
LLMの人手評価とは?評価基準設計方法、評価者育成方法、管理ポイント、ツール活用法を徹底解説!
最終更新日:2025年09月29日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- LLMをビジネスで活用する際、自動評価では測れない「品質」を担保するために人による評価が不可欠
- 評価の目的を明確にし、正確性や一貫性といった評価項目、5段階などの評価スケールを体系的に設計
- 人手評価のコストを抑えるには、クラウドソーシングの活用や評価ツールの導入が有効
LLM(大規模言語モデル)の導入が増えている現代では、LLMの信頼性を確保するための評価プロセスも重要になっています。中でもLLM-as-a-Judgeのように、評価を自動化する技術は高まっていると言えます。
しかし、自動評価だけでは見抜けないLLMの「真の品質」がビジネスの信頼性に直結します。そのため、人による主観的な評価も必要です。
この記事では、人手評価(Human Evaluation)基準の設計方法から、評価するアノテーターの育成・管理手法を解説します。また、人材の採用にかかるコストを抑える方法やツールの活用法についても解説しますので、人手評価を検討している企業担当者はぜひ参考にしてみてください。
LLM-as-a-Judgeについてはこちらで詳しく説明していますので併せてご覧ください。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
目次
LLMの人手評価(Human Evaluation)とは?
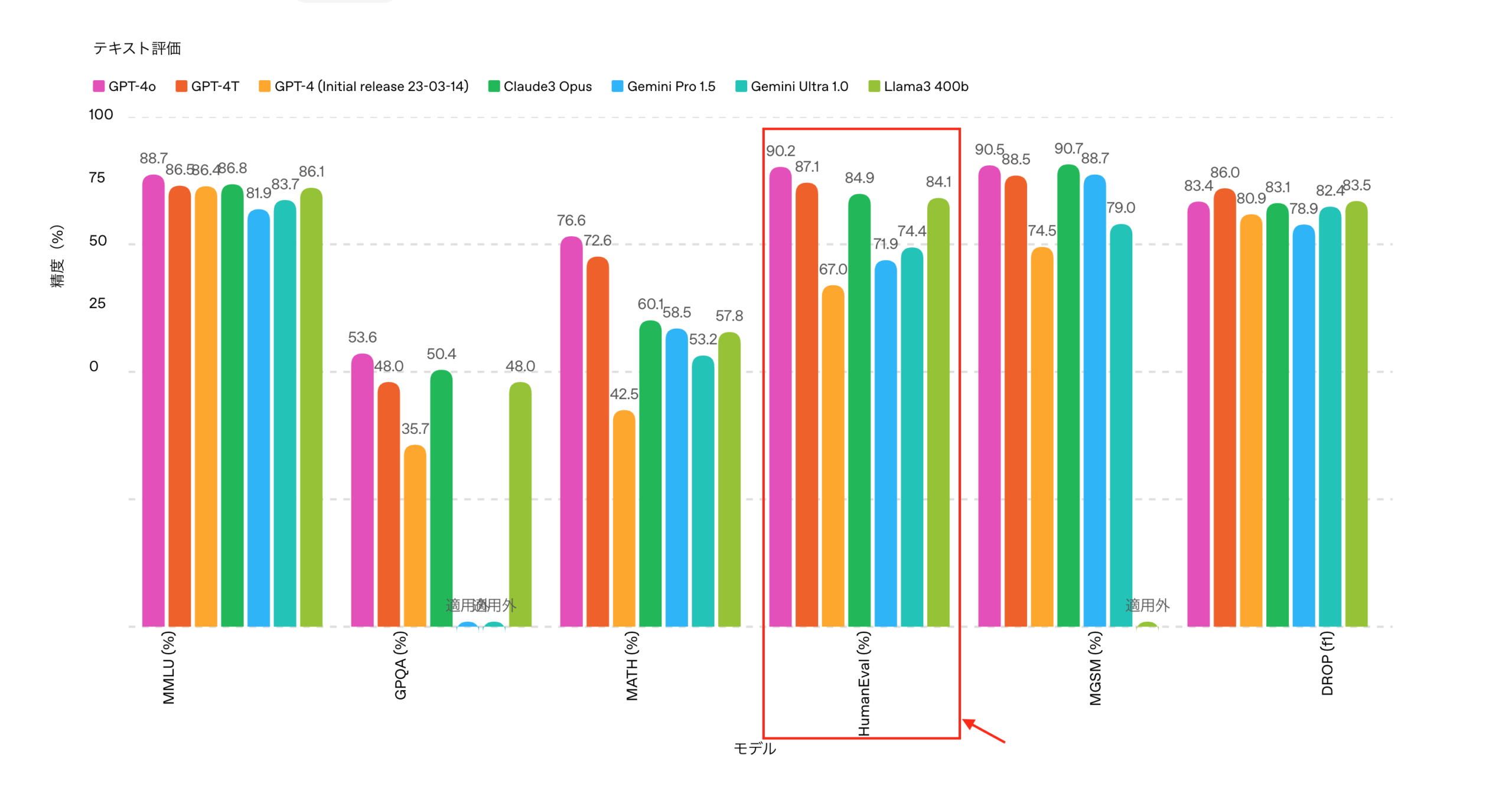
LLMの評価方法は、事前に定義された正解データとLLMの出力を比較し、その類似度などを機械的にスコアリングする自動評価と人手評価の2つに大別されます。最近はLLMでLLMの出力を評価するLLM-as-a-Judgeも特に人気です。
人手評価は、その名の通り、人間がLLMの出力を直接読み、評価基準に沿ってその品質を判断する手法です。
メリットとしては、正確性、流暢さ、安全性、ユーザーの意図との合致度など、自動評価では測れない複雑で微妙な品質を評価できることが重要です。また、ビジネスの現場やエンドユーザーの視点に立った実用的な評価が可能になります。
ただし、評価者の確保や作業にコストと時間がかかること、評価者によって判断がブレる可能性は重要なデメリットです。
コストと時間はかかりますが、サービスの最終的な品質を保証し、ユーザー満足度を向上させるためには、人手評価は不可欠なプロセスです。特に、モデルの選定やファインチューニングの最終判断、継続的な品質モニタリングにおいて重要な役割を果たします。
実際に、上記の画像のように、OpenAI社もモデル発表時に人手評価(Human Evaluation)のスコアを発表しています。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
LLMの人手評価基準の設計方法

人間によるLLMの人手評価では、再現性のある評価基準が不可欠です。ここでは、人手評価基準の設計方法について解説します。
評価目的の定義
LLMの人手評価では、何を測定したいのかを明確にすることから始めます。評価目的が曖昧なまま設計すると、評価者に依存してしまい、再現性が確保できません。
人による評価においても、まずは評価軸を優先度付けして明文化する必要があります。
例えば、顧客対応の自動化を目的とする場合は回答の正確性や一貫性を重視するべきでしょう。一方で、マーケティングコンテンツの生成タスクでは、創造性や自然さといった主観的な要素の評価が必要です。
目的が明確であれば、後続の評価項目設定やスケール設計において一貫性が保たれます。結果として、再現性の高いLLM品質評価が可能になります。
評価項目の設定
評価目的が定まったら、次に具体的な評価項目を設定します。LLMの人手評価では、複数の観点から回答の品質をチェックすることで、総合的な性能を測定可能です。
| 評価軸 | 概要 | 有効なタスク・ケース |
|---|---|---|
| 正確性(Accuracy) | 事実やデータが正しいかどうか | FAQや業務マニュアル |
| 妥当性(Relevance) | 質問や指示に対して適切に回答しているか | タスク達成度の測定 |
| 自然さ(Fluency) | 文章が読みやすく、ユーザーに違和感を与えないか | 顧客向けのテキスト生成タスク |
| 網羅性(Coverage) | 必要な情報を過不足なく含んでいるか | レポート生成や要約タスク |
| 一貫性(Consistency) | 条件やコンテキストに応じて出力が安定しているか | 長期運用や複数セッションを跨ぐ対話 |
| 安全性・倫理性(Safety) | 差別的・攻撃的な表現や有害な内容が含まれていないか | コンプライアンス関連の評価 |
これらの項目は業務用途によって優先度が変わるため、すべてを一律に評価するのではなく、目的に沿って重み付けすることが重要です。また、具体例や判断基準を明文化したガイドラインを添えると、再現性が高まります。
評価スケールの設計
評価項目を設定したら、それぞれをどのようにスコア化するかを設計します。人手評価では、単純な良い/悪いだけでは測定精度が粗くなり、改善点を特定しづらくなります。
そのため、一般的には5段階評価や7段階評価といった多段階スケールを採用し、回答品質の強弱を細かく表現できるようにします。
| 設計方法 | 概要 | スケール設定例 | 適用ケース |
|---|---|---|---|
| 5段階評価 | シンプルで直感的になっていて、スコアを付けやすい | (自然さ評価の場合) 5:非常に自然で人間の文章と遜色ない 4:概ね自然で小さな違和感がある 3:自然さに欠ける箇所が複数ある 2:文法的に誤りが多く不自然 1:読解困難なほど不自然 | 正確性や妥当性の評価、PoC段階での迅速な品質チェック |
| 7段階評価 | 細かな差異を捉えられるため、性能改善の微妙な変化を評価可能 | (正確性評価の場合) 7:完全に正確で誤りなし 6:軽微な表現の揺れがあるが正確 5:ほぼ正確だが小さな事実誤りを含む 4:正確性は半分程度、重要情報が一部不足 3:誤りが目立ち実用に支障 2:多くが不正確 1:ほぼ完全に誤り | モデル比較やA/Bテストなど、改善効果を詳細に数値化したい場合 |
こうした多段階評価によって、評価者間の解釈のずれを防ぐことが可能です。
また、誤り検出の目的ならバイナリ(合格/不合格)スケール、複雑な判断が必要な場合はチェックリスト形式を併用するのも有効です。
主観評価と客観評価のバランス
LLMの人手評価では、客観的な指標だけでなく、評価者の感覚に基づく主観評価も反映させる必要があります。例えば、文章の自然さやユーザーが受ける印象は人間の感覚でしか測れません。
一方で、主観評価は評価者ごとに解釈がぶれやすいため、客観評価と組み合わせて補完することが重要です。具体的には、以下のようなフローでばらつきを抑える工夫が必要です。
- 定量化できる要素(正確性や網羅性など):チェックリストやスコアで判定
- 定性的な要素(自然さや読みやすさ):評価者による平均スコアを採用
また、主観的な評価結果は定期的にレビューし、ガイドラインやサンプルを更新します。その上で基準を整備することで、一貫性のある評価が可能になります。
評価プロセスの標準化
主観評価と客観評価のバランスが調整できたら、評価プロセスの標準化を行います。人手評価は評価者ごとにやり方が異なると、評価が反映されるまでの時間や結果が不安定になってしまいます。
それを防ぐために、まずは評価フローを明文化します。具体的には、以下の一連の手順をドキュメント化します。
- タスク選定
- 評価基準の適用
- スコア記録
- レビュー
- フィードバック
評価基準の共有
次に、評価基準やスケールを統一したガイドラインを整備し、評価者間で共有します。サンプル回答や模範スコアを付けたリファレンスデータを用意しておくと、判断基準がブレにくくなります。
また、評価ツールを活用して進捗を一元管理し、誰がどのデータを評価したかをログとして残すことで再現性と透明性を確保できます。
標準化された評価プロセスは、LLM品質評価の信頼性と効率を高める基盤になり得ます。そのため、人手評価を実施する際は評価プロセスの標準化をゴールとして設計しましょう。
LLMの人手評価における評価者の育成・管理手法

精緻で安定した評価基準を整備しても、実際に評価を行う評価者がそれを正しく理解・運用できなければLLMの品質は担保できません。ここでは、初期トレーニングからフィードバック・再教育までの実践的な方法を解説します。
関連記事:「LLM導入での評価体制構築で難しいのは?生成AI改善サイクルの運用フロー、自動評価を実現」
初期トレーニング
人手評価を実施する前に、まずは評価者をトレーニングします。初期トレーニングでは、座学+演習+フィードバックを組み合わせることが効果的です。
- 座学:評価目的、評価基準、スケールの意味を解説
- 演習:サンプル回答を使ったスコア付け演習
- 模範解答との比較
- フィードバック
とはいえ、これらは別々に行うのではなく、手順に沿って実施するのが有効です。具体的な流れは以下の通りです。
| ステップ | 具体的な施策 |
|---|---|
| 1.事前資料の配布 | 評価基準、具体例、チェックリストをまとめたガイドを事前に共有・予習 |
| 2.ワークショップ形式での実施 | 少人数で演習を行い、リアルタイムで修正を加えることで理解度を均一化 |
| 3.テスト評価の実施 | 実運用データの一部を使ったテストを行う |
| 4.フィードバックと再演習 | スコアの傾向やズレを分析し、必要に応じて再トレーニングを実施する |
このプロセスを通じて、評価者間で認識する基準の差異を最小限に抑え、安定したLLM品質評価が可能な状態に整えます。初期トレーニングは一度きりではなく、理解度を確認するための「ゲート」として機能させることが重要です。
評価品質のモニタリング
初期トレーニング後は、評価者の評価品質を継続的にモニタリングします。モニタリングシステムでは、クロスチェックを導入するのがおすすめです。
クロスチェックとは同じ回答を複数の評価者に割り当てて、スコアの一致率を計測します。評価結果の一致率を数値化するために、Cohen’s KappaやFleiss’ Kappaといった統計指標を用いると客観的に一貫性を測定できます。
他にも、以下のモニタリング手法が有効です。
| モニタリング手法 | 概要 |
|---|---|
| ランダムサンプリング | 評価結果の一部を定期的に抽出してレビューし、極端なスコアや一貫性のない判定を発見する |
| スコア分布の可視化 | 評価者ごとの平均点や分布をダッシュボードで可視化し、偏りや異常値を早期に検出する |
| 再現性チェック | 過去に評価済みのデータを再度提示し、同じスコアが付くかを検証する |
モニタリングによって、LLMno長期運用における品質低下やスコアのばらつきを防止します。
モニタリングについては、評価者の誤りやぶれを非難するためではなく、評価基準を揃えるための仕組みとして設計するとシステムとして維持しやすくなります。
評価者ガイドラインの作成
評価者の育成や管理においては、評価者ガイドラインを作成しておくのが不可欠です。ガイドラインには、以下の内容を含めましょう。
| 内容 | 詳細 |
|---|---|
| 評価目的 |
|
| 評価基準 |
|
| スコアリングルール |
|
| 作業手順と注意点 |
|
| 品質管理とフィードバック |
|
| 曖昧なケースに対する判断指針 |
|
また、ガイドラインは一度作成したら終わりではなく、評価結果の傾向や現場からのフィードバックに基づいて、定期的に更新することが望ましいです。
こうしたガイドラインにより、誰が評価したとしても、同じ基準でLLM品質評価を実施できる体制が整備されます。
フィードバックと再教育
評価者のスキル確保には、継続的なフィードバックと再教育が必要です。
フィードバックでは、評価結果をレビューし、評価者ごとのスコア傾向や一致率を可視化して共有します。これにより、個々の強みや改善点が明確になり、評価基準から逸脱している部分を早期に修正することが可能です。
また、基準の改定や新しい評価項目が追加された際には再トレーニングセッションを実施し、評価者の理解度を均一化することが必要です。月次や四半期ごとにワークショップ形式で事例検討を行うと、評価者間の解釈の差異が減って品質評価の一貫性が高まります。
フィードバックと再教育を組み込んだ運用体制によって評価品質を安定させ、改善サイクルを回し続けることが可能です。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
LLMの人手評価コストを抑える方法

人手評価はLLMの品質向上に有効ですが、データ量が増えるほどコストも膨らみやすいのが課題とされます。ここでは、人手評価にかかるコストを抑えつつ、信頼性の高い評価を維持する方法を解説します。
クラウドソーシングの活用
LLMの人手評価では、評価対象データが膨大になるほど人的リソースの確保が問題に挙げられるようになります。
そこで有効なのがクラウドソーシングです。外部の評価者を利用することで、短期間で大量の評価タスクを処理できて社内リソースの負担を軽減できます。
ただし、クラウドソーシングでは評価者のスキルや理解度がばらつきがちです。そのため、実際の人手評価を行う際は、事前のトレーニング、テスト、ガイドラインの共有が必須となります。
社内外リソースの併用
社内外リソースを上手に組み合わせる戦略も、人手評価のコストを抑えつつ品質を確保するために有効です。重要な領域や機密性の高いデータは、ドメイン知識を持つ社内メンバーに担当させることで評価の正確性とセキュリティを確保します。
一方で、一般的な回答の品質評価や大量の初期スクリーニングは、外部のアノテーターやクラウドソーシングを活用することでコストを抑えられます。この際、外部リソースの活用後に社内チームが評価品質の監督を担い、定期的にレビューする仕組みが必要です。
こうした役割分担により外注コストを削減しつつ、評価基準や品質の一貫性を保つことができます。
評価ツールの利用
人手評価の信頼性を確保しながらコストを抑えるには、評価ツールの導入も効果的です。人手評価での活用に有効なツールは以下の通りです。
開発・実験管理フェーズ
| 代表的なツール / プラットフォーム | 特徴 | 主な活用例・目的 |
|---|---|---|
| LangSmith (LangChain) |
|
|
| Weights & Biases (W&B) |
|
|
本番モニタリング・観測可能性
| 代表的なツール / プラットフォーム | 特徴 | 主な活用例・目的 |
|---|---|---|
| Arize AI |
| |
| Datadog, New Relic など |
|
|
高品質な人手評価・データ生成
| 代表的なツール / プラットフォーム | 特徴 | 主な活用例・目的 |
|---|---|---|
| Scale AI |
|
|
オープンソース評価フレームワーク
| 代表的なツール / プラットフォーム | 特徴 | 主な活用例・目的 |
|---|---|---|
| RAGAS, ARES |
|
|
これらのツールを組み合わせることで、評価基準の標準化・アノテーターの一貫性管理・集計作業の自動化が可能となり、LLM品質評価の信頼性とスピードを両立できます。
現在は、LLMアプリケーションの開発から本番運用までを一気通貫で支援するLLMOpsプラットフォームが台頭しており、その機能の一部として高度な人手評価・自動評価機能が統合されています。
また、単純なテキスト生成だけでなく、RAG(拡張検索生成)システムやLLMエージェントといった、より複雑なアプリケーションの評価が重要になっています。これには、従来とは異なる評価指標やツールが必要です。
LLMの人手評価についてよくある質問まとめ
- LLMの人手評価とは?
LLMの人手評価とは、モデルの出力結果を人間が確認し、スコア付けするプロセスです。自動評価では判断が難しい主観的な要素(読みやすさ、ユーザーが満足するか)を補完でき、モデル改善のフィードバックを得られます。
- 人手評価は自動評価とどう使い分けるべき?
使い分けとしては両者を組み合わせるのが理想で、自動評価で大まかな精度を確認し、重要なケースや曖昧な出力は人手評価を行うことで、効率と品質のバランスを取ります。
- 自動評価:大量データを短時間で評価でき、定量的な傾向を把握するのに適している
- 人手評価:細かいニュアンスやユーザー体験を重視するタスクに向いている
- LLMの人手評価を行う評価者を育成・管理するにはどうすれば良いですか?
評価の品質を安定させるには、評価者の育成と管理が重要です。以下の手法が有効です。
- 初期トレーニング: 座学と演習を組み合わせ、評価基準の認識を統一します。
- 品質モニタリング: 同じデータを複数人で評価する「クロスチェック」などで、評価者間の一致率を定期的に確認します。
- 評価者ガイドラインの作成: 評価目的やスコアリングルール、作業手順を明記した文書を作成し、判断基準を明確にします。
- 継続的なフィードバック: 定期的に評価結果をレビューし、改善点を共有することで、評価者全体のスキルを維持・向上させます。
- コストがかさみがちなLLMの人手評価を、効率的に行う方法はありますか?
人手評価のコストを抑えつつ品質を維持するには、以下の方法が有効です。
- クラウドソーシングの活用: 大量の評価タスクを外部リソースに委託し、社内の負担を軽減します。
- 社内外リソースの併用: 機密性の高いデータは社内で、一般的なデータは外部で、と役割分担することでコストと品質のバランスを取ります。
- 評価ツールの利用: LangSmithやArize AIといった専門ツールを導入し、評価プロセス管理や集計作業を自動化・効率化します。特に、開発から本番運用までを一貫して支援するLLMOpsプラットフォームの活用が現在の主流です。
まとめ
LLMの人手評価は、モデルの改善と事業成果を左右するプロセスとして、近年注目されています。明確な評価基準の設計から、アノテーターの育成・管理を徹底することで、ばらつきのない結果を得られます。
しかし、これらのプロセスを自社だけでゼロから構築し、継続的に改善していくには深い専門知識と経験が求められます。特に、事業のコア部分に関わるLLMの品質管理は非常に繊細な判断を要する場面も少なくありません。
もし、評価基準の設計に迷ったり、評価プロセスの効率化、あるいはより高度なLLM活用について課題を感じているのであれば一度専門家の知見を取り入れることをお勧めします。外部の専門家は最新の評価手法や業界のベストプラクティスに精通しており、貴社の状況に合わせた最適な評価基盤の構築を支援してくれます。
確かな品質管理体制を築き、LLM活用の成功を確実なものにするための一歩として、専門家への相談をぜひご検討ください。
。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

