
AI駆動開発のデータパイプラインとは?重要性・構成要素5ステップ・注意点を徹底解説!
最終更新日:2026年03月04日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- AI駆動開発でLLMに自社の開発ルールや既存コードを正しく理解させるには、RAG(検索拡張生成)による継続的な情報供給が不可欠
- エンジニアの頭の中や過去のチャットログに眠る独自資産を構造化してパイプラインに乗せる
- 単にコードを書かせるだけでなく、AIが自らパイプラインを巡回してエラーを自己修正する「Agentic Workflow」の構築
GitHub Copilotなどのコード生成AIを導入したものの、期待したほど生産性が上がらない、あるいは自社のコーディング規約に沿わないコードが量産されてしまうといった課題に直面していないでしょうか。AIを単なる「便利な筆記用具」として使う段階は終わり、現在は「組織の知見をいかにAIに同期させるか」という基盤づくりのフェーズに移行しています。
本記事では、AI駆動開発におけるデータパイプラインの重要性や従来のETLとの違いや構築の5ステップ、そして自社の独自資産をAIの知能へと変換する戦略的なポイントを解説します。AIを「自社専用の熟練エンジニア」へと育てるための具体的な道筋を提示します。
コード生成・解析に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 コード生成・解析に強い会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・リファクタリング、ソース解析、AI駆動開発等
AI開発会社をご自分で選びたい方はこちらで特集していますので併せてご覧ください。
目次
AI駆動開発に欠かせないデータパイプラインとは?
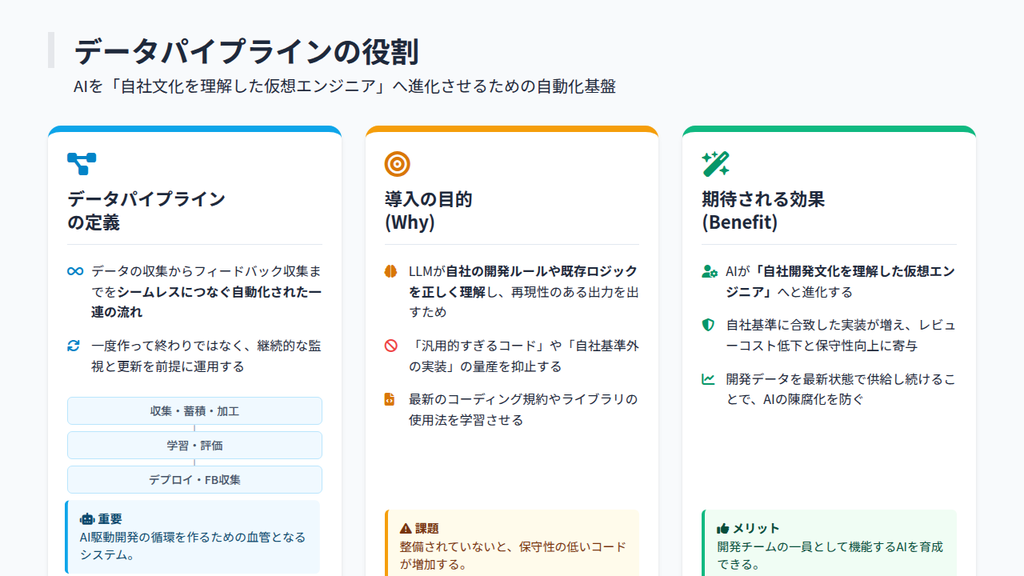
AI駆動開発におけるデータパイプラインとは、データの収集・蓄積から、加工、モデルの学習、評価、デプロイ、そして実稼働後のフィードバック収集までをシームレスにつなぐ自動化された一連の流れを指します。目的は、LLMが自社の開発ルールや既存ロジックを正しく理解し、再現性のあるアウトプットを出すことです。
例えば、最新のコーディング規約や設計思想、ライブラリの使い方が整理されていないと、LLMは汎用的なコードしか生成できません。その結果、自社基準に合わないコードや保守性の低い実装が量産されます。
データパイプラインを通じて開発データを最新状態でLLMに供給することで、AIは自社の開発文化を理解した仮想エンジニアへと進化します。
AI駆動開発におけるデータパイプラインと従来のシステム開発におけるETLの違い
従来のシステム開発におけるデータパイプラインは、分析用データの収集・加工(ETL)を指していました。しかし、AI駆動開発におけるデータパイプラインの最大の違いは、その循環性と自律性にあります。
| 特徴 | 従来のデータパイプライン (ETL) | AI駆動開発のデータパイプライン |
|---|---|---|
| 目的 | データの可視化・レポート作成 | モデルの精度維持・自動更新 |
| 処理対象 | 構造化データが中心 | 非構造化データ(画像・音声・LLMのログ)含む |
| 更新頻度 | 日次・週次などのバッチ処理 | データのドリフト(変化)に応じた動的更新 |
| 成否判定 | データが正しく変換されたか | 推論の精度、ビジネスKPIへの寄与度 |
コード生成・解析に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 コード生成・解析に強い会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・リファクタリング、ソース解析、AI駆動開発等
なぜAI駆動開発でデータパイプラインが重要なのか?
「AIを導入する」=「賢いアルゴリズムを買ってくる」という誤解がいまだに根強いですが、現実は異なります。AIの賢さは「どのような鮮度のデータを、どれだけ効率よく食べさせ続けられるか」というパイプラインの設計に依存します。
最新かつ正しい情報が必要
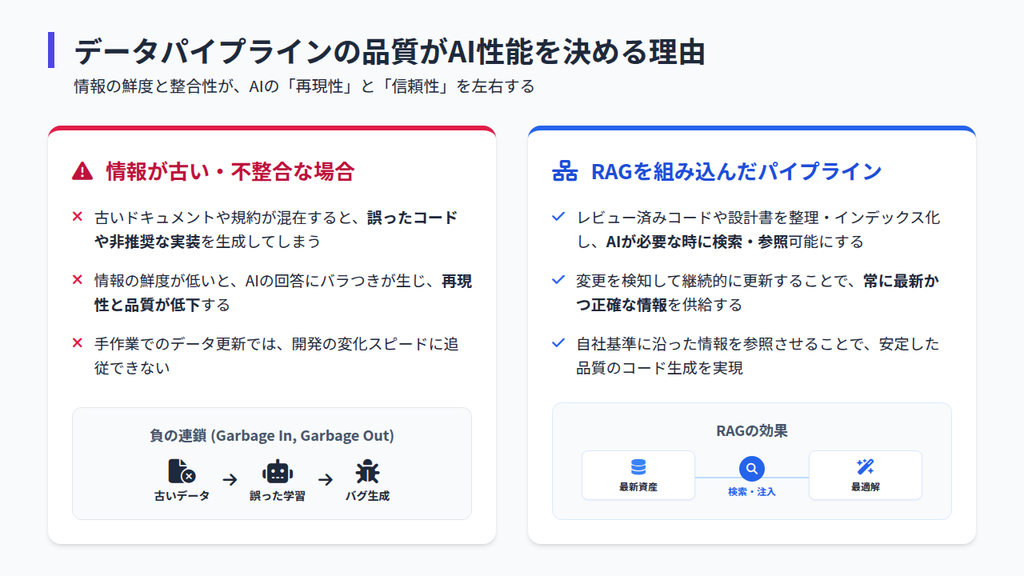
LLMは、古いドキュメントやプロジェクトごとにバラバラなコーディング規約をそのまま学習・参照すると、誤ったコードを生成します。これは、参照しているデータが古い、もしくは不整合であることが原因の一つです。
AI駆動開発をスケールさせるためには、LLMに最新かつ正しい情報を供給する仕組みが欠かせません。そこで重要になるのが、RAG(検索拡張生成)を組み込んだデータパイプラインです。
RAGは、レビュー済みコードや設計ドキュメントを整理・更新し、AIが必要なタイミングで参照できる状態を保ちます。RAGの導入により、LLMは最新かつ正確な情報を常に参照でき、自社基準に沿ったコードを生成できます。
アジリティ(開発速度)の向上
データパイプラインが整備されていない現場では、エンジニアが手作業でデータを整形し、モデルを学習させています。これは「手回し発電」で工場を動かそうとするようなものです。
自動化されたパイプライン(CI/CDならぬCT: Continuous Training)があれば、市場の変化に合わせてAIを即座にアップデートできます。
技術負債の抑制
「とりあえずAIモデルを作ってみた」というPoC止まりのプロジェクトの多くは、運用段階でデータ構造の変化に対応できず、数ヶ月で「使い物にならないAI」へと劣化します。堅牢なパイプラインは、モデルの劣化(ドリフト)を検知し、自動で再学習を促す「品質管理部門」の役割を果たします。
AI駆動開発におけるデータパイプラインの基本構成5ステップ
本章では、AI駆動開発におけるデータパイプラインの基本的な構成を紹介します。
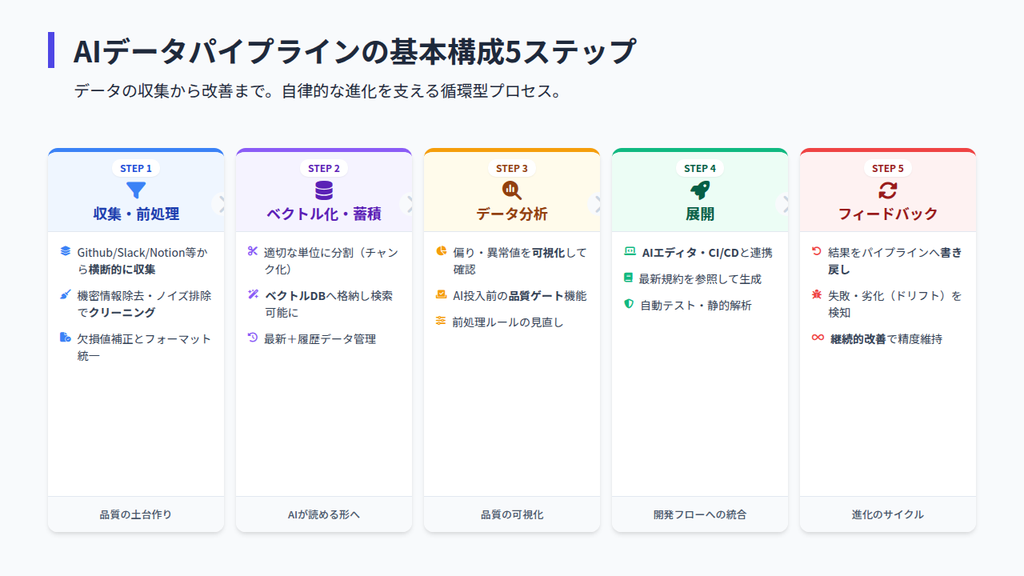
1.データ収集・前処理
データ収集と前処理は、AIのアウトプット品質を決める重要な工程です。
AI駆動開発では、コードだけでなく、設計や議論・意思決定の履歴も学習の対象です。そのため、GitHubやSlackでのディスカッションログ、Notionにアップされている設計書、Jiraチケットなど複数のツールに分散したデータを横断的に集約する必要があります。
また、収集した生データはAIにとって扱いづらく、誤った学習や参照の原因になります。そのため、以下のようなデータの前処理が必要です。
- 欠損値や異常値の処理
- 表記揺れや単位の統一
- 重複データの除去
- コード内の機密情報削除
- 古い設計図や不要ドキュメントの除外
AI駆動開発を安定して運用するためには、前処理段階でノイズを徹底的に排除することが重要です。
2.データのベクトル化・蓄積
データのベクトル化・蓄積は、AIが実際に学習・参照できる状態に持っていくための工程です。情報を小さな断片(チャンク)に分け、意味の近さで検索できる「ベクトルデータベース」に格納します。
AIは人間のように文脈や意味を直接理解できないため、データをAI用の特徴量へ変換する必要があります。具体的には、以下のような処理を行い、数値的・構造的に扱いやすい形式へと整えます。
- 学習用特徴量への変換
- 正規化・カテゴリ変換
- 時系列データの整形
変換されたデータは、データウェアハウスやデータレイクへ蓄積されます。
AI駆動開発では、データ更新に応じた再学習や性能検証が必要なため、最新データに加え、過去の履歴の管理も必要です。
データのベクトル化・蓄積を適切に設計することで、モデルの性能が継続的に向上し、AI駆動開発を発展させ続けられます。
3.データ分析
データ分析は、データパイプラインが正しく機能しているかを確認し、改善につなげるための工程です。AIに投入する前にデータを分析すると、品質の問題や偏りを早期に発見できます。
以下が具体的な分析内容です。
- 欠損値や異常値の発生状況
- データ量や項目ごとの偏り
- 時系列による変化
これらを可視化することで、AIが学習するデータを人が把握できるようにします。
分析の結果、問題が見つかった場合は、以下のようなデータや前処理、変換ルールを見直し、パイプラインに反映します。
- クレンジング条件の調整
- 特徴量設計の見直し
- 不要データの除外や追加
このフィードバックを繰り返すことで、データパイプラインが改善され、データ品質も持続的に向上していきます。
4.展開
データパイプラインで整備されたデータや知識は、実際の開発フローに組み込まれて初めて価値を発揮します。そのため、AI駆動開発では、AIエディタやCI/CDツールと連携し、開発者がAIを日常的に活用できる状態を作ることが重要です。
例えば、AIエディタ上では、最新のコーディング規約やレビュー済みコードを参照しながらコード生成や修正を行えます。
5.フィードバックループ
AIが生成したコードが、実際にビルドを通ったか、テストに合格したか、レビューで修正されたかという情報をパイプラインに書き戻します。CI/CDパイプラインと連携することで、生成されたコードに対して自動テストや静的解析を実行し、品質を継続的にチェックすることも可能です。
このように、データパイプラインと開発ツールをつなぐことで、AIのアウトプットを即座に改善できる仕組みを構築できます。
コード生成・解析に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 コード生成・解析に強い会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・リファクタリング、ソース解析、AI駆動開発等
AI駆動開発におけるデータパイプライン構築のポイント

本章では、AI駆動開発で構築するデータパイプラインのポイントを紹介します。
関連記事:「AI駆動開発の導入プロセスガイド!手順・成功へのコツ・従来開発との違い・よくある課題を徹底解説」
自社のデータ資産をどう生かすか?
AI導入の成否は、「汎用AIをいかに自社仕様へ染め上げるか」にあります。その鍵を握るのが、社内に眠る独自資産の特定と活用です。
独自資産は、最新のソースコードだけではありません。過去の泥臭い不具合修正の記録、仕様変更に至ったSlackでの議論、あるいはベテランの頭の中にしかない「暗黙のルール」が反映された古い設計書などです。
これらは現状、多くが属人化し、活用されないまま放置された「埋没資産」となっています。
パイプライン構築の第一歩は、これらをAIが参照可能な形へデジタル化・構造化することです。散逸した知見を整理し、AIのコンテキスト(文脈)に組み込むことで、AIは初めて「自社専属の熟練エンジニア」として振る舞います。
独自資産のデータ化こそが、競合と差別化するためのAI活用における最大の源泉なのです。
データ品質を最優先
AI駆動開発におけるデータパイプラインでは、AIに参照させるデータを制御することが重要です。参照データの品質が低ければ、高性能なLLMを用いても、アウトプットの品質は向上しません。
そのため、パイプラインにはデータの品質を評価・選別する仕組みを組み込む必要があります。例えば、最新のコーディング規約に準拠したコードや、テストカバレッジが高いコードを優先的にAIに参照させるスコアリング機能の構築が効果的です。
スコアリング機能により高品質な情報のみ優先的にAIへ供給され、AIは正解に近い情報をもとにコード生成や判断を行えます。
また、ノイズの自動除去も欠かせません。例えば、自動生成されたビルド成果物や、非推奨となったライブラリのドキュメントを、データパイプラインの途中で自動的に除外します。
ノイズ処理を自動化することで、古い情報や誤った情報が混入するリスクを抑えられます。
手作業を最小限にする
AI活用が進むほどデータは増え続けるため、手動での収集や更新では早期に限界が訪れます。そのため、担当者の負担や属人化を防ぐためにも、データ収集から反映までを自動化する仕組みを組み込むことが不可欠です。
例えば、以下のような自動化が挙げられます。
- リポジトリへのコードプッシュをトリガーに、コードやメタデータを自動で取得・更新
- Notion・Slack上のドキュメント更新を検知し、関連データをリアルタイムでベクトルデータベースへ反映
- ETL / ELTやDWHを活用し、データの抽出・変換・蓄積を一気通貫で自動処理
このような仕組みにより、LLMは最新情報を参照し、コード生成や判断を行えます。
AI駆動開発を効率よく進めるためには、繰り返し発生する処理はすべて自動化する考え方のもとで、データパイプラインを設計することが不可欠です。
Agentic Workflow(エージェント的ワークフロー)
従来のAI活用は人が指示を出す「受動的」なものでしたが、現在注目されているのはAIが自律的にタスクを完結させるAgentic Workflow(エージェント的ワークフロー)です。これは、AIがデータパイプライン上を自律的に巡回し、PDCAを回し続ける仕組みを指します。
最大の特徴は、AIによる自己修正能力です。例えば、生成したコードでテストが失敗した場合、AI自らがエラーログを解析します。
さらに過去の修正履歴や社内ドキュメントを自発的に参照し、修正案の提示から再実装までを自律的に行います。このワークフローの構築により、人間が介在する待ち時間が激減し、開発サイクルは劇的に高速化します。
単なるツールを超え、自律的に動くデジタルエンジニアを組織に組み込むことが次世代のAI駆動開発の肝となります。
AI駆動開発のデータパイプラインについてよくある質問まとめ
- AI駆動開発におけるデータパイプラインとは、従来のデータ活用と何が違うのですか?
従来のETLはレポート作成(可視化)が主目的ですが、AI杭同開発では「AIモデルの精度維持と自動更新」が目的です。
数値データだけでなく、ソースコード、Slackの議論ログ、設計ドキュメントなどの非構造化データを主に扱います。
また、データの変化(ドリフト)を検知して動的に更新し、AIが生成したコードの結果をフィードバックする循環構造を持っています。
- なぜ最新のAIモデルを使っているだけでは不十分なのですか?
LLMには学習データのカットオフ日があり、貴社の最新のコーディング規約や昨日のバグ修正内容は知りません。
汎用的な正解は出せても、貴社独自のライブラリの使い方や暗黙の設計思想を理解できないため、修正コストの高いコードが生成されやすくなります。
さらに、定期的なデータ供給がないと、システム環境の変化に伴いAIの回答精度が相対的に低下(ドリフト)していきます。
- データ量が少なくてもパイプラインを作る意味はありますか?
あります。
データ量が少ない段階からパイプラインを整備しておくことで、将来的なデータ増加やAI活用の拡大にも無理なく対応できます。
後から作り直すより、早期に「正しい流れ」を作る方がコストを抑えられます。
- 構築の必要性は理解しましたが、自社でイチからパイプラインを組むには工数がかかりすぎませんか?
既存の開発環境(GitHub, Azure, AWS等)との親和性や、どの範囲まで自動化するかにより最適な構成は大きく異なります。AI Marketでは、貴社の既存スタックを理解し、最短距離でパイプラインを構築できる実績豊富な開発会社を無料で選定・ご紹介します。まずはスモールスタートするための構成案を、コンシェルジュと一緒に整理することから始められます。
- 社内に散らばった独自データ資産をどう整理すればいいでしょうか?
どのデータがAIの精度向上に寄与するかを見極める「データアセスメント」が重要です。AI Marketにご相談いただければ、AI駆動開発の知見を持つコンサルタントを介して、どのドキュメントを優先的にベクトル化すべきか、現状のデータ品質で十分かといった初期診断のステップをサポートできる専門企業をご提案します。
まとめ
AI駆動開発におけるデータパイプラインは、LLMに正解データを継続的に供給し、アウトプット品質を安定させるための基盤です。モデルやアルゴリズムの性能以上に、どのデータをどのような状態でAIに参照させるかがAI活用の成否を分けます。
AI駆動開発のデータパイプラインは、データ収集・前処理からベクトル化、分析、展開までを一気通貫で設計することが重要です。特に、RAGを活用した正解データの選別や自動化による継続供給、履歴管理は欠かせません。
膨大な既存コードや散逸したドキュメントを整理し、自律的に動くエージェント環境までを構築するには高度なデータ工学とAI戦略の双方が求められます。自社に最適な構成の検討や、信頼できる開発パートナーの選定にお悩みの際は専門家の視点を取り入れることがプロジェクト成功への近道となります。
まずは自社のデータ資産がどこに眠っているかを棚卸しし、次世代の開発体制への一歩を踏み出しましょう。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

