
ランダムフォレストとは?決定木との違いやアルゴリズム、活用事例を徹底解説
最終更新日:2026年01月26日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役
ランダムフォレストは、ビジネスの現場で日々直面する複雑なデータ分析の課題を解決する強力なツールです。
多数の決定木を組み合わせることで、従来の分析手法では見過ごされてしまいがちなパターンや関係性を捉え、高精度の予測や分類を可能にします。ランダムフォレストと決定木では明確に異なるため、それぞれの仕組みについて理解する必要があります。
この記事では、ランダムフォレストと決定木の違いや、構成要素であるアルゴリズム、メリット・デメリット、活用事例について解説していきます。この記事を読むことで、ランダムフォレストが自社のビジネスにどのように貢献できるのか、具体的なイメージをつかむことができるでしょう。
関連記事:「AI(人工知能)とは?強いAIと弱いAIとは?」
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
AI開発会社をご自分で選びたい場合はこちらで特集していますので併せてご覧ください。
目次
ランダムフォレストとは?

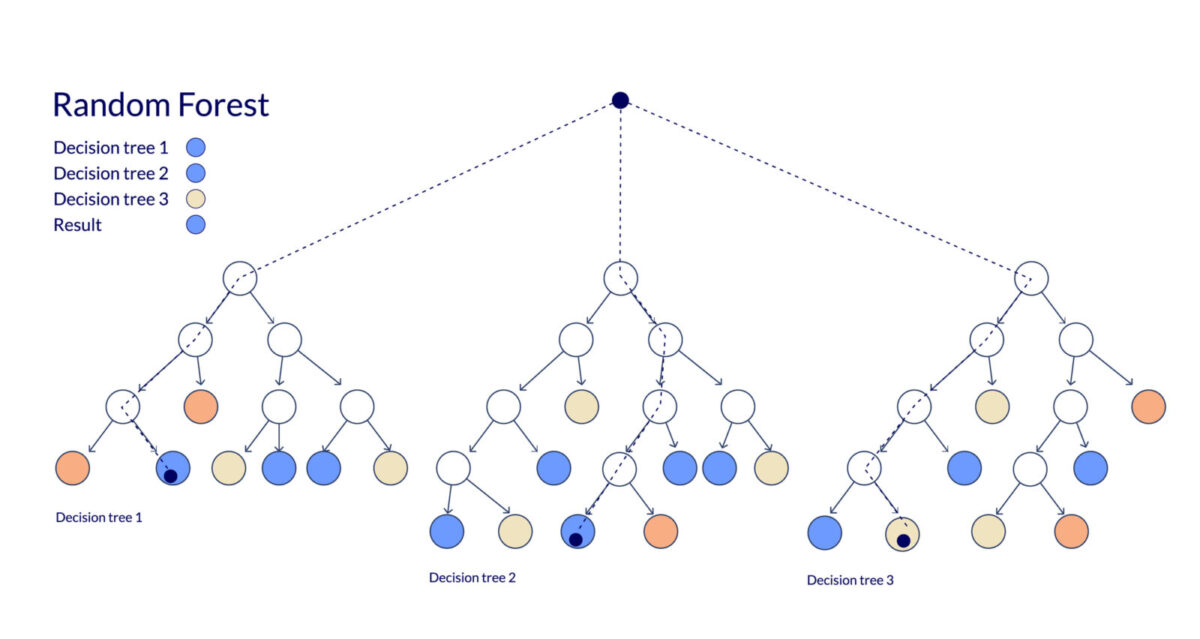
ランダムフォレストは機械学習におけるアンサンブル手法の一つで、複数の決定木分類器を統合し、確率的な予測を行う教師あり学習アルゴリズムです。各決定木分類器は独立して学習され、それらの予測を集約することで、モデルの分散を低減させながら予測精度を向上させます。
ランダムフォレストの学習プロセスでは、ブートストラップ法により、元データセットから重複を許してランダムにサンプリングされた複数の訓練データセットを生成します。分類タスクにおいては投票方式による多数決、回帰タスクでは各決定木の予測値の平均を算出することで安定した予測を実現します。
複数の異なる学習器を組み合わせることで予測性能を向上させるアンサンブル学習の代表的な実装例として位置づけられます。
関連記事:「アンサンブル学習とは?仕組みや学習手法、メリット、注意点」
ランダムフォレストと決定木の違い
決定木は、データを枝分かれさせながら再帰的にデータを分割し、階層的な判断規則を構築する直観的な学習アルゴリズムです。特徴量の中から最も情報量が高いものを選び、データを分割していくことで、ツリー状の構造を形成します。
しかし、決定木はモデルの複雑性が増大すると学習データに対して適合しすぎてしまい、過学習が発生しやすいのが課題とされています。過学習が発生すると、モデルの汎化性能が著しく低下する本質的な課題を抱えています。
一方、ランダムフォレストはアンサンブル学習が採用されているため、決定木よりも高い予測精度を実現し、過学習のリスクを低減することが可能です。各決定木が異なる特徴量のサブセットを使って学習します。
この確率的な学習メカニズムにより、個々の決定木の予測バイアスを相殺しつつ、モデル全体としての多様性を確保しています。カーネル法に基づくサポートベクターマシン(SVM)のような分類タスクに使われる他の機械学習アルゴリズムとは異なるアプローチですが、特定の分類タスクではSVMと同等以上の性能を発揮することがあります。
関連記事:「AIでデータ分析を行うメリットは?代表的手法・LLMの活用戦略・導入注意点と活用事例を徹底解説!」
ランダムフォレストの応用技術
ランダムフォレストは、その高い汎用性と精度の高さから、さまざまな技術分野で応用されています。統計的なノイズに対する耐性が高く、分類および回帰の双方において安定した予測性能を発揮します。
例えば、医療画像の解析などの画像認識分野や金融分野でのリスク評価など、高度な判断が求められる分野でも活用されています。
近年では、ディープラーニングの発展でDNN(ディープニューラルネットワーク)や畳み込みニューラルネットワーク(CNN)が主流となっていますが、ランダムフォレストはその解釈のしやすさや効率性から、補完的な役割を果たすことがあります。
このように、ランダムフォレストは多岐にわたる技術で応用されており、精度の高い予測やデータ解析を支える技術として重要な役割を担います。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
ランダムフォレストを構成するアルゴリズムの仕組み
ランダムフォレストの構造を支える要素として、ブートストラップ法・特徴量のランダム選択・多数決による予測の生成があります。以下では、ランダムフォレストの仕組みとして欠かせないアルゴリズムを1つずつ見ていきましょう。
ブートストラップ法
ブートストラップ法は、ランダムフォレストの基盤となるデータサンプリング手法であり、学習データの多様性を確保しながらモデルの汎化性能を向上させる役割を果たします。
元のデータセットからランダムにサンプリングを行い、複数のサブセットを作成します。
ブートストラップ法によって、ランダムフォレストでは各決定木の学習用データを独立に作成することが可能です。個々の決定木が異なるデータのパターンを学習するため、全体のモデルが特定のデータに依存しすぎることがなくなります。
結果として、単一の決定木よりも高い汎化性能が実現され、未知のデータに対する適応力が向上します。
特徴量のランダム選択
ランダムフォレストではパターンの偏りを防ぐために、全特徴量の中からランダムに選ばれた一部の特徴のみを考慮します。通常の決定木では、データの特徴量をすべて考慮し、情報量の多い特徴を優先的に分岐条件として選択します。
しかし、通常の決定木の方法では、一部の支配的な特徴量に依存する傾向が強まり、モデルが特定のパターンに偏りやすくなります。
ランダムフォレストでは各決定木が異なる特徴に基づいた学習を行うため、モデル全体の多様性が向上します。
さらに、特徴量をランダムで選択することで、特徴量の重要度を測定する際にも効果的です。ランダムフォレストでは、各特徴量がどの程度モデルの予測に貢献しているかを算出できるため、特徴量選択やデータの解釈にも活用可能です。
多数決による予測の生成
ランダムフォレストでは、個々の決定木の予測を統合することで結果を導き出します。
まず、各決定木が独立して学習し、それぞれの入力データに対して予測を出します。その後、すべての決定木の予測結果の中で最も多く出現したクラスを、最終的な予測値として採用します。
この手法により、ランダムフォレストはノイズの影響を受けにくく、より確実な予測モデルとなります。個々の決定木が持つ弱点を相互に補完し合うことで、高い精度と汎化性能を維持することが可能です。
分類問題と回帰問題で異なる方法が採用されており、それぞれのタスクに適した形で最適な予測を生成することが可能です。分類タスクでは多数決、回帰タスクでは平均値を取ることで最終的な予測を生成します。
ランダムフォレストの4つのメリット

ランダムフォレストを導入することで、以下のようなメリットが得られます。
- 広範なデータを高精度で分析できる
- 過学習を抑制できる
- 特微量の重要度を評価する
- 分類と回帰に対応できる
それぞれのメリットについて見ていきましょう。
広範なデータを高精度で分析できる
ランダムフォレストでは、単一の決定木が捉えきれない多様なデータパターンを学習できます。ノイズの多いデータや非線形な関係を持つデータでも、比較的高い精度を維持しながら解析することが可能です。
また、大規模データに対しても有効であり、ランダムに選択したサブセットを使うことで計算コストを抑えながら高精度なデータ分析を可能にします。
関連記事:「データ分析の仕組み、メリット・デメリット・手法の特徴・導入方法・データ事例」
過学習を抑制できる
ランダムフォレストが持つ、ブートストラップ法のランダムなデータサンプリングによって、特定のデータに依存しすぎることを防ぎます。各決定木は異なるデータの部分集合を用いて学習するため、特定のパターンに過度に適合するリスクが低くなります。
また、ランダムフォレストでは弱い学習器を多数組み合わせることで、バランスの取れた予測を行います。学習データの細部に引っ張られず、未知のデータに対しても安定した精度を発揮することが可能です。
特微量の重要度を評価する
ランダムフォレストの特徴量の重要度評価は、データ分析や機械学習モデルの解釈性を向上させるうえで有効です。高次元データを扱う場合に、どの変数が予測に貢献しているのかを特定することで、予測精度の向上に役立つデータを取得できます。
重要な特徴を抽出してモデルの精度を向上させたり、不要な特徴を削減して計算コストを抑えることもできます。こうした特徴は、マーケティングや医療などの分野で、意思決定の根拠を強化するツールとしても活用されています。
分類と回帰に対応できる
ランダムフォレストは、機械学習における分類と回帰の両タスクに適用可能です。この特性により、幅広い分野のデータ分析に活用され、高精度な予測を実現することが可能になります。
分類タスクでは、各決定木が与えられたデータに対して異なるクラスの予測を行い、多数決によって最終的な予測を決定されます。各決定木が異なるデータのサブセットを学習することで、精度の高い回答を得られます。
一方、回帰タスクでは各決定木が数値の予測を行い、その平均値を算出します。この手法により、外れ値に影響を受けにくく、精度の高い回帰モデルを構築することが可能です。
このように、ランダムフォレストは実務においても幅広く利用されています。さまざまなデータ分析のニーズに応えられるアルゴリズムであると言えるでしょう。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
ランダムフォレストのデメリット

ランダムフォレストは高精度な予測を可能にする一方で、いくつかのデメリットも内在しています。以下では、ランダムフォレストのデメリットについて解説していきます。
計算コストが高い
ランダムフォレストは、複数の決定木を構築し、それらの予測を統合するアンサンブル学習で結果が出力されるため、それぞれの決定木の学習と予測処理に多くの計算リソースが必要です。
単一の決定木は比較的軽量でも学習できます。しかし、ランダムフォレストでは数十から数百の決定木を同時に学習させるため、メモリ消費量や計算時間が大幅に増加します。
また、各決定木の構築時に特徴量のランダム選択やデータサンプリングが行われるため、データ量が増えるほど計算負荷も高くなります。
そのため、リアルタイム処理を求められるタスクでは生成にかかる時間がネックとなるでしょう。ランダムフォレストを実装する際には、必要な決定木の本数を調整し、並列処理を活用するなどの工夫が求められます。
精度は学習データに依存する
ランダムフォレストの高精度予測や汎化性能は、学習データの質に大きく依存します。モデルの学習に使用するデータが不十分であったり、バイアスを含んでいたりすると、予測結果の精度が低下する可能性があります。
テキストデータなど、疎なデータや多くのカテゴリ特徴を持つデータに対しては、他のアルゴリズムと比べてパフォーマンスが低いことがあります。また、特に小規模なデータセットでは過学習が発生する可能性があります。
ランダムフォレストでは、ブートストラップ法によりノイズの影響を抑えることはできます。しかし、データそのものの品質が低い場合には限界があるでしょう。
モデルの解釈性は低い
単一の決定木は、データの分岐ルールを明確に把握でき、各特徴量がどのように予測に影響しているのかを直感的に理解することができます。しかし、ランダムフォレストでは多数の決定木が個別に学習しているため、単純なルールに基づいて予測を説明することが困難です。
ビジネスや医療などの分野では、予測結果の根拠を説明できることが重要視されるため、ブラックボックス化しやすいランダムフォレストは適用が難しい場合があります。
解釈性が求められるタスクでは、他の手法と組み合わせて使用するか、より説明可能なモデルを選択する必要があります。
関連記事:「XAIの概要からアプローチ手法、メリット、課題、活用分野」
ハイパーパラメータの適切な制御が必要
ランダムフォレストの主要な技術的制約として、アルゴリズムの性能を最大限に引き出すために複数のハイパーパラメータを適切に調整する必要があります。
具体的には、モデルの構造を規定する以下に挙げるような複数の重要なパラメータの最適値を決定する必要があります。
- 決定木の総数(n_estimators)
- 各決定木の最大深さ(max_depth)
- ノードの分割に使用する特徴量の数(max_features)
これらのパラメータは相互に影響し合い、データセットの特性によって最適値が大きく変動するため、一般的な指針のみでは十分な性能を得ることが困難です。
さらに、これらのハイパーパラメータの最適化プロセスは、計算機資源を大量に消費する傾向があります。グリッドサーチやランダムサーチなどの一般的なハイパーパラメータ最適化手法を適用する場合、数多くのパラメータの組み合わせについてクロスバリデーションを実行する必要があります。これには相当な計算時間とメモリリソースが要求されます。
特に大規模なデータセットを扱う場合、この最適化プロセスがプロジェクトのボトルネックとなる可能性があります。
このパラメータ調整の複雑さは、特に実務での導入において重要な考慮事項となります。最適なパラメータ設定を見つけるまでの試行錯誤のプロセスは、プロジェクトの開発サイクルに大きな影響を与える可能性があり、迅速なモデル展開が求められる場面では制約となることがあります。
ランダムフォレストの活用事例

ランダムフォレストは、高精度な予測と汎用性の高さから、さまざまな分野で活用されています。それぞれの分野でどのように応用されているのか、具体的な事例について解説していきます。
マーケティング
ランダムフォレストは、マーケティング分野において顧客分析やターゲティングの精度向上に貢献しています。より複雑なパターンを捉え、高精度な予測が可能になります。
例えば、ECサイトでは、顧客の過去の購入履歴や閲覧履歴を基に、次に購入する可能性が高い商品を予測するレコメンドシステムに活用されています。パーソナライズされた提案が可能になり、コンバージョン率の向上も見込めます。
また、顧客の離脱予測や広告の効果測定にも応用されており、データが集まりやすいマーケティングにおいては、ランダムフォレストが特に有効なツールと言えるでしょう。
関連記事:「マーケテイング分析とはどんなものであるかや、メリット、各フレームワークの特徴」
異常検知
ランダムフォレストは、異常検知の分野でも強力なツールとして活用されています。不正行為の検出やシステムの異常監視などの精度を高め、確実性を向上させることが可能です。
例えば、製造業では設備の異常検知に活用されており、センサーから収集されたデータを解析します。通常とは異なる機械の動作を識別することで、故障の予兆を早期に検出する予知保全が可能です。
また、サイバー攻撃や不正アクセスの兆候を検知するといった、ネットワークセキュリティ分野にも使用されています。特徴量のランダム選択によって異常を分析できるため、攻撃手法の変化にも適応しやすいという利点があります。
関連記事:「異常検知とは?メリットや学習方法、手法」
金融
金融分野においては、リスク管理や不正検出、信用スコアリングといった用途で活用されています。膨大な取引データをリアルタイムで分析し、適切な判断を下すことが求められる業界であるため、リスク評価や異常検知といった活用方法が重宝されています。
従来の単純なルールベースのアプローチでは考慮しきれなかった複数の要素を、ランダムフォレストが統合的に分析し、より精度の高い信用スコアを算出することが可能になります。これにより、銀行や金融機関は貸付の意思決定を的確に行うことができ、健全なリスク管理を実現します。
また、株式市場の予測にも利用されており、従来の統計手法よりも市場の変動パターンを正確に捉えることが可能になります。ランダムフォレストの高精度な予測とデータ分析機能は、今後も金融業界での重要な役割を担うことになるでしょう。
関連記事:「金融業界で今、AIがどのように活用されているか」
医療
医療分野で活用するデータは多くの変数を含み、ノイズが多い傾向があります。ランダムフォレストはこうしたノイズや複雑なデータにも対応可能で、パターンの抽出・予測を実現します。
例えばがんの早期診断では、MRIやCTスキャンの画像データ、血液検査結果などの多様な情報を統合し、疾患の可能性を予測します。多数のデータを同時に考慮しながらモデルを構築できるため、単純なルールベースの診断よりも精度が向上しやすいのが特徴です。
また、患者データから将来病気になる可能性を予測することも可能です。栄養素や診断結果を活用することで、病気の予防にも貢献します。
関連記事:「医療業界が直面する医師の労働環境、データ管理、診断精度の課題」
サイバーセキュリティ
サイバーセキュリティ分野におけるランダムフォレストの応用は、特に異常検知とマルウェア分析において重要な技術革新をもたらしています。ランダムフォレストは、複雑なサイバー攻撃パターンの識別と、新種の脅威に対する適応的な検知を可能にします。
ランダムフォレストがサイバーセキュリティで特に有効とされる理由は、ネットワークトラフィックやシステムログなどの高次元データから、攻撃の特徴を自動的に学習できる点にあります。例えば、以下のような多様な特徴量を組み合わせて、正常な通信と異常な通信を高精度で区別できます。
- ネットワークパケットのヘッダー情報
- 通信プロトコルのパターン
- アクセス頻度
さらに、マルウェア検知における応用も注目されています。実行ファイルのバイナリパターン、APIコール系列、システムリソースの使用状況などの特徴を学習することで、既知のマルウェアだけでなく、新種のマルウェアや亜種の検出にも効果を発揮します。
このように、サイバーセキュリティにおけるランダムフォレストの活用は、単なる検知システムの実装を超えて、セキュリティ分析の質的向上にも貢献しています。
貴社ニーズに特化したAI開発に強い開発会社の選定・紹介を行います
今年度AIシステム開発相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・画像認識、予測、LLM等、AI全対応
完全無料・最短1日でご紹介 AI開発に強い会社選定を依頼する
ランダムフォレストについてよくある質問まとめ
- ランダムフォレストとは?
ランダムフォレスト(Random Forests)は、機械学習のアルゴリズムの1種です。複数の決定木を組み合わせることで、弱学習器を統合し、モデルの汎化性能を向上させるアンサンブル学習の手法です。
- ランダムフォレストと決定木の違いは?
決定木は、データをルールベースで分類・回帰するシンプルなアルゴリズムです。
一方、ランダムフォレストはアンサンブル学習を活用し、複数の決定木を組み合わせています。各決定木が異なる特徴量のサブセットで学習するため、バイアスが抑えられる仕組みになっています。
- ランダムフォレストの欠点は何ですか?
ランダムフォレストを運用していく上で、以下のような欠点・デメリットがあります。
- 計算コストが高い
- 精度は学習データに依存する
- モデルの解釈性は低い
まとめ
ランダムフォレストは、複数の決定木を組み合わせることで高精度な予測を実現するアルゴリズムです。過学習を抑えつつも、汎化性能を高めることが可能で、分類と回帰の両方に対応できる柔軟性を持ちます。
しかし、その性能を最大限に引き出すためには、適切なデータの前処理やパラメータの調整、そして結果の解釈が不可欠です。より高度な分析や、特定のビジネス課題への適用を検討される場合は、機械学習やデータ分析の専門家にご相談いただくことをお勧めします。
AI開発会社をご自分で選びたい場合はこちらで特集していますので併せてご覧ください。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

