
【AI論文解説】OmniHuman-1:たった1枚の画像から、リアルな人間の動画を生成する
最終更新日:2025年03月23日
記事監修者:吉井秀旭

近年、Diffusion model(拡散モデル)やTransformerを用いた汎用的なビデオ生成が急速に進歩し、画像分野と同様に大規模なデータセットから学習することで、より自然で多彩な映像を生成する技術が注目されています。
しかし、人間の姿を扱う「ヒューマンアニメーション(Human Animation)」においては、顔や全身、動作や手指の表現などを正確かつ多様に生成するために大規模データを活用しようとしても、音声同期(リップシンク)やポーズ検出の厳密な条件を満たすデータが大量には得られないなど、スケールアップの難しさが長らく課題となってきました。
本論文では、それらの課題を打破するために「Omni-Conditions(多条件)」という発想で大規模データを最大限に活かす手法を提案しており、実用度の高い高品質な人間の動画生成を可能にする新たな手法を示しています。
- 論文名:OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models
- 論文著者:Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, Chao Liang|ByteDance
- 論文提出日:2025年2月3日
- 論文URL:https://arxiv.org/abs/2502.01061
目次
本論文の概要
本論文では、一枚の参照画像から、音声・テキスト・ポーズといった複数の動作に関わる条件を同時に扱えるOmniHumanというモデルを提案しています。
既存のオーディオ駆動型やポーズ駆動型の手法では、データ不足を補うためにデータセットを厳しく絞り込んでしまい、結果的に学習可能な動作パターンが限定されがちでした。
そこでOmniHumanは、複数条件を一括で学習可能とする「Omni-Conditions Training」を導入し、動作に強く関わるポーズ情報から比較的弱いテキスト情報まで幅広いデータを混ぜて効率的に学習することで、多様なシーンや身体バリエーションに適応できる、より自然で自由度の高いヒューマンアニメーションを実現しています。
ポイント
- 弱い条件(テキスト等)から強い条件(ポーズ等)まで段階的に混在学習し、大規模データの活用効率を高めつつ、特定条件への依存や過学習を防いでいる
- 顔のみ、半身、全身など、異なる身体比率やアスペクト比でも同一モデルで対応可能な汎用性を実現し、従来の手法より自然で表現力の高い動画を生成
- 音声入力に基づくジェスチャーや手指、物体とのインタラクション表現が飛躍的に向上しており、リップシンク精度と合わせて実用性の高いヒューマンアニメーションを実現
提案手法
本研究の提案手法は大きく「OmniHuman」と「Omni-Conditions Training」の2つの要素から構成されています。OmniHumanはOmni-Conditions Trainingによって学習したモデルです。以下では、それぞれの要素を詳しく解説していきます。
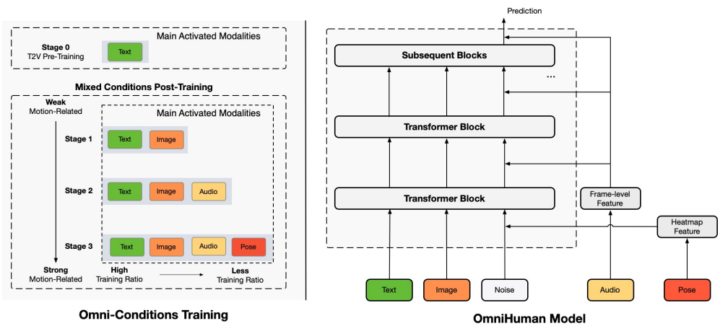
Omni-Conditions Training
これは、「どのような順番や比率でテキスト、音声、ポーズなどの条件を学習させるか」を工夫した学習方法です。まず、テキスト→動画に特化したDiffusionモデルを用意し、その後、画像・音声・ポーズといった条件を段階的に導入していきます。
こうすることで、データ不足やノイズの多さから生じる問題を最小限に抑えられる点と、それぞれの条件が競合することなく学習できる点がメリットです。結果として、より多様な動作パターンや身体表現を一つのモデルで再現できるようになります。
OmniHuman
OmniHumanは、テキストや音声、ポーズなど複数の形式の情報を入力できる動画生成モデルです。
元々は、動画を効率よく扱うために3DVAEでフレームを潜在空間に圧縮し、学習の最適化手法としてフローマッチングを使っているDiffusionモデルがベースとなっています。このDiffusionモデルはテキストからの動画生成が可能です。
さらにこのモデルに、Omni-Conditions Trainingによって音声・ポーズ情報などを順に組み込むことで、1枚の参照画像から自然な人間の動きを再現した動画を生成します。
顔の表情だけでなく全身のジェスチャーや手指の動きなどもリアルに表現できる汎用性の高さが特徴です。
実験結果
実験では、顔のみを扱うポートレート動画の生成タスクと、半身や全身を含むボディ動画の生成タスクにおいて、OmniHumanが既存手法と比較され、FIDやFVDなどの画質・動画品質評価指標や、リップシンクの精度を示すSync-Cなどの指標で一貫して高いスコアが報告されています。
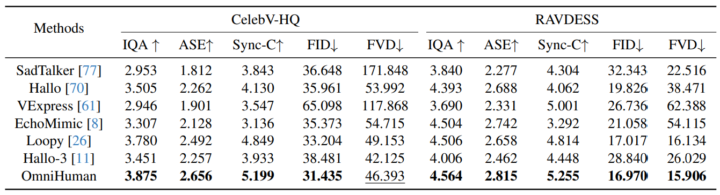

また、音声に合わせて口の動きや表情を自然に変化させるだけでなく、全身のジェスチャーや手指の動きが滑らかであることが示され、既存手法で課題とされてきた手の自然さや背景との統合にも大きな改善が見られます。

加えて、アブレーション実験では、音声やポーズの「学習データ比率」を変えた場合のモデルの挙動変化が検証されており、音声データの割合を下げすぎるとリップシンク精度が落ちる一方で、上げすぎると他のモーション表現が制限されるなど、混在比率の調整が非常に重要であることが明らかとなっています。

考察と今後の課題
本研究は、複数の動作条件を同時に扱うOmni-Conditions Trainingによって、音声やポーズなどの条件を混在させつつ、より幅広い人体動作を自然に再現できるOmniHumanを実現した点が大きな意義です。
従来は、フィルタリングや限定されたデータの利用で多彩な動作表現が難しく、特に音声とポーズの両立は困難でしたが、本手法により顔・全身・物体とのやり取りまで高品質かつ柔軟に対応できるようになりました。
一方で、長尺動画での整合性維持や微細動作の精度向上、さらにモデル規模の拡大に伴う計算コストやフェイク映像の悪用リスクといった課題も残されています。今後は、これらの問題へ対処しつつ、より軽量かつ安全に運用可能なモデルへと発展させる方向が期待されます。
OmniHumanについてよくある質問まとめ
- OmniHumanとは?
一枚の画像をもとに、人の動きを自然に再現できる動画を作る技術です。
音声やポーズ、テキストなど、いろいろな条件を組み合わせることで、表情から全身の動きまで幅広くカバーできます。
- 参照画像はどんな役割があるの?
参照画像によって、「どんな顔の人か」「背景はどうなっているか」を指定し、その見た目を維持したまま動きを作り出す役割を持ちます。似顔絵をもとに動くキャラクターを作るイメージです。
まとめ
本論文では、顔や全身の多彩な動作を生成できる大規模モデルを目指し、複数の動作条件を効果的に混合して学習する「OmniHuman」という手法を提案しています。
音声やポーズといった条件を組み合わせる際の学習戦略を工夫することで、これまでフィルタリングにより活用できなかった大量の動画データを取り込み、多様な場面や身体比率、動作バリエーションに自然に対応する高品質な人間の動画の生成を実現しました。
実験結果は、既存手法を超えるリップシンク精度や身体動作の多様性を示し、かつ参照画像に応じて任意のアスペクト比でも自然なアニメーションを行える柔軟性を確認しています。
AI Marketでは、

東京大学工学部でAIについて学びながら研究を行った後、東京大学大学院に進学し研究を続けています。研究内容は、錯覚を伴う身体運動を、制御や最適化に基づくシミュレーションでモデル化することです。本アカウントでは、AI関連の最新論文などの解説を行っています!

