
Googleが会話型画像セグメンテーション機能をGemini 2.5に実装、自然言語で複雑な条件指定による物体認識を実現
最終更新日:2025年07月22日
記事監修者:AI Market ニュース配信チーム
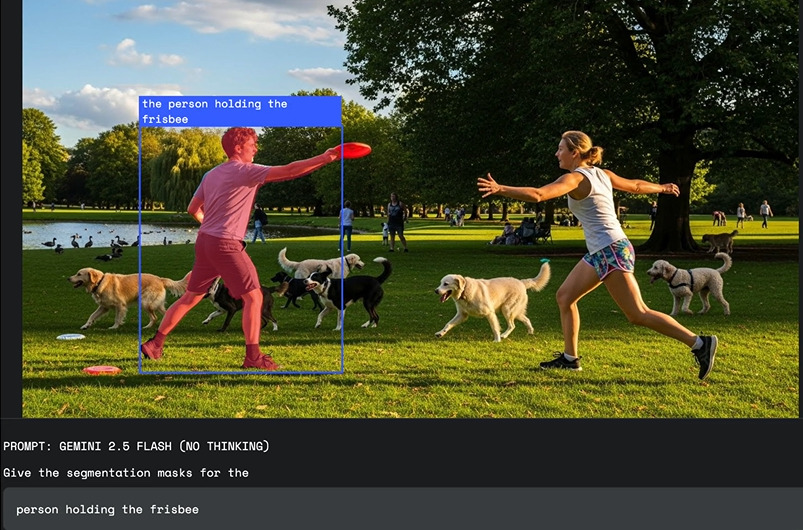
Googleが2025年7月21日に発表したGemini 2.5の会話型画像セグメンテーション機能により、「一番遠い車」や「立っていない人」といった複雑な条件を自然言語で指定して物体を特定できるようになった。
従来の単語ベースの物体認識を超え、関係性や抽象概念、条件文による画像解析が可能となり、創作活動から安全管理まで幅広い活用が期待される。
- Gemini 2.5に自然言語による複雑な物体認識機能を搭載、関係性や条件文での指定が可能
- 抽象概念の認識や多言語対応、画像内テキスト参照による高精度セグメンテーションを実現
- 単一APIでの提供により開発者体験を簡素化、創作から安全管理まで多様な用途に対応
Googleが発表したGemini 2.5の会話型画像セグメンテーション機能は、AI画像認識技術の発展において重要な転換点となる技術だ。
これまでのAI画像認識は段階的に進化してきており、初期のバウンディングボックスによる物体位置の特定から始まり、セグメンテーションモデルによる物体輪郭の精密な抽出、さらにオープンボキャブラリーモデルによる「青いスキーブーツ」や「木琴」といった詳細で珍しいラベルでの物体認識へと発展してきた。
しかし従来のモデルはピクセルと名詞のマッチングに留まっており、真の課題である会話型画像セグメンテーション、つまり複雑な記述的フレーズの解析による物体特定は実現されていなかった。
今回のGemini 2.5では、単純な「車」の認識を超えて「最も遠い車」といった複雑な条件指定による物体特定が可能となり、AIが人間の視覚的思考により近い形で画像を「理解」し「認識」できるようになっている。
この機能により、従来の制限された事前定義カテゴリから解放され、より直感的で強力な視覚データとの対話が実現される。
新機能の核心となる5つの主要クエリカテゴリーは、それぞれ異なる認識レベルでの物体特定を可能にしている。
物体関係カテゴリーでは、「傘を持っている人」といった物体間の複雑な関係性による特定、「左から3番目の本」といった序列による特定、「花束の中で最も枯れた花」といった比較属性による特定が可能だ。
条件ロジックカテゴリーでは、「ベジタリアン向けの食べ物」といったフィルタリングクエリや、「座っていない人」といった否定条件による絞り込みが実現されている。抽象概念カテゴリーでは、Geminiの豊富な世界知識を活用し、固定的な視覚定義が存在しない「損傷」「散らかり」「機会」といった概念的な要素の特定が可能となっている。
画像内テキストカテゴリーでは、外観だけでは物体の正確なカテゴリー区別が困難な場合に、画像内に存在するテキストラベルを参照した特定が可能で、これはGemini 2.5のOCR機能の強みを活かした機能だ。

多言語ラベルカテゴリーでは、英語以外の様々な言語でのラベル処理が可能で、グローバルな活用を想定した設計となっている。
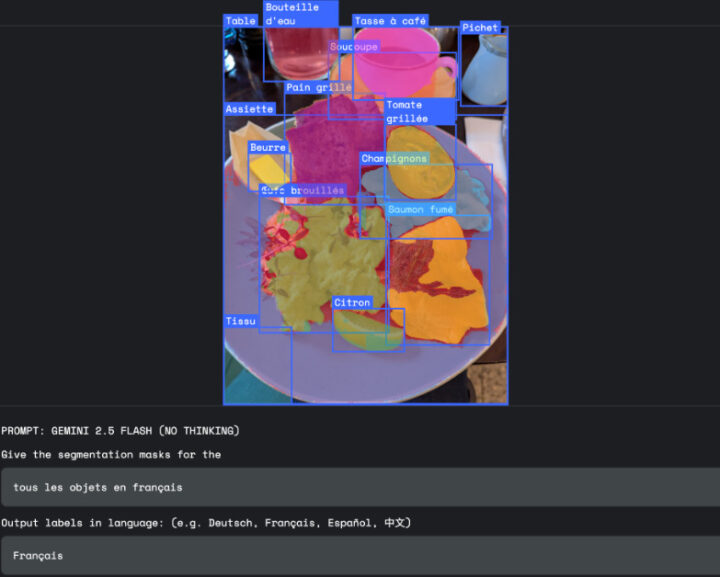
実際の活用場面では、3つの主要な用途が想定されている。クリエイティブ分野での活用では、従来の複雑な選択ツールを使用する代わりに、デザイナーが「建物の影」といった自然言語での指示によって直感的なメディア編集が可能となり、創作ワークフローがより流動的で直感的なプロセスに変化する。
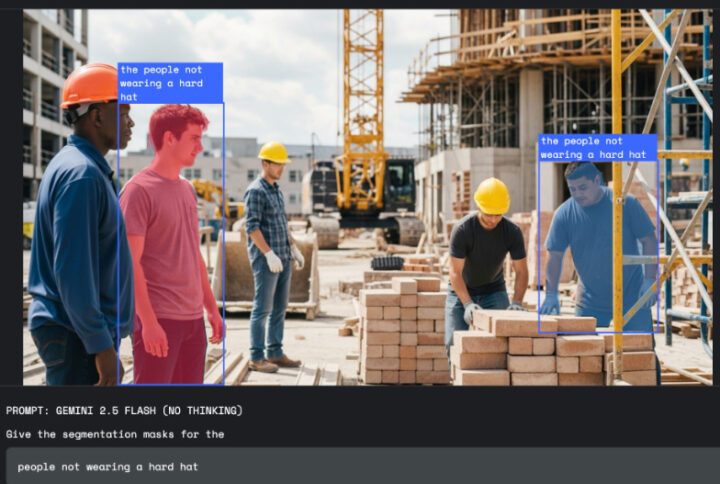
安全管理分野では、単純な物体認識ではなく状況の識別が重要であり、「工場でヘルメットを着用していない従業員をハイライト」といった条件文全体を一つのクエリとして理解し、非準拠個人のみを特定する精密なマスクを生成する。
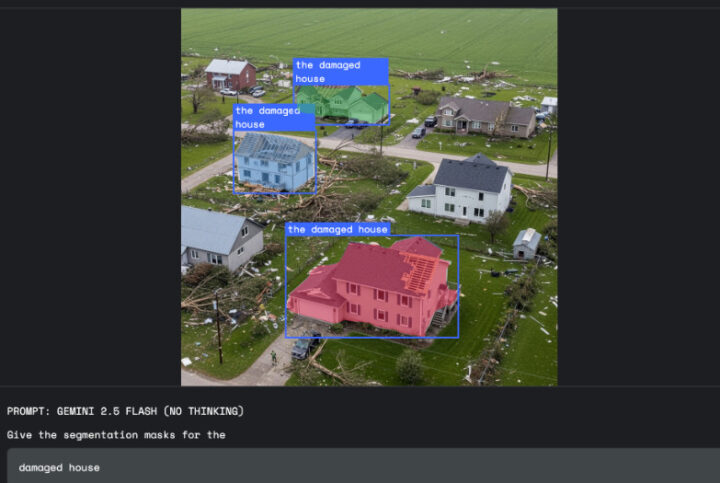
保険査定分野では、「損傷」という抽象概念が多様な視覚形態を持つ中で、「天候被害のある住宅をセグメント」といった指示により、Geminiの世界知識を活用して特定タイプの損傷に関連する具体的な凹みやテクスチャーを識別し、単純な反射や錆と区別する高度な判断が可能となっている。
開発者にとっての利点は2つの主要な側面で提供される。柔軟な言語対応により、厳格で事前定義されたクラスの制限から解放され、自然言語アプローチによって業界や利用者に特化した「ロングテール」の視覚クエリに対応できる柔軟性が提供される。
簡素化された開発体験では、単一APIでの提供により、個別の専門セグメンテーションモデルの検索、訓練、ホスティングが不要となり、洗練された視覚アプリケーション構築への参入障壁が大幅に低下している。
開発者はGoogle AI Studioの空間理解デモやPython環境でのインタラクティブな空間理解Colabを通じて即座に利用開始でき、Gemini APIの開発者ガイドやコミュニティフォーラムを通じたサポート体制も整備されている。
推奨されるベストプラクティスとして、gemini-2.5-flashモデルの使用、thinking予算の無効化、推奨プロンプトの使用とJSON出力形式の指定が挙げられている。
AI Marketの見解
Gemini 2.5の会話型画像セグメンテーション機能は、従来の画像認識技術の制約を大幅に解放する技術的ブレイクスルーと位置づけられる。
特に注目すべきは、単純な物体検出から複雑な推論を伴う視覚理解への転換であり、これによりAIが人間の視覚的思考プロセスにより近い形で画像を解析できるようになった点だ。
技術的には、大規模言語モデルと視覚モデルの高度な統合により、自然言語の複雑な意味構造を直接ピクセルレベルの情報と結びつける仕組みが実現されており、これは従来の分離されたNLPとコンピュータビジョンのアプローチを統合する重要な進歩と想定される。
ビジネス的観点では、単一APIによる提供が開発コストと複雑性を大幅に削減し、特に中小企業や新興企業にとって高度な画像認識機能へのアクセス障壁を低下させる効果が期待される。
市場への影響としては、創作ツール、安全管理システム、保険査定、医療画像診断など、多岐にわたる業界での既存ワークフローの変革が想定され、人間の専門知識とAIの高速処理能力を組み合わせた新たなサービス形態の創出が加速すると想定される。
会話型画像セグメンテーションに関するよくある質問まとめ
- 従来の画像セグメンテーションとの主な違いは何か?
従来は「車」といった単語での物体認識が主流でしたが、新機能では「一番遠い車」や「座っていない人」といった複雑な条件や関係性を自然言語で指定して物体を特定できます。
抽象概念や条件文による絞り込みも可能となっています。
- どのような業界での活用が想定されているか?
主要な活用分野として、デザイナーの創作活動での直感的な物体選択、工場や建設現場での安全コンプライアンス監視、保険業界での損害査定業務の効率化などが挙げられています。
単一APIでの提供により、様々な業界での導入が促進されると期待されています。

AI Market ニュース配信チームでは、AI Market がピックアップするAIや生成AIに関する業務提携、新技術発表など、編集部厳選のニュースコンテンツを配信しています。AIに関する最新の情報を収集したい方は、ぜひ𝕏(旧:Twitter)やYoutubeなど、他SNSアカウントもフォローしてください!
𝕏:@AIMarket_jp
Youtube:@aimarket_channel
TikTok:@aimarket_jp
過去のニュース一覧:ニュース一覧
ニュース記事について:ニュース記事制作方針
運営会社:BizTech株式会社
ニュース掲載に関するご意見・ご相談はこちら:ai-market-press@biz-t.jp

