
VLA(Vision-Language-Action)モデルとは?仕組み、VLMとの違い、重要モデル、メリット、課題を徹底解説!
最終更新日:2026年01月31日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- VLA(Vision-Language-Actionモデル)は、AIが「見て(Vision)」「言葉を理解し(Language)」「行動する(Action)」を統合
- 製造業のピッキング作業やサービス業の接客・案内など、これまで自動化が難しかった非定型的な業務への応用
- Google、Tesla、NVIDIAといった大手テック企業が開発を主導
工場の生産ラインや倉庫で稼働するロボットが、あらかじめ決められた作業しかできず、少しでも状況が変わると停止してしまうといった課題に直面していないでしょうか。もし、AIと連携したロボットが人の言葉を理解し、自ら「見て・考えて・動く」ことができれば、多くの業務はより効率的になるはずです。
物理世界でロボットがタスクを遂行するためのアプローチとして、VLA(Vision-Language-Action Model)が関心を集めています。
本記事では、VLA(Vision-Language-Actionモデル)について、その仕組みから最新動向までを網羅的に解説します。VLAが従来のロボット制御やVLM(Vision-Language Model)とどう違うのか、製造、医療、自動運転といった分野でどのようなメリットをもたらすのかを具体的に紹介します。
ロボティクスに強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 ロボティクスに強いAI会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
目次
VLA(Vision-Language-Action Model)とは?

VLA(Vision-Language-Action Model)は、視覚情報(Vision)・言語情報(Language)・行動(Action)を統合的に扱い、リアルタイムで意思決定と動作を行うAIモデルです。マルチモーダルなAIが進化する中で、物理環境でタスクを実行できるVLAが注目を集めています。
従来のAIは、画像認識や自然言語処理といった個別のタスクに特化しており、情報の理解と行動をシームレスにつなぐことが難しい課題がありました。そうしたなかで、VLAはカメラやセンサーから取得した映像と言語入力を同時的に処理し、自律型ロボットやAIエージェントが現実世界で具体的な行動を取るまでを一貫して行います。
VLAは、見る→理解する→動くを一つのモデル内で学習させることで人間のような柔軟な判断を可能にします。
また、VLAは世界モデルと競合ではなく、むしろ補完的に機能する関係にあります。世界モデルがVLAの内的シミュレーターとして機能する一方で、VLAは世界モデルの出力を受け取ります。
つまり、VLAは世界モデルと現実との橋渡し的な役割を担い、未来シナリオを生成します。
VLM(Vision-Language Model)との違い
VLAと似たモデルとして、VLM(Vision-Language Model)があります。VLMは画像とテキストを統合的に処理するマルチモーダルAIモデルです。
画像キャプション生成や画像検索、マルチモーダル質問応答といったタスクに強みを発揮します。しかし、VLMの出力はあくまで言語情報に留まるため、現実世界における行動を起こす機能は基本的に持ちません。
一方、VLAはVLMの能力を拡張し、認識した情報を基に行動計画を立て、物理的なアクションを実行する点が大きく異なります。VLMが画僧識別と言語処理までを担当するのに対し、VLAはそこから先の「どう動くか」を計算し、ロボットやデバイスを動作させるまでを担います。
つまり、VLMが認知レベルのAIであるのに対し、VLAは行動レベルまで踏み込む実行可能なAIといえます。
従来のロボット制御の限界
従来のロボット制御は、あらかじめ設定されたルールに基づき、決められた動作を正確に繰り返すことを得意としてきました。工場の生産ラインで一定の動作を繰り返す産業用ロボットはその代表例です。
しかし、このアプローチには環境の変化に対する柔軟性が低いという課題があります。少しでも位置がずれたり、対象物の形状や背景が変化したりするとエラーが発生するという問題が残ります。
また、視覚と言語情報を統合できない点も制約となっています。例えば、「机の上の青い本を取って」と指示されても、周囲を観察し、青い本を見つけ、取る動作はできません。
これらの制約が、多様な環境でのロボット活用を妨げていました。VLAはこうした課題を克服し、汎用的なロボット制御を実現する技術として期待されています。
ロボティクスに強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 ロボティクスに強いAI会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
VLAの仕組みをわかりやすく説明

VLAの仕組みは、視覚情報の処理・言語解釈・行動の計画と実行という3つの要素から成り立っています。以下では、それぞれの要素について解説します。
視覚情報の処理
視覚情報の処理では、カメラやセンサーから得られる画像データ・動画データを解析し、物体の情報を正確に認識するところから始まります。このとき活用されるのがLLM(大規模言語モデル)や、画像と言語を同時に扱う、マルチモーダル基盤モデルです。
マルチモーダル基盤モデルを用いて視覚エンコーダが画像中の特徴量を抽出し、物体検出やセマンティックセグメンテーションによって対象物を識別します。その結果は、言語処理モジュールや行動計画モジュールと共有され、次にどのような動作を行うべきかの判断材料となります。
VLAではこれらを統合的に扱うことで、環境変化に強く、柔軟に対応できる点が特徴です。これにより、未知の環境に対しても物理的に物体の位置関係を把握しやすくなります。
言語解釈
VLAにおける言語解釈は、プロンプトの指示を正確に理解し、次の行動計画につなげる重要なプロセスです。
この際、中心的な役割を果たすのが多くのLLMが採用しているTransformerアーキテクチャです。自己注意機構(Self-Attention)を用いて指示文全体の文脈を把握し、どの語が重要かを判断できます。
Transformerはマルチモーダル基盤モデルで解析された視覚情報を照合することで、どの物体が対象かを特定し、動作計画モジュールへと渡します。
従来のルールベースの自然言語処理では、言い回しが変わるだけで認識精度が低下する課題がありましたが、Transformerでは曖昧な表現に対応した解釈が可能です。ユーザーは日常的な言葉でもロボットに指示を出すことができ、直感的なヒューマン・マシンインタラクションが実現します。
行動の計画と実行
行動の計画と実行とは、視覚情報と解釈された指示をもとに、具体的な動作をシーケンスとして生成するプロセスです。ここで重要になるのが行動のトークン化という考え方で、ロボットの動作を離散的な単位(トークン)に分解し、文章を生成するかのように一連の行動を並べる手法を指します。
このトークン化により、モデルは抽象的な指令ではなく、実行可能なステップとして理解可能です。たとえば「赤いコップを持ってきて」という指示は、以下のようにトークン化されます。
- 対象の検出
- アームを伸ばす
- 把持
- 引き上げ
- 移動
- 置く
こうして生成された行動シーケンスは、リアルタイムにロボットの制御システムへ送られ、実際の動作として再現されます。
この行動のトークン化により、VLAはWeb上の膨大な知識を活用して、未知の物体や状況にも対応できる高い汎化能力を獲得します。例えば、「エナジードリンク」を直接学習していないロボットでも、Webデータから「疲れている人にはエナジードリンクが良さそうだ」と推論できるようになります。
そうすると、「疲れたから何か飲み物を」という曖昧な指示に対して、棚にあるエナジードリンクを選んで持ってくる、といった行動が可能になるのです。
行動のトークン化によって、既存の行動シーケンスを組み合わせたり、部分的に修正するだけで新しいタスクに対応できるため学習コストを大幅に削減できます。これにより、VLAは未知の環境や予期せぬ状況にも対応し、現実世界での実用性を高めています。
VLAの活用分野と実用化によるメリット

VLAはさまざまな産業や日常生活での活用が期待されています。ここでは、具体的な分野における応用例と実用化によるメリットを解説します。
製造業
製造業では、主にピッキング作業や組み立て工程の自動化において効果を発揮します。VLAを搭載したロボットは、カメラで作業エリアを認識し、生産計画をもとに部品を探して最適な動作経路を計算した上でピッキングできます。
また、人間の作業者が行っていた確認作業や仕分けも自動化できるため、現場において以下のメリットも享受できます。
- タクトタイム短縮
- ライン停止リスクの低減
- 作業ミス削減
- 人手不足対策
- 労災リスクの低減
- 品質の安定化
特に多品種少量生産やカスタム製品の組み立てでは、VLAによる適応的な制御が大きな価値を生み、生産効率と品質の両立を可能にします。
医療・介護
医療や介護の現場では、VLAの導入によって作業負担の軽減と安全性の向上が期待できます。例えば、病院では医療ロボットによる自律的な運搬が可能です。
介護施設では、入居者の移動補助や転倒検知をロボットが行うことでスタッフがより付加価値の高いケアに専念できる環境を整えられます。
これによって、医療現場におけるミスの減少やスタッフの肉体的・精神的負担の軽減につながります。この現象は連鎖して、患者や入居者の満足度向上にもつながります。
自動運転
自動運転の分野では、VLAが車両の周囲環境を認識し、運転ルートを立てるための中核技術として活用されることが期待されます。VLAを導入することで、交通標識や信号、歩行者の動きといった不規則な情報を統合的に理解し、人間らしい運転判断が可能になります。
また、音声による目的地指示や状況説明にも対応できるため、ドライバーとの自然なコミュニケーションが可能です。
サービス業
サービス業においてVLAは、接客や案内業務、清掃といった多様なタスクを自動化・効率化するための重要な技術となります。
| 分類 | タスク |
|---|---|
| ホテル業 |
|
| 飲食業 |
|
| 小売業 |
|
| 物流・宅配サービス |
|
| 商業施設・空港 |
|
例えばホテルや商業施設では、ロボットが利用客の質問に応じて館内案内を行ったり、荷物を部屋まで運んだりすることが可能です。
VLAで視覚と音声を同時に処理できるため、混雑状況や顧客の動きを認識し、最適なタイミングで行動を取ることができます。これにより、利用者の待ち時間短縮やサービス品質の向上が期待できます。
スマートホーム・パーソナルアシスタント
スマートホーム分野において、VLAは家の状況を把握し、異常検知に基づいて自律的に行動するパーソナルアシスタントとして機能します。
高齢者や子どもの見守りではカメラやセンサーから取得した情報を解析し、転倒や異常行動を検知することが可能です。転倒後に本人の応答がない場合は照明を点灯させたり、扉を解錠するといった高度な対応も実現できます。
ロボティクスに強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 ロボティクスに強いAI会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
重要なVLAモデル
VLAの研究開発は、世界中の大手テック企業や研究機関で進められており、すでに複数のモデルが登場しています。
RT-2(Google)
RT-2(Robotics Transformer 2)は、Google DeepMindが開発するロボティクスモデルです。人間が話す言葉を理解し、それを現実の動作に変換することを目指しています。
特定の作業手順を細かくプログラムしなくても、シンプルな指示だけでロボットが動作できる点が特徴です。
RT-2は、Webスケールの画像・言語データと、比較的小規模なロボットの動作データを組み合わせることで驚くべき能力を示します。RT-2の最大の特徴は、ロボット制御のために明示的に学習していないタスクでも実行できる「創発的能力」にあります。
例えば、RT-2を搭載したロボットに「ゴミを捨てて」と指示したとします。
ロボットは、Webデータから学習した「ゴミ」という概念と目の前にある空き缶や紙くずを結びつけ、それらをゴミと認識して掴んでゴミ箱に捨てるという一連のタスクを事前のプログラミングなしに実行できる可能性があります。
実際にGoogleの実験では、前モデルのRT-1が学習済みのタスク外での成功率が32%だったのに対し、RT-2は62%と成功率をほぼ倍増させました。これは、VLAが単なる研究段階の技術ではなく、実用化に向けて急速に進化していることを示しています。
RT-2の設計思想は、ロボットを人間の自然言語で操作可能な汎用エージェントへ進化させることです。現実世界での適応力とスケーラビリティを高めることで、自律ロボットの普及を加速させる役割を担うだけの可能性を秘めています。
Helix(Figure AI)
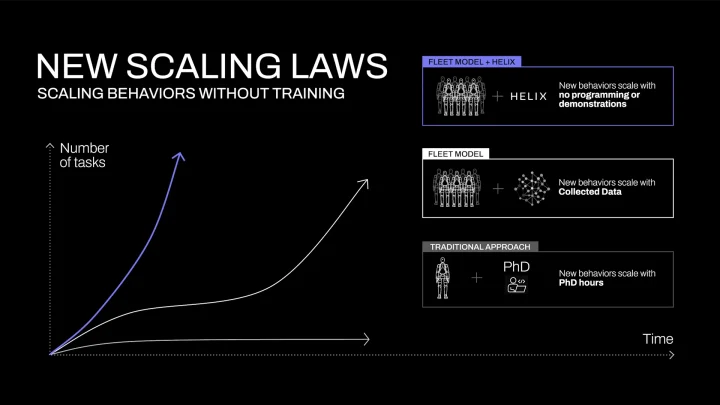
Helixは、ロボット開発企業Figure AIが発表したロボティクスモデルです。模倣学習(Imitation Learning)と人間によるデモンストレーション(実演)を組み合わせ、このデータに基づき、Webスケールの膨大な知識を持つAIモデルが状況を判断し、適切な行動を生成します。
これにより、運用を続ける中で未知の物体やタスクへの対応能力が向上し、モデルは自律的に賢くなっていきます。
倉庫や製造現場といった状況が変わりやすい環境でも、高い適応力を発揮します。新しい作業を一から教え込む必要も少なく、日々の運用で自律的に賢くなっていくため、現場の負担を軽減しながらの効率化が可能です。
使いながら成長するVLAモデルとして、Helixは運用コストを抑えつつも、長期的に性能を向上させるロボティクスソリューションになり得ます。Figure社はBMWの製造工場への導入を発表しています。
π0(Physical Intelligence)
π0は、サンフランシスコを拠点とするスタートアップPhysical Intelligence社が開発を進めるロボティクス向けのVLAモデルで、軽量かつ高汎用性を持つ行動計画AIとして設計されています。Physical Intelligence社は2024年に創業し、Googleの著名なロボット研究者などが集まって設立されたことで注目されています。
従来の大規模ロボティクスモデルが必要とした膨大なデータセットに依存せず、少量データ(Few-shot)やゼロショットでのタスク適応を可能にしています。
特に、現実世界の変化に対応できる柔軟性を重視されています。幅広い分野での利用が想定されており、現実的に導入が目指せるVLAモデルとして注目を集めています。
また、モデルがオープンソースで公開されていることもあり、学術界・産業界から大きな注目を集めている先進的なVLAモデルの一つです。
Gemini Robotics 1.5

Gemini Robotics 1.5は、Google DeepMindが展開するGeminiシリーズのロボティクス特化版で、自然言語処理と現実世界でのタスク遂行を目指します。多段階の行動計画を立てる思考と、その計画実行を重視して設計されており、単一指示の遂行に留まらないタスク対応を担っています。
技術的にはこのシステムは2つのモデルで構成されています。
- Gemini Robotics-ER 1.5 (Embodied Reasoning)
- Gemini Robotics 1.5 (Vision-Language-Action)
Gemini Robotics-ERは「頭脳」の役割を担います。ユーザーからの「部屋を片付けて」といった曖昧で複雑な指示を理解し、具体的なステップ(例:1.ゴミを拾う, 2.本を棚に戻す, 3.服を畳む)に分解する高レベルの計画を立てます。
一方、Gemini Roboticsは「身体」の役割を担います。「ER」モデルが立てた計画(例:「ゴミを拾う」)を受け取り、それを実行するための具体的なロボットの動き(アームの制御など)を生成します。
多段階の行動計画を立てる思考は、上記2つのモデルの連携によって実現されています。
Gemini Robotics 1.5は、人間が複雑なプログラムを書かなくても、自然言語で指示するだけでロボットを動かせる未来を描いており、ロボット活用の裾野を広げるモデルといえるでしょう。
Tesla Optimus(Tesla)
Tesla Optimusは、Teslaが開発を進める人型ロボットで、同社の自動運転AI技術を応用して人間に近い動作を実現することを目指しています。人間と同じ二足歩行の形態を持ち、重量物の運搬や組立作業といった現場業務で活用可能です。
特に注目されるのは、Teslaが持つセンサーデータや走行データを活かして、現実世界での認識と行動を高度に統合している点です。世界中で走行する数百万台のTesla車両から収集した膨大な映像データをAIのトレーニングに活用しています。
これにより、Optimusは周囲の状況を理解して柔軟に対応することが可能になります。
デモ動画では、洗濯物をたたむ、卵を割らずに持つといった繊細な作業やヨガのポーズで片足立ちのバランスを取るなど、AI制御による自律動作の能力が飛躍的に向上していることが示されています。
将来的には人手不足が深刻な分野で活躍することが期待されており、人間と共存する汎用ロボットとしてのポジションを確立しつつあります。
NVIDIA Project GR00T(GR00T N1)
NVIDIA Project GR00T(GR00T N1)は、NVIDIAが発表した次世代ロボティクス基盤で、視覚・言語・行動を統合するマルチモーダルなGPUアクセラレーションで動作させることを目的としています。現実世界の物理挙動を再現した環境で、大規模にデータを生成・学習できる点が特徴です。
GR00T N1は、NVIDIAが培ってきたGPUコンピューティングとAIソフトウェアエコシステムを活かし、学習から推論、動作制御までを統合的にサポートします。これにより、複雑なタスクを効率的にこなし、人間と協働できるロボットの開発を加速させています。
NVIDIAはパートナー企業や研究機関との協力も進めていることから、GR00T N1はオープンなロボティクス開発基盤としても位置付けられています。
VLAの実装に向けた技術的課題

VLAを実際の現場に導入するには、いくつかの技術的課題が残されています。
学習データの不足
VLAの性能を引き出すためには視覚・言語・行動の3要素を網羅したデータが必要です。しかし、汎用的に応用できるマルチモーダルデータセットはまだ十分に整備されていません。
特に行動データは収集コストが高く、ロボットによる実環境での試行やシミュレーションを通じて集める必要があるためデータが不足しがちです。データの不足はモデルの学習バイアスや汎化性能の低下を招き、未知の状況に適応できない原因となります。
この課題への対処方法として、シミュレーション環境での大量データ生成や模倣学習・自己教師あり学習を組み合わせる手法が最適です。また、企業固有の作業環境に合わせたファインチューニングによって、不足分を補完可能です。
安全性
ロボットが誤った行動を取れば人や設備に損害を与えるリスクがあるため、安全に動作するシステム構築が不可欠です。例えば、人間が近くにいる状況では速度を自動的に制御し、衝突や転倒を防げるようにしなければいけません。
現場で安全に運用するためには、複数のレイヤーでリスクを低減する仕組みが必要です。有効とされる対策は、以下の通りです。
| 手法 | 詳細 |
|---|---|
| リアルタイム監視 | センサーやカメラで周囲の状況をモニタリングし、緊急停止や速度制限を即座に実行 |
| シミュレーションによる事前検証 | NVIDIA OmniverseやIsaac Simのようなシミュレーション環境でテストし、衝突や誤作動のリスクを事前に排除 |
| 信頼性評価と出力検証 | モデルが生成した行動計画に対して確率的信頼度を評価し、しきい値を下回る場合は人間が確認する |
| 人間との協働設計(HRI) | 作業員が近くにいる場合は協調モードに切り替え、速度や力を制御するコボット的挙動を採用する |
| サイバーセキュリティ対策 | 通信の暗号化、アクセス認証、多層防御を徹底する |
これらの対策を組み合わせることで、安全性と信頼性を担保しつつ、現実世界での稼働を拡大できます。特に産業現場や公共空間では、人とロボットの共存を前提とした多層的な安全設計が不可欠です。
汎化性能
VLAにおける汎化性能とは、学習したタスクや環境を超えて、新しい状況にも対応できる能力を指します。この汎化性能が低いと、現場ごとに再学習や再設定が必要となり、導入コストが増加してしまいます。
この課題に対しては、シミュレーションと実機データを組み合わせた学習や、少量のデータから効率的に学習するFew-shot・Zero-shot学習の活用が効果的です。
ロボティクスに強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 ロボティクスに強いAI会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
VLAについてよくある質問まとめ
- VLA(Vision-Language-Action Model)とは?
VLAは、視覚情報(Vision)と言語情報(Language)を同時に処理し、それに基づいて具体的な行動(Action)を計画・実行するマルチモーダルAIモデルです。
- VLAが従来のロボット制御と比べて優れている点は?
従来のロボットはルールに基づいて動くため、環境が変化すると再設定が必要でした。一方でVLAは視覚認識と言語理解を統合し、状況に応じて動作を調整できるため、未知の環境や新しいタスクにも対応可能です。
- VLAとVLM(Vision-Language Model)の違いは?
VLMは画像や映像を理解して言語で説明する能力を持ちますが、実際に行動することはできません。一方、VLAはVLMの能力を基盤に、得られた情報から行動計画を立てて実行します。
つまり、VLMが認識・説明に特化しているのに対し、VLAはタスクを完遂する実行能力まで備えています。
- 代表的なVLAモデルとは?
VLAの代表的なモデルとして知られているのは、以下の通りです。
- RT-2(Google DeepMind)
- Helix
- π0
- Gemini Robotics 1.5
- Tesla Optimus
- NVIDIA Project GR00T (GR00T N1)
- VLAはどのような分野で活用されていますか?
VLAは幅広い分野での実用化が期待されています。
- 製造業:部品ピッキングや組立作業の自動化
- 医療・介護:薬剤運搬や患者の見守り、移動支援
- 自動運転:交通環境を理解し、安全な走行計画を立案
- サービス業:接客、配膳、清掃など顧客体験を向上
- スマートホーム:転倒検知や家庭内アシスタントとして安全性と快適性を向上
まとめ
VLAは、視覚情報・言語情報・行動をマルチモーダルに扱うモデルです。RT-2によって確立された概念ですが、現在ではさまざまなモデルがリリースされており、ロボティクス分野での実用化が期待されています。
一方で、VLAを自社の環境に導入し、その価値を最大限に引き出すためには専門的な知見が不可欠です。どのAIモデルが自社の課題に適しているのか、学習に必要なデータはどのように準備すればよいか、そして何より現場で安全に運用するための設計はどうすべきかなど検討すべき項目は多岐にわたります。
もし、VLAの導入に関する具体的なステップや、自社のユースケースにおける実現可能性についてさらに詳しく知りたい場合はAI導入の専門家へ相談することをおすすめします。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

お電話で無料相談
WEBから無料相談(60秒で完了)
今年度問い合わせ急増中
Warning: foreach() argument must be of type array|object, false given in /home/aimarket/ai-market.jp/public_html/wp-content/themes/aimarket/functions.php on line 1594
Warning: foreach() argument must be of type array|object, false given in /home/aimarket/ai-market.jp/public_html/wp-content/themes/aimarket/functions.php on line 1594
