモデルとなるでしょう。
意思決定(Policy)
世界モデル実装における意思決定(Policy)は、VisionとMemoryによって構築された内部世界をもとに最適な行動を選択するコンポーネントです。学術的には制御(Controller)と呼ばれることも多く、世界モデルを実務に適用した仕組みへと昇華させる役割を担います。
視覚と記憶・予測が作り出した「脳内シミュレーション」の中で、どの行動をとれば報酬(利益)が最大化するかを学習します。
意思決定の本質は、現実世界そのものではなく、Memoryが生成する潜在空間上の未来予測に対して意思決定を行う点にあります。実際に試行錯誤を繰り返さなくても、もしこの行動を取ったらどうなるかを内部シミュレーション上で評価し、目的関数が最大化される行動を選択できます。
実装面では、Policyは強化学習アルゴリズムによって最適化されるのが一般的です。
ただし、世界モデル全体と分離した設計にするのが重要です。VisionやMemoryと疎結合に設計することで、環境が変わってもPolicyのみを再学習する、あるいはPolicyを差し替えるといった運用が可能になります。
また、リアルタイム性と計算コストも考慮しなければいけません。理論上は長い未来をシミュレーションした方が良い意思決定が可能ですが、実システムではレイテンシが発生するリスクもあります。
そのため、どこまでを推論し、どこからを事前学習・最適化に委ねるのかを明確にする必要があります。
世界モデル実装においてPolicyは、事業要件・制御・制約を反映するレイヤーであり、経営や現場の意思が表れやすい部分でもあります。
世界モデルの活用に強いAI開発会社の選定・紹介を行います 今年度世界モデルに関する相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 世界モデルの活用に強いAI開発会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
世界モデル実装手法にはどんな選択肢がある?
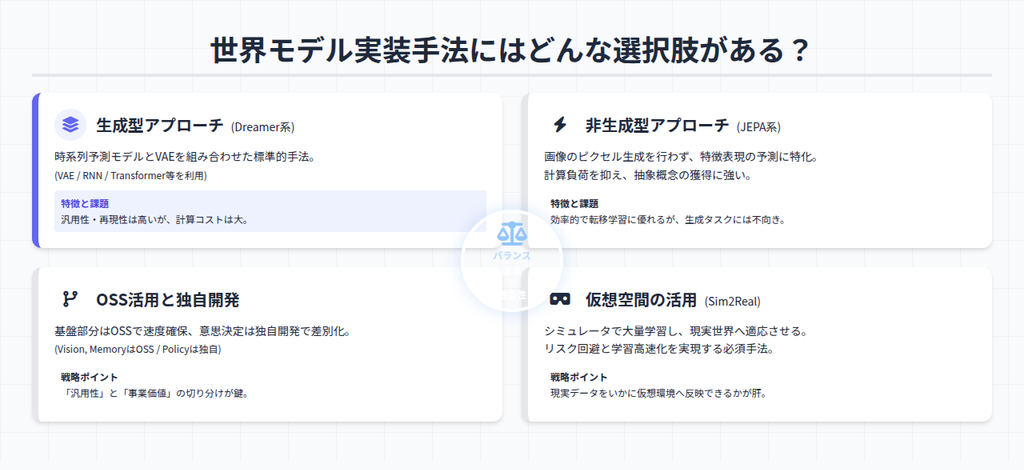
世界モデルをゼロから実装するには、高度な専門知識と多大な計算資源を要します。実務で成果につなげるためには、すでに確立された手法を適切に活用し、開発スピードと再現性を確保する視点が欠かせません。
実績あるアルゴリズムを土台にする
世界モデルの実装を前進させるうえで、実績あるアルゴリズムを土台にするのが基本的な手法です。Vision・Memory・Policyを一から設計することも理論上は可能ですが、検証コストと不確実性が大きく、PoC段階で停滞する可能性もあります。
そのため、既存のアルゴリズムを採用することで、実装の初速と再現性を大きく高められます。
Dreamer系
代表例として挙げられるのが、生成型世界モデルであるDreamer系アルゴリズムです。Dreamerは以下のような構成を持ち、世界モデルを実装させるための教科書とも言える枠組みを提供します。
- VAEによる表現学習
- 確率的ダイナミクスモデル
- 潜在空間上での強化学習
異なるドメイン(画像、数値、テキスト)のデータを固定のハイパーパラメータで学習できる汎用性の高さが魅力です。近年のDreamerV3では、学習の安定性とスケーラビリティがさらに改善されており、実務検証に耐える水準に達しています。
JEPA系
一方で、非生成型のアプローチとして注目されているのがJEPA系です。JEPAは画像や動画をピクセル単位で予測して生成する重い処理を避けて、将来状態の表現を予測することに焦点を当てており、計算効率と表現の汎用性に強みがあります。
生成クオリティを重視しない用途や、下流タスクへの転用を前提とする場合にはJEPA系が有効です。
既存アルゴリズムを採用するメリットは、実装速度と信頼性の両立にあります。既存のアルゴリズムには、論文・OSS・検証事例が揃っているため、設計上の正解パターンが前提となっており失敗を回避できます。
世界モデルの実装においては、アルゴリズムをそのまま使うかどうかではなく、どの型をベースにし、どこを自社要件に合わせて改変するかを見極めることが重要です。
オープンソース(OSS)活用と独自開発の境界線
世界モデルの実装を成立させるためには、どこまでをOSS(オープンソース)に委ね、どこからを自社独自で開発するのかという切り分けが欠かせません。
一般的に、VisionやMemoryといった基盤部分の実装は、OSSを積極的に活用する合理性が高い領域です。既存の世界モデル系リポジトリや表現学習・時系列予測のフレームワークは、すでに多くの検証が重ねられており実装品質と学習安定性が担保されています。
これらを活用すれば、世界モデルの実装に向けた土台を短期間で構築できます。そのため、多くの企業が、まずはGitHub上の主要OSSをベースに導入を進めます。
一方で、すべてをOSSに依存することが競争力につながるわけではありません。自社独自の価値が生まれるのは、データ設計・報酬設計・制約条件の組み込みといった業務文脈が強く反映される部分です。
例えば、どの状態を重要とみなすか、どの行動がリスクとされるかといった判断はOSSでは一般化できず、自社のナレッジそのものが反映されます。
実務面における切り分けの考え方としては、以下のように整理するのが有効です。
- 汎用性が高く差別化しにくい部分:OSS
- 再現困難だが事業価値に直結する部分:独自開発
何を学習させ、何を最適化し、どの意思決定を良しとするかという設計が、結果として自社独自の競争優位性になります。
この境界線を明確にせずに実装を進めると、OSSの改変に工数を費やしながら、事業的な差別化が生まれない状態に陥りがちです。世界モデル実装を成功させるには、技術的にできることと事業として守るべき価値を切り分ける視点が不可欠です。
仮想空間(シミュレータ)を活用した学習効率最大化
世界モデルの実装において、学習環境の設計はモデル構造と同等、あるいはそれ以上に重要です。現実世界のみを対象に学習を行う場合、データ収集コストの増大や、試行錯誤に伴うリスク、環境変化への対応遅れといった課題は避けられません。
こうした課題を回避する手段として有効なのが、仮想空間(シミュレータ)やデジタルツインを活用した学習です。現実環境を再現した仮想世界上で、世界モデルに大量の経験を与え、学習データを蓄積できます。
シミュレータは単なるテスト環境ではなく、世界モデルを育成するための基盤として位置づける必要があります。行動結果をフィードバックできる環境や、パラメータを意図的に揺らす設定、異常系やレアケースを再現できる設計は現実データだけでは補えない重要な学習材料になります。
ここで極めて重要になるのが、「Sim2Real(Simulation to Real)」、つまり仮想空間で得た知能を精度を落とさずに現実世界へ適応させる手法です。
これにより、世界モデルの汎化性能やロバスト性を高めることが可能です。また、仮想空間を活用することで、学習サイクルそのものを高速化できます。
世界モデル実装を事業に結びつけるには、現実世界での精度だけを追求するのではなく、どのような仮想環境でAIを育てるかがポイントになります。
世界モデルを独自データで学習する場合の計算リソース

世界モデルを自社固有の業務に適用させるためには、独自に収集・設計したデータによる学習が不可欠になります。
その際、避けて通れないのが計算リソースの問題です。特にGPUは、世界モデルの実装可否を決定づける重要な判断材料となります。
世界モデル実装において必要なGPU
独自データで世界モデル実装を進める際、GPU要件はモデルの賢さそのものよりも、学習をどのスケールで回すか(観測解像度・時系列長・モデルサイズ・バッチ設計)で決まります。
特に世界モデル実装は、表現学習と遷移予測に加えて、強化学習の更新も同時に走る構成が多く、一般的な画像分類や単体の生成モデル学習よりも、GPUメモリとスループットの両方を要求しがちです。
ここで押さえるべき前提は、推論と学習で必要になるGPUが別物という点です。
実装上の目安として、研究コミュニティで再現性が高い基準は単一GPUで回せる世界モデルです。例えばDreamer系は、論文上「各エージェントを単一のNVIDIA A100で学習した」と明記されており、世界モデルの実装における基準点になるでしょう。
また、タスクによってはDreamerV3相当の学習が、A100換算で0.3 GPU-days(約7.2時間)と報告される例もあり、PoCスケールなら単一のGPUでも試算可能です。
一方で、独自データ(高解像度カメラ、長い時系列、マルチセンサー)を扱う世界モデルの実装では、GPUのメモリ不足が早期に顕在化するでしょう。実際にDreamerV3の実装では、A100を前提とした設定をそのまま動かすとOOMになり、24GBのGPUでは厳しい可能性が議論されています。
そのため、PoCで回る構成と、本番を見据えた伸びる構成を分けて設計するのが実務的です。
GPU要件を左右する要因
世界モデル実装におけるGPU要件は、高性能のGPUを用意すれば解決するという単純な問題ではありません。実務では、設計上の選択がそのままGPUの消費量に直結します。
最もGPU要件に影響が大きいのは、観測データの性質です。
- 入力が静止画か動画か
- 解像度はいくつか
- センサが単一かマルチモーダルか
これらの要素によって、視覚部分の計算負荷は大幅に変わります。特に、動画入力や高解像度画像を扱う世界モデルを実装する際には、VAEやエンコーダのメモリ消費が急増しやすく、GPU要件が跳ね上がります。
他にも、時系列の長さと予測ホライズンが挙げられます。どれだけ長い履歴を保持し、どこまで先の未来を予測するかは、RNNやTransformerの計算量を左右します。
さらに、潜在表現の設計もGPU要件に含まれます。潜在次元数を大きくすれば表現力は高まりますが、その分計算量も増えます。
見落とされがちなのが、評価・検証のコストです。
学習そのもの以上に、評価用のロールアウトやシミュレーションがGPU時間を消費することがあります。そのため、PoC段階から評価設計を含めてGPU要件を見積もらなければ、後工程で想定外のコスト増につながります。
世界モデルの活用に強いAI開発会社の選定・紹介を行います 今年度世界モデルに関する相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 世界モデルの活用に強いAI開発会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
世界モデル実装を成功させるための実務ポイント

世界モデルは実務上、正しく実装することと、事業で使える形に仕上げることは別の課題になります。技術的に動作していても、開発が長期化したり、運用に耐えなかったりすれば価値は生まれません。
ここでは、世界モデル実装を現場で成功させるためのポイントを解説します。
PoC段階では完全な実装を目指さない
世界モデルの実装におけるPoC段階においては、理論的に優れた構成を完成させることではなく、自社の課題に対して機能するかを見極めることが本来の目的です。にもかかわらず、初期段階から完全なモデルを志向すると、検証に入る前に時間と計算資源を消費してしまいます。
実務では、Vision・Memory・Policyのすべてを高精度に実装する必要はありません。PoCでは、以下のように意図的に単純化した世界モデルで十分です。
- 入力解像度を下げる
- 潜在次元を小さくする
- 予測ホライズンを短くする
重要なのは、世界を内部表現として持ち、予測を経由して意思決定ができるという構造が成立するかどうかを確認することです。
また、PoC段階では評価軸を絞る必要もあります。最終的なKPIを満たす必要はなく、将来の改善余地が見える指標を一つでも確認できれば成功と捉えるべきです。
世界モデル実装は段階的に育てるのが前提になりますので、PoC段階では削れる要素を明確にしましょう。
状態空間(State Space)の戦略的抽出
「カメラ画像やセンサー値は多ければ多いほど良い」という考え方は、世界モデルの実装においては注意が必要です。予測や意思決定に無関係なノイズ(不要な視覚情報や微細な振動データなど)が混ざると、AIが学習すべき本来の因果構造がぼやけてしまいます。
業務上の意思決定に真に影響する変数は何かを見極め、AIが注視すべき「状態空間」を意図的に設計する必要があります。これは、事業ドメインの深い理解が求められる「エンジニアリングと事業理解の融合点」です。
因果関係を捉えるための時系列設計
世界モデルは「Aという行動をしたら、Bという状態に変化した」という時系列の連続性からルールを学びます。そのため、データの「切り出し方」が極めて重要です。
物理現象の変化に対してサンプリングが粗すぎると因果関係が途切れ、細かすぎると計算リソースを浪費し、長期的な予測が困難になります。また、重要な事象(故障、衝突、成功など)の前後データが欠落していると正しい遷移モデルは構築できません。
データ収集段階から、物理法則の学習に適した「時系列の整合性」を担保する設計が求められます。
データの偏りを克服するカバレッジと安全性
通常運転時のデータ(正常データ)だけで学習させた世界モデルは、いざという時の「異常系」や「境界条件」において全く使い物にならないリスクがあります。
現実世界では発生頻度が低いものの、発生すれば致命的なケースをどう学習させるかが鍵です。現実では収集困難なデータは、仮想空間で意図的に生成し、現実データと組み合わせて学習させます。
これにより、モデルの汎化性能(未知の状況への対応力)と安全性を飛躍的に高めることが可能になります。
計算コストと学習時間を前提に設計する
世界モデルの実装では、理論上の性能や最先端の構成よりも先に、計算コストと学習時間を前提条件とする必要があります。世界モデルにおいては試行錯誤のたびにGPUが消費され、学習サイクルが長期化しやすい特性を持ちます。
学習に数週間かかる構成では設計の改善やデータ追加の意思決定が遅れ、事業検証が停滞します。そのため、実装プロセスでは1回の学習に要する時間を、明示的に設計変数として扱うことが重要です。
具体的には、解像度・時系列長・潜在次元・バッチサイズといった要素を、性能ではなく学習時間とGPU予算から逆算して決めるアプローチが有効です。これにより、改善サイクルを回せる現実的な構成が見えてきます。
計算コストを無視した高性能志向の設計は、結果として検証回数を減らし、モデル品質を下げることにもつながります。
また、本番運用を見据える場合、世界モデルは一度学習して終わりではなく、定期的な更新を前提とした設計でなければ、運用フェーズで破綻します。
説明可能性を確保してブラックボックス化を避ける
世界モデルは、構造の複雑さゆえにブラックボックス化しやすい領域です。それぞれのフェーズにおいて「なぜその判断に至ったのか」が説明できなくなるリスクがあります。
- Vision:圧縮された潜在表現
- Memory:確率的予測
- Policy:行動選択
実務で説明可能性が不確実な状態に陥ると、運用・改善・責任分界が困難になります。
特に事業では、モデルの判断根拠を技術的・業務的に説明できる状態にしておかなければなりません。どの観測が影響したのか、予測のどの段階でズレが生じたのかを切り分けられなければ、再発防止も改善も行えません。
説明可能性を確保するための実装上のポイントは、各コンポーネントを意図的に分解・可視化する設計が効果的です。潜在空間の挙動をログとして観測する、予測分布を可視化するなど、後から検証可能な情報を残すことでブラックボックス化を防げます。
これらは性能を直接向上させる施策ではありませんが、長期的な運用では不可欠です。
世界モデルの実装についてよくある質問まとめ
- 世界モデルを実装するために必要なコンポーネントは?
世界モデルの実装は、単一のモデルではなく、役割の異なる3つのコンポーネントを組み合わせて成立します。
- 視覚(Vision):現実世界の観測情報(画像・センサ値など)を、高次元のまま扱うのではなく、将来予測や意思決定に適した潜在表現へ圧縮する
- 記憶・予測(Memory):Visionで得られた潜在表現を時系列として扱い、行動に応じた世界の変化を内部モデルとして学習する
- 意思決定(Policy):Memoryが予測した未来を評価し、目的や報酬に基づいて最適な行動を選択する
- 世界モデルは既存のアルゴリズムやOSSだけで実装できますか?
PoCレベルであれば、既存のアルゴリズムやOSSだけでも実装可能です。Dreamer系やJEPA系など、世界モデルの代表的な構成は論文とOSSが公開されており、基本的な動作検証や技術理解には十分活用できます。
ただし、事業利用を前提とする場合、OSSだけで完結するケースはほとんどありません。そのため、基盤部分はOSSを活用し、データ設計・報酬設計・運用ロジックは自社で作り込むという切り分けが、失敗しにくいアプローチになります。
- 自社の課題が本当に「世界モデル」で解決できるのか判断がつきません。
世界モデルは万能ではなく、物理的な制御や長期予測が必要な領域で真価を発揮します。AI Marketでは、貴社の業務プロセスをヒアリングした上で、世界モデルの適用妥当性を診断し、投資対効果の高い導入シナリオを共に検討します。
- 世界モデルの実装経験がある開発パートナーをどう探せばよいでしょうか?
世界モデルは先端領域であるため、対応できる企業は限られます。AI Marketは、独自のネットワークから世界モデルや強化学習に強みを持つ開発企業を厳選しています。貴社の業界特有の制約を理解し、伴走できる最適なパートナーをコンシェルジュが無料でご紹介します。
まとめ
世界モデルの実装は、観測・予測・意思決定を一体として設計するエンジニアリングであり、多くの企業が抱える課題でもあります。3つの構成要素が持つ役割と制約を理解したうえで組み上げていくことが成果を出すための前提となります。
実装を成功させるヒントは、技術が最先端であることよりも、現実的に回せることにあります。実績あるアルゴリズムやOSSを土台にしつつ、データ設計や評価軸といった自社固有の部分にこそ開発リソースを集中させることで世界モデルは初めて競争優位性へと転化します。
自社独自のデータをどう価値に変換し、どのタイミングで計算リソースを投入すべきか。その判断には、技術の深部と事業の勘所を繋ぐ視点が不可欠です。世界モデルの実装に向けた具体的なロードマップ策定や、最適な開発パートナーの選定にお悩みの際は専門的な知見を持つ第三者のサポートを受けることも有力な選択肢となります。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

